







 本文介绍了线上故障处理的原则和步骤,强调了尽早发现问题、迅速广播、快速恢复和持续观察的重要性。处理手段包括重启、扩容、回滚等,并提供了一个四步处理流程:判断是否有变化、是否单机、是否集群问题以及依赖服务是否存在问题。此外,文章还讨论了如何预防故障,如了解服务、绘制系统架构和部署图、梳理故障等级、进行压测演练、定期盘点和设置监控警报。
本文介绍了线上故障处理的原则和步骤,强调了尽早发现问题、迅速广播、快速恢复和持续观察的重要性。处理手段包括重启、扩容、回滚等,并提供了一个四步处理流程:判断是否有变化、是否单机、是否集群问题以及依赖服务是否存在问题。此外,文章还讨论了如何预防故障,如了解服务、绘制系统架构和部署图、梳理故障等级、进行压测演练、定期盘点和设置监控警报。
摘要
通常处理线上问题的三板斧是重启-回滚-扩容,能够快速有效的解决问题,但是根据我多年的线上经验,这三个操作略微有些简单粗暴,解决问题的概率也非常随机,并不总是有效。这边总结下通常我处理应用中遇到的故障的解决方案。
原则
处理故障的时候必须遵循的一些原则
-
提早发现问题,避免故障扩散
故障的出现链路一般如下图所示
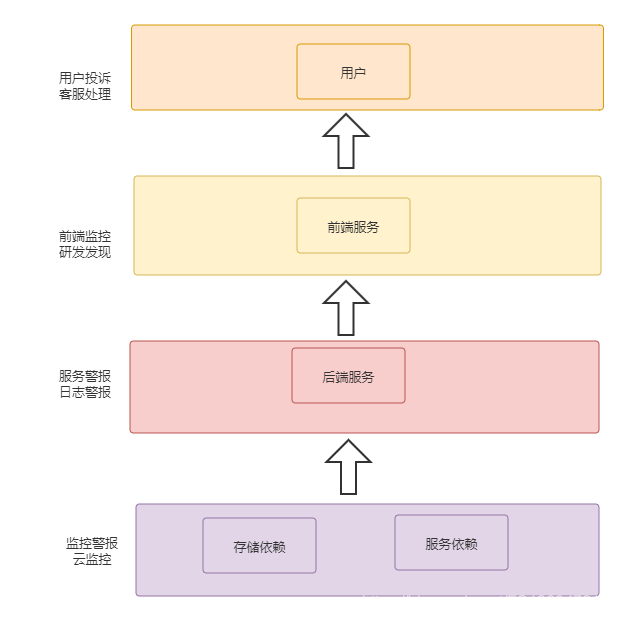
每一层都有可能出现问题,越底层出现问题,影响面越大。所以每一个层次都需要有相应的问题监控机制,这样越早发现问题,越能尽早解决故障,避免问题的扩散。比如服务依赖的一个数据库主库有问题了,如果等到用户报过来,这时候可能服务已经挂了几分钟了。再等你分析问题,解决问题,切换主备什么的,可能几分钟又过去了。影响访问比较大了。如果在数据库出问题时,就已经收到警报,迅速解决,可能没等用户报过来,问题解决了。 -
迅速广播
当收到一个P0警报,判断应用出现问题了,第一时间在组内广播。全部人员进入一级战斗状态,发现可能和其他依赖的服务/中间件/运维/云厂商有关,立即通知相关责任人,要求进入协同作战。 -
快速恢复
保留现场很重要,有助于发现root cause。但是发生故障了,必须要争分夺秒,不能为了保留现场浪费几分钟的时间去干什么dump内存,jstack线程状态的事。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











