







DIN 深度兴趣网络介绍以及源码浅析
前言
继续分析论文, 养成及时记录的好习惯; 周末立了写两篇博客的 Flag, 期望能够完成 … 🤣 🤣 🤣
另外需要说明的是, 本篇文章并不打算详细的解读原文, 而是按照我的理解记录文章最核心的观点, 以及对相关代码进行解读, 最终的目标是以后我再翻看本文能够快速回忆起文章最重要的内容. OK, 下面开始分析.
广而告之
可以在微信中搜索 “珍妮的算法之路” 或者 “world4458” 关注我的微信公众号;另外可以看看知乎专栏 PoorMemory-机器学习, 以后文章也会发在知乎专栏中;
Deep Interest Network (深度兴趣网络, DIN)
文章信息
- 论文标题: Deep Interest Network for Click-Through Rate Prediction
- 论文地址: https://arxiv.org/abs/1706.06978
- 代码地址: https://github.com/zhougr1993/DeepInterestNetwork, 另外作者在 README 中推荐看 https://github.com/mouna99/dien 中的实现.
- 发表时间: 2017
- 论文作者: Zhou Guorui, Song Chengru, Zhu, Xiaoqiang, Ma Xiao, Yan Yanghui, Dai Xingya, Zhu Han, Jin Junqi, Li Han, Gai Kun
- 作者单位: Alibaba Group
核心观点
文章首先介绍了现有的点击率 (CTR) 预估模型大都满足相同的模式: 先将大量的稀疏类别特征 (Categorical Features) 通过 Embedding 技术映射到低维空间, 再将这些特征的低维表达按照特征的类别进行组合与变换 (文中采用 in a group-wise manner 来描述), 以形成固定长度的向量 (比如常用的 sum pooling / mean pooling), 最后将这些向量 concatenate 起来输入到一个 MLP (Multi-Layer Perceptron) 中, 从而学习这些特征间的非线性关系.
然而这个模式存在一个问题. 举个例子, 在电商场景下, 用户兴趣可以使用用户的历史行为来描述 (比如用户访问过的商品, 店铺或者类目), 然而如果按照现有的处理模式, 对于不同的候选广告, 用户的兴趣始终被映射为同一个固定长度的向量来表示, 这极大的限制了模型的表达能力, 毕竟用户的兴趣是多样的.
为了解决这个问题, 本文提出了 DIN 网络, 对于不同的候选广告, 考虑该广告和用户历史行为的相关性, 以便自适应地学习用户兴趣的特征表达. 具体来说, 文章介绍了 local activation unit 模块, 其基于 Attention 机制, 对用户历史行为进行加权来表示用户兴趣, 其中权重参数是通过候选广告和历史行为交互来进行学习的.
另外, 本文还介绍了 Mini-batch Aware Regularization 与 Dice 激活函数两种技术, 以帮助训练大型的网络.
上面这几段话是做个简单的总结, 下面再详细分析一下.
核心观点解读
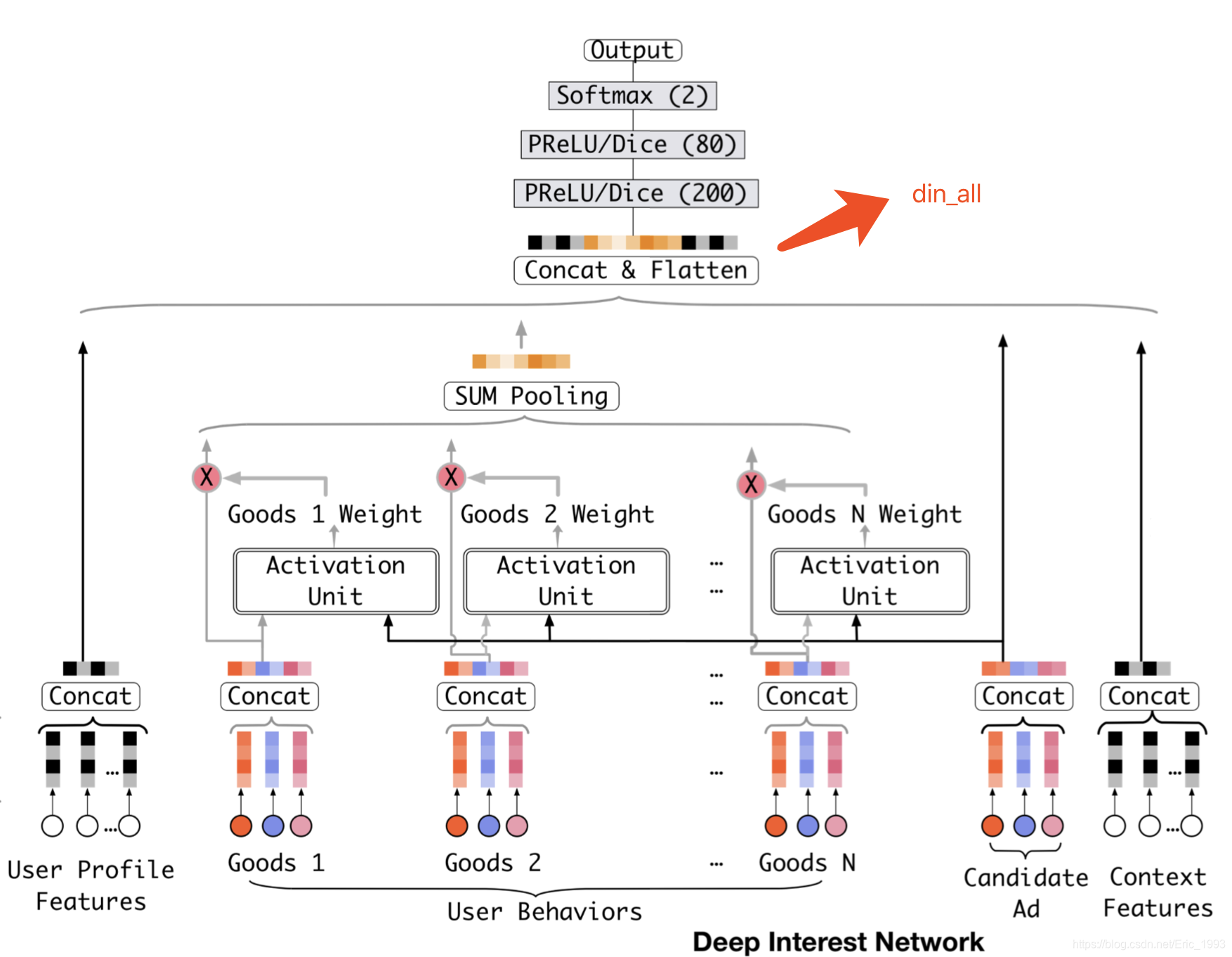
观察下图的 Base Model, 是现有的大多数 CTR 模型采用的模式:

