




总论中对PPStructure核心类做了概要介绍,本文旨在详解核心类之一:StructureSystem类。
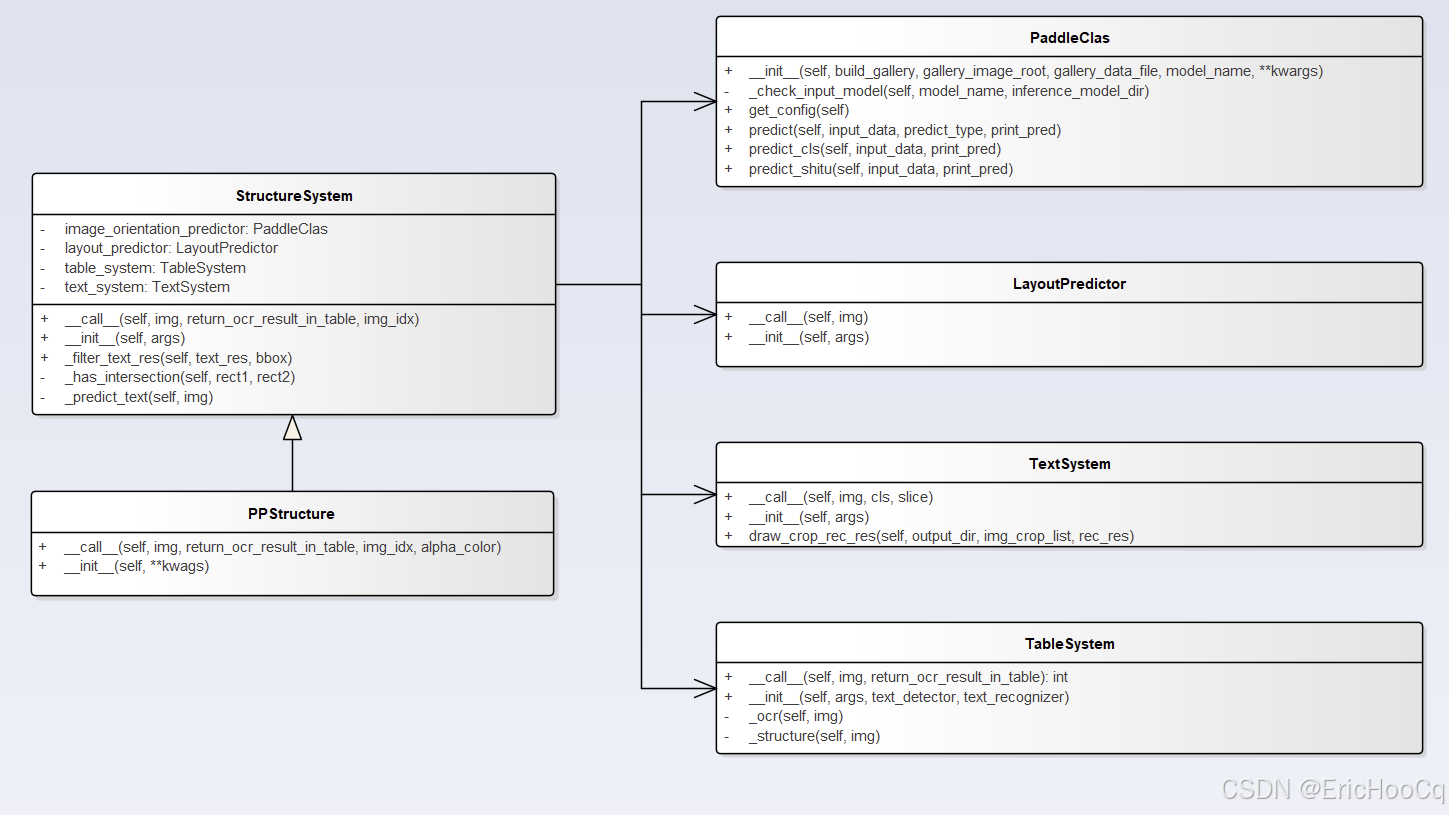
回顾下总论中的内容,StructureSystem类是PPStructure的父类,其代码在paddleocr/ppstructure/predict_system.py文件中,负责版面分析(structure模式)与关键信息提取(kie模式)的功能实现,相互关系可以参照类图。
本文首先详细解释StructureSystem类的__init__与__call__方法,接着通过代码实验,进一步了解该类的实现原理与用法。
构造函数__init__方法
构造函数用于构造StructureSystem类的实例,是使用该类的前提。构造函数位于predict_system.py文件的第44行,定义如下:
def __init__(self, args)
可见,只要传入一个参数对象args即可,系统并没有对参数对象的类进行任何约束,看起来非常简单。但是,如果仔细阅读源码,可以看出构造函数中对args对象的属性有最小集要求。亦即传入的args参数对象,至少应该包含源码中使用到的属性,否则会报错。以下是args必须包含的属性列表:
- args.mode 代表模式,可以为structure或者kie
- args.recovery 代表是否启用恢复训练,可以为True或者False
- args.image_orientation 代表是否启用图像排版方向分类模型,可以为True或者False
- args.layout 代表是否启用版面分析模型,可以为True或者False
- args.ocr 代表是否启用文本识别模型,可以为True或者False
- args.table 代表是否启用表格解析模型,可以为True或者False
- args.show_log 代表是否显示日志信息,可以为True或者False
- args.return_word_box 代表是否返回表格中每个文本的边界框坐标,可以为True或者False
- args.layout_model_dir代表版面分析模型的路径
- args.det_model_dir代表文本检测模型的路径
- args.rec_model_dir代表文本识别模型的路径
- args.table_model_dir代表表格解析模型的路径
- args.layout_dict_path代表版面分析模型配套字典路径
- args.rec_char_dict_path代表文本识别模型配套字典路径
- args.table_char_dict_path代表表格解析模型配套字典路径
上述清单中,大部分参数是bool和str类型,其中的四个模型路径和三个字典路径,都不能设置错误,否则将导致系统运行异常或者解析结果异常。一般情况下,可以通过设置args.structure_version和args.lang两个参数来控制版面分析、表格解析模型;通过设置 args.ocr_version和args.lang两个参数来控制文本检测与识别模型。PPStructure会自动下载相关模型,解压缓存到本地路径,正确设置相关参数。对源码足够理解深入时,可以自己下载解压模型,并设置模型与配套字典路径。官网的模型清单如下(注意下载时模型model与字典dict要配套):
面对如此多的参数设置,如果完全自定义一个类,仅仅完成一系列属性的设置,将极为繁琐且无趣。如果能够利用现有代码,必如清风拂面般惬意。下面推荐几个实用的函数:
