






课程打卡凭证

下载MindSpore的NLP框架
模型简介
BERT,即Bidirectional Encoder Representations from Transformers,它是一种预训练语言模型(Pre-trained Language Model, PLM),由Google公司在2018年推出。
概念与原理
BERT是一种基于Transformer架构的预训练语言模型,旨在通过在大规模文本数据上的预训练来捕捉语言的深层双向表征。它的主要特点是使用了Transformer的encoder部分进行堆叠构建,通过预训练和微调两个阶段来生成深度的双向语言表征。双向性(Bidirectional)意味着BERT在预测一个词时,可以同时考虑这个词的上下文信息,包括它的前面和后面的词,从而提高了模型对语言的理解能力。
结构与特点
BERT有两种size,base版有110M参数,large版有340M的参数,参数量庞大。BERT的预训练阶段包括两个任务:Masked LM(遮蔽语言模型)和Next Sentence Prediction(下句预测)。Masked LM通过在输入文本中随机遮蔽一些词,然后让模型预测这些被遮蔽的词来训练模型。Next Sentence Prediction则是为了训练模型对句子关系的理解能力。BERT的编码层数可以根据需要进行调整,常见的有12层(base)和24层(large)两种配置。在维度方面,BERT通常采用768维度的向量表示。
导入必要的库与模块
定义加载并处理情感分析数据集的类

数据集介绍


该数据集来自百度飞桨团队,示例如图。它已经过了分词预处理与情感标注,其中0表示消极,1表示中性,2表示积极。下载地址为:https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz
下载并解压数据集
数据加载和数据集预处理