其中红蓝粉三色节点分别表示商品 ID (Goods ID), 店铺 ID (Shop ID), 类目 ID (Cate ID) 三种稀疏特征, 其他的输入特征, 使用白色节点表示 (比如左边的用户特征, 比如用户 ID; 还有右边的上下文特征, 比如广告位之类的特征). 注意 Goods 1 ~ Goods N 用来描述用户的历史行为. 候选广告 Candidate Ad 本身也是商品, 也具有 Goods / Shop / Cate ID 三种特征.
之后使用 Embedding Layer 将这些类别特征转化为 dense 的低维稠密向量, 其中对于用户历史行为特征, 之后使用 SUM Pooling 转化为一个固定长度的向量, 该向量可以表示用户的兴趣; 这里需要注意上一节 “核心观点” 中提到的问题, 对于同一个用户, 如果候选广告 (Candidate Ad) 发生了变化, 用户的兴趣却依然是同一个向量来表达, 显然这限制了模型的表达能力, 毕竟用户的兴趣是丰富的/变化的.
为了解决上面的问题, 本文提出了深度兴趣网络 DIN, 如下图:
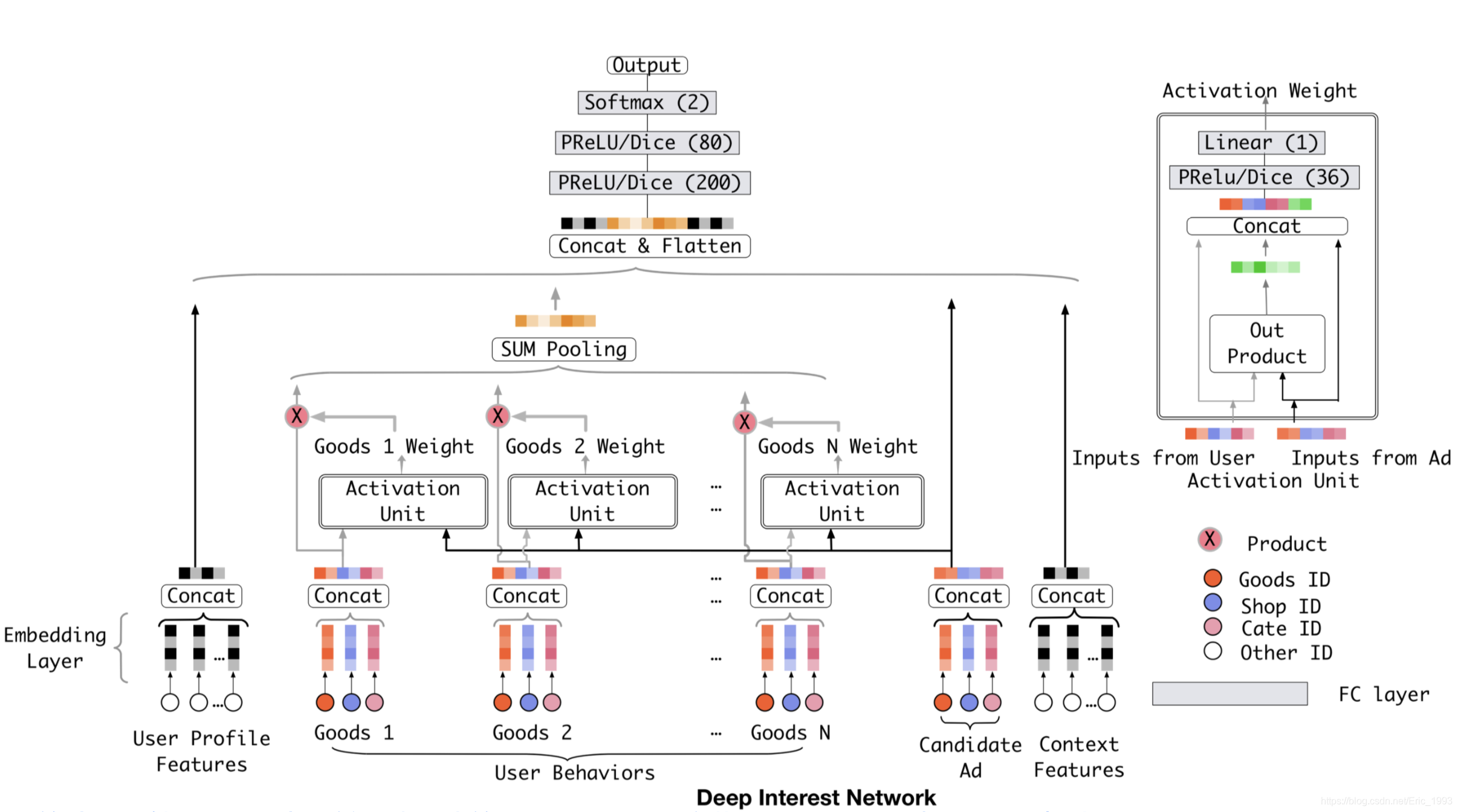
注意该图和 Base Model 的差异. DIN 介绍了被称为 Local Activation Unit 的模块, 它用来学习候选广告和用户历史行为的关系, 并给出候选广告和各个历史行为的相关性程度 (即权重参数), 再对历史行为序列进行加权求和, 最终得到用户兴趣的特征表达. 用数学公式来表达, 即为: 假设 { e 1 , e 2 , … , e H } \{\bm{e}_1, \bm{e}_2, \ldots, \bm{e}_H\} {e1,e2,…,eH} 为用户 U U U 的历史行为的 embedding list, 长度为 H H H, v A \bm{v}_A vA 表示 Candidate Ad 的特征表达, 那么给定广告 A A A, 用户的兴趣可以表示为:
v U ( A ) = f ( v A , e 1 , e 2 , … , e H ) = ∑ j = 1 H a ( e j , v A ) e j = ∑ j = 1 H w j e j \boldsymbol{v}_{U}(A)=f\left(\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}_{j}, \boldsymbol{v}_{A}\right) \boldsymbol{e}_{j}=\sum_{j=1}^{H} \boldsymbol{w}_{j} \boldsymbol{e}_{j} vU(A)=f(vA,e1,e2,…,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej
其中 a ( ⋅ ) a(\cdot) a(⋅) 为前向传播网络 (本文中即为 Local Activation Unit, 观察其接受两个参数, 分别是用户第 j j j 个历史行为以及候选广告的 embedding v A \boldsymbol{v}_{A} vA), 其输出结果, 即权重 w j \boldsymbol{w}_{j} wj.
可以从公式中观察到, 即便对一组相同的用户历史行为序列, 如果候选广告 A A A 发生了变化, 权重 w j \boldsymbol{w}_{j} wj 也会发生变化, 用户兴趣的特征表示 v U ( A ) \boldsymbol{v}_{U}(A) vU(A) 不再是固定的.
