









简单语法总结【下】:续R语言学习笔记【简单语法总结-上】
七. 输入与输出
7.1 输出
7.1.1 print()函数
print()函数里面带有一些参数:
- digits指定每个数输出的有效数字位数。
- quote指定字符串输出是否带两边的括号。
- print.gap指定矩阵或数组输出是行列的距离。
7.1.2 cat()函数
cat()函数可以把多个参数连接起来再输出(类似于paste()函数)
#使用cat()是要加上换行符"\n"
cat(c("ab","C"),c("d","e"),"\n",sep="") #自定义分隔符,可以用sep="参数"
cat("i=",1,"\n",file="c:/cat.txt") #cat()可以指定一个参数”file=文件名“,把结果写到指定的文件中
7.1.3 format()函数
format()函数为一个数值型向量找到一种共同的显示形式,然后把向量转化为字符型
format(c(1,100,1000))
7.1.4 formatC()函数
函数formatC()对输入的向量的每一个元素单独进行格式转化而且不生成同一格式
formatC(c(1,1000,10000))

7.1.5 把矩阵x输出到文件中
write(t(x),file="文件名”,ncol=ncol(x))
- t(x)为将矩阵转置
- 如果不指定列数,默认为5列.
x=matrix(1:12,nrow=3,ncol=4);x
write(t(x),file="c:/input.txt",ncol=ncol(x))

7.1.6 把数据框d输出到文件中
用write.table(x,file="文件名’)
7.1.7 写入csv文件
write.table(data,file,sep)可以写成任意分隔符的文件
7.2 输入
cat(1:12,"\n",file="c:/RData/cat1.txt") #见统计计算45,这里不太懂
x=scan('c:/cat1.txt')
7.2.1 导入文本文件
7.2.1.1 使用read.table()函数导入带分隔符的文本文件
- file:需要读入的文件名或者路径
当需要读入的文件在R的工作目录下时,file=files.name,否则file=”文件的存储路径” - header:是否文件的读入第一行,默认值为FALSE
- sep: 文件中分开数据的分隔符:
①默认为sep=”“,表示分隔符为一个或多个空格、换行或回车
②若分隔符为逗号,则sep=”,”
③ 若为制表符,则sep=”\t” - quote:设置如何引用字符型变量。若没有分隔符,则quote=”\”
- row.names:用于指定行名的可选参数
- col.names:若header=F,用于指定列名的可选参数.如col.names=c(“name”,”English”)
- na.strings:用于表示缺失值的字符向量。默认为NA,也可自行定义表示缺失值的字符。
- colClasses:每一列的变量类型。如:colClasses=c(“numeric”,”character”)表示将第一列定义为数值型,第二列定义为字符型。
- skip=50:从第50行开始截取 ; nrows=2: 从第50行开始截取2行
- head(x,n=k):显示文件前k行。
7.2.1.2 读取excel文件(将excel文件改为逗号分隔的csv文件 )
a=read.table(file="c:/shuju.csv",sep=",",header=T);a
7.2.1.3 读取文本文件间隔为英文空格
a1=read.table("c:/1.txt",sep=" ",header=T);a1
class(a1) ##读入的数据都为数据框类型
7.2.1.4 读取文本文件间隔为逗号
a2=read.table("c:/2.txt",sep=",",header=T);a2
class(a2) ##读入的数据都为数据框类型
7.2.1.5 读取文本文件间隔为制表符
a3=read.table("c:/3.txt",sep="\t",header=T);a3
class(a3) ##读入的数据都为数据框类型
my.class=data.frame(read.csv(file.choose()))
class(my.class)
write.table(my.class,file="c:/input.txt")
read.table("c:/input.txt",sep=",")
7.2.1.6 读取csv文件(逗号分割的一种数据文件)
read.csv(file,header=T)
read.csv("c:/2.txt",header=T) #read.csv可以读取逗号分隔的文本文件
read.csv("c:/3.txt",header=T) #如果文本文件不是逗号分隔,会出现这样的情况
read.csv("c:/input.csv",header=T) #read.csv读取csv文件
a3=read.table("c:/shuju1.txt",sep="\t",header=T);a3
7.3 格式的相互转化
7.3.1 csv文件转成分隔符为空格
write.table(a1,"c:/11.txt",sep=" ")
7.3.2 csv文件转成分隔符为逗号
write.table(a2,"c:/22.txt",sep=",")
write.table(a2,"c:/22.txt",sep=",",col.names=FALSE)
7.3.3 csv文件转成分隔符为制表符
write.table(a3,"c:/33.txt",sep="\t")
write.table(a3,"c:/44.txt",sep="|_____|") #可以写成任意分隔符的文件
7.4 相关练习题:
题目:
#张三 女 14 156 42.0
#李四 男 15 165 49.0
#王五 女 16 157 41.5
#赵六 男 14 162 52.0
#丁一 女 15 159 45.5
将上述数据写成纯文本文件,用函数read.table()读该文件,然后再用函数write.csv()写成一个能用excel表能打开的文件,并用excel打开 。
1.将数据写入excel表格中,然后将excel表格转化为文本文件(制表符分隔) #不能直接在记事本输入数据,字符型变量将会曝错
2.然后利用:
- a3=read.table(“c:/RData/3.txt”,sep=“\t”,header=T);a3
- write.csv(a3,“c:/fivess.csv”,sep=“\t”)
八.作图
8.1 低水平作图
8.1.1 R语言创建多个图形
#每次创建一副新图形之前打开一个新的图形窗口
dev.new()
画图
dev.new()
画图
......
8.1.2 指定符号和线型的参数:
① pch 指定绘制点时使用的符号。

