






简介
ELK技术:elasticsearch + logstash + kibana
ELK基础
ELK 是什么
ELK 是 Elasticsearch、Logstash、 Kibana 三大开源框架首字母大写简称。其中 Elasticsearch 是一个基于 Lucene、分布式、通过 Restful方式进行交互的近实时搜索平台框架。 像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用 Elasticsearch 作为底层支持框架。
Logstash 是 ELK 的中央数据流引擎,用于从不同目标(文件/数据存储/MQ )收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
Kibana可以将 elasticsearch 的数据通过友好的页面展示出来 ,提供实时分析的功能。
一般认为 ELK 是一个日志分析架构技术栈总称,但实际上 ELK 不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景。
即 Logstash 收集数据,ES 过滤数据,Kibana 配合展示数据。
Elaticsearch
以前我们查数据查信息,是用的 SQL,然后用的是 like %搜索关键字%,但如果是大数据的场景下,就会很慢,然后我们就会去建立索引以提高查询速度,但是 %搜索关键字%,左侧的 百分号 会使得索引失效。这时候就需要搜索效率较高的分布式的全文搜索引擎 ElasticSearch。ES 也可以来当数据库,但是不建议。
Lucene 是 Doug Cutting 的开源的 Java 全文检索项目,是一个 jar包,引入就可以直接使用。Hadoop 也是 Doug Cutting 的。
Elaticsearch,简称为es,是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时地存储、检索数据,本身扩展性很好,可以扩展到上百台服务器,处理 PB级别(大数据时代)的数据。
ElasticSearch 是基于 Lucene 做了封装和增强,es 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,让全文搜索变得简单。
Solr 和 ES 对比
简介
ES:全文搜索、结构化搜索、分析。
Solr 也是 Apache下的项目,也是使用 Java 开发的,也是基于 Lucene。
对比
-
单纯对已有的数据进行搜索时,即已经存在于服务器里面了,Solr 更快。
-
当实时建立索引时,ES 快,Solr 会产生 IO阻塞,查询性能较差。
-
随着数据量的增加,Solr 的搜索效率会变低,而 ES 几乎没有明显变化。
总结
-
es 基本是开箱即用,非常简单。Solr安装略微复杂
-
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
-
Solr 支持更多格式的数据,比如 JSON、XML、CSV,而 ES 仅支持 json 文件格式。
-
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要 kibana 友好支撑
-
Solr 查询快,但更新索引时慢(即插入、删除慢),用于电商等查询多的应用
-
ES 建立索引快(即查询慢),即实时性查询快,用于 facebook、新浪等搜索。
-
Solr 是传统搜索应用的有力解决方案,但 ES 更适用于新兴的实时搜索应用。
-
-
Solr 比较成熟,有一个更大、更成熟的用户、开发和贡献者社区,而 ES 相对开发维护者较少,更新太快,学习使用成本较高。
3、ES 的下载安装和插件的下载
3.1、ES 下载
官网:Elastic — The Search AI Company | Elastic
进官网下载压缩包即可,
3.1.1、Windows 下安装和启动
解压到指定目录即可使用,
运行 bin/elasticsearch.bat 即可启动
在 bin目录下 cmd,输入 elasticsearch-plugin list,可以查看已加载的插件
3.1.1.1、目录结构
bin 启动文件 config 配置文件 log4j2.properties 日志配置文件 jvm.options 虚拟机需求配置,若内存较小一定要修改 -Xms,比如 -Xms256m elasticsearch.yml es 的配置文件,默认 9200端口,通信地址 9300 lib 相关 jar包 modules 功能模块 plugins 插件,比如把 ik分词器放进去
3.2、插件下载
3.2.1、head
地址:https://github.com/mobz/elasticsearch-head/
下载完之后如果下的是压缩文件就解压到指定目录,然后进入文件夹,进行 cmd。(首先需要 node 环境)
npm install (或 cnpm install) npm run start
3.2.1.1、使用
这个是 ES 的可视化图形界面工具,地址是 9100,但是因为端口不一样,所以访问 9200 会产生跨域问题。
所以需要在 elasticsearch.yml 中进行配置,解决跨域,加上以下这段:
http.cors.enabled: true http.cors.allow-origin: "*"
4、Kibana下载安装
4.1、简介
Kibana是一个针对Elasticsearch的开源分析及 可视化平台,用来搜索、查看交互存储在Elasticsearch索弓 |中的数据。使用Kibana ,
可以通过各种图表进行高级数据分析及展示。Kibana让海 量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪
表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成
Kibana安装并启动Elasticsearch索引监测。
