







股票市场的波动深刻影响全球经济和个人财富,准确预测其走势对于规避风险至关重要。尽管混合深度学习(DL)和机器学习(ML)模型在预测准确性方面展现出巨大潜力,但其高计算需求往往超出普通个人电脑的能力,限制了广泛的应用。为了应对这一挑战,本文致力于优化LightGBM(一种高效实现梯度提升决策树(GBDT)的模型),在保持低计算需求的同时实现最大性能提升。本文提出了一系列创新的特征工程方法,包括指标价格斜率比率和收盘价与开盘价之差除以相应14期指数移动平均线(EMA)的比率,旨在捕捉市场动态并提高预测准确性。此外,本文测试了七种不同的特征和目标变量转换方法,包括收益率、对数收益率、EMA比率及其标准化版本以及EMA差异比率,以确定在效率和准确性之间权衡的最佳方法。结果表明,对数收益率、收益率和EMA差异比率是最佳的目标变量转换方法,而EMA比率在方向预测准确性上表现较差,标准化版本的目标变量转换方法则需要显著更长的训练时间。此外,引入的特征在所有目标变量转换方法中均表现出较高的特征重要性。本研究展示了一种使用LightGBM进行股票市场预测的可行且计算高效的方法,使得高级预测技术更加普及。
1. 引言
股票市场对个人和社会的金融福祉有着深远的影响。尽管其直接影响主要体现在企业和投资者身上,但其影响范围远远超出了这些直接参与者,渗透到消费者价格、经济政策和通货膨胀等日常生活的各个方面。股票市场的增长通常被视为经济繁荣的标志,但其衰退往往会给参与者和非参与者带来严重后果。因此,个人需要采取预防性措施来减轻这些后果的影响。
时间序列预测是一种应对股票市场复杂性的成熟方法。它利用科学方法,根据历史数据预测时间依赖变量的未来值。在过去的几十年中,时间序列预测被广泛应用于股票市场,因为它能够支持明智的决策、经济规划和潜在的被动收入。
随着技术的指数级增长,时间序列预测领域的创新也在加速。最初,统计方法在该领域占据主导地位,但随着人工智能的快速发展,机器学习(ML)和深度学习(DL)被应用于金融时间序列,如股票市场。ML和DL模型在处理复杂和非线性数据方面的有效性被证明是革命性的,许多当代研究提出了ML和DL的混合模型。尽管这些模型非常准确,但其计算需求通常将其实用性限制在拥有大量技术资源的机构中,从而限制了个人投资者、独立研究人员、小规模从业者和普通人的使用。
为了应对这一挑战,本研究重点关注LightGBM,这是一种使用基于树的算法的ML模型。与更重的深度学习模型相比,LightGBM在计算上更高效且高度可扩展,这使其更易于广泛采用。在M5预测竞赛中,LightGBM在时间序列预测中展示了令人印象深刻的结果。在本研究中,我们旨在通过引入新的特征工程技术和确定最佳的特征和目标变量转换方法,进一步提高其性能。
2. 相关工作
2.1 统计模型