② cex 指定符号的大小。cex是一个数值,表示绘图符号相对于默认大小缩放的倍数。
③ lty 指定线条类型

④ lwd 指定线条宽度,默认值是1.
| 参数取值 | 描述 |
|---|---|
| 1 | 默认宽度 |
| k | 默认宽度的k倍 |
| -k | 默认宽度的1/k倍 |
8.1.3 与颜色相关的参数

8.1.4 文本属性

8.1.5控制图形储存和边界大小的参数

8.1.6 添加文本、自定义坐标轴和图例
- 标题main、
- 副标题sub、
- 坐标轴标签xlab,ylab、
- 坐标轴范围xlim,ylim(例如xlim=c(0,60))
#指定坐标轴范围
yield <- c(15.2, 16.9, 15.3, 14.9, 15.7, 15.1, 16.7)
plot(yield,xlim = c(1886,1890))# 指定输出横轴范围
plot(yield,ylim = c(15,16))# 指定输出纵轴范围
- plot、hist、boxplot函数可以自行设定坐标轴和文本标注参数,有的函数却不可以,需要借助相应的函数。
①标题
title()函数科一位图形添加各种标题和坐标轴标签,同时可以指定标题和坐标轴标签的打字奥,字体,颜色等。
②坐标轴
axis()函数可以创建自定义坐标轴,格式如下:
axis(side, at=, labels=, pos=, lty=, col=, las=, tck=, …)
各个参数的含义如下:

③lines() 函数可以为现有图形添加新的图形元素。
④abline()函数可用来为图形添加参考线。
⑤图例
legend()函数用来为图添加图例
8.1.7 一页多图的命令
在同一页面上绘制多张图用layout()函数;
在一幅图上添加新图,得到组合图用par()函数。
par(mfrow=c(3,2)) #同一页有3行2列,共6个图,而且次序为按行填放
par(mfcol=c(3,2)) #同一页有3列2行,共6个图,而且次序为按列填放
par(mfrow=c(1,1)) #取消一页多图
【注】:本部分部分引用自:原文链接:https://blog.csdn.net/u014458853/article/details/49948787
8.2 高水平作图
8.2.1 条形图 barplot()函数
barplot(height, names.arg = NULL, beside = FALSE,horiz = FALSE,density = NULL, angle = 45,col = NULL, border = par(“fg”), main =NULL, sub = NULL, xlab = NULL, ylab = NULL,xlim = NULL, ylim = NULL,…)
height:向量或矩阵,用来构成条形图中各条的数值。
names.arg:位于条低端的文字标签。
beside: 逻辑值,为FALSE时绘制堆叠图,为TRUE时绘制分组图。
horiz: 逻辑值,为FALSE时,绘制垂直条形图,为TRUE时绘制水平条形图。
density:一个向量值。当指定该值时,条将以斜线填充。即每英寸斜线的密度。
angle:以逆时针方向给出的阴影线的角度。默认为45度。
col:条的填充色。
border:条的边框颜色,如设置为TRUE时,边框颜色将于阴影线的颜色相同。
main:用于指定绘图的主标题。
sub:用于指定绘图的次标题。
xlab, ylab :用于指定x轴和y轴的标签。
xlim, ylim:分别用于指定x轴和y轴的取值范围。
a=read.table(file="c:/tiaoxing.csv",sep=",",header=TRUE);a
attach(a) #连接数据框
##画变量gender的简单垂直条形图
count=table(gender);count #gender的频数描述
barplot(count,main="simply bar plot",xlab="gender",ylab="frequency") #horiz:逻辑向量,FALSE是为垂直条形图
##画变量gender的简单水平条形图
count=table(gender);count #gender的频数描述
barplot(count,main="simply bar plot",xlab="gender",ylab="frequency",horiz=TRUE) #horiz:TRUE为水平条形图
##变量unit的累计条形图
count2=table(gender,unit);count2 #变量gender和unit的列联表
barplot(count2,col=c("red","green"),legend=rownames(count2),main="stacked bar plot",xlab="unit",ylab="frequency",beside=FALSE) #beside:逻辑向量,FALSE是为累计条形图,
##变量unit的分组条形图
count2=table(gender,unit);count2 #变量gender和unit的列联表
barplot(count2,col=c("red","green"),legend=rownames(count2),main="stacked bar plot",xlab="unit",ylab="frequency",beside=TRUE) #TRUE为分组条形图
##age的分组(gender)均值条形图
means=tapply(age,gender,mean);means #计算age按gender的分组的均值
barplot(means)
#一页多图
par(mfrow=c(2,3))
#绘制简单的条形图
math <- c(78, 92, 89, 61, 95)
barplot(math)
#添加x轴上的分类标签
math <- c(78, 92, 89, 61, 95)
names<-c("小刚", "小明", "小花", "小芳", "小丽")
barplot(math,names.arg=names)
#指定填充色,边框色,标题
math <- c(78, 92, 89, 61, 95)
names<-c("小刚", "小明", "小花", "小芳", "小丽")
barplot(math,names.arg=names,border="green",main="成绩",col=c("red","orange","lightblue","yellow","lightgreen"))
#绘制堆叠条形图
math <- c(78, 92, 89, 61, 95)
english <- c(90, 89, 95, 70, 98)
grade <- matrix(c(math,english),2,5)
names<-c("小刚", "小明", "小花", "小芳", "小丽")
barplot(grade,border="green",names.arg=names,main="成绩",xlab="姓名",ylab="成绩",legend=c("数学","英语"))
#绘制簇状(分组)条形图
math <- c(78, 92, 89, 61, 95)
english <- c(90, 89, 95, 70, 98)
grade <- matrix(c(math,english),2,5)
names<-c("小刚", "小明", "小花", "小芳", "小丽")
barplot(grade,names.arg=names,beside=TRUE,main="成绩",xlab="姓名",ylab="成绩",col=rainbow(10))#rainbow函数可以生成n个颜色向量

