







真秘籍了这波,是我考前一星期的整理所得,从考点出发,逐步展开。
计算机算法:枚举、排序、搜索、计数、贪心、动态规划、图论、数论、字符串算法等。
数据结构:数组、对象/结构、字符串、队列、栈、树、图、堆、平衡树/线段树等。





Python使用sys包下的stdin与stdout
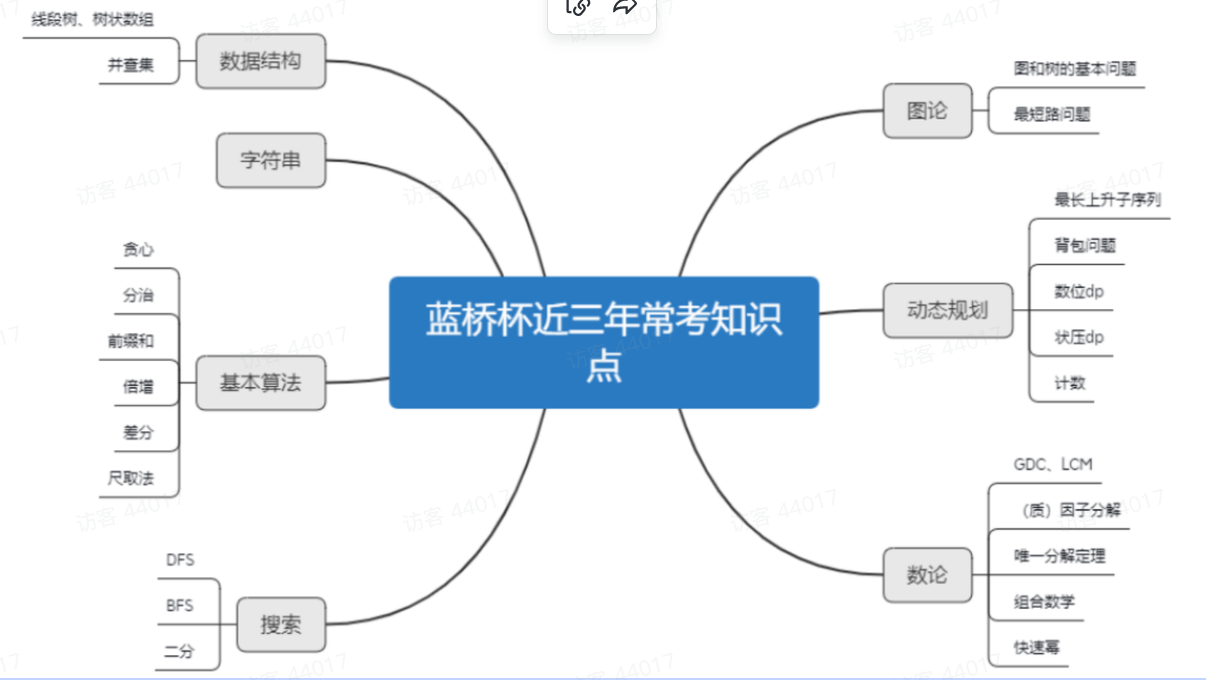
知识点
Python 内置函数 | 菜鸟教程这些好好看看
1. 基础算法
a. 枚举
enumerate()函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在for循环中。
>>> seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 two
2 threeb. 位运算
| | | 或 |
| & | 与 |
| ^ | 按位异或 |
| ~ | 取反 |
| >> | 右移 |
| << | 左移 |
ⅰ. “A B有一个为真 但不同时为真” 的运算称作异或 xor ^操作
ⅱ. 凡是 2的幂次方,其二进制数的某一高位为 1,并且仅此高位为 1,其余位都为 0
c. 双指针
d. 一维二维前缀和
e. 差分
f. 贪心
g. 模拟
h. 二分
ⅰ. bisect库
对有序数组进行查找,bisect 是 Python 内置的一个二分查找库,功能是查找给定值在一个有序列表中的插入位置,插入该值后,列表仍然保持有序。
| bise 二分法查找x 获取并返回插入的位置 |
| 能保证有序的最左边的插入位置 |
|
| 有序的最右边的插入位置 | |
| insort 二分法插入x 将待插入元素插入到给定列表中 |
| |
|
|
import bisect
>>> sorted_list = [1, 3, 3, 5, 7, 9]
>>> insert_point = bisect.bisect_left(sorted_list, 5)
>>> print(f"元素5的插入点:{insert_point}")
元素5的插入点:3
>>> sorted_list
[1, 3, 3, 5, 7, 9]i. 高精度
2. 排序
sort()函数
list.sort(cmp=None, key=None, reverse=False)
- key:指定可迭代对象中的一个元素来进行排序。
- reverse = True 降序, reverse = False 升序(默认)
排序算法:
冒泡,选择,插入,归并,快速,桶,堆,基数
3. 搜索
dfs,bfs,剪枝,双向bfs,记忆化搜索,迭代加深搜索,启发式搜索
4. dp
一维,线性,背包,区间,树形,状压,数位(速成),最长上升子序列,计数
5. 字符串
哈希,字典树,可以输出-1
6. 数学
初等数论,排列组合,
数论:gcd,lcm,质因子分解,唯一分解定理,素数筛,组合数字,快速幂,逆元,exgcd
- gcd:最大公约数
递归原理:GCD(a,b) = GCD(b,a%b)
math.gcd(3, 6)- lcm:最小公倍数
lcm(a,b) = ab/gcd(a,b)
math.lcm(3, 6)- exgcd
