







直接使用系统调用的缺点:
(1) 影响系统性能
系统调用比普通函数调用开销大
因为,频繁的系统调用要进行用户空间和内核空间的切换
(2) 系统调用一次所能读写的数据量大小,受硬件的限制
解决方案:使用带缓冲功能的标准I/O库(以减少系统调用次数)
文件系统的基本概念
文件系统:一种把数据组织成文件和目录的存储方式,提供了基于文件的存取接口,并通过文件权限控制访问。
文件系统接口:
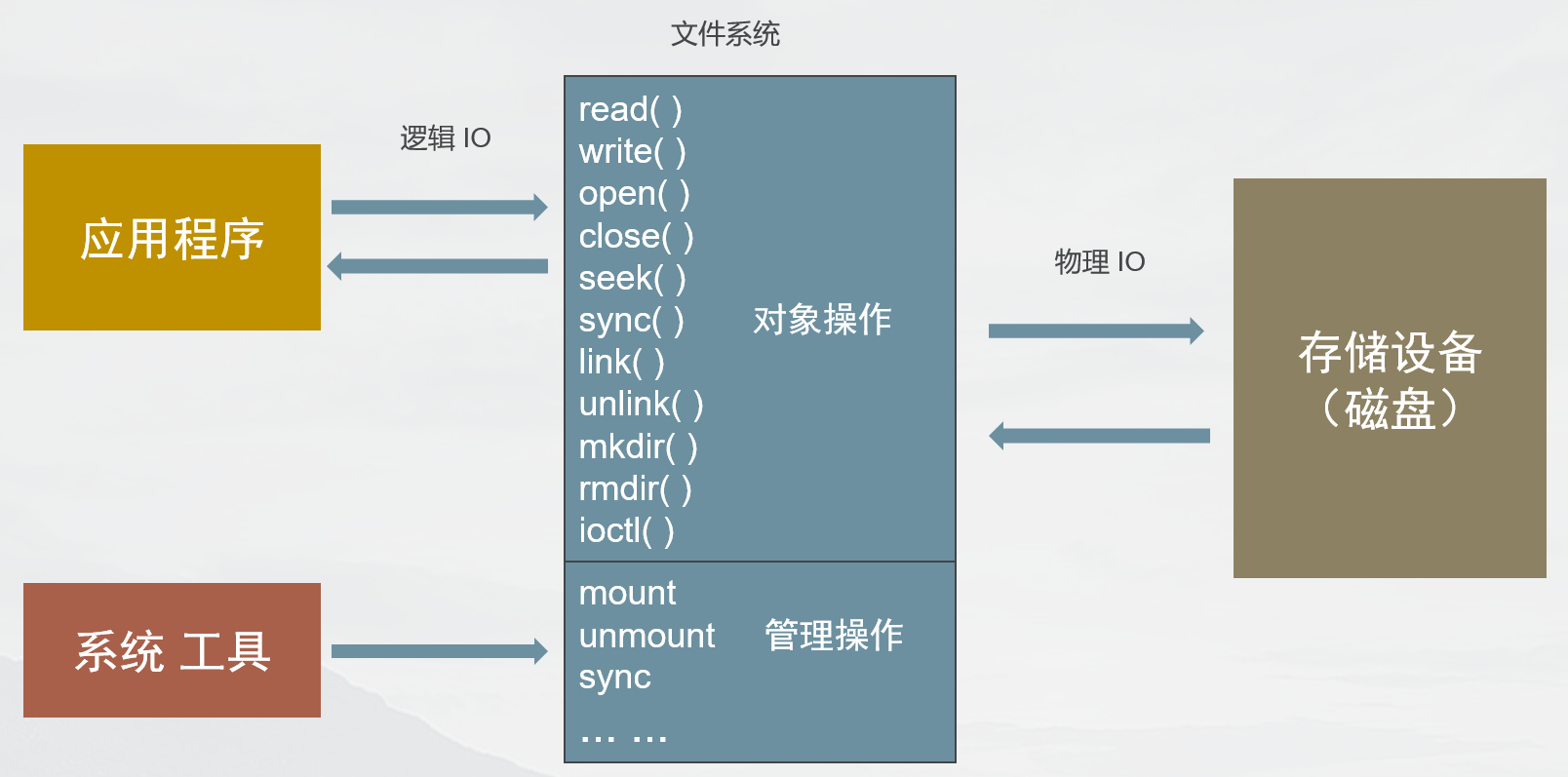
文件系统缓存:
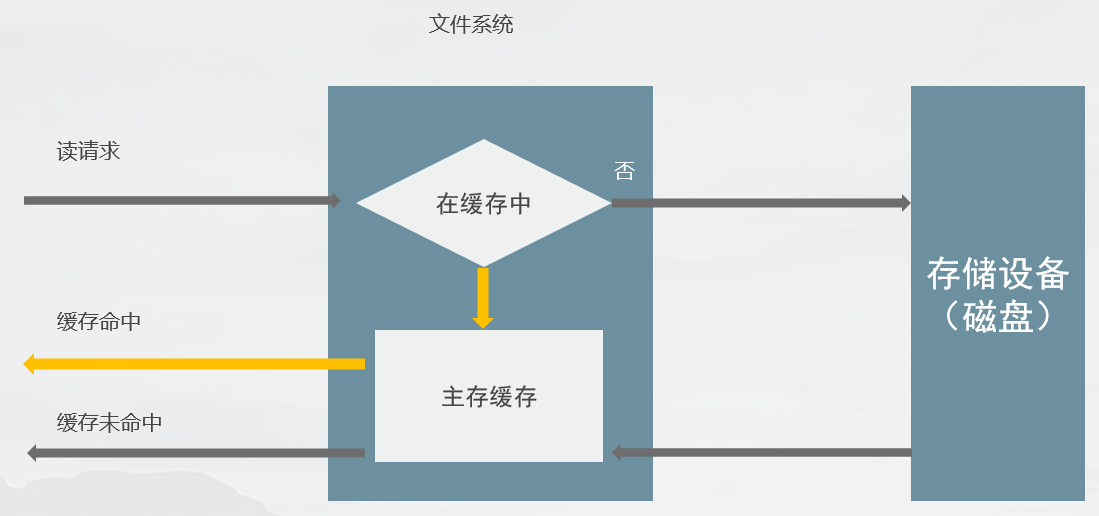
主存(通常是DRAM)的一块区域,用来缓存文件系统的内容,包含各种数据和元数据。
文件 I/O 访问方式
标准文件访问方式
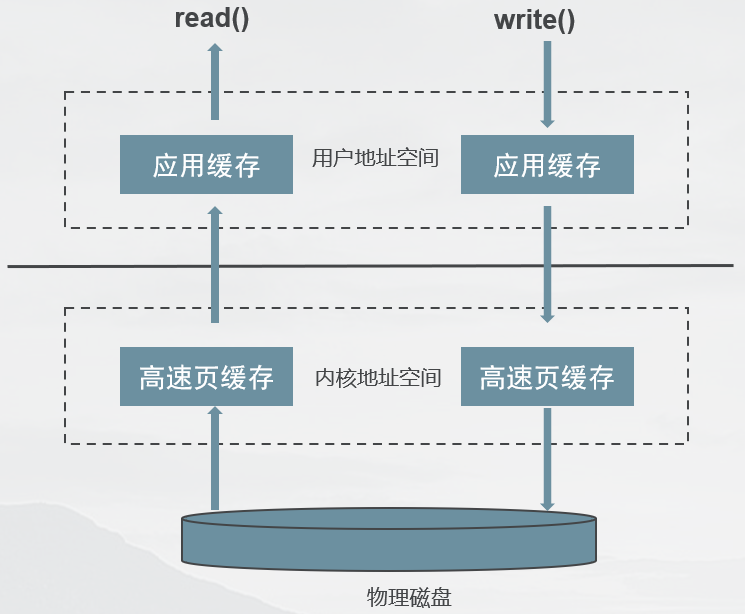
直接 I/O
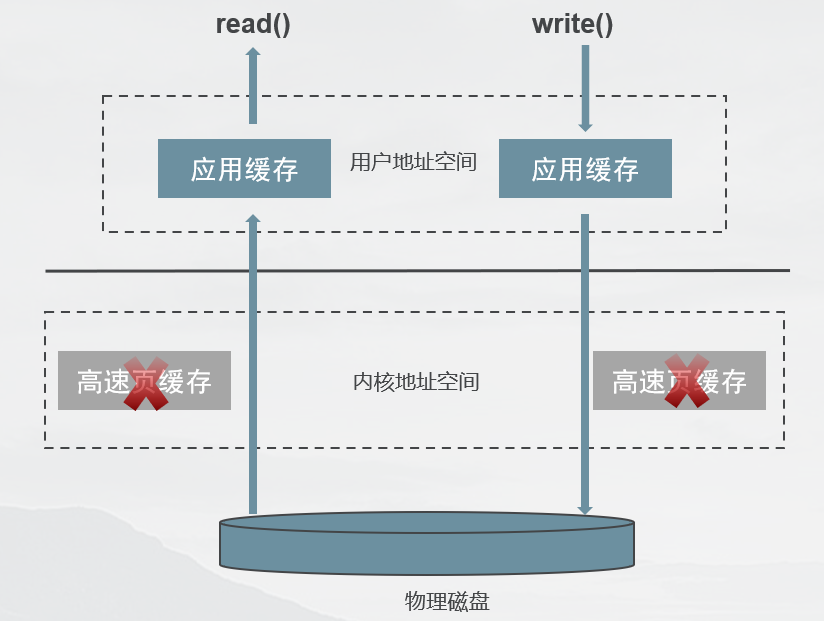
实现方式:open+O_DIRECT
绕过内核缓冲区的直接访问,便有效避免了CPU和内存的多余时间开销。
O_DIRECT != O_SYNC
O_SYNC 只对写数据有效,它将写入内核缓冲区的数据立即写入磁盘
将机器故障时数据的丢失减少到最小,但仍然要经过内核缓冲区。
注意:直接 I/O 的缺点就是如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。
直接 IO 和 标准文件 IO 对比
1.使用标准不一样,文件 IO 遵循POSIX标准,只能在遵循 POSIX 标准的类UNIX环境下使用;标准 IO 遵循 ANSI 标准,只要重新编译就可以在不同的环境下运行。