8.2.3 饼图 pie()函数
pie(x, labels = names(x), radius = 0.8,main= “NULL”, col = NULL, clockwise = FALSE,density = NULL, angle = 45, lty = NULL, border = NULL, edges = 200, ….)
-
x:非负数值向量,表示每个扇形的面积
-
labels:表示个扇形标签的字符型向量
-
col:颜色
-
radius 表示饼图的圆的半径,特别是在字符标签过长的情况尤其适用。
-
main 是用来表示图标的标题的。
-
clockwise 是一个逻辑值,用来指示饼图各个切片是否按顺时针做出分割。
-
density:底纹的密度。默认值为NULL。
-
angle:设置底纹的斜率。
-
edges设置多边形的边数(圆的轮廓是具有很多边的多边形近似)。
a=read.table(file="c:/tiaoxing.csv",sep=",",header=TRUE);a
attach(a)
count=table(gender);count
pie(count,main="simply pie chart") #简单饼图
pie(count,col=rainbow(2),main="simply pie chart") #通过rainbow()定义两种不同的颜色显示饼图
par(mfrow=c(2,2))
#简单的饼图
x <- c(10,20,30,40,50)
label <- c("Alabama","Alaska", "Arizona", "Arkansas", "California")
pie(x, labels = label)
# pie(x, labels = label, clockwise = TRUE)#这是按顺时针方向来绘制饼图
#为饼图添加标题和颜色
pie(x, labels=label, main="City pie chart", col=terrain.colors(length(x)))
# 在这里是用了terrain.colors这个颜色函数,也可以选择彩虹颜色col=rainbow(length(x))或者自定义的颜色
#饼图每个扇形的百分比以及添加图表图例,继续以上面的例子为例
x <-c(10,20,30,40,50)
label <-c("Alabama", "Alaska", "Arizona","Arkansas", "California")
piepercent<-round(100*x/sum(x), 1)
piepercent <-paste(piepercent, "%", sep = "")
pie(x,labels=piepercent, main="City pie chart",col= terrain.colors (length(x)))
legend("topright",label, cex=0.8, fill=terrain.colors(length(x)))
#发现右边的文本标签离饼图比较远,有一个比较好的设置标签的位置的方法是用locator()参数,你可以再你想要的位置处双击鼠标即可,代码如下
pie(x,labels=piepercent, main="City pie chart",col= terrain.colors(length(x)))
legend(locator(1),label, cex=0.8, fill=terrain.colors(length(x)))

8.2.4 3D饼图
用plotrix packages 绘制3D 饼图
饼图和3个维度需要使用额外的软件包绘制。软件包:plotrix 称为 pie3D。没有的话需要先安装。
install.packages("plotrix")
library(plotrix)
pie的3D图由以下函数创建:
pie3D(x, main, labels,explode, radius, height…)
- main:饼图主标题
- labels:各个“块”的标签
- explode:各个“块”之间的间隔,默认值为0
- radius:整个“饼”的大小,默认值为1,0~1为缩小
- height:饼块的高度,默认值为0.1
x <- c(10,20,30,40,50)
label <- c("Alabama","Alaska", "Arizona", "Arkansas", "California")
install.packages("plotrix")
library(plotrix)
pie3D(x,labels=label,explode=0.1,main="PieChart of Countries ")

