








📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


概述
本文复现论文 Wide Residual Networks[1] 提出的深度神经网络模型。
为了解决深度神经网络梯度消失的问题,深度残差网络(Residual Network[2])被提出。然而,仅为了提高千分之一的准确率,也要将网络的层数翻倍,这使得网络的训练变得非常缓慢。为了解决这些问题,该论文对ResNet基本块的架构进行了改进并提出了一种新颖的架构——宽度残差网络(Wide Residual Network),其减少了深度并增加了残差网络的宽度。
我基于Pytorch复现了该网络并在CIFAR-10[3]、CIFAR-100[3]和SVHN[4]数据集上进行试验。此外,我提供了一个基于SVHN数据集训练的数字识别系统用于体验。
本文所涉及的所有资源的获取方式:这里
模型结构
宽度残差网络共包含四组结构。其中,第一组固定为一个卷积神经网络,第二、三、四组都包含 n 个基本残差块。
基本残差块的结构如图所示:
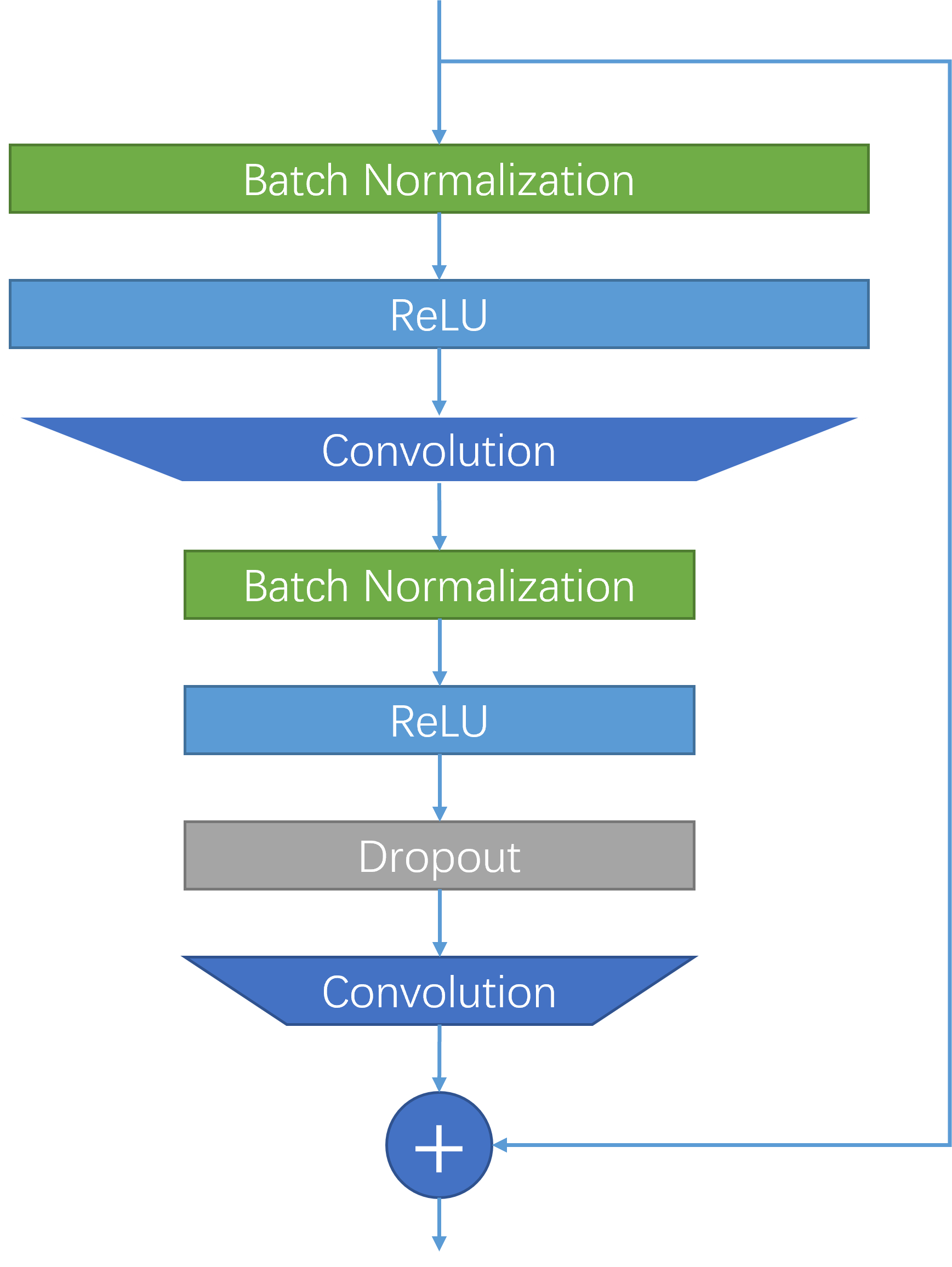
与普通的残差块不同的地方在于,普通残差块中的批归一化层和激活层都放在卷积层之后,而该论文将批归一化层和激活层都放在卷积层之前,该做法一方面加快了计算,另一方面使得该网络可以不需要用于特征池化的瓶颈层。此外,宽度残差网络成倍地增加了普通残差网络的特征通道数。
宽度残差网络在第三、四组的第一个卷积层进行下采样,即设置卷积步长为2。
核心逻辑
Wide Residual Network 的模型代码如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
class WideBasicBlock(nn.Module):
"""Wide Residual Network的基本单元"""
def __init__(self, in_channels, out_channels, stride, dropout):
super(WideBasicBlock, self).__init__()
self.stride = stride
# 批归一化层、激活层、卷积层、Dropout层
self.layers = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(dropout),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
)
def forward(self, x):
out = self.layers(x)
if self.stride != 1:
residual = F.adaptive_avg_pool2d(x, (out.size(2), out.size(3)))
else:
residual = x
if out.size(1) != residual.size(1):
# 对池化和升维的特殊处理
if out.size(1) % residual.size(1) == 0:
residual = residual.repeat(1, out.size(1) // residual.size(1), 1, 1)
else:
padding = torch.zeros(residual.size(0), out.size(1) - residual.size(1), residual.size(2), residual.size(3)).to(residual.device)
residual = torch.cat((residual, padding), dim=1)
out = out + residual
return out
class WideResidualNetwork(nn.Module):
"""Wide Residual Network"""
def __init__(self, in_channels, out_channels, depth, width, dropout=0):
super(WideResidualNetwork, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = self.add_block(
in_channels = 16,
out_channels = 16 * width,
depth = depth,
stride = 1,
dropout = dropout
)
self.conv3 = self.add_block(
in_channels = 16 * width,
out_channels = 32 * width,
depth = depth,
stride = 2,
dropout = dropout
)