def ext_gcd(a, b): #扩展欧几里得算法
if b == 0:
return 1, 0, a
else:
x, y, gcd = ext_gcd(b, a % b) #递归直至余数等于0(需多递归一层用来判断)
x, y = y, (x - (a // b) * y) #辗转相除法反向推导每层a、b的因子使得gcd(a,b)=ax+by成立
return x, y, gcd- 分解质因数
质数:因子只有1和自己
def prime_factor(num):
factors = []
i = 2
while i * i <= num:
if num % i == 0:
factors.append(i)
num = num // i
else:
i += 1
if num > 1:
factors.append(num)
return factors- 素数筛
素数肯定没有因子,所以对每个数寻找是否有因子
## 自定义函数
def prime(n):
for i in range(2, n):
if n % i == 0: return False
return True
# 找出所有 <= m 的素数
m = 29
primes = [n for n in range(2, m + 1) if prime(n)]
## 结果
print(primes)- 排列组合
math库
| perm(n,k) | 排列数P = n! / (n - k)! |
| comb(n,k) | 组合数C = P / k! |
- 前n项平方和
![]()
7. 数据结构
优先队列,单调队列duque队列,二维单调队列,线段树、树状数组,并查集
a. 优先队列
入队操作出队操作
使用heapq
import heapq
a = []
heapq.heappush(a,18)# 添加堆节点
heapq.heapify(list)# 原地小根堆化
heapq.heappop(h)# 从堆中弹出并返回最小的值
heapq.merge(list,list)合并多个堆然后输出
heapq.nlargest(5,a)# 最大前5
heapq.nsmallest(1,b,key=lambda x:x[1])# 最小Python 中的 heapq 模块提供了优先队列算法。函数 heapq.heappush() 用于在队列 queue 上插入一个元素。heapq.heappop() 用于在队列 queue 上删除一个元素。
需要注意的是:heapq.heappop() 函数总是返回「最小的」的元素。所以我们在使用 heapq.heappush() 时,将优先级设置为负数,这样就使得元素可以按照优先级从高到低排序, 这个跟普通的按优先级从低到高排序的堆排序恰巧相反。这样做的目的是为了 heapq.heappop() 每次弹出的元素都是优先级最高的元素。
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
size = len(nums)
q = [(-nums[i], i) for i in range(k)]
heapq.heapify(q)
res = [-q[0][0]]