2.文件 IO 属于系统文件只能在 linux 下进行系统调用,可移植性差。标准 IO 属于C库(意思是C语言环境),可以在不同的操作系统下移植使用。
3.文件 IO 使用文件描述符(fd:起的编号),标准 IO 使用文件流指针(结构体:包含文件的各种数据)。
4.文件 IO 不带缓冲,执行效率低;标准 IO 带缓冲,执行效率高。(缓冲:理解为一块内存,标准IO可以写完数据后找到合适时机一起放入磁盘,而文件IO是每写一个数据都会放一次磁盘,分为全缓冲(大小4096,向文件写入时):写满,程序结束,主动刷新(fflush),执行.行缓冲(1024,向终端输出时用):写满,结束,主动刷新(fflush),换行符,执行。无缓冲:每次执行。程序正常结束也会刷新缓冲区)
5.文件IO 属于系统调用,可以访问不同类型的文件,如普通文件,设备文件(open时不能create),管道文件,套接字文件等;标准IO 属于C库只能访问普通文件。
缓存同步
为了保证磁盘系统与缓冲区中内容一致,Linux 系统提供了sync、fsync 和 fdatasync 三个函数。
函数描述:向打开的文件写数据并同步;成功返回写入的字节数,若出错,返回-1。
头文件:#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
void sync(void);
说明:
sync -将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际写磁盘操作结束。
fsync-将fd对应文件的块缓冲区立即写入磁盘,并等待实际写磁盘操作结束返回。