- parse_args函数,代码在paddleocr/paddleocr.py文件中。函数使用了argparse模块,从命令行获取参数配置,并构造参数对象返回。所有PP-Structure/PP-OCR代码运行中需要的属性,均已具备,并设置了默认值。
- get_model_config函数,代码在paddleocr/paddleocr.py文件中。函数获取默认的模型配置,需要传入type、version、model_type、lang四个参数。其中type代表模型类型,可以为OCR或者STRUCTURE;version代表模型版本,ocr模型支持PP-OCR/PP-OCRv2/PP-OCRv3/PP-OCRv4四个版本,structure模型支持PP-Structure/PP-StructureV2两个版本;model_type代表模型类型,包括det/rec/table/layout/cls等,分别代表文本检测/文本识别/表格解析/版面分析/图像分类;lang代表语言,支持en/ch等。
- confirm_model_dir_url函数,代码在paddleocr/ppocr/utils/network.py中。函数用于优先使用本地路径model_dir,在本地路径未设置的情况下再使用default_url(网上下载位置)地址,需要传入model_dir、default_model_dir、default_url三个参数。
- maybe_download函数,代码在paddleocr/ppocr/utils/network.py中。函数判断本地路径下是否包含.pdiparams/.pdiparams.info/.pdmodel等模型文件,如果没有,将从网上下载并解压到指定目录。需要传入model_storage_directory和url两个参数,用于设置模型本地存储路径与网上下载地址。
魔法函数__call__
上节的构造函数完成了实例基础设置,真正体现功能的地方在魔法函数__call__。函数位于predict_system.py文件的第89行,定义如下:
def __call__(self, img, return_ocr_result_in_table=False, img_idx=0)
传入参数解释如下:
- img参数,图像数据三维张量,形状为[h,w,3],分别代表图像高度、图像宽度、通道数(RGB)
- return_ocr_result_in_table参数,是否返回表格中的ocr识别结果,默认为False。如果改为True,那么不仅返回表格识别的html结果,还要返回表格中每个文本要素。文本要素包括边界框、文本、置信度等信息。
- img_idx参数,代表图像序号,在多次调用时区分识别结果。假如有个多页的pdf文件,需要识别其中的所有表格,那么通常的处理逻辑是逐页载入并识别,最后合并各页结果,这时候页码就是天然的img_idx参数值。__call__函数的返回值中,会加入img_idx属性,用于将图像序号与识别结果串联。
魔法函数__call__将利用配置中的四大模型,完成版面分析、文本检测、文本识别、表格解析等功能,返回识别结果。其返回值包含res_list与time_dict两项:
- res_list
第一项返回值是一个结果列表,列表中的每一项代表一个版面要素。每个识别到的版面要素是一个字典,包含以下属性:- type 要素类型标签,字符串str类型,值来自于版面分析模型配套字典。以官方字典为例,table代表表格,title代表标题,equation代表公式
