






引入
在此之前没有系统性的接触过opencv的相关知识,多数的学习方向是深度学习机器学习等,在视觉方面不甚熟悉,通过车牌识别的任务让我对opencv的了解和使用有了更加深层次的认识,在这个过程中也学习到了一些对于图像的处理方法,下面是我这段时间的一些学习过程,笔记记录和一些心得。
思路框架
数据预处理
定位车牌位置
在这一步我选择了使用 CascadeClassifier, 是openCV下objdetect模块中用来做目标检测的级联分类器的一个类,是以滑动窗口机制+级联分类器的方式进行目标的检测。
基本原理
xml中存放的是训练后的特征池,特征size大小根据训练时的参数而定,检测的时候可以简单理解为就是将每个固定size特征(检测窗口)与输入图像的同样大小区域比较,如果匹配那么就记录这个矩形区域的位置,然后滑动窗口,检测图像的另一个区域,重复操作。
机理步骤
-
加载xml级联分类器
-
导入image
-
图像颜色处理
-
图像形状resize
-
调用detectMultiScale()实现多尺度检测
g_cascade.detectMultiScale(InputArray image, //输入图像
CV_OUT std::vector<Rect>& objects, //输出检测到的目标区域
double scaleFactor =1.1, //搜索前后两次窗口大小比例系数,默认1.1,即每次搜索窗口扩大10%
int minNeighbors = 3, //构成检测目标的相邻矩形的最小个数 如果组成检测目标的小矩形的个数和小于minneighbors - 1 都会被排除,如果minneighbors为0 则函数不做任何操作就返回所有被检候选矩形框
int flags = 0, //若设置为CV_HAAR_DO_CANNY_PRUNING 函数将会使用Canny边缘检测来排除边缘过多或过少的区域
Size minSize = Size(), //能检测的最小尺寸
Size maxSize = Size() //能检测的最大尺寸
);
####轮廓显示
调用 cv2.rectangle() 方法,用于在任何图像上绘制矩形
cv2.rectangle(image, start_point, end_point, color, thickness)
参数:
image: 它是要在其上绘制矩形的图像。
start_point:它是矩形的起始坐标。坐标表示为两个值的元组,即(X坐标值,Y坐标值)。
end_point:它是矩形的结束坐标。坐标表示为两个值的元组,即(X坐标值Y坐标值)。
color:它是要绘制的矩形的边界线的颜色。对于BGR,我们通过一个元组。例如:(255,0,0)为蓝色。
thickness:它是矩形边框线的粗细像素。厚度**-1像素**将以指定的颜色填充矩形形状。
返回值:返回一个图像。
实例代码
def detect_plate(img, text=''):
plate_img = img.copy()
roi = img.copy()
# 检测车牌并返回检测到的车牌轮廓的坐标和尺寸
plate_rect = plate_cascade.detectMultiScale(plate_img, scaleFactor=1.2,
minNeighbors=7)#scaleFactor=1.04,minNeighbors=10scaleFactor=1.2,minNeighbors=7
for (x, y, w, h) in plate_rect:
plate = roi[y:y + h, x:x + w, :] # 提取车牌所在的区域
cv2.rectangle(plate_img, (x + 2, y), (x + w - 3, y + h - 5), (51, 181, 155),
3) # 最后通过在边缘周围绘制矩形来表示检测到的轮廓
return plate_img, plate # 返回处理后的图像
提取车牌部分并处理
思路过程
- 首先将图片处理为灰度图片,再使用方法
cv2.threshold()简单阈值,将整幅图像分成了非黑即白的二值图像了。
方法介绍
cv2.threshold(src, thresh, maxval, type[, dst])
参数:
src:表示的是图片源
thresh:表示的是阈值(起始值)
maxval:表示的是最大值
type:表示的是这里划分的时候使用的是什么类型的算法,常用值为 0(cv2.THRESH_BINARY)
- 对二值化后的图片进行腐蚀和膨胀操作。腐蚀和膨胀属于形态学操作,就是改变物体形状,腐蚀 = 变瘦,膨胀 = 变胖。主要采用cv2.erode()和cv2.dilate(),注意,腐蚀和膨胀主要针对二值化图像的白色部分。
腐蚀:是一种*消除边界点,使边界向内部收缩的过程,可以用来消除小且无意义的物体.
膨胀: 是将与物体接触的所有背景点合并到该物体中,使边界向外部扩张的过程
可以用来填补物体中的空洞.
def segment_characters(image):
# 预处理裁剪的车牌图像
img_lp = cv2.resize(image, (333, 75))
img_gray_lp = cv2.cvtColor(img_lp, cv2.COLOR_BGR2GRAY) # 将BGR格式转换成灰度图片
# 把整幅图像分成了非黑即白的二值图像
_, img_binary_lp = cv2.threshold(img_gray_lp, 200, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 腐蚀图像 模糊程度(腐蚀程度)就越高 呈正相关关系
img_binary_lp = cv2.erode(img_binary_lp, (3, 3))
# 进行膨胀操作
img_binary_lp = cv2.dilate(img_binary_lp, (3, 3))
LP_WIDTH = img_binary_lp.shape[0]
LP_HEIGHT = img_binary_lp.shape[1]
# 使边框变为白色
img_binary_lp[0:3, :] = 255
img_binary_lp[:, 0:3] = 255
img_binary_lp[72:75, :] = 255
img_binary_lp[:, 330:333] = 255
# 估计裁剪车牌的字符轮廓大小
dimensions = [LP_WIDTH / 6,
LP_WIDTH / 2,
LP_HEIGHT / 10,
2 * LP_HEIGHT / 3]
plt.imshow(img_binary_lp, cmap='gray')
plt.show()
cv2.imwrite('contour.jpg', img_binary_lp)
# 在裁剪的车牌内获取轮廓
char_list = find_contours(dimensions, img_binary_lp)
return char_list
模型构建
思路过程
- 在模型构建的这一个过程中重要的是能够实现对单独的字母数字进行一个识别,就此目标我想到了利用神经网络的强大学习能力以求达到理想的分类效果,但是选择了神经网络模型就意味着需要喂给模型大量的数据来实现模型的训练学习,在构建数据集的过程中使用了
ImageDataGenerator做数据增强,能使得模型的学习效果更好。通过一系列随机变换对数据进行提升,这样有利于抑制过拟合,提升模型的泛化能力。
train_datagen = ImageDataGenerator(rescale=1. / 255, width_shift_range=0.1, height_shift_range=0.1)
path = './'
train_generator = train_datagen.flow_from_directory(
path + '/train', # 目标目录
target_size=(28, 28), # 所有图片大小被设置为28*28
batch_size=1,
class_mode='sparse')
validation_generator = train_datagen.flow_from_directory(
path + '/val', # 目标目录
target_size=(28, 28), # 所有图片大小被设置为28*28
class_mode='sparse')
#数据集的来源是网上找的
- 模型就选择了CNN卷积神经网络作为框架
model = Sequential()
model.add(Conv2D(16, (22, 22), input_shape=(28, 28, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (16, 16), input_shape=(28, 28, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (8, 8), input_shape=(28, 28, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (4, 4), input_shape=(28, 28, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(36, activation='softmax'))