文章核心观点介绍完毕, 关于 Dice 激活函数和 Mini-batch Aware Regularization 后面也许会在代码分析中介绍. (嗅到了 Flag 的味道~ 🤣🤣🤣)
DIN 源码浅析
数据处理
详见代码: https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/build_dataset.py
其核心逻辑代码如下:
for reviewerID, hist in reviews_df.groupby('reviewerID'):
pos_list = hist['asin'].tolist()
def gen_neg():
neg = pos_list[0]
while neg in pos_list:
neg = random.randint(0, item_count-1)
return neg
neg_list = [gen_neg() for i in range(len(pos_list))]
for i in range(1, len(pos_list)):
hist = pos_list[:i]
if i != len(pos_list) - 1:
train_set.append((reviewerID, hist, pos_list[i], 1))
train_set.append((reviewerID, hist, neg_list[i], 0))
else:
label = (pos_list[i], neg_list[i])
test_set.append((reviewerID, hist, label))
(每当要画图的时候, 尘封已久的 iPad Pro 才能发挥它应该有的价值, 不愧为生产力工具 … 🤣, 没有成为影碟机或者游戏机, 不知道是幸运还是不幸~)
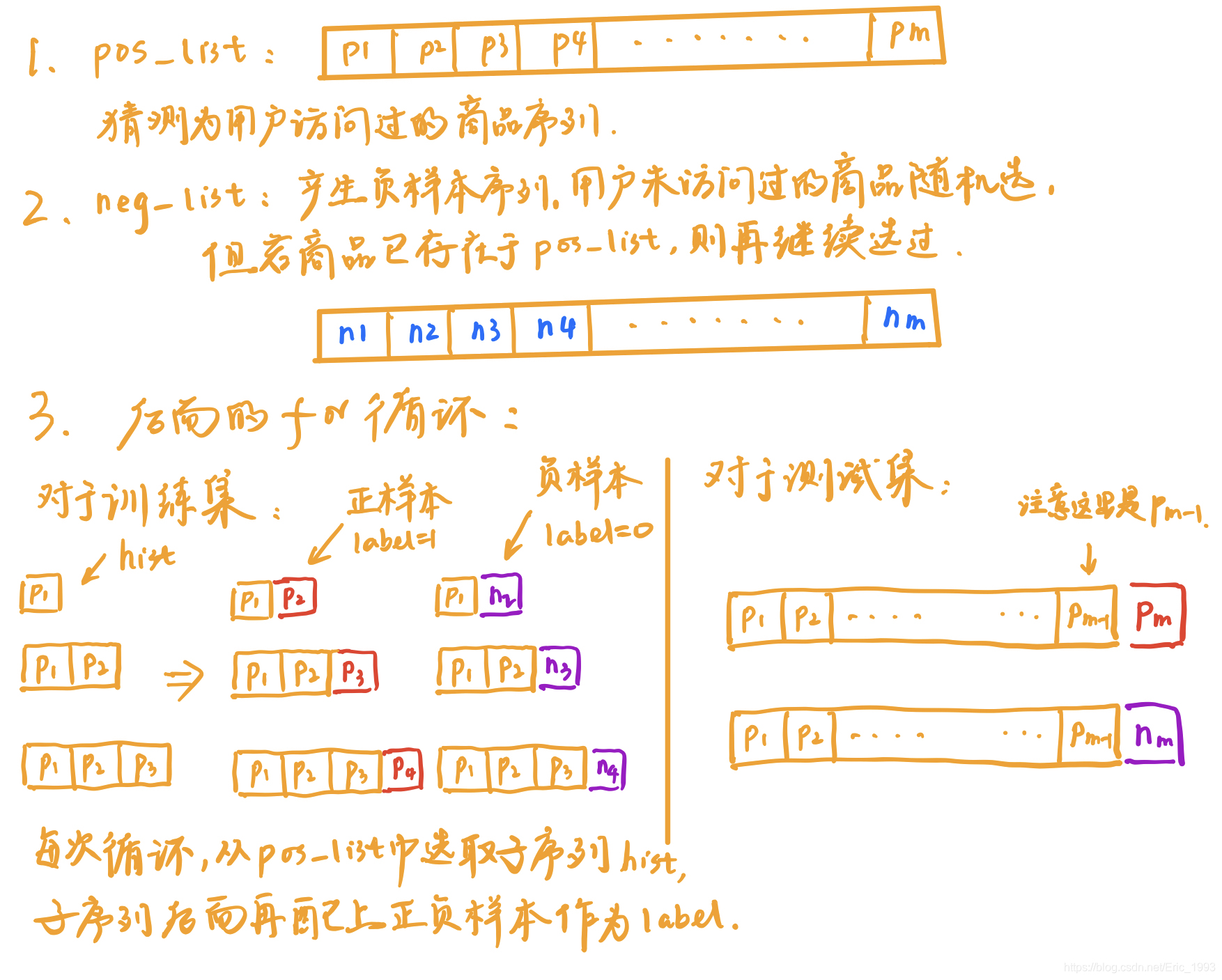
构建训练集和测试集
代码详见: https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/input.py
上一节对原始数据进行处理, 得到数据:
## 训练数据
train_set.append((reviewerID, hist, pos_list[i], 1))
train_set.append((reviewerID, hist, neg_list[i], 0))
## 测试数据
label = (pos_list[i], neg_list[i])
test_set.append((reviewerID, hist, label))
之后训练集的制作使用 DataInput 实现, 其为一个迭代器:
class DataInput:
## ..... 不核心的代码去掉
def next(self):
if self.i == self.epoch_size:
raise StopIteration
ts = self.data[self.i * self.batch_size : min((self.i+1) * self.batch_size,
len(self.data))]
self.i += 1
u, i, y, sl = [], [], [], []
for t in ts:
## t 表示 (reviewerID, hist, pos_list[i]/neg_list[i], 1/0)
## 其中 t[1] = hist, 为用户历史行为序列
u.append(t[0])
i.append(t[2])
y.append(t[3])
sl.append(len(t[1]))
max_sl = max(sl)
hist_i = np.zeros([len(ts), max_sl], np.int64)
k = 0
for t in ts:
for l in range(len(t[1])):
hist_i[k][l] = t[1][l]
k += 1
return self.i, (u, i, y, hist_i, sl)
DataInput 从 train_set 中读取数据, 其中:
u保存用户的 User ID, 即代码中reviewID, 那么u就是用户 ID 序列i表示正样本/负样本, 后面正负样本我统一用目标节点 (target) 来描述, 即i为目标节点序列y表示目标节点的 label, 取值为1或0;sl保存用户历史行为序列的真实长度 (代码中的len(t[1])就是求历史行为序列的长度),max_sl表示序列中的最大长度;
由于用户历史序列的长度是不固定的, 因此引入 hist_i, 其为一个矩阵, 将序列长度固定为 max_sl. 对于长度不足 max_sl 的序列, 使用 0 来进行填充 (注意 hist_i 使用 zero 矩阵来进行初始化的)
测试集的制作基本同理:
class DataInputTest:
## 忽略不核心的代码
def next(self):
if self.i == self.epoch_size:
raise StopIteration
ts = self.data[self.i * self.batch_size : min((self.i+1) * self.batch_size,
len(self.data))]
self.i += 1
u, i, j, sl = [], [], [], []
for t in ts:
## t 表示: (reviewerID, hist, label)
## 其中 label 为 (pos_list[i], neg_list[i])
u.append(t[0])
i.append(t[2][0])
j.append(t[2][1])
sl.append(len(t[1]))
max_sl = max(sl)
hist_i = np.zeros([len(ts), max_sl], np.int64)
k = 0
for t in ts:
for l in range(len(t[1])):
hist_i[k][l] = t[1][l]
k += 1
return self.i, (u, i, j, hist_i, sl)
由于前面 test_set 返回的结果: (reviewerID, hist, label), 其中 label 表示 (pos_list[i], neg_list[i]), 所以:
u保存用户的 User ID, 即代码中reviewID, 那么u就是用户 ID 序列i保存正样本j保存负样本sl保存用户历史行为序列的真实长度 (代码中的len(t[1])就是求历史行为序列的长度),max_sl表示序列中的最大长度;hist_i保存用户历史行为序列, 长度不足max_sl的序列后面用0填充.