- bbox 要素边界框,列表list类型,包含四个整数值,分别是左上角x、左上角y、右下角x、右下角y
- img 要素图像切片数据,NumPy张量ndarray类型,形状为[slice_h,slice_w,3],分别代表切片高度、切片宽度、通道数。程序调试时,可以将此切片数据导出为jpg文件,查看切片位置是否合理。从验证的角度看,slice_h应该与bbox[3]-bbox[1]相等,slice_w应该与bbox[2]-bbox[0]相等。
- res 要素识别结果,字典dict类型。该字典包含以下属性:
- cell_bbox 单元格边界框数组,列表list类型,列表中每一项是表格的单元格边界框坐标。单元格边界框用八个浮点数的数组表示,分别代表左上角x、左上角y、右上角x,右上角y、右下角x、右下角y、左下角x、左下角y。
- boxes 文本检测模型得到的各文本框数组,列表list类型,列表中每一项是一个文本边界框坐标。文本边界框用四个浮点数的数组表示,分别代表左上角x、左上角y、右下角x、右下角y。注意,此属性只在__call__函数传入参数return_ocr_result_in_table为True时才返回。
- rec_res是文本识别模型得到的结果数组,列表list类型,每一项代表一段文本。每段文本用三元组tuple表示,元组第一项是文本,第二项是置信度,第三项是文本分词详情。注意,此属性只在__call__函数传入参数return_ocr_result_in_table为True时才返回。
- html是表格解析模型结果,字符串str类型,用标准的HTML语言来描述表格结构和内容。
- img_idx 图片顺序号,整型
- score 代表识别置信度,浮点型。置信度越高,代表识别结果越准确。
- time_dict
第二项返回结果是耗时记录,字典dict类型,用于获取识别解析过程中各步骤耗时与总耗时。字典包含以下属性:- image_orientation 代表图像方向分类模型耗时
- layout 代表版面分析模型耗时
- table 代表表格解析模型耗时
- table_match 代表表格结构与内容匹配模型耗时
- det 代表文本检测模型耗时
- rec 代表文本识别模型耗时
- kie 代表关键信息提取模型耗时
- all代表总耗时
实验一:表格内容提取
第一个实验的目标,是直接使用StructureSystem类,识别总论示例代码用到的官方图片,主要代码如下:
args = construct_engine_params()
structure_system = StructureSystem(args)
img = cv2.imread('./img/table1.jpg')
res_list, time_dict = structure_system(img, return_ocr_result_in_table=True)
logger.debug(f'task finished with time elapsed as follows.')
logger.debug(f'all: {
time_dict["all"]}')
logger.debug(f'layout:{time_dict['layout']} table:{time_dict['table']} det:{time_dict['det']} rec:{time_dict['rec']}')
if len(res_list) == 1 and res_list[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}