






1.前言
作为一个十余年来快速发展的崭新领域,深度学习受到了越来越多研究者的关注,它在特征提取和模型拟合上都有着相较于浅层模型显然的优势。深度学习善于从原始输入数据中挖掘越来越抽象的分布式特征表示,而这些表示具有良好的泛化能力。它解决了过去人工智能中被认为难以解决的一些问题。且随着训练数据集数量的显著增长以及芯片处理能力的剧增,它在目标检测和计算机视觉、自然语言处理、语音识别和语义分析等领域成效卓然,因此也促进了人工智能的发展。
2.CNN的热潮
2006 年,Hinton等人在《Science》上发文,其主要观点有:1)多隐层的人工神经网络具有优异的特征学习能力;2)可通过“逐层预训练”(layer-wise pre-training)来有效克服深层神经网络在训练上的困难,从此引出了深度学习(DeepLearning)的研究,同时也掀起了人工神经网络的又一热潮。
3.CNN的核心思想
CNN的提出是为了解决多层感知机梯度发散、全连接导致的参数过多引起的模型的问题。其引入三个核心思想:
- 局部感知共享(Local field)
- 权值共享(Shared Weights)
- 下采样(Subsampling)
3.1 局部感知
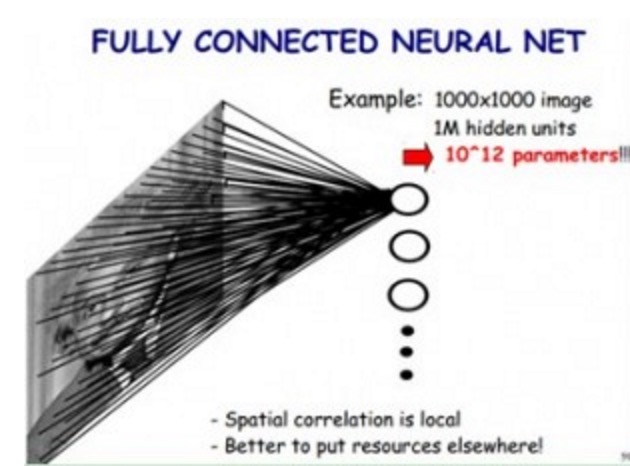
假如,传统神经网络方式,对一张图片进行分类,那么,我们把图片的每个像素都连接到隐藏层节点上,那么对于一张1000x1000像素的图片,如果我们有1M隐藏层单元,那么一共有10^12个参数,这显然是不能接受的。
神经网络的局部感知特性如同模仿人的眼睛寻找屋子里的东西,我们的目是是聚焦在一个个的物体上(屋子的局部)通过不停的扫描屋子其他地,从而找到我们想要的东西。
隐藏层的每个神经元仅与图像中 10∗10的局部图像相连接,那么此时的权值参数数量为 10∗10∗10^6直接减少4个数量级。

3.2 权值共享
尽管局部感知使计算量减少了几个数量级,但权重参数数量依然很多。能不能再进一步减少呢?方法就是权值共享。权值共享即不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权值参数。
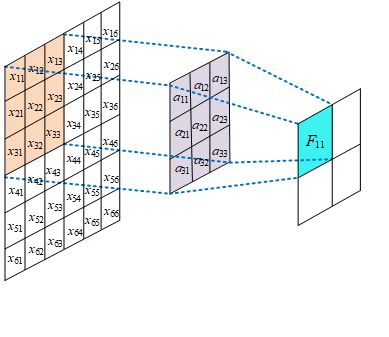
一个m*m的卷积核在图像上扫描,进行特征提取,如果通道数为k,那么参数总量为m * m * K.如过不进行权值共享,就会变成下图:
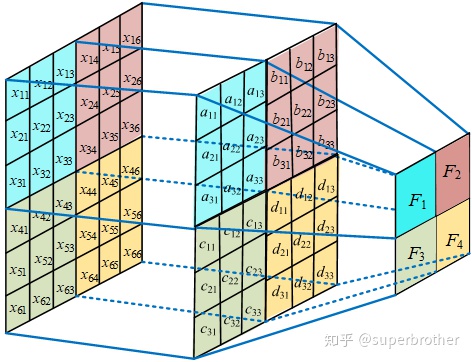
卷积核的参数数量与图像像素矩阵的大小保持一致,即W * H * K
例如:Inception V3的输入图像尺寸是192*192。如果把第一层3 * 3 *32的卷积核权值不共享,那么参数就为192 * 192 *32,约120W参数,是原来288的 4096倍。
3.2下采样
卷积运算又叫做互相关运算,目的是对输入图像进行下采样,从而压缩原始图像,到达减少参数的效果。在下图中,一个二维输入数组和一个二维核(kernel)数组通过互相关运算输出一个二维数组。
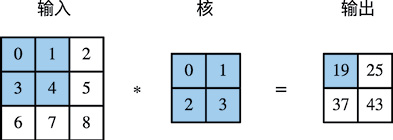
基本的二维卷积运算如方程式所示,假设某个信号的样本矩阵为x。滤波器w的大小为U * V,则v输出y是信号序列x和滤波器w的卷积。不同的滤波器w可以提取出信号样本不同的信息。这里假设卷积的输出y的下标(i,j) 从(U,V)开始。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gKfyAdni-1636446155283)(C:\Users\10722\AppData\Roaming\Typora\typora-user-images\image-20211105153440668.png)]
4.CNN的缺点
-
输出的每个通道信息是由输入特征的所有通道信息聚合而来,并且信道之间参数不共享,所以导致参数量较大;
-
有相关研究指出不同输出通道对应的卷积滤波器之间存在信息的冗余,因此对每个输出通道都使用不同的卷积核,效率低下;
-
池化层会丢失大量有价值信息,忽略局部与整体之间关联性;
-
当网络层次太深时,采用反向传播修改参数会使靠近输入层的参数改动较慢;
,忽略局部与整体之间关联性; -
当网络层次太深时,采用反向传播修改参数会使靠近输入层的参数改动较慢;
-
采用梯度下降算法很容易使训练结果收敛于局部最小值而非全局最小值;















 4749
4749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