4.2、下载安装
官网:https://www.elasticsearch.co/cn/kibana
下载到压缩包之后解压到指定目录,运行 bin/kibana.bat 即可启动。端口在 5601。
汉化的配置文件在 x-pack\plugins\translations\translations 里面。
使用汉化需要在 config/kibana.yml 的最后加上汉化配置:
i18n.locale: "zh-CN"
5、ES核心概念
5.1、简介
ES 是面向文档的,一切都是 json,
| Relation DB(关系型数据库) | ElasticSearch |
|---|---|
| 数据库(database) | 索引(index) |
| 表(table) | types(已过时) |
| 行(row) | document |
| 字段(column) | field |
5.2、设计
-
物理设计:ES 在后台把每个索引划分成多个分片,每片分片可以在集群中的不同服务器间迁移。一个人就是一个集群,默认的集群名称就是 elasticsearch
-
逻辑设计:一个索引类型中可以有多个文档,
5.3、索引、类型、文档
索引就是数据库,
类型就分类,比如食品类,工具类等,
文档就是一条具体数据,文档是 json,是 k:v 形式的,可以是层次型的,
一个集群至少一个节点,一个节点就是一个 es进程,如果创建索引,那么索引将会有 5个分片组成(primary shard,又称主分片)构成,每个主分片会有一个副本(replica shard,又称复制分片)。
主分片对应的复制分片都不会在同一个节点内,作用利于某个节点挂掉后数据不会丢失。
一个分片是一个 Lucene索引,一个包含倒排索引的文件目录。倒排索引的结构使得 ES 在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
即一个 ES索引其实底层是由多个 Lucene索引组成的,Lucene 使用倒排索引,就可以不使用 like关键字了,而是使用额外的空间存储倒排索引,即用空间换时间。
5.3.1、倒排索引
ES 使用的结构是倒排索引,采用 Lucene倒排索引作为底层,这种结构适用于全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
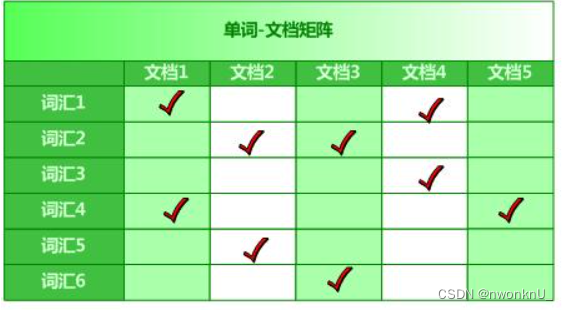
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词-文档矩阵就是一个矩阵,列是文档,行是单词,然后若文档包含此单词,就进行标记。然后根据指定的单词数组进行匹配,匹配程度越高的代表权重越大,在 ES 中就是 _score。
5.4、数据类型
-
字符串类型:text、keyword(text 支持分词,keyword 不支持)
-
数值类型:long、integer、short、byte、double、float、half float、scaled float
-
日期类型:date
-
布尔值类型:boolean
-
二进制类型:binary
6、IK分词器
6.1、简介
分词:即把一段文本划分成一个个关键字,然后进匹配操作,中文的话会默认把每个字都划分成一个词。
IK分词器提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 是最少划分,ik_max_word 是最细粒度划分。
6.2、下载
官网:https://github.com/medcl/elasticsearch-analysis-ik
下载完毕后解压到 ES文件夹的 plugins文件夹,然后把 ik 这个文件夹的名称改成 ik,名字可以不是 ik,需要自己去查询相应知识。
6.3、kibana 中简单使用分词器
ik_smart 是将一段话打断点划分掉,每个词不会有重复使用的地方,比如:中国共产党。
而 ik_max_word 是举例所有可能,比如:中国共产党,中国,国共,共产党,共产,党。
但有时候可能有想要合并在一起进行查询的词被划分掉了,这时候就需要我们自己把词加入到分词器的字典中。可以创建一个 dic文件放到 elasticsearch-7.6.1\plugins\ik\config\ 目录下,然后再在 IKAnalyzer.cfg.xml 中的 <entry key="ext_stopwords"></entry> 里面将我们新建的文件全名放进去。如果有多个,就写多个 entry。
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
7、Rest风格操作
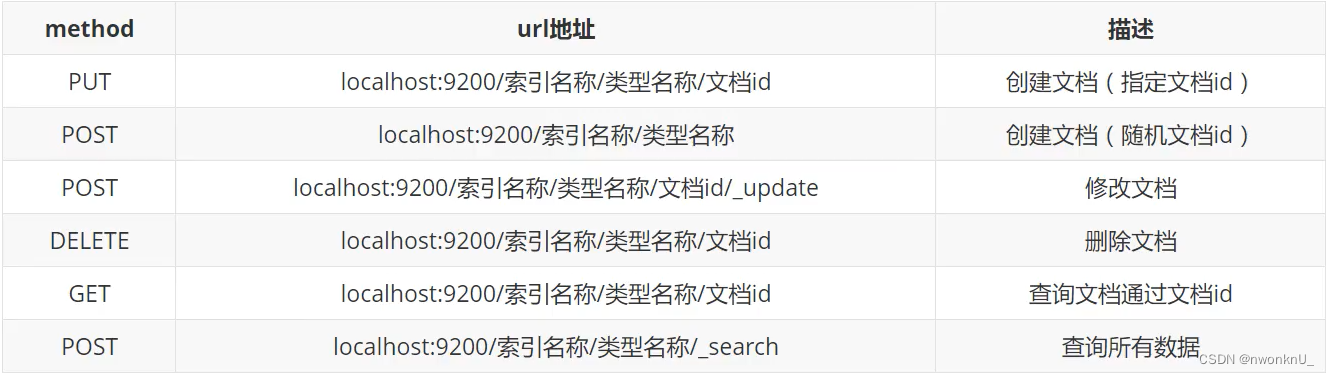
7.1、PUT 创建、更新
// 创建指定索引库指定类型指定文档id 的文档
// 对同一个文档 PUT 不同数据也可以去修改,就是覆盖了,
// 但是如果你少写了一个字段,就相当于传了 null 过去,所以推荐使用 _update
PUT /index1/type1/1
{
"name": "chw",
"age": 15
}
// 创建指定索引库,设置其规则
PUT /index1
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
// 创建指定索引库指定类型指定文档id 的文档
PUT /index2/type1/1
{
"name": "chw",
"age": 15
}
// _doc 就是默认的类型,可以写出来,也可以不写,type 已经过时不用了
// ES 会默认识别数据类型,然后使用最匹配的数据类型
PUT /index3/_doc/1
{
"name": "chw",
"age": 15,
"birthday": "1997-01-05",
"tags": ["二刺螈","直男"]
}
7.2、GET 查询
// 查询对应索引库的基本信息 GET index2(或者 /index2) // 查询 ES 的信息 GET _cat/health GET _cat/indices?v
