







1. The University of Cambridge’s Machine Translation Systems for WMT18
1. basic Architecture
Combine the three most commonly used architectures: recurrent, convolutional, and self-attention-based models like the Transformer
2. system combination
If we want to combine q models M 1 , . . . , M q M_1,...,M_q M1,...,Mq, we first divide the models into two groups by selecting a p with 1 ≤ \le ≤ p ≤ \le ≤ q.
Then, we refer to the first group M 1 , . . . , M p M_1,...,M_p M1,...,Mp as full posterior scores and the second group M p , . . . , M q M_p,...,M_q Mp,...,Mq as MBR-based scores.
Full-posterior models scores compute as follows:
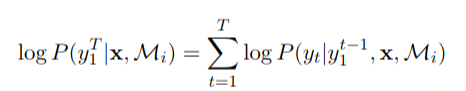
Combined scores compute as follows:
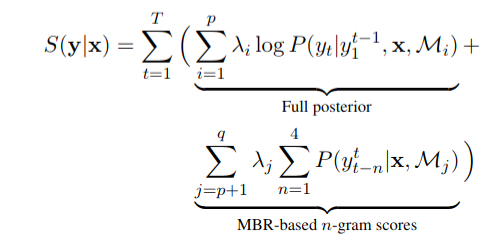
3. Data
1. language detection (Nakatani, 2010) on all available monolingual and parallel data
2. additionally filtered on ParaCrawl
- No words contain more than 40 characters.
- Sentences must not contain HTML tags.
- The minimum sentence length is 4 words.
- The character ratio between source and targetmust not exceed 1:3 or 3:1
- Source and target sentences must be equal af-ter stripping out non-numerical characters.
- Sentences must end with punctuation marks.
2. NTT’s Neural Machine Translation Systems for WMT 2018
1. basic Architecture
Transformer Big
2. Data
- use language model (such as KenLM) to evaluate a sentences naturalness
- use a word alignment model (such as fast_align) to check whether the sentence pair has the same meaning
- translating monolingual sentences with Transformer -> seudo-parallel corpora
- Back-translate & evaluate -> selected the high-scoring sentence pair
- R2L model re-ranks an n-best hypothesis generated by the Left-to-Right (L2R) model (n=10)
3. Microsoft’s Submission to the WMT2018 News Translation Task:How I Learned to Stop Worrying and Love the Data
1. basic Architecture
Transformer Big + Ensemble-decoding + R2L Reranking
2. Data
-
Dual conditional cross-entropy filtering
For a sentence pair(x, y), cross-entropy compute as follows:
a d q ( x , y ) = e x p ( − ( ∣ H A ( y ∣ x ) − H B ( y ∣ x ) ∣ ) + 1 2 ( H A ( y ∣ x ) + H B ( y ∣ x ) ) ) adq(x, y) = exp(-(|H_A(y|x) - H_B(y|x)|) + \frac{1}{2} (H_A(y|x) + H_B(y|x))) adq(x,y)=exp(−(∣HA(y∣x)−HB(y∣x)∣)+21(HA(y∣x)+HB(y∣x)))
where A and B are translation models trained on the same data but in inverse directions.(We setting A = W d e − > e n A = W_{de->en} A=Wde−>en and B = W e n − > d e B = W_{en->de} B=Wen−>de)
H M ( y ∣ x ) = − 1 ∣ y ∣ ∑ t = 1 ∣ y ∣ l o g P M ( y t ∣ y < t , x ) H_M(y|x) = - \frac{1}{|y|} \sum\limits_{t=1}^{|y|} log P_M(y_t|y<t, x) HM(y∣x)=−∣y∣1t=1∑∣y∣logPM(yt∣y<t,x)
P M ( x ∣ y ) P_M(x|y) PM(x∣y) is the probability distribution for a model M
-
Data weighting
sentence instance weighting is a feature available in Marian(Junczys-Dowmunt et al., 2018) .
sentence score = Data weighting * cross-entropy -> sort and select by sentence score














 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









