







空间元素 x 的 p 阶范数定义为 :
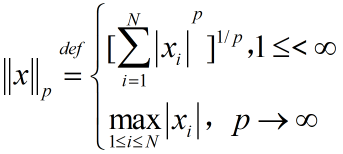
信号处理
1阶范数

可以看出,一阶范数表示信号作用的强度(大小)。
2阶范数

二阶范数的平方表示信号的能量。
无穷阶范数
对于定义在闭区间上的 x( t ) ,表示信号可测得的峰值,也即信号的幅度。
Frobenius 范数
矩阵A的Frobenius范数定义为矩阵A各项元素的绝对值平方的总和
设 是一个 m × n 的矩阵,称
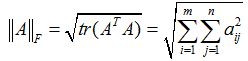
为这个矩阵的Frobenius 范数
- 可用于利用低秩矩阵来近似单一数据矩阵。
- 用数学表示就是去找一个秩为k的矩阵B,使得矩阵B与原始数据矩阵A的差的F范数尽可能地小。
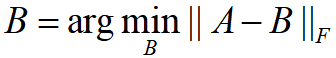
机器学习
L0范数与L1范数
L0范数是指向量中非0的元素的个数。
如果用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。换句话说,让参数W是稀疏的。
L1范数是指向量中各个元素绝对值之和。
L1范数是L0范数的最优凸近似。任何的规则化算子,如果他在Wi=0的地方不可微,并且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。W的L1范数是绝对值,|w|在w=0处是不可微。
虽然L0可以实现稀疏,但是实际中会使用L1取代L0。因为L0范数很难优化求解,L1范数是L0范数的最优凸近似,它比L0范数要容易优化求解。
L2范数
L2范数,又叫“岭回归”(Ridge Regression)、“权值衰减”(weight decay)。它的作用是改善过拟合。
过拟合:模型训练时候的误差很小,但是测试误差很大,即模型复杂到可以拟合到所有训练数据,但在预测新的数据的时候,结果很差。
L2范数是指向量中各元素的平方和然后开根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
L1和L2对比:
L1趋向于产生少量的特征,其他的特征都是0
L2会选择更多的特征,这些特征的wi都会接近于0
核范数和迹范数
核范数(Nuclear Norm),也称为矩阵1范数,是指矩阵的所有奇异值之和。核范数常用于矩阵的低秩近似问题,即通过最小化核范数来求解矩阵的最优低秩近似解。
迹范数(Trace Norm),也称为矩阵2范数或矩阵弗罗贝尼乌斯范数(Frobenius Norm),是指矩阵的所有奇异值的平方和的平方根。迹范数在矩阵优化问题中也具有重要的应用,例如矩阵补全问题、矩阵重构问题等。
两者的区别在于核范数是对奇异值进行求和,而迹范数是对奇异值的平方和进行开方。在矩阵优化问题中,通常选择核范数或迹范数中的其中一个作为目标函数,具体选择哪一个则要根据具体的问题来决定。
对偶范数
对偶范数是指在对偶空间中对原范数进行定义的范数。对于一个向量,它的
范数被定义为:
其中, 是
的共轭指数,即
和
。
对偶范数的直观理解是,在对偶空间中,对向量 x 施加某种压缩或约束后,使得在原空间中对应的向量 z 的范数最小。因此,对偶范数也被称为压缩范数或约束范数。
由霍尔德(Hölder)不等式可以直接得出: 范数的对偶范数是
范数,其中
.
- l2−范数的对偶范数是 l2−范数
- l1−范数的对偶范数是 l∞−范数
- 对偶范数的对偶范数是原范数
















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