7.3、POST 更新
POST /index3/_doc/1/_update
{
"doc": {
"name": "修改后的名字"
}
}
7.4、DELETE删除
DELETE index1
8、花式查询
GET index3/type1/_search?q=name:chw
GET /xxx-dev*/container_log/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"log_time": {
"gte": "now-14d/d",
"lte": "now-13d/d"
}
}
},
{
"match": {
"log_level": "INFO"
}
},
{
"query_string": {
"default_field": "log",
"query": "系统日志 AND 83c401c012e34892a73e13fd6bab88b1.436925.16517091000101945"
}
}
]
}
},
"_source": ["log", "log_level", "log_time"],
"from": 0,
"size": 5,
"sort": [
{
"log_time": {
"order": "asc"
}
}
]
}
8.1、模糊匹配
_score 就是匹配度,匹配度越高,则分值越高。hits是查询结果数组,就是索引和文档的信息,即每一个 {} 就是一个文档。
_source 就是根据 query 的结果来选择想要的字段,过滤结果,就相当于 SQL语句的 SELECT。
sort 就是排序,在里面指定想排序的字段,然后在字段中指定 order 是 desc/asc。
分页就通过 from和size 两个关键字指定,即开始和需要数量。下标从 0 开始。
匹配多个条件就通过空格分隔即可,比如:"tags": "男 技术 旅游",多个条件之间只要能匹配上 1个,就可以被查询出来,匹配程度越高,_score的分值越高。
GET /xxx-dev-202204*/container_log/_search
{
"query": {
"match": {
"log": "系统日志"
}
},
"_source": ["name","age","desc"],
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0,
"size": 2
}
bool就是布尔查询,must 可以进行多 match 操作,即多条件查询,and 连接。 如果将 must 改成 should,那就变成了 or 连接。
not 就是 must_not。
可以在 bool 中加过滤器 filter,进行数据过滤。
GET /xxx-dev-202204*/container_log/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "chw"
}
},
{
"match": {
"age": "18"
}
},
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
}
}
8.2、精确匹配
term 查询是直接通过 倒排索引 指定的词条进行精确查找的。效率比 match 高。
match 则会使用 分词器解析,先分析文档,再通过分析过的文档进行查询。
两个类型:text、keyword。text 可以被分词器解析,而 keyword 是不能被分词器解析的。
还可以通过 bool+should 来精确查询多个。
// 先去设置 name 的分词器匹配类型是 keyword,才会变成精确查找,不会被分词器解析
GET /xxx-dev-202204*/container_log/_search
{
"query": {
"term": {
"name": "ch"
}
}
}
GET /xxx-dev-202204*/container_log/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": "c"
}
},
{
"term": {
"name": "ch"
}
},
]
}
}
}
8.3、高亮查询
查询完之后,加上 highlight 关键字,然后指定字段。它会给你加上 <em>标签,当然可以自定义所加的标签,通过 pre_tags、post_tags 自定义加上的前后缀标签。
GET /xxx-dev-202204*/container_log/_search
{
"query": {
"match": {
"name": "ch"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
9、SpringBoot集成ES
9.1、依赖引入
记得要查看版本是否与要连接的 ES 版本一致,否则可能连接不上。
<!-- 非 SpringBoot项目 --> <dependency> <gtoupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.6.2</version> </dependency> <properties> <elasticsearch.version>7.6.1</elasticsearch.version> </properties> <dependency> <gtoupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
9.2、写一个 config
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
return new RestHighLevelClient(RestClient.builder(
// 集群的话就 new 多个 HttpHost,用 , 分隔。"http" 这个参数可以不加,即允许使用 https