for i in range(k, size):
heapq.heappush(q, (-nums[i], i))
while q[0][1] <= i - k:
heapq.heappop(q)
res.append(-q[0][0])
return res
8. 图论
值得冲刺(背了忘了没关系,保两天就行)
求单个起点单个终点的最短路:
dijkstra 正权(普通的和堆优化的)以及起点到终点的最短路 →→ 起点到终点的最长边长度多少或最短边长度多少。(4星)
bellman-ford 负权 (4星)
多个起点多个终点的最短路:
flody (3星)
最小生成树:
prim (3星)
克鲁斯卡尔 (kruskal重构树)(4星)
spfa 判断负环 (3星)
拓扑排序 判断是否是 DAG (3星)
LCA 最近公共祖先 (4星)
强连通分量 tarjan(3星)
必会库
1. bisect
2. collections
a. deque双端队列
collections.deque([iterable[, maxlen]])
- iterable :迭代对象,可以是字符串,列表等可迭代对象。
- maxlen : maxlen 没有指定或者是 None , deque 可以增长到任意长度。否则, deque 就限定到指定最大长度。一旦限定长度的 deque 满了,当新项加入时,同样数量的项就从另一端弹出
q = deque(['a', 'b', 'c'], maxlen=10)
# 从右边添加一个元素
q.append('d')
print(q) # deque(['a', 'b', 'c', 'd'], maxlen=10)append(x):添加 x 到右端。
appendleft(x):添加 x 到左端。
clear():移除所有元素,使其长度为0.
copy():创建一份浅拷贝。3.5 新版功能.
count(x):计算deque中个数等于 x 的元素。3.2 新版功能.
extend(iterable):扩展deque的右侧,通过添加iterable参数中的元素。
extendleft(iterable):扩展deque的左侧,通过添加iterable参数中的元素。注意,左添加时,在结果中iterable参数中的顺序将被反过来添加。
index(x[, start[, stop]]):返回第 x 个元素(从 start 开始计算,在 stop 之前)。返回第一个匹配,如果没找到的话,升起 ValueError 。3.5 新版功能.
insert(i, x):在位置 i 插入 x 。如果插入会导致一个限长deque超出长度 maxlen 的话,就升起一个 IndexError 。3.5 新版功能.
pop():移去并且返回一个元素,deque最右侧的那一个。如果没有元素的话,就升起 IndexError 索引错误。
popleft():移去并且返回一个元素,deque最左侧的那一个。如果没有元素的话,就升起 IndexError 索引错误。
remove(value):移去找到的第一个 value。 如果没有的话就升起 ValueError 。
reverse():将deque逆序排列。返回 None 。3.2 新版功能.