定义process_dataset函数来处理数据集,它使用了前面定义的GeneratorDataset类来处理来自source的数据,并对其进行一系列的转换。
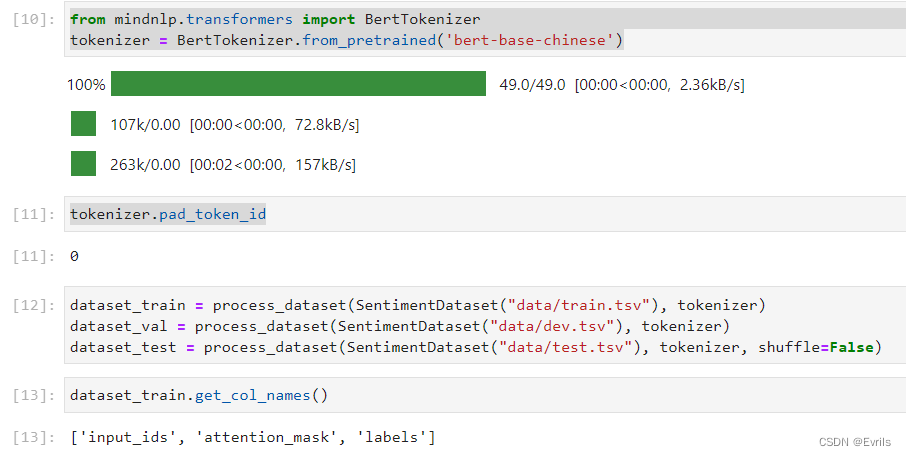
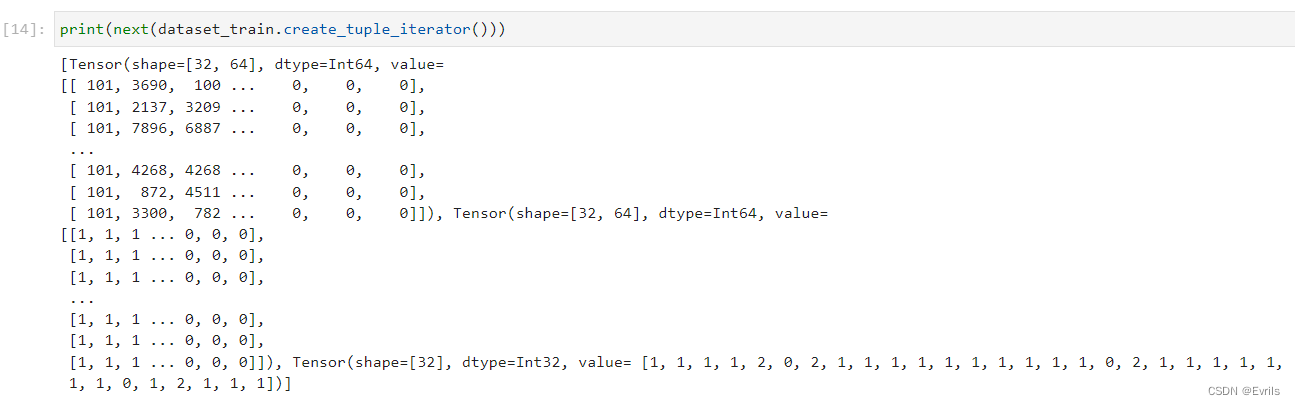
从mindnlp.transformers中的BertTokenizer来加载BERT中文分词器,并准备用于情感分析任务的数据集。定义三个数据集:dataset_train、dataset_val和dataset_test,分别对应训练集、验证集和测试集。
模型构建
使用mindnlp库中的BertForSequenceClassification模型来进行序列分类任务,并且启用自动混合精度(AMP)训练来加速训练并减少显存使用。
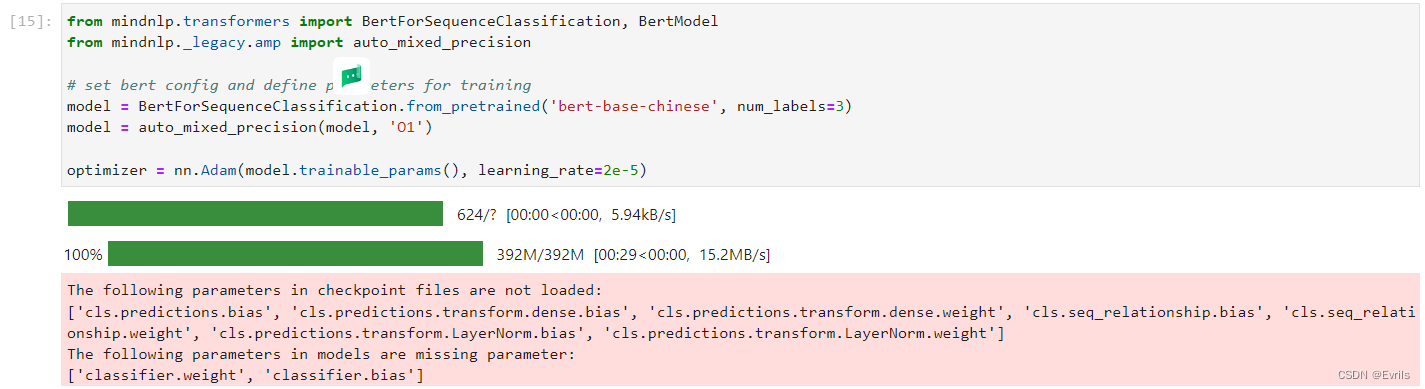
定义Accuracy对象来作为模型评估的指标;CheckpointCallback用于在训练过程中保存模型的检查点;BestModelCallback用于在验证集上评估模型性能,并在模型性能提升时保存最佳模型;Trainer用于管理训练过程。
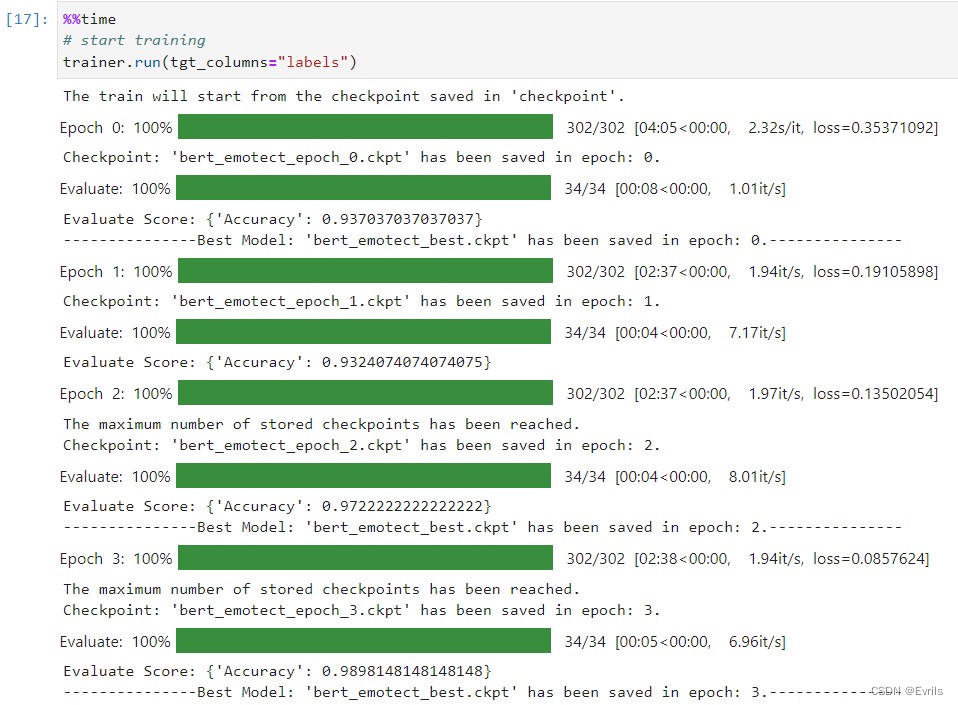
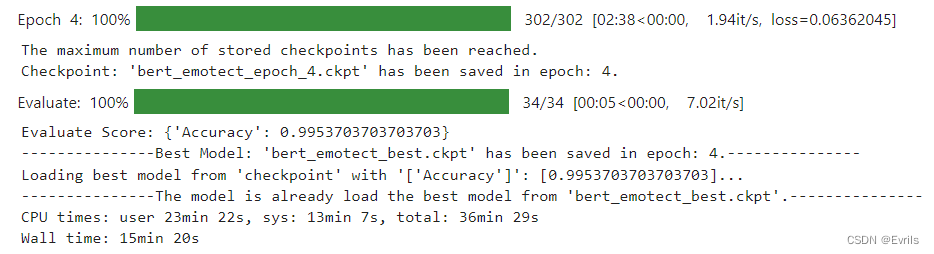
启动训练过程,并输出训练的时间。
模型验证
使用Evaluator来评估训练好的模型在测试集上的性能。