8.2.5 扇形图(fan plot)
有时候饼图会让各个切块的面积比较比较困难,所以为改善这种状况,我们创造了一种成为扇形图(fan plot)的饼图变种,扇形图(Lemon & Tyagi, 2009)为用户提供了一种同时展示相对数量和相互差异的方法。在R中,扇形图是通过plotrix包中的fan.plot()函数实现的。
install.packages("plottrix")
library(plotrix)
fan.plot(x,labels = label, main="Fan Plot",col= terrain.colors (length(x)))#可使用函数内置的颜色
legend("topright",label, cex=0.4, fill= terrain.colors (length(x)))

8.2.6 plot()函数
plot函数默认的使用格式如下:
- plot(x, y = NULL, type = “p”, xlim = NULL, ylim = NULL, log = “”, main= NULL, sub = NULL, xlab = NULL, ylab = NULL, ann = par(“ann”), axes = TRUE, frame.plot = axes, panel.first = NULL, panel.last = NULL, asp =
NA, …)
- type为一个字符的字符串,用于给定绘图的类型,可选的值如下:
“p”:绘点(默认值);
“l”:绘制线;
“b”:同时绘制点和线;
“c”:仅绘制参数"b"所示的线;
“o”:同时绘制点和线,且线穿过点;
“h”:绘制出点到横坐标轴的垂直线;
“s”:绘制出阶梯图(先横后纵);
“S”:绘制出阶梯图(先纵后竖);
“n”:作空图。- main参数
字符串,给出图形的标题;- sub参数
字符串,给出图形的子标题- xlab参数
字符串,用于给出x轴的标签。- ylab参数
字符串,用于给出y轴的标签。- xlim参数
二维向量,表示x轴的范围。- ylim参数
二维向量,表示y轴的范围。
8.2.6.1 散点图
plot(x=x轴数据,y=y轴数据,main="标题",sub="子标题",type="线型",xlab="x轴名称",ylab="y轴名称",
xlim = c(x轴范围,x轴范围),ylim = c(y轴范围,y轴范围))
- x,y是数值型向量
- type:指定所绘制图形的类型:
①type=“p”:只有点
②type=“l”:只有线
③type=“o”:实心点和线(即线覆盖在点上)
④type=“b”:线连接点 (折线图 )
⑥ type=“h”:从点到横轴画直线,类似直方图的线:
⑦ type=“s”:阶梯函数:左连续
⑧ type=“S”:阶梯函数:右连续
⑨ type=“n”:不生成任何点和线,适用于后面介绍的低级图形函数作图统计计算66页
⑩type=“c”#点线图去掉点 - xlab,ylab:x,y轴的标签
- main,sub:主标题,图形的小标题
a=read.table(file="c:/realdata.csv",sep=",",header=TRUE);a
b=a[,2:7]
c=as.matrix(b)
plot(c[,1],type="l")
lines(c[,2],type="l",col="red") #低级图形函数
lines(c[,3],type="l",col="yellow")
lines(c[,4],type="l",col="blue")
lines(c[,5],type="l",col="orange")
lines(c[,6],type="l",col="green")
8.2.6.2 折线图 plot(x,y.type=“b”)函数
a=read.table(file="c:/RData/my.class.csv",sep=",",header=TRUE);a
attach(a)
plot(Weight,Height,type="b") #type="b"时折线图的标志
x <- 1:10
beijing <- round(rnorm(10,mean = 20 , sd = 2),1)
shanghai <- round(rnorm(10,mean = 20 , sd = 3),1)
guangzhou <- round(rnorm(10,mean = 20 , sd = 1),1)
plot(x,beijing,type = 'l',ylim = c(16,30),lwd = 2,main = "北京上海和广州最近十天的气温变化趋势")
lines(x,shanghai,type = 'l',col = 'blue',lwd = 2)
lines(x,guangzhou,type = 'l',col = 'red', lwd = 2)

8.2.8 箱线图: boxplot()函数
箱线图或箱形图是由5个特征值绘制而成的图形,其有一个箱子和两条线段组成。5个特征值是变量的最大值、最小值、中位数、第一四分位数和第三四分位数。连接两个分位数画出一个箱子,箱子用中位数分割,把两个极值点与箱子用线条连接,即成箱线图。箱线图的形式如下图所示:

