







Objects as Points论文阅读笔记
前言
在这篇博客中,我主要对CenterNet的实现过程进行一些分析。由于本人刚刚接触计算机视觉领域,所以有些问题可能分析的不够透彻或者有些错误,也请各位读者多多谅解并及时指出问题,万分感谢。
背景介绍
大多数目标检测器都是在图像上将目标用框(bounding box)来框出,这需要枚举所有可能的物体位置并对每个位置进行分类,但是这种方式效率低下。在今年4月,得克萨斯奥斯汀大学和伯克利提出了CenterNet的目标检测方法。这种方法将目标检测的问题转化为了对关键点(也就是目标的bounding box的中心点)的检测问题。相对于基于bounding box的检测器,CenterNet的模型更简单,速度更快,准确率也更高。其实Objects as points并不是第一个提出这种基于关键点检测方法的论文,但是CenterNet取得了目前所有同类算法(single-stage detector)在MSCOCO数据集上的最好成绩。
CenterNet除了可以用于目标检测, 还可以很容易的扩展到其他任务上,比如3D物体检测和人体姿态估计。在论文中也给出了基于CenterNet来完成这两个任务的方法,感兴趣的话可以去阅读论文原文,在这篇博客中我只是大致分析一下如何使用CenterNet进行目标检测。论文原文以及源代码链接:https://pan.baidu.com/s/1cAG7HGaqXbthUzZkPDoD-Q 提取码:m3s1
初步处理(得到热点图)
输入图像I
∈
R
W
∗
H
∗
3
\in R^{W*H*3}
∈RW∗H∗3,W是图像宽度,H是图像高度,3是RGB图像通道数。
输出热点图Y
∈
[
0
,
1
]
W
/
R
∗
H
/
R
∗
C
\in [0,1]^{W/R*H/R*C}
∈[0,1]W/R∗H/R∗C,其中R是输出stride大小,默认为4,C是图像中的中心点种类数。在目标检测问题中C就是目标种类数,在人体动作检测的时候C就是人的关节数(一般是17)。也就是说我们在这一步中需要得到各个种类中心点的热点图。
热点图的计算方法采用二维高斯分布。假设实际的中心点(也就是物体边框的几何中心点)为p
∈
R
2
\in R^2
∈R2,由于输出图像
Y
x
y
z
∈
[
0
,
1
]
W
/
R
∗
H
/
R
∗
C
Y_{xyz}\in[0,1]^{W/R*H/R*C}
Yxyz∈[0,1]W/R∗H/R∗C,所以p映射到大小W/R, H/R的图像中的对应点~p = p/R。 (注意这一步向下取整会造成误差) 然后以~p为中心,并利用二维高斯分布计算周围点在[0,1]范围内的值,从而生成一个中心点的热点图。这个热点图会用于之后的误差分析,由于论文中最开始讲的就是这一部分,所以我也在一开始讲解这个处理过程。
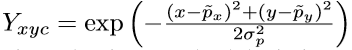