fdatasync - 类似fsync,但只影响文件的数据部分。而除数据外,fsync 还会同步更新文件属性。
Linux 文件 I/O 流程
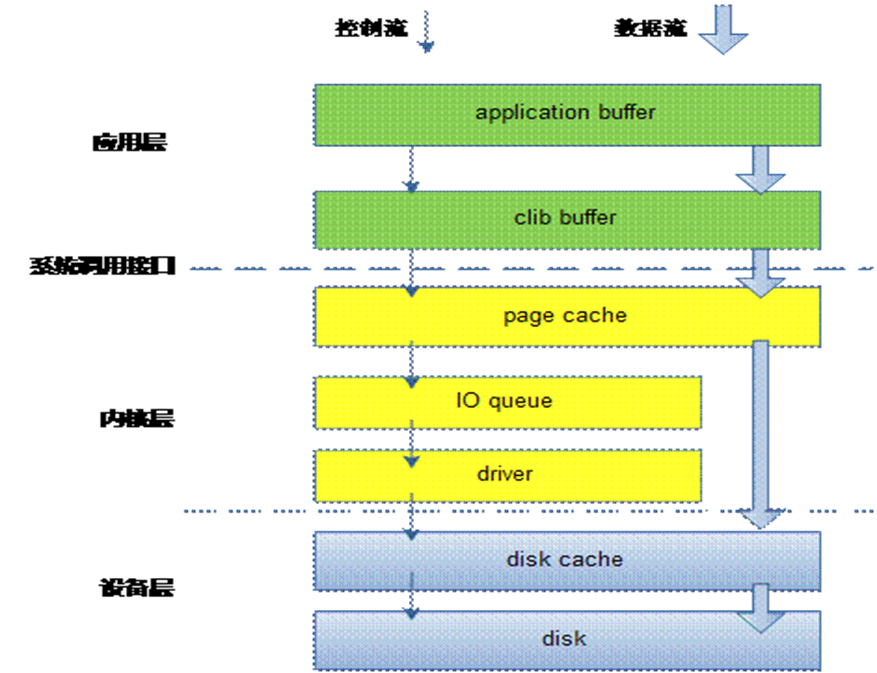
文件 I/O(操作系统)
对于文件的 I/O 常见的有:
1.缓冲与非缓冲 I/O
2.直接与非直接 I/O
3.阻塞与非阻塞 I/O VS 同步与异步 I/O
缓冲与非缓冲 I/O
文件操作的标准库是可以实现数据的缓存,那么根据是否利用标准库缓冲,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O:
缓冲 I/O:利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
非缓冲 I/O:直接通过系统调用访问文件,不经过标准库缓存。
这里 「缓冲」 特指标准库内部实现的缓冲。
直接与非直接 I/O
磁盘 I/O 是非常慢的,所以 Linux 内核为了减少磁盘 I/O 次数,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是「页缓存」,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
根据是否利用操作系统的缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O:
直接 I/O:不会发生内核缓存和用户程序之间数据复制,而是直接经过文件系统访问磁盘。
非直接 I/O:读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