【注】:此图来源于网络
boxplot函数的基本用法为:
boxplot(x, …)
公式形式的用法
boxplot(formula, data = NULL, …, subset, na.action = NULL, drop = FALSE, sep = “.”, lex.order = FALSE)
默认用法:
boxplot(x, …, range = 1.5, width = NULL, varwidth = FALSE,notch = FALSE, outline = TRUE, names, plot = TRUE,border = par(“fg”), col = NULL, log = “”,pars = list(boxwex = 0.8, staplewex = 0.5, outwex = 0.5),horizontal = FALSE, add = FALSE, at = NULL)
主要参数的含义:
- x: 向量,列表或数据框。
- formula: 公式,形如y~grp,其中y为向量,grp是数据的分组,通常为因子。
- data: 数据框或列表,用于提供公式中的数据。
- range: 数值,默认为1.5,表示触须的范围,即range × (Q3 - Q1)
- width: 箱体的相对宽度,当有多个箱体时,有效。
- varwidth: 逻辑值,控制箱体的宽度, 只有图中有多个箱体时才发挥作用,默认为FALSE, 所有箱体的宽度相同,当其值为TRUE时,代表每个箱体的样本量作为其相对宽度
- notch: 逻辑值,如果该参数设置为TRUE,则在箱体两侧会出现凹口。默认为FALSE。
- outline: 逻辑值,如果该参数设置为FALSE,则箱线图中不会绘制离群值。默认为TRUE。
- names:绘制在每个箱线图下方的分组标签。
- plot : 逻辑值,是否绘制箱线图,如设置为FALSE,则不绘制箱线图,而给出绘制箱线图的相关信息,如5个点的信息等。
- border:箱线图的边框颜色。
- col:箱线图的填充色。
- horizontal:逻辑值,指定箱线图是否水平绘制,默认为FALSE。
a=read.table(file="c:/my.class.csv",sep=",",header=TRUE);a
attach(a)
boxplot(Weight,Height)
boxplot.stats(Weight) #输出用于构造图形的统计量,中位数是107.25,最大值是133,最小值是50.5
par(mfrow=c(2,3))
#简单的使用
h<-c(144,166,163,143,152,169,130,159,160,175,161,170,
146,159,150,183,165,146,169)
boxplot(h)
#********************
#多组的箱线图
#题目:
#某工厂推行新的工作方法,实验组和对照组(原方法)的工作效率(每小时产量),如下面的数据:
#试验组:35, 41, 40, 37, 43, 32, 39, 46
#对照组:32, 39, 34, 36, 32, 38, 34, 31
#绘制其箱线图。
#程序如下:
x <- c(35, 41, 40, 37, 43, 32, 39, 46, 32, 39, 34, 36, 32, 38, 34, 31)
f <- factor(rep(c("试验组","对照组"),each=8))
data<- data.frame(x,f)
boxplot(x~f,data)
#width参数的效果
x <- c(35, 41, 40, 37, 43, 32, 39, 46, 32, 39, 34, 36, 32, 38, 34, 31)
f <- factor(rep(c("试验组","对照组"),each=8))
data<- data.frame(x,f)
boxplot(x~f,data,width=c(1,2),ylab="工作效率(个/小时)")
#箱体颜色
x <- c(35, 41, 40, 37, 43, 32, 39, 46, 32, 39, 34, 36, 32, 38, 34, 31)
f <- factor(rep(c("试验组","对照组"),each=8))
data<- data.frame(x,f)
boxplot(x~f,data,width=c(1,2),col=c(2,3),border=c("darkgray","purple"))
#带凹口的箱线图
x <- c(35, 41, 40, 37, 43, 32, 39, 46, 32, 39, 34, 36, 32, 38, 34, 31)
f <- factor(rep(c("试验组","对照组"),each=8))
data<- data.frame(x,f)
boxplot(x~f,data,width=c(1,2),col=c(2,3),notch=TRUE)

计算五数总括
最有代表性,最能反应数据重要特征的5个数为:中位数,下四分位数,上四分位数,最小值,最大值。
用 fivenum()函数来计算样本的五数总括,格式如下:
fivenum(x,na.rm = TRUE)
- x为样本数据
- na.rm为逻辑变量,为TRUE(默认值)时,在计算五数总括前,所有NA,NAN数据将被去除。
x <- c(runif(8));x
fivenum(x)

8.2.9 茎叶图 stem() 函数
stem(x, scale = 1, width = 80, atom = 1e-08)
- 参数x: 是数值向量,用于绘制茎叶图的数据。
参数scale: stem函数中的scale参数控制茎叶图的长度,默认为1。
【注】:sacle设置的越大,分茎越多,精度越高,如果你的scale较小,他甚至会自动帮你的数据做四舍五入(这样会降低精度)- width参数
控制茎叶图中叶子的宽度,如果为0,则只输出该茎统计的数字个数。如果为10以内的数,则表示超过指定宽度的统计数量个数,下面的例子可以理解为,统计频数比0多的数,多几个就加几。当width设置的足够大,就可以将所有的数字显示全了,默认为100.
#某人对自己上班时间的开车速度进行了统计,统计12次的数据如下(km/h):
#30,33,18,27,32,40,26,28,21,28,35,20
v<-c(30,33,18,27,32,40,26,28,21,28,35,20)
stem(v)
stem(v,scale=0.8)
stem(v,scale=1,width=90)

