







背景
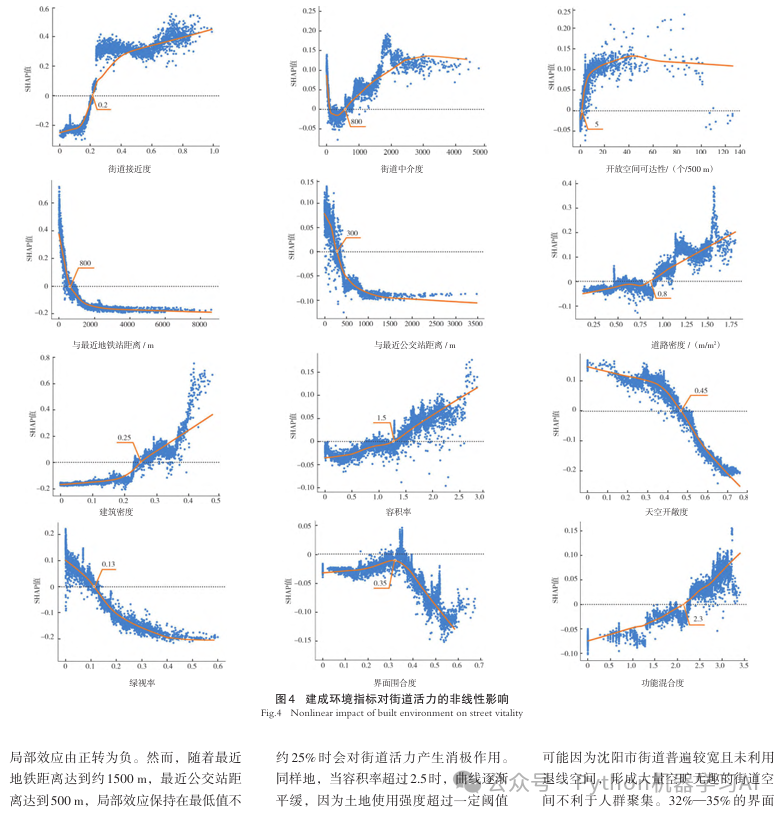
SHAP主效应值,即该特征在独立作用时对模型预测的贡献,这种方式剥离了交互效应的影响,更加直观地展现了主效应的变化趋势,为分析特征的独立作用提供了清晰的视角,有助于更深入地理解模型的特征行为,详情参考文章——期刊配图:SHAP主效应图绘制解释单个特征在独立作用时对模型预测的贡献
然而,仅仅展示主效应值的分布还不够直观。拟合曲线的引入,基于LOWESS(局部加权回归)的平滑曲线【当然其它拟合方法也可以,这里参考的是以下shap依赖图绘制的文章,也是往期文章——文献复现——优化SHAP依赖图拟合曲线与交点标注的新应用】,可以更好地捕捉主效应的全局趋势,揭示模型对特征的敏感性变化。同时,交点标注则进一步突出关键点——即SHAP值为0的位置,这些交点反映特征从正向影响到负向影响的临界点,为在特征影响变化与趋势提供参考
代码实现
模型构建
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('2024-12-17-公众号Python机器学习AI.xlsx')
from sklearn.model_selection import train_test_split, KFold
X = df.drop(['Y'],axis=1)
y = df['Y']
# 划分训练集和测试集
X_temp, X_test, y_temp, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 然后将训练集进一步划分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_temp, y_temp, test_size=0.125, random_state=42) # 0.125 x 0.8 = 0.1
import optuna
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error
def objective(trial):
params = {
'n_estimators': trial.suggest_categorical('n_estimators', [50, 100, 200, 300]),
'max_depth': trial.suggest_int('max_depth', 3, 15, step=1),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.3),
'subsample': trial.suggest_uniform('subsample', 0.5, 1.0),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.5, 1.0),
'gamma': trial.suggest_uniform('gamma', 0, 5)
}
model = XGBRegressor(**params, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
return mean_square 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