new HttpHost("127.0.0.1", 9200, "http")
));
}
}
9.3、使用 Client
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public Page<DocumentResponseVO> listPageMatch(SearchLogVo searchLogVo) {
List<DocumentResponseVO> list = new ArrayList<>();
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 过滤结果字段
String[] fields = {"log", "log_level", "log_time"};
FetchSourceContext sourceContext = new FetchSourceContext(true, fields, Strings.EMPTY_ARRAY);
searchSourceBuilder.fetchSource(sourceContext);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 匹配查询
List<String> collect = new ArrayList<>();
if (ObjectUtil.isNotNull(searchLogVo.getKeyword())) {
collect = Lists.newArrayList(searchLogVo.getKeyword());
}
if (!collect.contains("系统日志")) {
collect.add("系统日志");
}
if (!StringUtils.isEmpty(searchLogVo.getTid()) && !collect.contains(searchLogVo.getTid())) {
collect.add(searchLogVo.getTid());
}
// collect = collect.stream()
// .map(it -> "log:\"" + it + "\"")
// .collect(Collectors.toList());
String join = Joiner.on(" AND ").join(collect);
QueryStringQueryBuilder keywordQueryBuilder = QueryBuilders.queryStringQuery(join);
// keywordQueryBuilder.defaultField("*");
keywordQueryBuilder.field("log");
boolQueryBuilder.must(keywordQueryBuilder);
// 时间范围条件
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("@timestamp");
rangeQueryBuilder.gte(searchLogVo.getBeginDate().getTime());
rangeQueryBuilder.lte(searchLogVo.getEndDate().getTime());
/// 时间格式
rangeQueryBuilder.format("epoch_millis");
// rangeQueryBuilder.format("yyyy-MM-dd hh:mm:ss");
boolQueryBuilder.must(rangeQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
// 分页
searchSourceBuilder.from(searchLogVo.getFrom());
searchSourceBuilder.size(searchLogVo.getSize());
// 请求响应时间
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 排序
searchSourceBuilder.sort("@timestamp", SortOrder.DESC);
// 若以 * 结尾,则根据日期精确索引范围
List<String> dateIndex = new ArrayList<>();
String index = searchLogVo.getIndex();
if (index.endsWith("*")) {
DateTime beginDate = new DateTime(searchLogVo.getBeginDate());
beginDate = beginDate.withTime(0, 0, 0, 0);
DateTime endDate = new DateTime(searchLogVo.getEndDate());
while (beginDate.isBefore(endDate)) {
dateIndex.add(beginDate.toString("yyyyMMdd"));
beginDate = beginDate.plusDays(1);
}
String[] split = index.split("-");
if (split.length == 2) {
index = index.substring(0, index.length() - 1);
} else if (split.length == 3) {
index = index.substring(0, index.lastIndexOf("-"));
} else {
throw new RuntimeException("暂不知其他索引情况");
}
String finalIndex = index;
dateIndex = dateIndex.stream()
.map(it -> finalIndex + "-" + it + "*")