模型构建
完整代码见: https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/model.py
注意看源码的时候, 如果你在大脑中使用训练集去将模型的流程过一遍, 可以忽略 Model 中关于 self.j 的代码, 它只会在运行测试集的时候被用到, 这和 TF 的静态图特性有关.
class Model(object):
def __init__(self, user_count, item_count, cate_count, cate_list, predict_batch_size, predict_ads_num):
self.u = tf.placeholder(tf.int32, [None,]) # [B]
self.i = tf.placeholder(tf.int32, [None,]) # [B]
self.j = tf.placeholder(tf.int32, [None,]) # [B] ## 读代码的时候可以先忽略关于 self.j 的部分
self.y = tf.placeholder(tf.float32, [None,]) # [B]
self.hist_i = tf.placeholder(tf.int32, [None, None]) # [B, T]
self.sl = tf.placeholder(tf.int32, [None,]) # [B]
self.lr = tf.placeholder(tf.float64, [])
先来看如果是训练集, 模型会传入哪些参数:
self.u: 用户 ID 序列self.i: 目标节点序列 (目标节点就是正或负样本)self.y: 目标节点对应的 label 序列, 正样本对应1, 负样本对应0self.hist_i: 用户历史行为序列, 大小为[B, T]self.sl: 记录用户行为序列的真实长度self.lr: 学习速率
Embedding 获取
### 用户 embedding, 整个代码没有被用到 .....
user_emb_w = tf.get_variable("user_emb_w", [user_count, hidden_units])
### 目标节点对应的商品 embedding
item_emb_w = tf.get_variable("item_emb_w", [item_count, hidden_units // 2])
### 如果我没有猜错, 这应该是 bias
item_b = tf.get_variable("item_b", [item_count],
initializer=tf.constant_initializer(0.0))
### 类目 embedding
cate_emb_w = tf.get_variable("cate_emb_w", [cate_count, hidden_units // 2])