分析:
图中位于“|”右边的数字是1位数字构成的,绘制的茎叶图默认0-4一组,5-9一组。则可以看出,位于[10,20)区间的有1个:18;位于[20,30)区间的有6个;位于[30,40)区间的有4个:30,32,33,35;位于[40,50)区间的有1个:40.
10~ 20之间有1个,2025之间有2个,2530之间有4个…
stem(Height)
8.2.10 直方图:hist() 函数
估计数值型变量的分布密度,可以用hist()画直方图&用density()进行非参数密度估计。
hist(x, breaks = “Sturges”, freq = NULL, probability = !freq,include.lowest = TRUE, right = TRUE, density = NULL, angle = 45, col =NULL, border = NULL, main =paste(“Histogram of” , xname), xlim = range(breaks), ylim = NULL, xlab = xname, ylab, axes = TRUE, plot = TRUE, labels = FALSE, nclass = NULL, warn.unused = TRUE, …)
- x:由一个数据值组成的数值向量
- freq:逻辑向量,为TRUE时为频数绘制图形,为FALSE时为概率密度绘制图形。当仅当breaks为等距,且为指定probability时,freq默认为TRUE。
- col:指定填充直条的颜色
- xlab:x轴标签
- ylab:y轴标签
- breaks:直方图的断点,主要有以下几种情况:
①可以是一个向量给出直方图中每个区间的断点;
②可以是一个函数用于计算每个断点的向量;
③用于表示区间数的一个数字;
④一个字符串用于给出计算区间数所使用的算法;
⑤一个用于计算区间数的函数。- probability:与!freq的含义相同。
- include.lowest : 逻辑值,如果为TRUE,则如果数据x[i]等于断点值,则会包含在第一个区间条中(如right参数为FALSE,则会包含在下一个区间中)。除非breaks是向量,否则设置会被忽略并给出一个警告错误。
- right
逻辑值。如果设置为TRUE,则直方图条右侧区间是封闭的(左侧开放)。- density
指阴影线的密度,即每英寸(2.54厘米)的线数。默认值为NULL值,意味着没有阴影线。非正值也不会绘制阴影线。- angle
指阴影线的斜度,以逆时针角度给出。默认为45度。
.>- col
填充条形使用的颜色。默认值为NULL,即没有填充色。- border
数字或字符串,用于描述条形边框的颜色。默认为NULL,即使用标准前景色。- main, xlim, ylim, xlab, ylab
见本站关于plot函数中的说明(R语言中plot函数的使用)- axes
逻辑值。默认为TRUE,绘图时绘制轴。- labels
逻辑值。默认为FALSE,如果为TRUE,则在条形框的顶端给出标签(频数或密度)。
a=read.table(file="c:/RData/tiaoxing.csv",sep=",",header=TRUE);a
attach(a)
summary(age) #变量的基本描述结果,最小值、第25百分位数,中位数,第75百分位数,最大值
hist(age) #简单直方图
hist(age,breaks=12,col="red") #组数为12的直方图
hist(age,breaks=12,col="red",freq=FALSE)
rug(jitter(age)) #轴须线
lines(density(age),col="blue") #密度曲线
par(mfrow=c(2,2))
#1
Height<-c(144,166,163,143,152,169,130,159,160,175,161,170,146,159,150,183,165,146,169)
hist(Height,col="lightblue",border="red",labels=TRUE,ylim=c(0,7.2))
#2
hist(Height,breaks=12,freq=FALSE,density=10,angle=60)
#3
data <- c(rep(1, 10), rep(2, 5), rep(3, 6))
hist(data, breaks = c(0.5, 1.5, 2.5, 3.5))

8.2.11 核密度图
核密度估计是在概率论中用已知的样本来估计未知的密度函数,属于非参数检验方法之一。
density(x, bw = “nrd0”, adjust = 1, kernel = c(“gaussian”, “epanechnikov”, “rectangular”,“triangular”, “biweight”, “cosine”, “optcosine”),weights = NULL, window = kernel, width, give.Rkern = FALSE,n = 512, from, to, cut = 3, na.rm = FALSE, …)
- X:我们要进行核密度估计的数据,由样本构成的向量。
- Bw:带宽,bw为默认值时,R会画出光滑曲线。这里可以由我们自己制定,也可以使用默认的办法nrd0: Bandwidth selectors for Gaussian kernels。我们还可以使用bw.SJ(x,nb = 1000, lower = 0.1 * hmax, upper = hmax, method = c(“ste”,“dpi”), tol = 0.1 * lower),这里的method =”dpi”就是前面提到过的插入法,”ste”代表solve-the-equationplug-in,也是插入法的改进
- Kernel:核的选择
- Weights:对比较重要的数据采取加权处理
#以faithful数据集为例说明density的用法:
#R数据集faithful是old faithful火山爆发的数据,其中“eruption”是火山爆发的持续时间,waiting是时间间隔.
#对数据“eruption”做核密度估计
data(faithful)
A<-faithful
x<-A[,"eruptions"]
density(x)
plot(density(x))