如果在使用文件操作类的系统调用函数时,指定了 O_DIRECT 标志,则表示使用直接 I/O。如果没有设置过,默认使用的是非直接 I/O。
如果用了非直接 I/O 进行写数据操作,内核什么情况下才会把缓存数据写入到磁盘?
以下几种场景会触发内核缓存的数据写入磁盘:
1.在调用 write 的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上;
2.用户主动调用 sync,内核缓存会刷到磁盘上;
3.当内存十分紧张,无法再分配页面时,也会把内核缓存的数据刷到磁盘上;
4.内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上;
阻塞与非阻塞 I/O VS 同步与异步 I/O
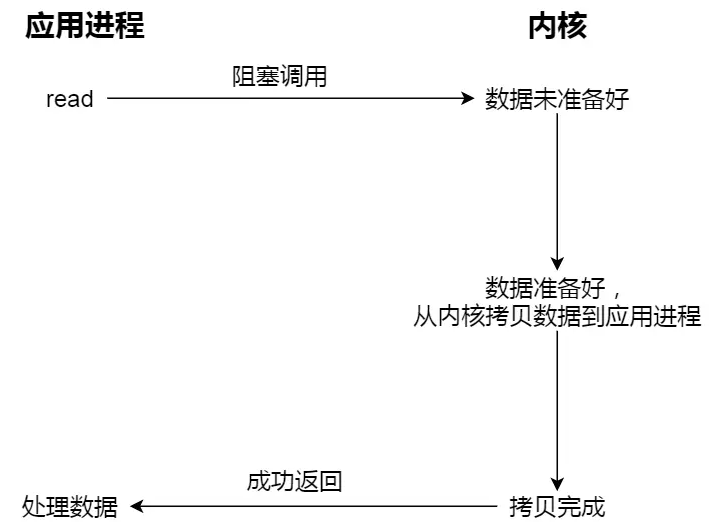
阻塞 I/O:当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程:
非阻塞 I/O:非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。
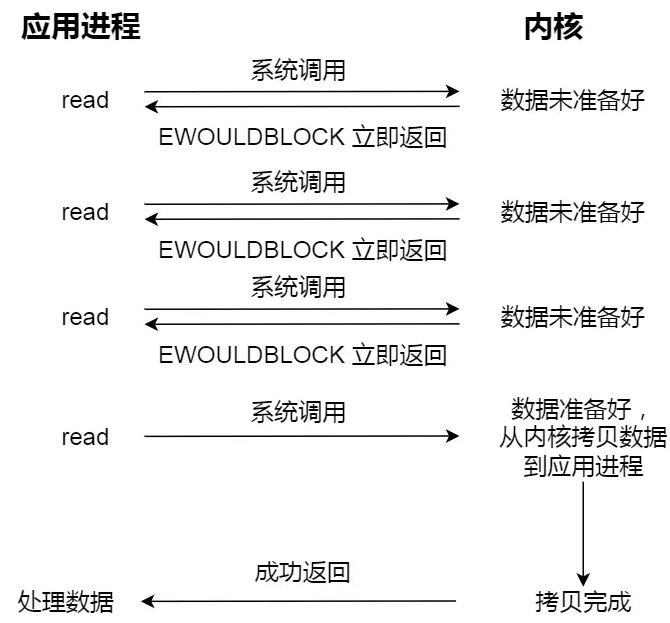
这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。
这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
如果设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O.