.collect(Collectors.toList());
}
SearchRequest searchRequest = new SearchRequest(dateIndex.toArray(new String[dateIndex.size()]));
searchRequest.source(searchSourceBuilder);
SearchResponse search = null;
try {
// ES查询
search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
log.error("ES查询出错:{}", e.getMessage(), e);
}
// 获取命中结果
SearchHits searchHits = search.getHits();
if (!ObjectUtils.isEmpty(searchHits.getHits())) {
SearchHit[] hits = searchHits.getHits();
list = Arrays.stream(hits)
.map(DocumentResponseVO::hitsMappingDocumentResponse)
.peek(DocumentResponseVO::initSource)
.collect(Collectors.toList());
}
long totalHits = searchHits.getTotalHits();
int ceil = (int) Math.ceil(totalHits / (searchLogVo.getSize() * 1.0));
Page<DocumentResponseVO> page = new Page<>();
if (searchLogVo.getFrom() == 0) {
page.setCurrent(1);
} else {
page.setCurrent(searchLogVo.getFrom() / searchLogVo.getSize() + 1);
}
page.setPages((long) ceil)
.setTotal(totalHits)
.setSize(searchLogVo.getSize())
.setRecords(list);
return page;
}
10、关于索引的API操作
10.1、创建索引
void createIndexTest(){
// 1、得到创建索引的请求
CreateIndexRequest createIndexRequest = new CreateIndexRequest("index1");
// 2、客户端执行请求,获得响应
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
}
10.2、获取索引
void getIndexTest(){
GetIndexRequest getIndexRequest = new GetIndexRequest("index1");
boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
if (exists) {
GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
}
}
10.3、删除索引
void deleteIndexTest(){
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("index1");
DeleteIndexResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
11、关于文档的API操作
public void initSource() {
String logString = (String) sourceAsMap.get("log");
String tid = logString.substring(logString.indexOf("TID") + 4, logString.indexOf("]"));
this.tid = tid;
String[] split = logString.split("c.p.health.aop.log.BaseAopLog -", 2);
if (split.length == 2) {
String subLog = split[1];
subLog = StringUtils.trim(subLog);
subLog = StringUtils.replace(subLog, "\n", "");
subLog = StringUtils.replace(subLog, "\t", "");
if (ObjectUtils.isEmpty(this.source)) {
this.source = JsonUtils.json2pojo(subLog, RespLogVo.class);
}
}
}
public static DocumentResponseVO hitsMappingDocumentResponse(SearchHit hit) {
DocumentResponseVO doc = new DocumentResponseVO();
doc.setDocId(hit.getId())
.setIndex(hit.getIndex())
.setType(hit.getType())
.setSourceAsMap(hit.getSourceAsMap())
.setSourceAsString(hit.getSourceAsString())
.setScore((double) hit.getScore())
.setLogLevel((String) hit.getSourceAsMap().get("log_level"));
return doc;
}
==================================================