par(mfrow=c(1,2))
data(faithful)
A<-faithful
attach(A)
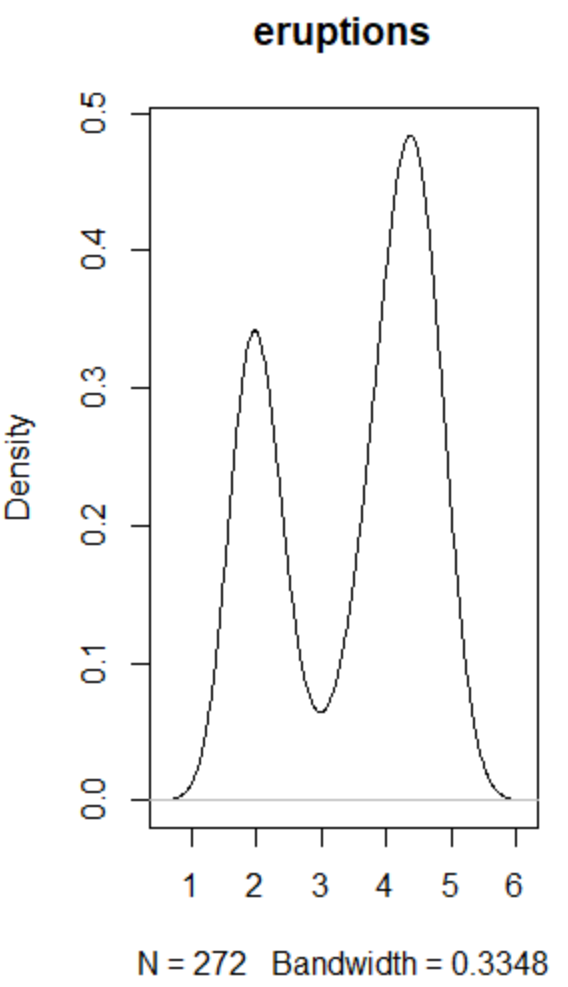
plot(density(eruptions),main="eruptions")
#把核密度曲线加到直方图上
h1 <- hist(eruptions,prob=T,plot=T) $ density
h2 <- density(eruptions)
hist(eruptions,prob=T,ylim=range(h1,h2 $ y))
lines(h2)
a=read.table(file="c:/tiaoxing.csv",sep=",",header=TRUE);a
attach(a)
dd=density(age)
plot(dd)
8.2.12 Q-Q图
无论是直方图还是经验分布图,要从比较上鉴别样本是否处近似于某种类型的分布是困难的。
QQ图可以帮我们鉴别样本的分布是否近似于某种类型的分布。
Q-Q图主要用于检验数据分布的相似性,如果要利用Q-Q图来对数据进行正态分布的检验,则可以令x轴为正态分布的分位数,y轴为样本分位数,如果这两者构成的点分布在一条直线上,就证明样本数据与正态分布存在线性相关性,即服从正态分布。
#首先安装画图的package叫做qqman:
install.packages('qqman')
library(qqman)
#简单实现qq图
#输入为一个vector,我们以a <- seq(1, 250, 1)做为示例数据
dev.new()
a <- seq(1, 250, 1)
#利用qqnorm函数直接绘制出了如下正态检验qq图
qqnorm(a)
#进一步使用qqline命令在qq图上加上标准直线
qqline(a, col=2, lwd=2) # 设置为红色加粗
#注:qqline的默认算法为向量a上四分位数和下四分位数对应两个点的连线

8.2.12.1 qqnorm()函数
qqnorm()可以直接绘制正态分布检验的qqplot,结果大致呈一条直线则说明大致服从正态分布
qqnorm(age) #qqnorm(x)对向量做正态概率(纵轴为次序统计量,横轴为对应次序统计量的标准正太分位数
qqline(age) #qqline(x)在qqnorm(x)图上画一条拟合曲线
qqplot(Height,Weight) #qqplot(x,y)把x和y的次序统计量分别画在x轴和y轴上以比较这两个变量的分布
set.seed(100)
qqnorm(rnorm(200))

