







原文地址:https://my.oschina.net/dfsj66011/blog/793392
例如,假设你有一个关于身高和体重的数据框数据:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from numpy import float64
#身高数据
Height_cm = np.array([164, 167, 168, 169, 169, 170, 170, 170, 171, 172, 172, 173, 173, 175, 176, 178], dtype=float64)
#体重数据
Weight_kg = np.array([54, 57, 58, 60, 61, 60, 61, 62, 62, 64, 62, 62, 64, 56, 66, 70], dtype=float64)
hw = {'Height_cm': Height_cm, 'Weight_kg': Weight_kg}
hw = pd.DataFrame(hw)#hw为矩阵 两列两个变量(身高和体重) 行为变量序号
print hw Height_cm Weight_kg
0 164.0 54.0
1 167.0 57.0
2 168.0 58.0
3 169.0 60.0
4 169.0 61.0
5 170.0 60.0
6 170.0 61.0
7 170.0 62.0
8 171.0 62.0
9 172.0 64.0
10 172.0 62.0
11 173.0 62.0
12 173.0 64.0
13 175.0 56.0
14 176.0 66.0
15 178.0 70.0import pandas as pd
from sklearn import preprocessing
import numpy as np
from numpy import float64
from matplotlib import pyplot as plt
#scale 数据进行标准化 公式为:(X-mean)/std 将数据按按列减去其均值,并处以其方差 结果是所有数据都聚集在0附近,方差为1。
is_height_outlier = abs(preprocessing.scale(hw['Height_cm'])) > 2 #线性归一化 数据中心的标准偏差与2比较
is_weight_outlier = abs(preprocessing.scale(hw['Weight_kg'])) > 2
is_outlier = is_height_outlier | is_weight_outlier#按位或 表示两个变量中有一位是异常的 本组数据(体重,身高)异常 is_outlier是数组,值为True或False
color = ['g', 'r']
pch = [1 if is_outlier[i] == True else 0 for i in range(len(is_outlier))]#pch是数组,值为1或0,1表示异常点
cValue = [color[is_outlier[i]] for i in range(len(is_outlier))]#颜色数组
# print is_height_outlier
# print cValue
fig = plt.figure()
plt.title('Scatter Plot')
plt.xlabel('Height_cm')
plt.ylabel('Weight_kg')
plt.scatter(hw['Height_cm'], hw['Weight_kg'], s=40, c=cValue)#散点图 s代表图上点大小
plt.show()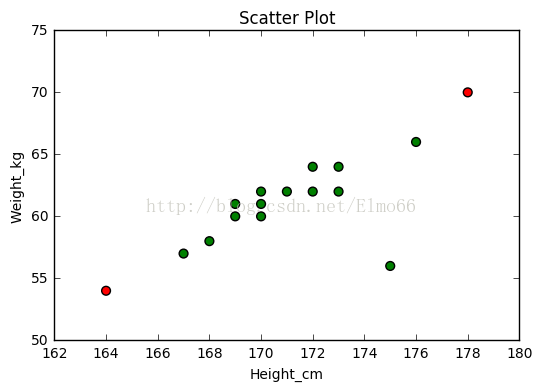
注意,身高为175cm的这个数据点(图中右下角)并没有被标记为异常点,它与数据中心的标准偏差低于2,但是从图中直观的发现的它偏离身高、体重的线性关系,可以说它才是真正的离群点。
顺便说一下,上图中尺度的选择可能会有些误导,实际上,身高对体重的影响关系应该让Y轴从0开始,但是我仅仅是想通过这些数据说明异常值的检测,希望你能忽略这个不好的习惯。
下面我们使用马氏距离求解:
#马氏距离检查异常值
# -*- coding: utf-8 -*-
#马氏距离检查异常值,值越大,该点为异常点可能性越大
import pandas as pd
import numpy as np
from numpy import float64
from matplotlib import pyplot as plt
from scipy.spatial import distance
from pandas import Series
from mpl_toolkits.mplot3d import Axes3D
#身高数据
Height_cm = np.array([164, 167, 168, 168, 169, 169, 169, 170, 172, 173, 175, 176, 178], dtype=float64)
#体重数据
Weight_kg = np.array([55, 57, 58, 56, 57, 61, 61, 61, 64, 62, 56, 66, 70], dtype=float64)
#年龄数据
Age = np.array([13, 12, 14, 17, 15, 14, 16, 16, 13, 15, 16, 14, 16], dtype=float64)
hw = {'Height_cm': Height_cm, 'Weight_kg': Weight_kg, 'Age': Age}#hw为矩阵 三列三个变量(身高、体重、年龄) 行为变量序号
hw = pd.DataFrame(hw)
print len(hw)#13
n_outliers = 2#选2个作为异常点
#iloc[]取出3列,一行 hw.mean()此处为3个变量的数组 np.mat(hw.cov().as_matrix()).I为协方差的逆矩阵 **为乘方
#Series的表现形式为:索引在左边,值在右边
#m_dist_order为一维数组 保存Series中值降序排列的索引
m_dist_order = Series([float(distance.mahalanobis(hw.iloc[i], hw.mean(), np.mat(hw.cov().as_matrix()).I) ** 2)
for i in range(len(hw))]).sort_values(ascending=False).index.tolist()
is_outlier = [False, ] * 13
for i in range(n_outliers):#马氏距离值大的标为True
is_outlier[m_dist_order[i]] = True
# print is_outlier
color = ['g', 'r']