@Override
public Page<DocumentResponseVO> listPageMatch(SearchLogVo searchLogVo) {
List<DocumentResponseVO> list = new ArrayList<>();
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 过滤字段
String[] fields = {"log", "log_level", "log_time"};
FetchSourceContext sourceContext = new FetchSourceContext(true, fields, Strings.EMPTY_ARRAY);
searchSourceBuilder.fetchSource(sourceContext);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 时间范围条件
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("log_time");
rangeQueryBuilder.gte(searchLogVo.getBeginDate());
rangeQueryBuilder.lte(searchLogVo.getEndDate());
/// 时间格式
// rangeQueryBuilder.format("yyyy-MM-dd hh:mm:ss");
boolQueryBuilder.must(rangeQueryBuilder);
// 日志级别
// 需将 log_level 的 type 设置成 keyword 后才可用 TermQueryBuilder
List<String> logLevelList = Lists.newArrayList(searchLogVo.getLogLevel());
String logLevelQueryString = Joiner.on(" OR ").join(logLevelList);
QueryStringQueryBuilder logLevelQueryBuilder = QueryBuilders.queryStringQuery(logLevelQueryString);
logLevelQueryBuilder.field("log_level");
boolQueryBuilder.must(logLevelQueryBuilder);
// 匹配查询
List<String> keywordList = new ArrayList<>();
if (ObjectUtil.isNotNull(searchLogVo.getKeyword())) {
keywordList = Lists.newArrayList(searchLogVo.getKeyword());
}
if (!keywordList.contains("系统日志")) {
keywordList.add("系统日志");
}
if (!StringUtils.isEmpty(searchLogVo.getTid())) {
keywordList.add(searchLogVo.getTid());
}
String keywordQueryString = Joiner.on(" AND ").join(keywordList);
QueryStringQueryBuilder keywordQueryBuilder = QueryBuilders.queryStringQuery(keywordQueryString);
keywordQueryBuilder.field("log");
boolQueryBuilder.must(keywordQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
// 分页对象
searchSourceBuilder.from(searchLogVo.getFrom());
searchSourceBuilder.size(searchLogVo.getSize());
// 请求响应时间
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 排序
searchSourceBuilder.sort("@timestamp", SortOrder.ASC);
SearchRequest searchRequest = new SearchRequest(searchLogVo.getIndex());
searchRequest.source(searchSourceBuilder);
SearchResponse search = null;
try {
// ES查询
search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
log.error("ES查询出错:{}", e.getMessage(), e);
}
// 获取命中结果
SearchHits searchHits = search.getHits();
if (!ObjectUtils.isEmpty(searchHits.getHits())) {
SearchHit[] hits = searchHits.getHits();
list = Arrays.stream(hits)
.map(DocumentResponseVO::hitsMappingDocumentResponse)
.peek(DocumentResponseVO::initSource)
.collect(Collectors.toList());
}
long totalHits = searchHits.getTotalHits();
int ceil = (int) Math.ceil(totalHits / (searchLogVo.getSize() * 1.0));