目标检测的预测结果
我们的目标是通过输入图像I,预测出图像的中心点图Y^
x
y
c
∈
[
0
,
1
]
W
/
R
∗
H
/
R
∗
C
_{xyc}\in[0,1]^{W/R*H/R*C}
xyc∈[0,1]W/R∗H/R∗C 。Y^
x
y
c
_{xyc}
xyc在0,1之间,0表示(x,y,c)处为背景,1表示(x,y,c)处为中心点(根据c的值确定属于哪一类中心点),Y^
x
y
c
_{xyc}
xyc值的大小表示像素点(x,y)是类别c的中心点的一个置信度大小。
而且由于我们对图像进行了下采样,也就是因为输出中心点图大小比原始图像长宽都缩小了R倍,而像素点位置p~=p/R这一步是向下取整,所以也造成了很少量的中心点偏移,所以我们还需要预测一个中心点的偏移值。将上一步中预测中心点位置加上偏移值才是实际预测中心点位置。
进行目标检测除了需要知道目标的中心点位置,我们还需要知道目标所处的边框大小,也就是需要预测一个边框的长宽值。在已知边框中心的情况下,通过边框长宽就可以完全定位目标边框的位置。
综上所述,对于每个像素点我们需要使用网络预测出C+4个值。
- C个是否是中心点的信息
- w(预测边框的宽)
- h(预测边框的高)
- δ \delta δx(中心点在x方向上的偏移)
- δ \delta δy(中心点在y方向上的偏移)
结合以上C+4个参数我们就可以得到目标边框的预测结果:(结果用边框的左上角和右下角位置表示)
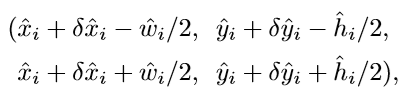
由于每个像素点都可以计算出一个目标边框,所以我们还需要对预测结果进行一步筛选。在前面我们说过,Y^
x
y
c
_{xyc}
xyc值的大小表示像素点(x,y)是类别c中心的置信度大小,所以我们只需要分别选择出每个类别,也就是每个通道上的极值点位置。极值点的判断可以简单的将像素点与其八邻域像素点值进行比较,如果像素点(x,y)在通道c上比它的八邻域像素点在通道c上的值大,那么就保留(x,y)作为类别c的一个中心点预测结果。
目标检测的损失函数
明确模型的输入和输出之后,在开始训练之前还需要明确模型的损失函数,也就是需要明确如何度量预测结果的好坏。预测误差根据预测结果的类型也可以分为三类:
- 中心点误差Lk
- 中心点偏移误差Loff
- 边框尺寸误差Lsize
中心点误差Lk
首先第一个误差就是由于中心点估计产生的误差,误差Lk的计算方式如下:
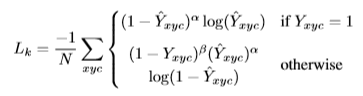
可以看到中心点误差的计算中使用到了在第一部分中的热点图,由于热点图是由实际中心点求二维高斯分布得到的,所以由以上公式可以体现出预测中心点和实际中心点之间的偏差程度。在论文中α=2 β=4,N是图像I中的中心点个数,在最后结果除以N是为了使结果归一化。。
中心点偏移误差Loff
由于图像下采样,使得最后预测的中心点和原图中实际中心点的位置存在着微小的误差,这是由于向下取整的问题造成的。所以我们还需要一个偏移预测量
O
p
O_p
Op来表示中心点由于下采样造成的偏移,
O
p
O_p
Op由x,y这两个方向上偏移构成。Loff就是将所有中心点的偏移预测量和实际偏移量做差(L1 loss)再求平均的结果。
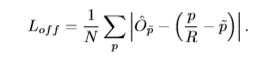

边框尺寸误差Lsize
网络预测结果中包含了边框长宽的预测,为了表示对边框的预测误差,这里直接计算预测边框的总面积与实际边框总面积的误差。
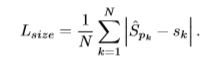

总损失函数
将以上三个方面的误差加权求和就可以得到总的误差值Ldet,在论文中人size=0.1,人off=1。
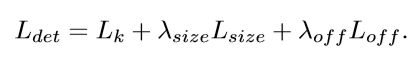
目标检测的训练网络
明确前面几个问题之后就需要选择训练网络。在论文中,作者使用了四种网络结构:ResNet-18,ResNet-101,DLA-34,和Hourglass-104。其中两个ResNet和DLA都使用了可变形卷积层。关于可变形卷积参见博客。

不同网络效果

小结
在这篇博客中我简单分析了一下CenterNet的实现方法,如果博客中有什么错误,还请大家及时指出。在之后的博客中我会对这篇论文的源代码进行一些分析,并尝试自己实现CenterNet。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