统计模型在金融时间序列预测领域有着广泛的应用。其中,自回归移动平均(ARIMA)模型基于数据中线性相关性的识别来生成预测。因此,它在能源预测和酒店价格预测等领域表现出高准确性。然而,由于其仅建模线性关系的局限性,当面对股票市场等非线性异方差时间序列时,它的表现不佳。因此,广义自回归条件异方差(GARCH)模型被开发出来,通过直接建模波动性成功解决了这一问题。正如Farah Hayati Mustapa等人所展示的,混合GARCH-ARIMA模型在预测标准普尔500指数时实现了有限的准确性(R-squared=0.023910)。
2.2 机器学习模型
机器学习模型在21世纪初崭露头角,利用技术进步有效地应用于股票市场。机器学习模型擅长解码多变量数据集中的复杂关系,这些数据集提供了额外的信息,证明了在处理股票市场的非线性特性方面更为可靠。值得注意的机器学习模型包括支持向量机、随机森林和梯度提升机,后者以更高效的方式在LightGBM、XGBoost、CatBoost和AdaBoost等模型中实现。Ma shangchen等人展示了LightGBM和GBDT模型在2016年至2018年期间预测标准普尔500指数时均实现了比同期指数更高的回报,LightGBM在此期间实现了高达394%的总回报。
2.3 深度学习模型
在机器学习模型成功的基础上,深度学习模型专注于对时间序列中的时间依赖性进行建模,并具有直接从目标变量中提取信息特征的能力。然而,它们的采用速度较慢,部分原因是它们对训练数据有巨大的需求。这些需求包括足够大的数据集;充足的随机存取内存(RAM);以及高度可并行化的处理器,如最先进的图形处理单元(GPU)和张量处理单元(TPU)。混合机器学习-深度学习模型已被证明在时间序列预测中特别有效,利用了两种技术的优势。Yuankai Guo等人提出了一个LSTM-LightGBM混合模型,使用LSTM预测诸如成交量和收盘价等特征的值,然后由LightGBM进行最终预测。他们提出的模型优于独立的长期短期记忆(LSTM)和递归神经网络(RNN)模型。
3. 我们的贡献
本研究旨在优化LightGBM的性能,减少对通常用于深度学习模型的高性能硬件的依赖。我们系统地评估了七种不同的目标变量转换方法,并在包含使用这些相同转换方法创建的不同特征变体的特征集上进行了训练。此外,我们引入了新的交叉特征,如价格与指标之间的斜率差异和开盘价与前收盘价之间的差异,以在不显著增加训练时间的情况下提高准确性。
4. LightGBM
Light Gradient Boosting Machine(简称LightGBM)是一个先进的开源机器学习框架,建立在GBDT的基础上,显著提高了效率。GBDT通过在数据上迭代训练决策树来纠正之前树的错误,从而进行预测。更具体地说,首先使用目标变量的均值作为基预测来预测数据。随后,决策树被拟合到基预测的残差上,以预测错误。这个过程,称为提升轮次,重复进行,直到在验证集上评估的准确性在指定的提升轮次内不再提高。