Page<DocumentResponseVO> page = new Page<>();
if (searchLogVo.getFrom() == 0) {
page.setCurrent(1);
} else {
page.setCurrent(searchLogVo.getFrom() / searchLogVo.getSize() + 1);
}
page.setPages((long) ceil)
.setTotal(totalHits)
.setSize(searchLogVo.getSize())
.setRecords(list);
return page;
}
11.0、使用注意
11.0.1、使用 TermQueryBuilder 时需注意
使用精确查找时经常会失败,是因为你没将精确查询的字段的 type 设置成 keyword
.startObject("cyzjdm").field("type", "keyword").field("index", false).endObject()
term 做精确查询可以用它来处理数字,布尔值,日期以及文本。查询数字时问题不大,但是当查询字符串时会有问题。 term 查询的含义是 termQuery 会去倒排索引中寻找确切的 term,但是它并不知道分词器的存在。term 表示查询字段里含有某个关键词的文档,terms表示查询字段里含有多个关键词的文档。
也就是说直接对字段进行 term 本质上还是模糊查询,只不过不会对搜索的输入字符串进行分词处理罢了。如果想通过 term 查到数据,那么 term 查询的字段在索引库中就必须有与 term 查询条件相同的索引词,否则无法查询到结果。
即 elasticsearch 里默认的 IK分词器是会将每一个中文都进行了分词的切割,所以你直接想查一整个词,或者一整句话是无返回结果的。
11.0.1.1、关于 keyword
有的文章说设置该属性用于关键词搜索,不进行分词。对于字符串类型的字段,es 会默认生成一个 keyword字段用于精确搜索。也有的说实际上还是会分词,只不过keyword的设置增加了一个额外字段,该字段就是 filename.keyword。这个 keyword 才是不分词的索引字段,也就真正意义上实现了不分词处理字段。索引也是索引该字段才生成真正的精确匹配。至于分不分词实验一下就好了。感觉他们想表达的意思差不多是 filename.keyword 不分词,但是 filename 还是会分词。
11.1、添加/更新文档
// 创建请求
IndexRequest request = new IndexRequest("chw_index");
// 规则 PUT /chw_index/_doc/1
request.id("1");
// 请求的超时时间
request.timeout(TimeValue.timeValueSeconds(1));
// 把传过来的数据放入请求
request.source(JSON.toJSONString(传过来的对象), XContentType.JSON);
// 客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
11.2、获取文档
GetRequest getRequest = new GetRequest("chw_index", "1");
// 不获取返回的 _source 的上下文了
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
// 获取文档信息
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
// 文档的内容
getResponse.getSourceAsString();getResponse.getSourceAsMap();
11.3、更新文档
UpdateRequest updateRequest = new UpdateRequest("chw_index", "1");
updateRequest.timeout("1s");
// 把传过来的数据放入请求
updateRequest.doc(JSON.toJSONString(传过来的对象), XContentType.JSON);
// 执行请求命令
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
11.4、删除文档
DeleteRequest deleteRequest = new DeleteRequest("chw_index", "1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = client.delete(updateRequest, RequestOptions.DEFAULT);
11.5、批量操作
批量操作时使用 BulkRequest 对象, .什么方法,就做什么操作,最后 client.bulk,其他的操作和参数都是类似的。
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
for(int i = 0; i < xxList.size(); i++){
bulkRequest.add(
new IndexRequest("chw_index")
.id(""+(i+1))
.source(传入对象的JSOn字符串, XContentType.JSON);
)
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
bulkResponse.hasFailures();// 是否成功
11.6、查询
-
SearchRequest:搜索请求
-
SearchSourceBuilder:条件构造
-
HighlightBuilder:构建高亮
-
TermQueryBuilder: 精确查询
-
XxxQueryBuilder...