cate_list = tf.convert_to_tensor(cate_list, dtype=tf.int64)
## 从 cate_list 中获取目标节点对应的类目 id
ic = tf.gather(cate_list, self.i)
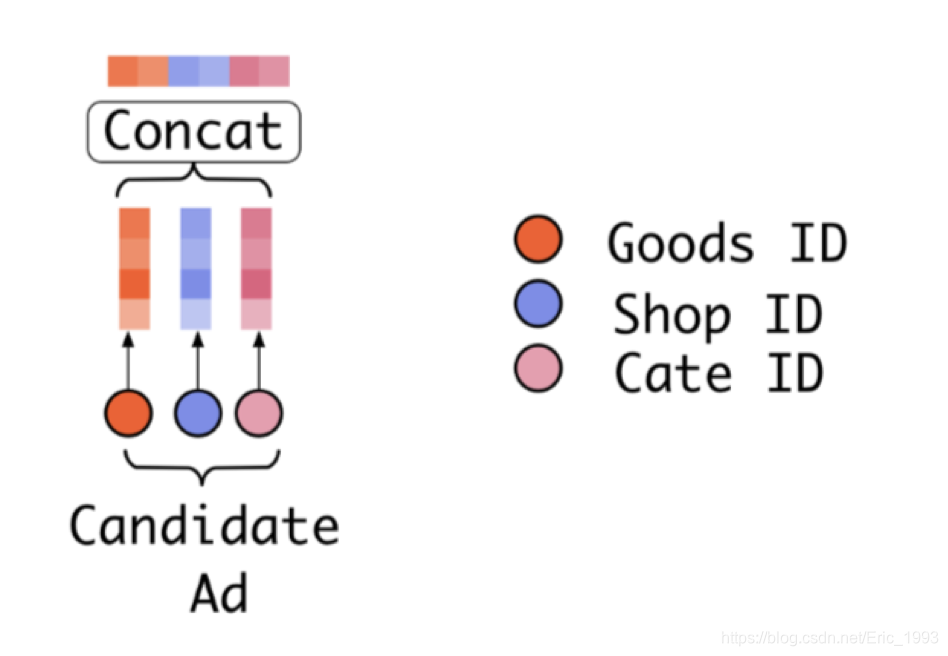
## 将目标节点对应的商品 embedding 和类目 embedding 进行 concatenation
i_emb = tf.concat(values = [
tf.nn.embedding_lookup(item_emb_w, self.i),
tf.nn.embedding_lookup(cate_emb_w, ic),
], axis=1)
i_b = tf.gather(item_b, self.i)
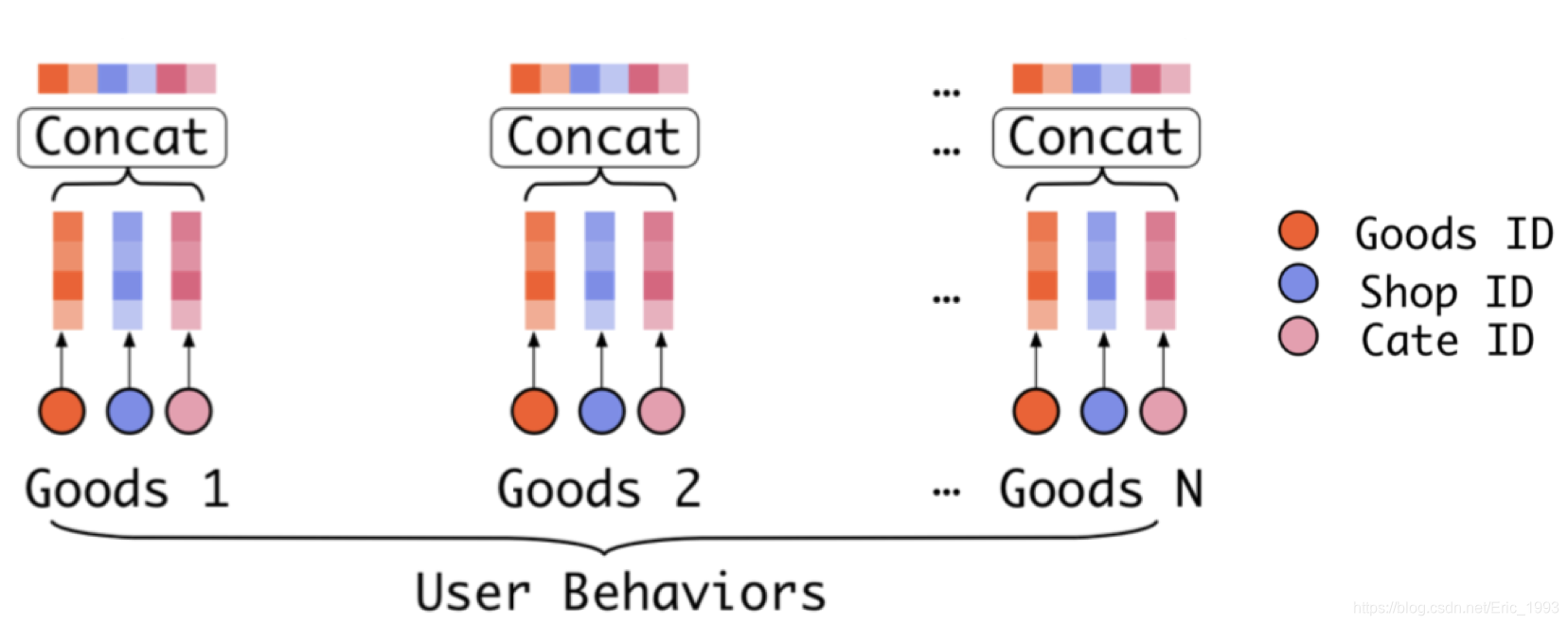
## 注意 self.hist_i 保存用户的历史行为序列, 大小为 [B, T], 所以在进行 embedding_lookup 时,
## 输出大小为 [B, T, H/2]; 之后将 Goods 和 Cate 的 embedding 进行 concat, 得到
## [B, T, H] 大小. 注意到 tf.concat 中的 axis 参数值为 2
hc = tf.gather(cate_list, self.hist_i)
h_emb = tf.concat([
tf.nn.embedding_lookup(item_emb_w, self.hist_i),
tf.nn.embedding_lookup(cate_emb_w, hc),
], axis=2)
上面的代码主要是对用户 embedding layer, 商品 embedding layer 以及类目 embedding layer 进行初始化, 然后在获取一个 Batch 中目标节点对应的 embedding, 保存在 i_emb 中, 它由商品 (Goods) 和类目 (Cate) embedding 进行 concatenation, 相当于完成了下图中的步骤:
后面对 self.hist_i 进行处理, 其保存了用户的历史行为序列, 大小为 [B, T], 所以在进行 embedding_lookup 时, 输出大小为 [B, T, H/2]; 之后将 Goods 和 Cate 的 embedding 进行 concat, 得到 [B, T, H] 大小. 注意到 tf.concat 中的 axis 参数值为 2, 相当于完成下图中的步骤:
Attention
经过上面的处理, 我们已经得到候选广告对应的 embedding i_emb, 大小为 [B, H], 以及用户历史行为对应的 embedding hist_i, 大小为 [B, T, H], 下面将它们输入 Attention 层中, 自适应学习用户兴趣的表征.