LightGBM在几个不同的方面改进了GBDT,其中包括:
i. 梯度单边采样(GOSS)
梯度是损失函数的导数。它们指示残差相对于模型参数的变化程度。GOSS更关注具有较大梯度的实例,因为它们对模型更具信息性,同时保留了一部分具有较低梯度的实例。通过这个过程,在不显著降低准确性的情况下实现了更高的效率。
ii. 基于直方图的分箱
分箱将特征值的多个实例组合成一个离散的分箱。一个分箱由其值范围和包含的数据点数组成。梯度是根据分箱而不是单个数据点计算的,从而降低了内存使用并加快了训练速度。此外,这种方法过滤了噪声数据,从而促进了泛化。
iii. 叶向生长
与使用层级生长的GBDT不同,LightGBM以叶向生长决策树。在层级生长中,决策树最后一层的所有节点同时分裂,节点数量呈指数级增长。相比之下,叶向生长只分裂最具信息性的节点,而不考虑层级,从而创建更深、更复杂的树并减少计算压力。
5. 方法论
5.1 数据收集
苹果公司(AAPL)的股价波动通常被认为与蓝筹股类似,即它们流动性充足、相对稳定且波动性较低。作为标准普尔500等主要指数的组成部分,AAPL也反映了更广泛的市场趋势,使其成为评估股票市场预测方法的合适案例。因此,我们选择AAPL进行测试。我们从TradingView的导出图表数据功能中提取开盘价、最高价、最低价和收盘价(OHLC)以及成交量,总共有8137个数据点,日期跨度从1992年5月到2024年9日,日线时间框架。TradingView使用Cboe One的数据,该数据约占美国股票市场份额的10%。市场休市的日期不是数据集的一部分,因此没有缺失值。
5.2 特征工程
我们将预测给定日期在市场开盘时的收盘价(目标变量),允许对隔夜价格缺口进行建模,并使用当天的开盘价作为特征。我们从OHLC价格和成交量中计算出大量典型和新颖的特征,旨在模拟不同的复杂市场行为和动态,通常借用技术分析(TA)和统计学的概念。
6. 实验
为了评估LightGBM的性能,并比较每种转换方法的性能,我们在方法论中描述的数据集上进行了多次测试。我们使用数据集的80%-20%的训练-测试分割。
6.1 转换方法
首先,我们对特定特征集的副本进行异常值处理,以便稍后比较它们的性能。不同的转换方法,如方法论中所述,迭代地应用于每个适用的特征,以创建包含所有特征在每个转换变体中的新数据集。
6.2 训练与交叉验证
为了稳健地推广模型,我们选择滚动训练-验证分割,使用scikit-learn的TimeSeriesSplit来避免任何数据泄漏。首先,我们将训练集分成四个部分以创建三个验证折叠。在第一个折叠中,模型在第一部分训练并在下一部分验证。第二个折叠使用前两部分进行训练并在第三部分验证。最后,第三个折叠使用除最后一部分之外的所有部分进行训练,并在第四部分验证。
6.3 自定义损失函数
由于在股票市场预测的背景下,较大的错误可能会导致严重的后果,我们选择了一个自定义损失函数,它对较大的错误进行更严厉的惩罚。