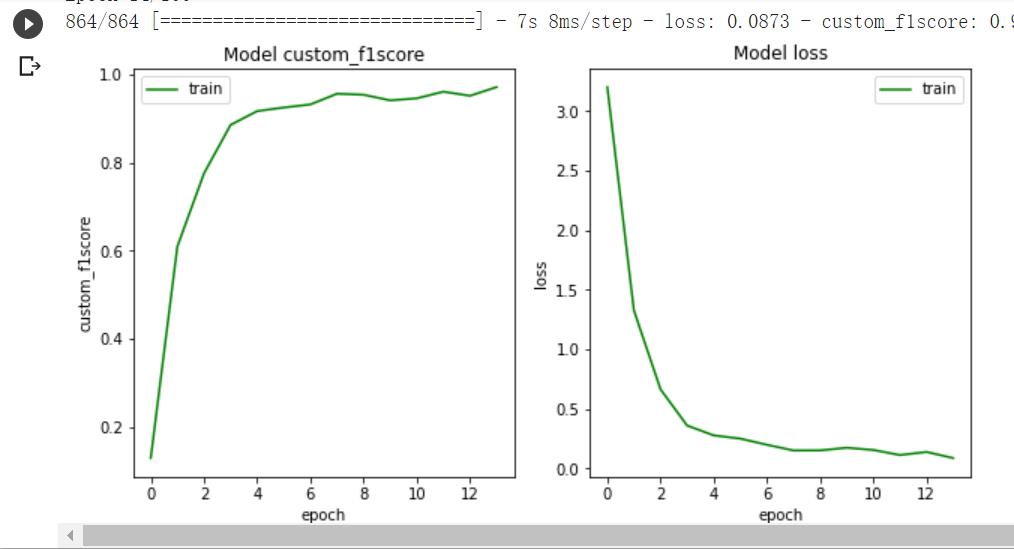
5b7a38f668b930a79ef2ec3c41dbc5e2025×135 10.3 KB