pch = [1 if is_outlier[i] == True else 0 for i in range(len(is_outlier))]
cValue = [color[is_outlier[i]] for i in range(len(is_outlier))]
# print cValue
fig = plt.figure()
#ax1 = fig.add_subplot(111, projection='3d')
ax1 = fig.gca(projection='3d')
ax1.set_title('Scatter Plot')
ax1.set_xlabel('Height_cm')
ax1.set_ylabel('Weight_kg')
ax1.set_zlabel('Age')
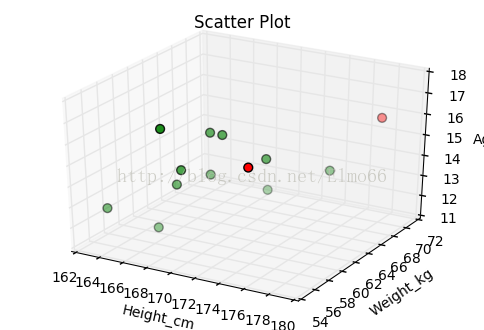
ax1.scatter(hw['Height_cm'], hw['Weight_kg'], hw['Age'], s=40, c=cValue)
plt.show()上面的代码根据马氏距离(也称广义平方距离)检测离群值得两个极端点。马氏距离可以解决n维空间数据,关于马氏距离的计算公式可参考其他资料,R和Python关于马氏距离求解的包在参数上以及计算结果的含义上略有不同(R计算结果是距离的平方,协方差矩阵默认可自动求逆,而Python计算结果默认就是马氏距离,但是参数中的协方差需自己求逆),这次右下角的点被捕捉到。
你可以通过这种方式移除掉5%的最有可能是异常点的数据
percentage_to_remove = 20 # Remove 20% of points
number_to_remove = round(len(hw) * percentage_to_remove / 100) # 四舍五入取整
m_dist_order = Series([float(distance.mahalanobis(hw.iloc[i], hw.mean(), np.mat(hw.cov().as_matrix()).I) ** 2)
for i in range(len(hw))]).sort_values(ascending=False).index.tolist()
rows_to_keep_index = m_dist_order[int(number_to_remove): ]
my_dataframe = hw.loc[rows_to_keep_index]
print my_dataframe Age Height_cm Weight_kg
3 17.0 168.0 56.0
1 12.0 167.0 57.0
0 13.0 164.0 55.0
11 14.0 176.0 66.0
6 16.0 169.0 61.0
8 13.0 172.0 64.0
7 16.0 170.0 61.0
5 14.0 169.0 61.0
4 15.0 169.0 57.0
2 14.0 168.0 58.0
9 15.0 173.0 62.0
警告
当你的数据表现出非线性关系关系时,你可要谨慎使用该方法了,马氏距离仅仅把他们作为线性关系处理。,例如下面的例子。
import pandas as pd
from sklearn import preprocessing
import numpy as np
from numpy import float64
from matplotlib import pyplot as plt
from scipy.spatial import distance
from pandas import Series
x = np.array([4, 8, 10, 16, 17, 22, 27, 33, 38, 40, 47, 48, 53, 55, 63, 71, 76, 85, 85, 92, 96], dtype=float64)
y = np.array([6, 22, 32, 34, 42, 51, 59, 63, 64, 69, 70, 20, 70, 63, 63, 55, 46, 41, 33, 19, 6], dtype=float64)
hw = {'x': x, 'y': y}
hw = pd.DataFrame(hw)
percentage_of_outliers = 10 # Mark 10% of points as outliers
number_of_outliers = round(len(hw) * percentage_of_outliers / 100) # 四舍五入取整
m_dist_order = Series([float(distance.mahalanobis(hw.iloc[i], hw.mean(), np.mat(hw.cov().as_matrix()).I) ** 2)
for i in range(len(hw))]).sort_values(ascending=False).index.tolist()
rows_not_outliers = m_dist_order[int(number_of_outliers): ]
my_dataframe = hw.loc[rows_not_outliers]
is_outlier = [True, ] * 21
for i in rows_not_outliers:
is_outlier[i] = False
color = ['g', 'r']
pch = [1 if is_outlier[i] == True else 0 for i in range(len(is_outlier))]
cValue = [color[is_outlier[i]] for i in range(len(is_outlier))]
fig = plt.figure()
plt.title('Scatter Plot')
plt.xlabel('x')
plt.ylabel('y')
plt.scatter(hw['x'], hw['y'], s=40, c=cValue)
plt.show()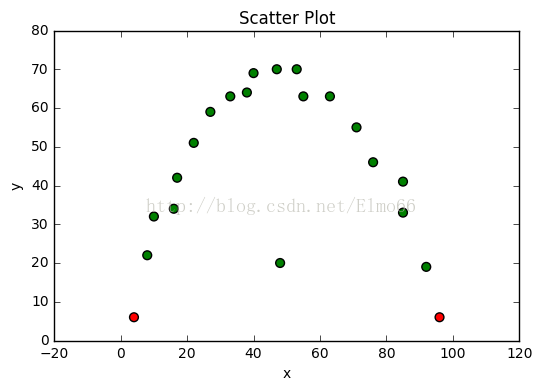
请注意,最明显的离群值没有被检测到,因为要考虑的数据集的变量之间的关系是非线性的。
注意,在多维数据中使用马氏距离发现异常值可能会出现与在一维数据中使用t-统计量类似的问题。在一维的情况下,异常值能很大程度上影响数据的平均数和标准差,t统计量不再提供合理的距离中心度量值。(这就是为什么使用中心和距离的测量总能表现的更好,如中位数和中位数的绝对差,对异常值检测更健壮。可以参考利用绝对中位差发现异常值。)作为马氏距离,类似t统计量,在高维空间中也需要计算标准差和平均距离。















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