模型推理
定义predict函数来预测文本的情感标签。
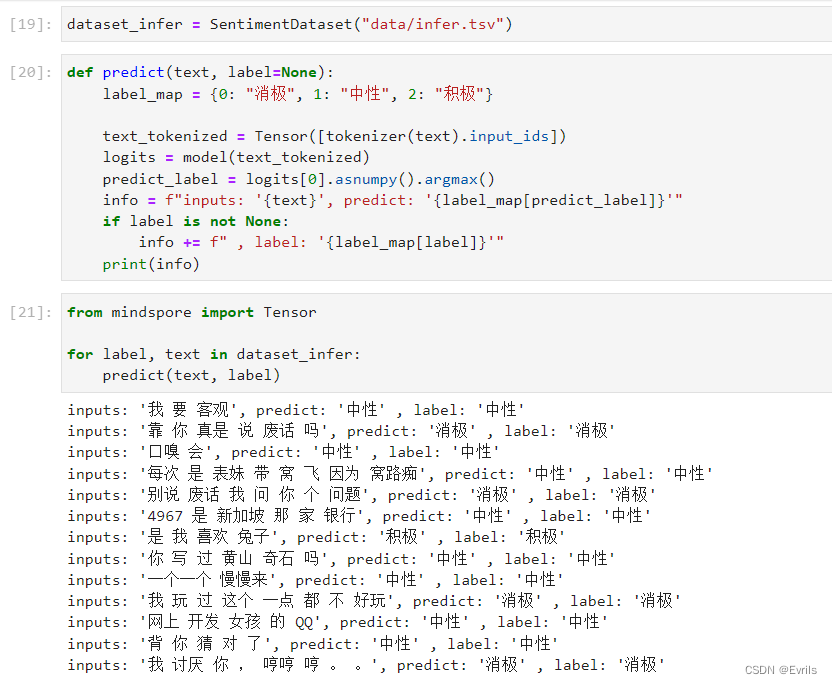
自定义推理数据集
通过自定义推理数据集,可以展示模型的泛化能力。

“奇葩”在现在网络用语中,偏向消极,而原意为积极。因此,该模型泛化能力还不够。















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