11d6a4d8eb636f11d693274a2b3955e729×563 39.2 KB

c32c157180388d0478cb74d1a64332a1014×549 33.2 KB
由图可以看出CNN在该任务中的表现还是非常理想的。
在平台上训练模型结束后,保存为h5文件,再在本地对该文件进行读取,从而实现将模型在本地运用。
model = tf.keras.models.load_model('model.h5', compile = False)
最后运用该模型对目标样本进行预测
for i, ch in enumerate(char):
img = cv2.resize(ch, (28, 28), interpolation=cv2.INTER_AREA)
plt.subplot(3, 4, i + 1)
plt.imshow(img, cmap='gray')
plt.title(f'predicted: {show_results()[i]}')
plt.axis('off')
最初想法
cv2.bilateralFilter:双边滤波
双边滤波综合考虑距离和色彩的权重结果,既能够有效地去除噪声,又能够较好地保护边缘信息。 在双边滤波中,当处在边缘时,与当前点色彩相近的像素点(颜色距离很近)会被给予较大的权重值;而与当前色彩差别较大的像素点(颜色距离很远)会被给予较小的权重值(极端情况下权重可能为0,直接忽略该点),这样就保护了边缘信息。
dst=cv2.bilateralFilter(src,d,sigmaColor,sigmaSpace,borderType)
式中:
● dst是返回值,表示进行双边滤波后得到的处理结果。
● src 是需要处理的图像,即原始图像。它能够有任意数量的通道,并能对各通道独立处理。图像深度应该是CV_8U、CV_16U、CV_16S、CV_32F或者CV_64F中的一 种。
● d是在滤波时选取的空间距离参数,这里表示以当前像素点为中心点的直径。如果该值为非正数,则会自动从参数 sigmaSpace 计算得到。如果滤波空间较大(d>5),则速度较慢。因此,在实时应用中,推荐d=5。对于较大噪声的离线滤波,可以选择d=9。
● sigmaColor是滤波处理时选取的颜色差值范围,该值决定了周围哪些像素点能够参与到滤波中来。与当前像素点的像素值差值小于 sigmaColor 的像素点,能够参与到当前的滤波中。该值越大,就说明周围有越多的像素点可以参与到运算中。该值为0时,滤波失去意义;该值为255时,指定直径内的所有点都能够参与运算。
● sigmaSpace是坐标空间中的sigma值。它的值越大,说明有越多的点能够参与到滤波计算中来。当d>0时,无论sigmaSpace的值如何,d都指定邻域大小;否则,d与 sigmaSpace的值成比例。
● borderType是边界样式,该值决定了以何种方式处理边界。一般情况下,不需要考虑该值,直接采用默认值即可。
为了简单起见,可以将两个sigma(sigmaColor和sigmaSpace)值设置为相同的。如果它们的值比较小(例如小于10),滤波的效果将不太明显;如果它们的值较大(例如大于150),则滤波效果会比较明显,会产卡通效果。
在函数cv2.bilateralFilter()中,参数borderType是可选参数,其余参数全部为必选参数。
Opencv之图像滤波:6.双边滤波(cv2.bilateralFilter)_Justth.的博客-CSDN博客_opencv 双边滤波
cv2.findContours:轮廓检测
用于轮廓检测,其输入为二值图像(binary image)
cv2.findContours() 函数有三个输入参数:
- 输入图像(二值图像)
- 轮廓检索方式
- 轮廓近似方法
[1] - 轮廓检索方式
| mode | 含义 |
|---|---|
| cv2.RETR_EXTERNAL | 只检测外轮廓信息 |
| cv2.RETR_LIST | 输出的轮廓间无等级关系,以list形式输出轮廓信息 |
| cv2.RETR_CCOMP | 输出两层轮廓信息,即内外两个边界. 上面一层为外边界,里面一层为内孔的边界信息 |
| cv2.RETR_TREE | 以树结构输出轮廓信息 |
[2] - 轮廓近似方法
| method | 含义 |
|---|---|
| cv2.CHAIN_APPROX_NONE | 存储所有边界点 |
| cv2.CHAIN_APPROX_SIMPLE | 压缩垂直、水平、对角方向,只保留端点 |
| cv2.CHAIN_APPROX_TX89_L1 | 使用teh-Chini近似算法 |
| cv2.CHAIN_APPROX_TC89_KCOS | 使用teh-Chini近似算法 |
findContours 轮廓提取函数会返回值为:
[1] - image - 处理后的图像
[2] - contours - 检测到的轮廓的点集
[3] - hierarchy - 各层轮廓的索引
python sorted()函数
语法知识:sorted(iterable, key=None, reverse=False)
iterable : 可迭代对象
key : 排序函数,在sorted内部将可迭代对象中的每个元素传递给这个函数的参数,根据函数运算结果进行排序
reverse : 排序规则,reverse = True降序,reverse = False 升序(默认)
cv2.counterArea:计算轮廓的面积
area = cv2.contourArea(cnt)
cv2.arcLength:计算轮廓的周长
perimeter = cv2.arcLength(cnt,True)
cv2.approxPolyDP:轮廓类似
将轮廓形状近似到另外一种有更少点组成的轮廓形状,新轮廓的点的数目有我们设定的准确度来决定。假设我们要在一幅图像中查找一个矩形,但是由于图像的种种原因,我们不能得到一个完美的矩形,而是一个不规则形状,现在就可以使用这个函数来近似这个形状了。这个函数的第二个参数叫epsilon,它是从原始轮廓到近似轮廓的最大距离,它是一个准确率参数,选择一个好的epsilon对于得到满意结果非常重要。
心得
通过这个项目对可视化有了一个了解,但是对图像的一些处理手法还是不熟练,并且在原理方面的认识也并不足够深入,总体而言,对可视化的认识还是停留在表面,没有深入其中机理。这个过程中也学习到了很多新的关于OpenCV的方法,见识到了很多的新报错和debug的方法。利用CNN结构虽然在单个的字母和数字上的表现效果比较好,但是对于不同的照片的表现参差不齐,在最初的想法中是调用了已有的函数库实现效果较好,但是还是不能做到汉字的识别。















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}