8.2.12.2 qqline()函数
作用:在qq图上加上标准直线
8.2.13 curve()函数:绘制常见函数曲线
curve函数语法格式如下:
curve(expr, from = NULL, to = NULL, n = 101, add =FALSE, type = “l”, xname = “x”, xlab = xname, ylab = NULL, log = NULL,xlim = NULL, …)
主要的参数如下:
expr:函数名称或一个关于变量x的函数表达式;
from,to:表示绘图的起止范围;
n:一个整数值,表示x取值的数量;
add:是一个逻辑值,当为TRUE时,表示将绘图添加到已存在的绘图中;
type:与plot函数中type含义相同;
xname:用于x轴变量的名称。
xlab,ylab:x轴和y轴的标签名称。
par(mfrow=c(3,3))
#绘制y=x
curve(x+0, -10, 10, bty="l", xlab="x1", ylab="y")
abline(h=0, v=0, lty=2, col="gray")
text(0.5, -0.5, "0", col="gray")
text(8, 10, "y = x")
# 绘制y= 2x + 3
curve(2*x + 3, -10, 10, bty="l", xlab = "x", ylab = "y", asp = 1)
abline(h=0, v=0, lty=2, col = "darkgray")
text(0.8, -0.8, "0", col = "darkgray")
text(15, 20, "y = 2x + 3")
#*********************************
# 绘制形如y = ax2 + bx + c的图像
#y=x^2
curve(x^2,-5,5,bty="l",xlab="x",ylab="y",asp=1,ylim=c(-5,25))
abline(h=0,v=0,lty=2,col="darkgray")
text(0.8,-0.8,"0",col="darkgray")
text(7,23,expression(paste("y = ",x^2)))
#y=x^2+3x+1
curve(x^2+3*x+1,-10,5,col="blue",add=T)
text(8,25.5,expression(paste("y = ",x^2," + 3x + 1")),col="blue")
abline(v= -b/(2*a),col="lightblue",lty=2)
#*********************************
# 绘制幂函数图像
下面的程序代码给出的是形如y = xα的图像。
# y = x
curve(x^1,-1.5,2,bty="l",xlab="x",ylab="y",asp=1,ylim=c(-1,1))
abline(h=0,v=0,lty=2,col="darkgray")
text(0.1,-0.1,"0",col="darkgray")
lines(c(0,1,1),c(1,1,0),lty=2,col="red")
text(1.1,0.95,"1",col="red")
#y = x ^ 2
curve(x^2,-1.5,2,add=T,col="blue")
#y = x ^ 3
curve(x^3,-1.5,2,add=T,col="orange")
#y = x ^ (1/2)
curve(x^(1/2), 0,2,add=T,col="green")
#y = x ^ (1/3)
curve(x^(1/3), 0,2,add=T,col="darkgreen")
#*********************************
# 绘制指数函数
下面程序代码绘制的是形如 y = ax的函数图像。
curve(2^x,-3,3,bty="l",xlab="x",ylab="y",asp=1,ylim=c(-0.5,8))
abline(h=0,v=0,lty=2,col="darkgray")
text(0.2,-0.15,"0",col="darkgray")
curve(4^x,-3,3,bty="l",add=T,col="blue")
curve((1/2)^x,-3,3,bty="l",add=T,col="red")
curve((1/4)^x,-3,3,bty="l",add=T,col="green")
curve(exp,-3,3,bty="l",add=T,col="orange")
#*********************************
# 绘制对数函数图像
绘制形如 y = loga(x)的函数图像
curve(log(x,2),0,10,bty="l",xlab="x",ylab="y",asp=1,ylim=c(-3,5))
abline(h=0,v=0,lty=2,col="darkgray")
text(0.15,-0.15,"0",col="darkgray")
curve(log(x),0,10,bty="l",add=T,col="orange")
curve(log(x,10),0,10,bty="l",add=T,col="blue")
curve(log(x,0.5),0,10,bty="l",add=T,col="green")
curve(log(x,0.1),0,10,bty="l",add=T,col="red")
#其中,橘黄色的曲线是y = ln(x)的函数图像。
#*********************************
# 绘制三角函数图像
#(1)正弦与余弦函数
#sin(x)
curve(sin(x),-10,10,bty="l",xlab="x",ylab="y",asp=1)
#cons(x)
curve(cos,-10,10,add=T,col="blue")
#下面是绘制坐标轴和图中红色的线及标签
abline(h=0,v=0,lty=2,col="darkgray")
text(0.5,-0.5,"0",col="darkgray")
lines(c(-pi,-pi),c(1.5,-1.5),col="red",lty=3)
text(-pi,2.5,expression(-pi),col="darkgray")
lines(c(-pi/2,-pi/2),c(1.5,-1.5),col="red",lty=3)
text(-pi/2,2.5,expression(-frac(pi,2)),col="darkgray")
lines(c(pi/2,pi/2),c(1.5,-1.5),col="red",lty=3)
text(pi/2,2.5,expression(frac(pi,2)),col="darkgray")
lines(c(pi,pi),c(1.5,-1.5),col="red",lty=3)
text(pi,2.5,expression(pi),col="darkgray")
#(2)正切函数
curve(tan,-2*pi,2*pi,col="red",ylim=c(-6,6),asp=1)
abline(h=0,v=c(-pi,-pi/2,0,pi/2,pi),lty=2,col="darkgray")
text(c(-pi+0.5,-pi/2+0.5,0.5,pi/2+0.5,pi+0.5),-0.5,
c("-π","-π/2",0,"π/2","π"),col="darkgray")
#(3)余切函数
#在R的默认基础库中没有提供余切函数,但是可以根据余切与正切的关系来绘制。余切等于正切的倒数。
#下面的代码是绘制余切函数:
curve(1/tan(x),-2*pi,2*pi,col="blue",ylim=c(-6,6),asp=1)
abline(h=0,v=c(-pi,-pi/2,0,pi/2,pi),lty=2,col="darkgray")
text(c(-pi+0.5,-pi/2+0.5,0.5,pi/2+0.5,pi+0.5),0.5, c("-π","-π/2",0,"π/2","π"),col="darkgray")

九.一些零碎知识的补充
1.清空内存操作
ls() #查看
rm(list = ls())
gc()
ls() #产看是否清空完毕
【注】:本文部分内容来自:翔宇亭IT乐园
















 2768
2768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









