







 本文介绍了Q-Learning算法,包括其行为策略——ε-贪婪法,以及优化策略——贪婪法更新Q表。Q-Learning通过在状态-行为对上进行价值函数更新,寻找最优策略。算法流程涉及根据状态选择动作,接收奖励并更新Q值,进而指导后续动作的选择。更新公式展示了Q值的迭代过程,其中包含了学习率α、折扣因子γ和最大Q值的选取。
本文介绍了Q-Learning算法,包括其行为策略——ε-贪婪法,以及优化策略——贪婪法更新Q表。Q-Learning通过在状态-行为对上进行价值函数更新,寻找最优策略。算法流程涉及根据状态选择动作,接收奖励并更新Q值,进而指导后续动作的选择。更新公式展示了Q值的迭代过程,其中包含了学习率α、折扣因子γ和最大Q值的选取。
Agent在探索中寻找最优策略的过程包括两部分:
- 它在面对State的时候选择哪个Action去行动(选择的依据跟价值函数有关),这叫做行为策略。
- 如何使用新得到的经验去更新价值函数,这叫做优化策略(注意这是个名词)。
Q-Learning使用 ε \varepsilon ε-贪婪法作为行为策略,使用贪婪法作为优化策略来更新Q表。
Q-Learning算法概述
Q-Learning算法的拓扑图如下,白色远点表示状态,黑色圆点表示状态-行为对(即在状态下执行动作)
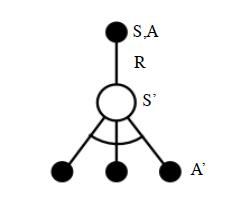
如上图,先基于状态 S t S_t St,用 ε \varepsilon ε-贪婪法 选择执行动作 A t A_t At,得到奖励值 R t + 1 R_{t+1} Rt+1,进入状态 S t + 1 S_{t+1} S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