### 注意原代码中写的是 hist_i =attention(i_emb, h_emb, self.sl)
### 为了方便说明, 返回值用 u_emb_i 来表示, 即 Attention 之后返回用户的兴趣表征;
### 源代码中返回的结果 hist_i 还经过了 BN 层, 当然这不是我们关心的重点
u_emb_i = attention(i_emb, h_emb, self.sl)
其中 Attention 层的具体实现为:
def attention(queries, keys, keys_length):
'''
queries: [B, H]
keys: [B, T, H]
keys_length: [B], 保存着用户历史行为序列的真实长度
'''
## queries.get_shape().as_list()[-1] 就是 H,
## tf.shape(keys)[1] 结果就是 T
queries_hidden_units = queries.get_shape().as_list()[-1]
queries = tf.tile(queries, [1, tf.shape(keys)[1]]) ## [B, T * H], 想象成贴瓷砖
## queries 先 reshape 成和 keys 相同的大小: [B, T, H]
queries = tf.reshape(queries, [-1, tf.shape(keys)[1], queries_hidden_units])
## Local Activation Unit 的输入, 候选广告 queries 对应的 emb 以及用户历史行为序列 keys
## 对应的 embed, 再加上它们之间的交叉特征, 进行 concat 后, 再输入到一个 DNN 网络中
## DNN 网络的输出节点为 1
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att', reuse=tf.AUTO_REUSE)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att', reuse=tf.AUTO_REUSE)
## 上一层 d_layer_3_all 的 shape 为 [B, T, 1]
## 下一步 reshape 为 [B, 1, T], axis=2 这一维表示 T 个用户行为序列分别对应的权重参数
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(keys)[1]])
outputs = d_layer_3_all ## [B, 1, T]
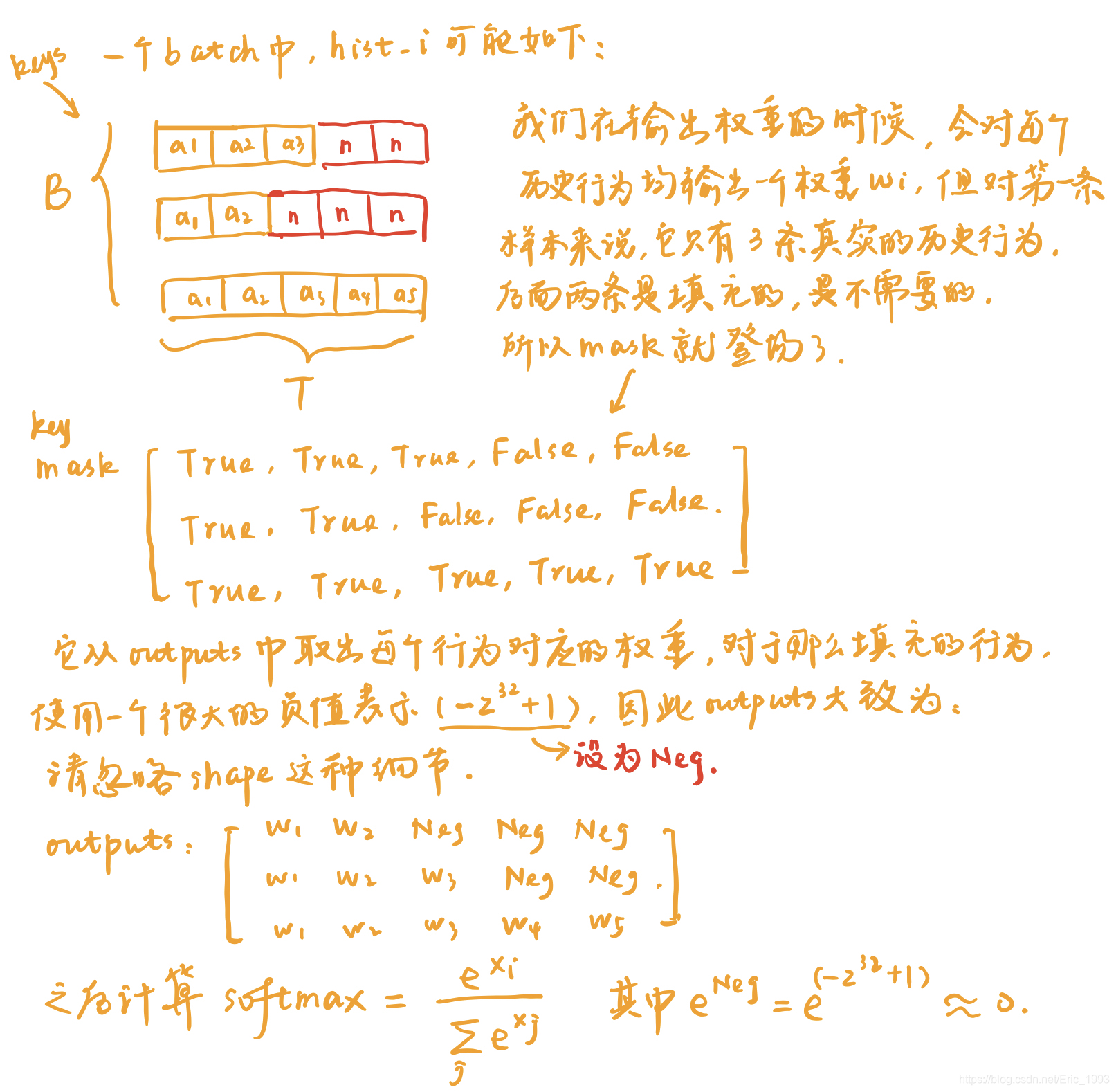
# Mask
## 由于一个 Batch 中的用户行为序列不一定都相同, 其真实长度保存在 keys_length 中
## 所以这里要产生 masks 来选择真正的历史行为
key_masks = tf.sequence_mask(keys_length, tf.shape(keys)[1]) # [B, T]
key_masks = tf.expand_dims(key_masks, 1) # [B, 1, T]
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
## 选出真实的历史行为, 而对于那些填充的结果, 适用 paddings 中的值来表示
## padddings 中使用巨大的负值, 后面计算 softmax 时, e^{x} 结果就约等于 0
outputs = tf.where(key_masks, outputs, paddings) # [B, 1, T]
# Scale
outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)
# Activation
outputs = tf.nn.softmax(outputs) # [B, 1, T]
# Weighted sum
## outputs 的大小为 [B, 1, T], 表示每条历史行为的权重,
## keys 为历史行为序列, 大小为 [B, T, H];
## 两者用矩阵乘法做, 得到的结果就是 [B, 1, H]
outputs = tf.matmul(outputs, keys) # [B, 1, H]