SearchRequest searchRequest = new SearchRequest ("chw_index");
// 构建搜索条件构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 查询条件构建器
// .termQuery:精确匹配,.matchAllQuery():匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "chw");
searchSourceBuilder.query(termQueryBuilder);
// from和size 有默认值
// searchSourceBuilder.from();
// searchSourceBuilder.size();
searchSourceBuilder.timeout("60s");
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 命中的结果内容
searchResponse.getHits();
12、简单上手
12.1、京东搜索
12.1.1、爬虫
12.1.1.1、jsoup依赖
解析网页,如果想要解析视频需要用 tika
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version> </dependency>
12.1.1.2、HTML 解析工具类
public class HtmlParseUtil {
public static List<Object> parseJD(String keyword) throws Exception {
// 请求地址,不能获取到 ajax
String url = "https://search.jd.com/Search?keyword=" + keyword;
// 解析网页,返回的 Document 就是页面的对象
Document document = Jsoup.parse(new URL(url), 30000);
// 获取 div元素
Element goodsElement = document.getElementById("J_goodsList");
// 获取 li 元素
Element liElement = goodsElement.getElementsByTag("li");
List<自定义对象> 自定义对象List = new ArrayList<>();
for (Element el : liElement) {
// 图片一般都是懒加载的
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
自定义对象 对象 = new 自定义对象();
// 设置对象属性值
自定义对象List.add(对象);
}
}
}
12.1.2、ES 入库、查询业务
public Boolean bulk(String keyword) {
List<自定义对象> 自定义对象List = HtmlParseUtil.parseJD(keyword);
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for(自定义对象 对象 : 自定义对象List){
bulkRequest.add(new IndexRequest("jd_goods_index")
.source(JSON.toJSONString(对象), XContentType.JSON);
)
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
public List<Map<String, Object>> pageByKeyword(String keyword, Integer pageNo, Integer pageSize) {
SearchRequest searchRequest = new SearchRequest ("jd_goods_index");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 查询条件构建器
// .termQuery:精确匹配,.matchAllQuery():匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
searchSourceBuilder.query(termQueryBuilder);
// 高亮
HighlighterBuilder highlighterBuilder = new HighlighterBuilder();
highlighterBuilder.field("title");
highlighterBuilder.requireFieldMatch(false);
highlighterBuilder.preTags("<span style='color:red'>");
highlighterBuilder.postTags("</span>");
searchSourceBuilder.highlighter(highlighterBuilder);
searchSourceBuilder.from((pageNo - 1) * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUtil.SECONDS));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 命中的结果内容
List<Map<String, Object>> result = new ArrayList<>();
for (SearchHit document : searchResponse.getHits().getHits()) {
// 解析高亮字段
Map<String, HighlightField> highlightFieldMap = document.getHighlightFields();
HighlightField title = highlightFieldMap.get("title");
Map<String, Object> sorceAsMap = document.getSourceAsMap();
if(title != null) {
Text[] fragments = title.fragments();
String newTitle = "";
for (Text text : fragments) {
newTitle += text;
}
// 解析出高亮并设置进去
sorceAsMap.put("title", newTitle);
}
result.add(sorceAsMap);
}
return result;
}

















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