self.conv4 = self.add_block(
in_channels = 32 * width,
out_channels = 64 * width,
depth = depth,
stride = 2,
dropout = dropout
)
self.linear = nn.Linear(64 * width, out_channels)
def add_block(self, in_channels, out_channels, depth, stride, dropout):
"""添加一个基本单元的组合"""
layers = nn.Sequential()
layers.add_module(
name = '0',
module = WideBasicBlock(
in_channels = in_channels,
out_channels = out_channels,
stride = stride,
dropout = dropout
)
)
for i in range(1, depth):
layers.add_module(
name = str(i),
module = WideBasicBlock(
in_channels = out_channels,
out_channels = out_channels,
stride = 1,
dropout = dropout
)
)
return layers
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.linear(out)
return out
以上代码仅作展示,更详细的代码文件请参见附件。
实验
训练与测试
所有实验基于WRN-37-2进行且使用SGD进行优化。对于CIFAR-10和CIFAR-100,学习率为0.01并在第60、120、160轮衰减到20%,dropout采用0.3,weight_decay和momentum分别为0.0005和0.9。对于SVHN,学习率为0.01并在第80、120轮衰减到10%,dropout为0,weight_decay和momentum分别为0.0005和0.9。三个数据集的batch size均为128。
此外,CIFAR-10和CIFAR-100使用了数据增强操作,具体为随机水平翻转和随机裁剪。
具体的实验结果如下表所示:
| 数据集 | 准确率 |
|---|---|
| CIFAR-10 | 94.16% |
| CIFAR-100 | 74.12% |
| SVHN | 96.95% |
在线部署
我从网络上随机截取了10张大小、颜色、形状、背景各异的数字图像。这些图片的来源包括:车牌(6、8、9)、扑克牌(3)、广告(1、2、4、5、7)、腰带卡扣(0)。测试结果显示正确率为100%。
使用方式
解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:

网站提供了在线部署功能,如若使用请输入一张小于1MB、单个数字为主体的JPG图像。
使用方式
解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:
unzip Wide-Residual-Networks.zip
cd Wide-Residual-Networks
代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt
如果希望在本地训练模型,请运行如下命令:
python main.py -d ['CIFAR-10' 、'CIFAR-100'、 'SVHN'三者其中之一]
如果希望在线部署,请运行如下命令:
python main-flask.py
参考文献
[1] Zagoruyko S, Komodakis N. Wide residual networks[J]. arXiv preprint arXiv:1605.07146, 2016.
[2] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[3] Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images[J]. 2009.
[4] Netzer Y, Wang T, Coates A, et al. Reading digits in natural images with unsupervised feature learning[C]//NIPS workshop on deep learning and unsupervised feature learning. 2011, 2011(5): 7.
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