return outputs
代码中给了详细的注释. 其中, Local Attention Unit 的输入除了候选广告的 embedding 以及用户历史行为的 embedding, 还有它们之间的交叉特征:
## queries 传入候选广告的 embedding, keys 传入用户历史行为的 embedding
## queries-keys, queries*keys 均为交叉特征
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
outputs = DNN(din_all) ## 简略代码, 用来说明问题
之后 din_all 会输入到 DNN, 以产生权重, 相当于完成下面的步骤:
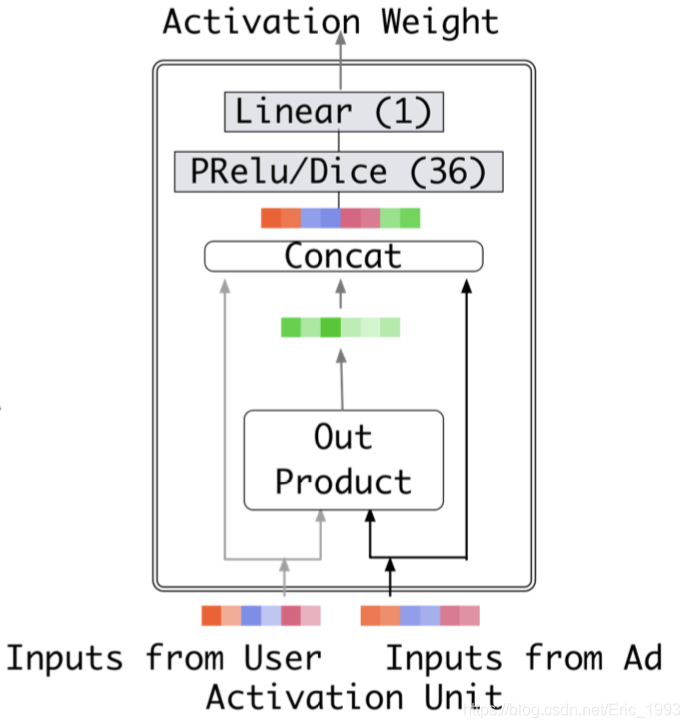
之后进行的重要一步是 产生 Mask, 这是因为:
得到正确的权重 outputs 以及用户历史行为序列 keys, 再进行矩阵相乘得到用户的兴趣表征:
# Weighted sum
## outputs 的大小为 [B, 1, T], 表示每条历史行为的权重,
## keys 为历史行为序列, 大小为 [B, T, H];
## 两者用矩阵乘法做, 得到的结果就是 [B, 1, H]
outputs = tf.matmul(outputs, keys) # [B, 1, H]
此外, 作者还定义了名为 attention_multi_items 的函数,
def attention_multi_items(queries, keys, keys_length):
它的逻辑和上面的 attention 完全一样, 只不过, 上面 attention 函数处理的 query 只有一个候选广告, 但是这里 attention_multi_items 一次处理 N 个候选广告.
全连接层
这个没啥好说的, din_i 中:
u_emb_i: 由 Attention 层得到的输出结果, 表示用户兴趣;i_emb: 候选广告对应的 embedding;u_emb_i * i_emb: 用户兴趣和候选广告的交叉特征;
din_i = tf.concat([u_emb_i, i_emb, u_emb_i * i_emb], axis=-1)
din_i = tf.layers.batch_normalization(inputs=din_i, name='b1')
d_layer_1_i = tf.layers.dense(din_i, 80, activation=tf.nn.sigmoid, name='f1')
#if u want try dice change sigmoid to None and add dice layer like following two lines. You can also find model_dice.py in this folder.
# d_layer_1_i = tf.layers.dense(din_i, 80, activation=None, name='f1')
# d_layer_1_i = dice(d_layer_1_i, name='dice_1_i')
d_layer_2_i = tf.layers.dense(d_layer_1_i, 40, activation=tf.nn.sigmoid, name='f2')
# d_layer_2_i = tf.layers.dense(d_layer_1_i, 40, activation=None, name='f2')
# d_layer_2_i = dice(d_layer_2_i, name='dice_2_i')
d_layer_3_i = tf.layers.dense(d_layer_2_i, 1, activation=None, name='f3')
如下图: (作者的 dense 节点设置和图中不完全相同)
总结
博客写到这里, 终于结束了. 勉为其难的总结一下吧, 其实就两个字: 真的累~


















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