应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
I/O 多路复用技术(select,poll):通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
大大改善了 CPU 的利用率,因为当调用了 I/O 多路复用接口,如果没有事件发生,那么当前线程就会发生阻塞,这时 CPU 会切换其他线程执行任务,等内核发现有事件到来的时候,会唤醒阻塞在 I/O 多路复用接口的线程,然后用户可以进行后续的事件处理。
I/O 多路复用接口最大的优势在于:户可以在一个线程内同时处理多个 socket 的 IO 请求。
用户可以注册多个 socket,然后不断地调用 I/O 多路复用接口读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
select I/O 多路复用过程:
read 获取数据的过程(数据从内核态拷贝到用户态的过程),也是一个同步的过程。
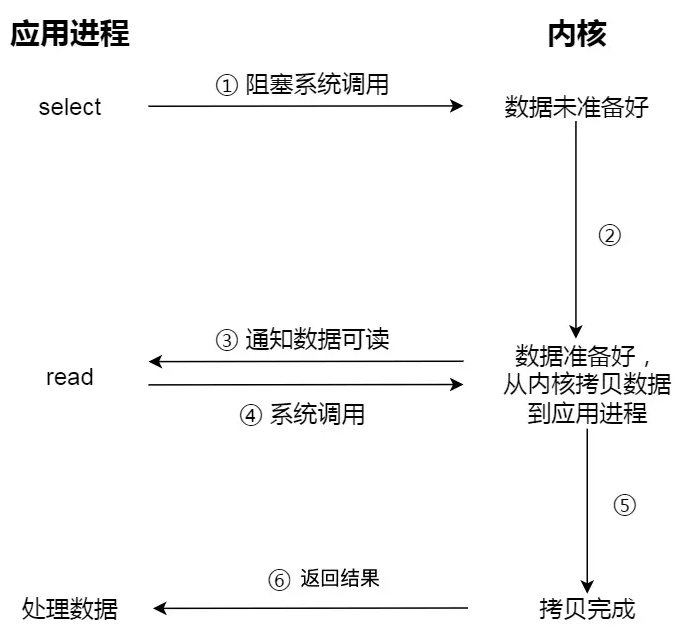
实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。
因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程同样是异步的,内核自动完成的,和=同步操作不一样,应用程序并不需要主动发起拷贝动作。
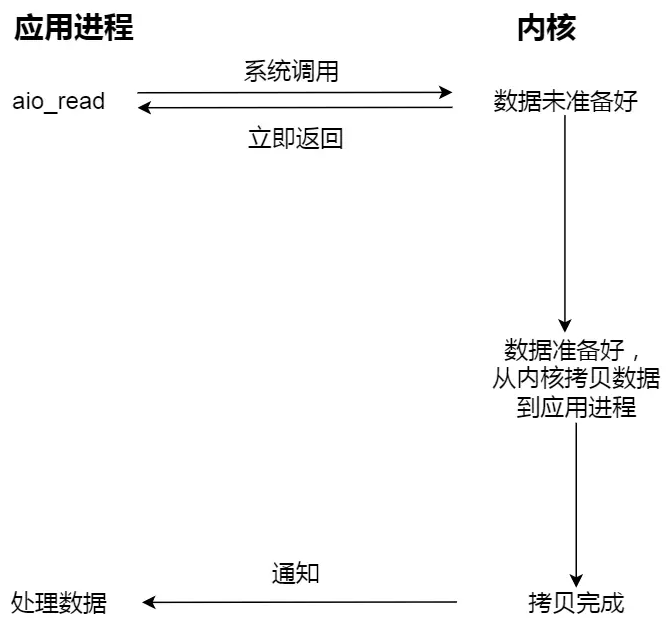
小结
I/O 是分为两个过程的:
1.数据准备的过程
2.数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。
异步 I/O 则不同,「过程 1」和「过程 2」都不会阻塞。
















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