rotate(n=1):向右循环移动 n 步。 如果 n 是负数,就向左循环。如果deque不是空的,向右循环移动一步就等价于 d.appendleft(d.pop()) , 向左循环一步就等价于 d.append(d.popleft()) 。
Deque对象同样提供了一个只读属性:
maxlen:Deque的最大尺寸,如果没有限定的话就是 None 。
b. Counter
dict子类,用于计数
- 字符串
>>> from collections import Counter
>>> c2 = Counter('asfjslfjsdlfjgkls')
>>> c2
Counter({'s': 4, 'f': 3, 'j': 3, 'l': 3, 'a': 1, 'd': 1, 'g': 1, 'k': 1})- 列表
c = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(c) # Counter({'blue': 3, 'red': 2, 'green': 1})elements()
返回迭代器,其中每个元素将重复出现计数值所指定次。 元素会按首次出现的顺序返回。
c = Counter(a=4, b=2, c=0, d=-2)
print(sorted(c.elements())) # ['a', 'a', 'a', 'a', 'b', 'b']most_common([n])
按常见程度由高到低
from collections import Counter
list0 = ['a', 'b', 'b', 'a', 'a', 'e', 'd', 'a', 'c', 'e', 'c', 'b', 'd', 'e', 'd', 'a']
list1 = Counter(list0)
print(list1)
print(list1.most_common(3))
subtract([iterable-or-mapping]):从 迭代对象 或 映射对象 减去元素。
c. defaultdict:可以调用提供默认值的函数
- key不存在时,返回默认值
from collections import defaultdict
dd = defaultdict(lambda: 'not exist')
dd['key1'] = 'abc'
print(dd['key1']) # key1存在
# 'abc'
print(dd['key2']) # key2不存在,返回默认值
# 'not exist'
- list:很容易将一个key-value的序列转换为list字典
from collections import defaultdict
d = defaultdict(list)
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
for k, v in s:
d[k].append(v)
print(d) # defaultdict(<class 'list'>, {'yellow': [1, 3], 'blue': [2, 4], 'red': [1]})
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qdpython/article/details/120786550- int:(直接用counter好一点吧)
s = 'mississippi'
d = defaultdict(int)
for k in s:
d[k] += 1
print(d) # defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})- set:(和list的情况一样,list返回的是列表字典,这里返回的是集合字典)
d. orderedDict
3. functools
a. functools.lru_cache:记忆化搜索
感觉像是建立字典记录
lru_cache 装饰器可以用来为一个函数添加一个缓存系统。这个缓存系统会存储函数的输入和对应的输出。如果函数被调用,并且给出了已经缓存过的输入,那么函数就不会重新计算,而是直接从缓存中获取对应的输出。
要使用 functools.lru_cache 装饰器,你只需要在你的函数定义之前添加 @functools.lru_cache 行。
from functools import lru_cache
@lru_cache(maxsize=128, typed=False)
def add(x, y):
print(f"Calculating: {x} + {y}")
return x + y
print(add(1, 2)) # 输出:Calculating: 1 + 2 \n 3
print(add(1, 2)) # 输出:3
print(add(1.0, 2.0)) # 输出:Calculating: 1.0 + 2.0 \n 3.0
print(add(1.0, 2.0)) # 输出:3.0b. reduce()会对参数序列中元素进行累积。
reduce(function, iterable[, initializer])
function是函数,iterable是可迭代对象
4. itertools
| accumulate(iterable,fun) | 对iterable应用fun,默认是累加 |
| product() | 返回笛卡尔积 |
| permutations(iter, k) | 全排列 |
| combinations(iter, k)k(需要排列的长度) | 全组合 - 元素无重复值 |
| combinations_with_replacement(iter, k) | 全组合 - 元素有重复 |
| takewhile(filter, iter) | 筛选满足条件的值 |
| dropwhile(filter, iter) | 滤除满足条件的值 |
5. math
| factorial(x) | x! |
| perm(n,k) | 排列数P = n! / (n - k)! |
| comb(n,k) | 组合数C = P / k! |
| ceil(x)/floor(x) | 向上/向下取整 |
| dist(p,q) | 点到点-欧式距离 |
| hypot() | 点到原点 |
| gcd(a, b) / lcm(*int) | 最大公约数 / 最小公倍数 |

6. re
| re.match(pattern, string, flags=0) | 尝试从字符串的起始位置匹配一个模式 | pattern string | 匹配的正则表达式 要匹配的字符串。 |
| re.search(pattern, string, flags=0) | 扫描整个字符串并返回第一个成功的匹配 | ||
| re.compile(pattern[, flags]) | re.compile(pattern[, flags]) | pattern | 一个字符串形式的正则表达式 |
| re.findall(pattern, string, flags=0) | 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来匹配所包含的任意一个字符,例如 [amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
单个特殊字符类
| 实例 | 描述 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
字符类
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
tips
- nums1[:] = nums1[0:m]# 应该直接修改原始列表,切片是没有对原来的列表进行更改的















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