6.4 超参数调优
网格搜索在以前的研究中常用,但计算成本高且耗时。相反,我们采用Optuna的贝叶斯优化算法,这是一种更快、更可扩展的替代方案。在平衡训练效率与性能的同时,我们将使用500次试验。一些优化的参数如下所示:
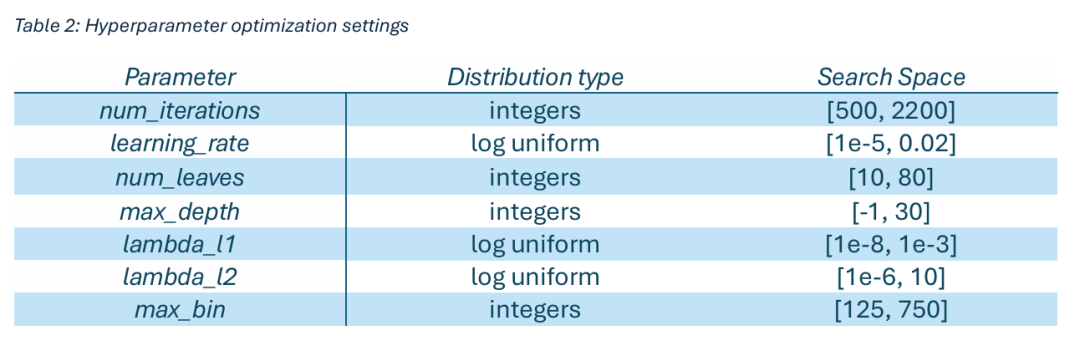
6.5 指标
准确评估模型性能对于得出有意义的结果至关重要。对于每种目标变量转换方法,我们相应地反向转换预测,以便与实际市场价值进行比较。我们计算平均绝对误差(MAE)、均方根误差(RMSE)、方向准确性(DA)和训练时间。所有测试均在AMD Ryzen 5 3600处理器上进行,配有32GB的DDR4内存,尽管训练过程并未完全使用。此外,一些计算通过CuPy分配给图形处理单元(GPU)以减轻CPU的负载。
6.6 基准
随机游走(RW)模型假设关于下一个时间点的值的所有信息都反映在当前值中。它是股票市场预测的最基本基准,因为任何无法超越它的模型本质上没有有意义的预测能力。RW模型的方程如下所示:

7. 结果
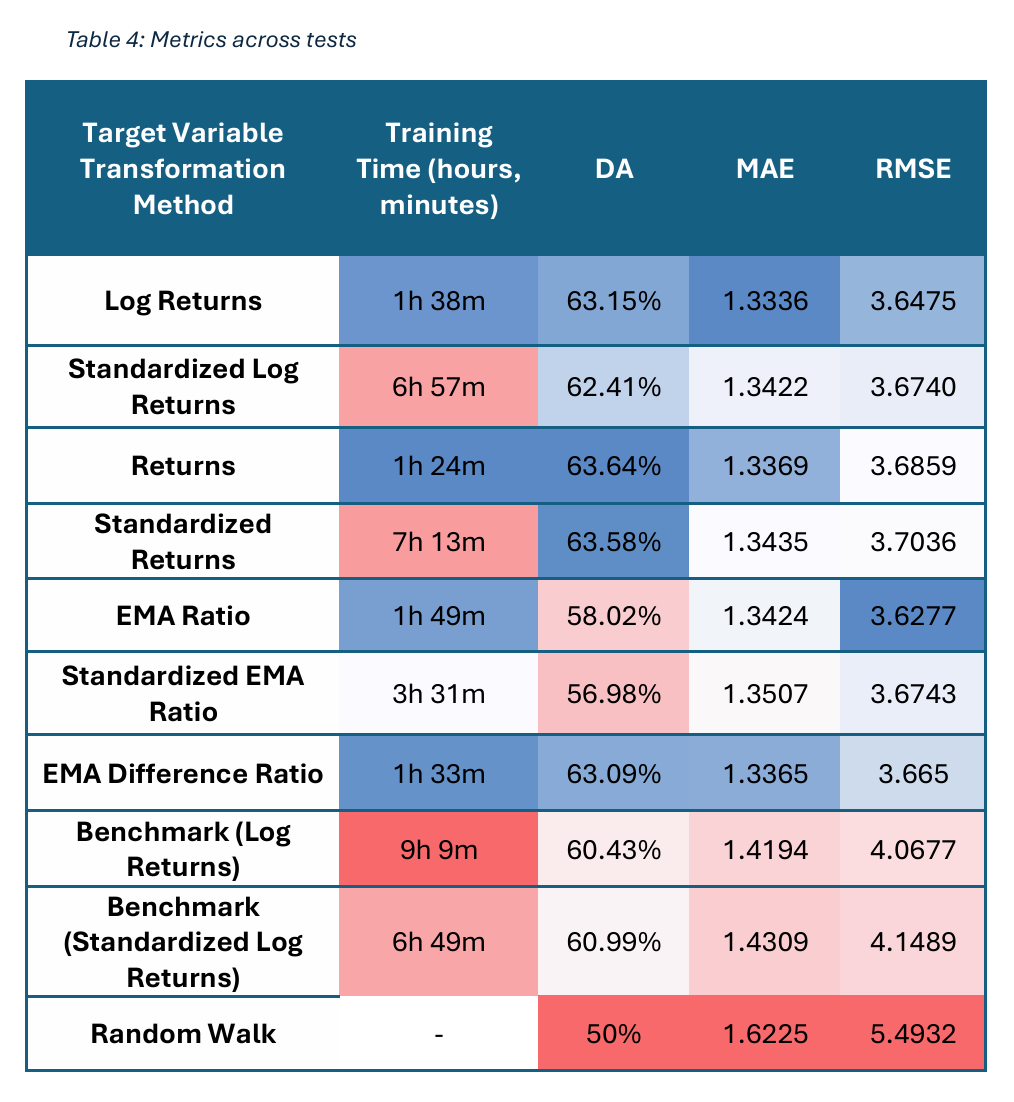
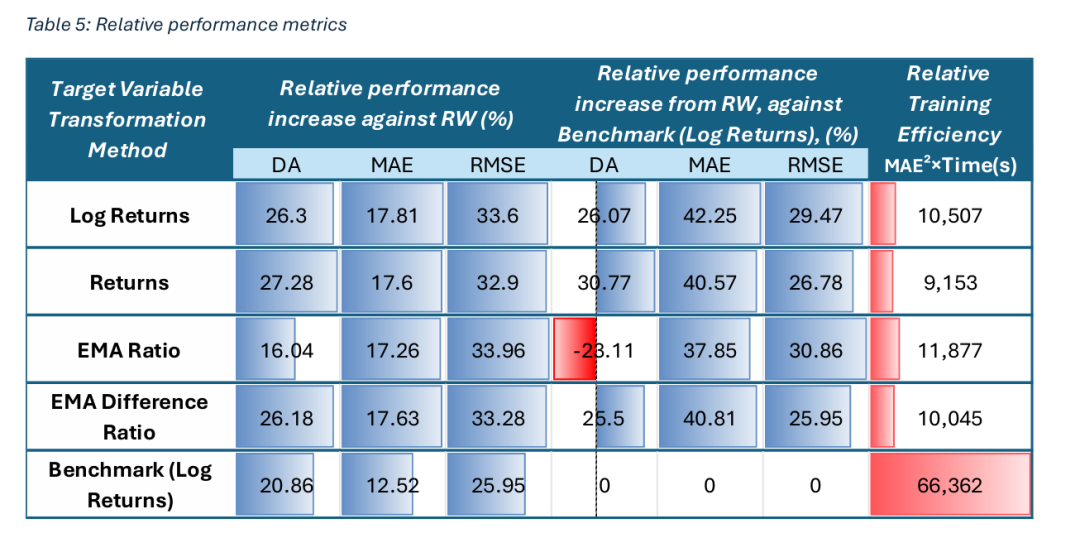
从九次测试中提取的指标在以下表格中表示:
8. 结论
本研究探讨了结合创新转换方法的创新特征工程技术,以优化LightGBM在股票市场预测中的性能,并在AAPL日线价格上进行测试。不同的转换方法在目标变量和特征上进行了评估(如果适用)。为了进行比较,部署了两个基于传统特征的LightGBM模型和一个RW模型。
我们的研究结果表明,对数收益率是目标变量的最佳转换方法,尽管性能差异通常较小。转换方法的标准化版本略微降低了准确性,但大大增加了训练时间,这表明标准化对于LightGBM等基于树的模型是适得其反的。
转换方法极大地影响了不同模型中特征的相对重要性。通过EMA比率、EMA差异比率和收益率转换的特征在所有模型中得分特别高。至关重要的是,新特征,特别是隔夜价格缺口,始终表现出比传统特征更高的重要性。这证明了它们能够为模型提供有关复杂市场动态的额外信息,从而提高预测性能,同时显著减少训练时间。
异常值处理方法对LightGBM没有太多好处,尽管在这方面的测试有限。未来的实验可以更好地评估这种方法及其在时间序列预测更广泛背景下的有效性。此外,残差图表明,在高波动性时期,模型性能会恶化。未来的工作可能涉及训练多个专门的LightGBM模型,每个模型都在特定的波动性制度下训练。这些制度可以使用GARCH模型或LightGBM分类器来识别。最后,EMA比率在多步预测中具有前景,鉴于其基于趋势的性质。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









