




背景
在机器学习和数据科学领域,构建高效的预测模型只是第一步,如何将模型成果落地应用至关重要,借助在线部署工具,可以实现模型的实时预测与可视化交互,为用户提供直观的分析支持。本次实践以Stacking回归模型为核心,结合SHAP值分析特征重要性,并通过Streamlit搭建交互式Web应用关注微信公众号:Python机器学习AI
代码实现
模型构建
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('2024-11-27公众号Python机器学习AI.xlsx')
from sklearn.model_selection import train_test_split, KFold
X = df.drop(['Y'],axis=1)
y = df['Y']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=42)
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, AdaBoostRegressor, StackingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
from sklearn.linear_model import LinearRegression
# 定义一级学习器
base_learners = [
("RF", RandomForestRegressor(n_estimators=100, random_state=42)),
("XGB", XGBRegressor(n_estimators=100, random_state=42, verbosity=0)),
("LGBM", LGBMRegressor(n_estimators=100, random_state=42, verbose=-1)),
("GBM", GradientBoostingRegressor(n_estimators=100, random_state=42)),
("AdaBoost", AdaBoostRegressor(n_estimators=100, random_state=42)),
("CatBoost", CatBoostRegressor(n_estimators=100, random_state=42, verbose=0))
]
# 定义二级学习器
meta_model = LinearRegression()
# 创建Stacking回归器
stacking_regressor = StackingRegressor(estimators=base_learners, final_estimator=meta_model, cv=5)
# 训练模型
stacking_regressor.fit(X_train, y_train)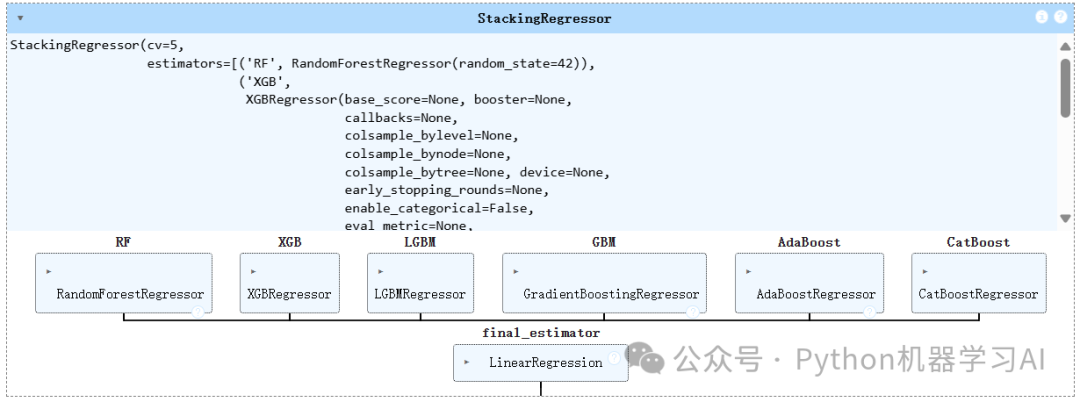
通过Stacking回归器结合多个基学习器(如随机森林、XGBoost等)和线性回归元学习器,构建了一个集成学习模型并完成训练,用于提升预测性能,详情参考——从入门到实践:如何利用Stacking集成多种机器学习算法提高模型性能
模型保存
import joblib
joblib.dump(stacking_regressor, "stacking_regressor_model.pkl")将训练好的Stacking回归模型保存为文件 stacking_regressor_model.pkl,以便后续加载和使用,无需重复训练,提升效率和便捷性
SHAP部分
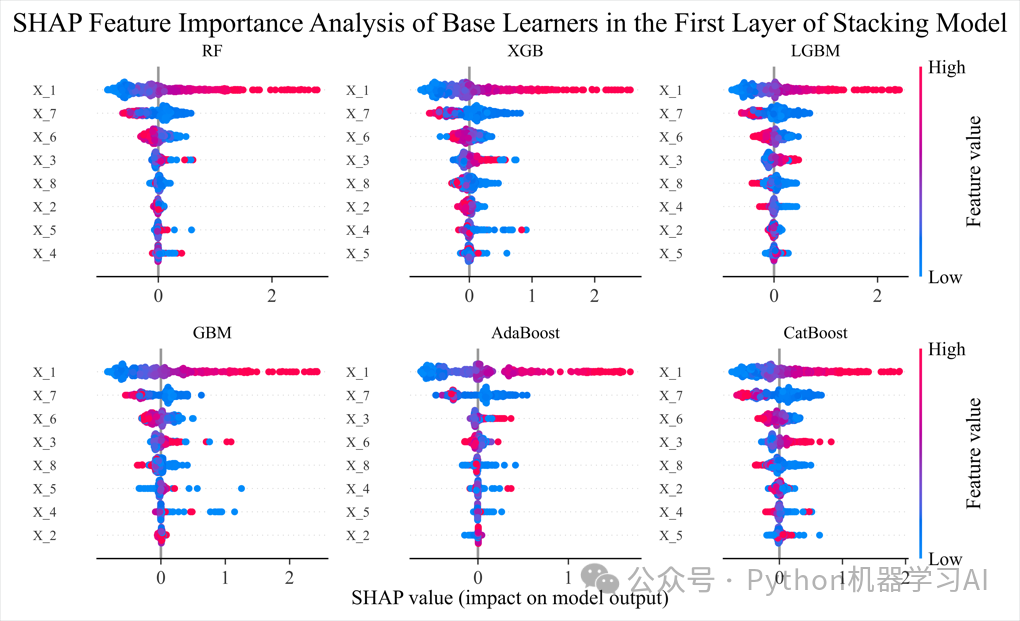
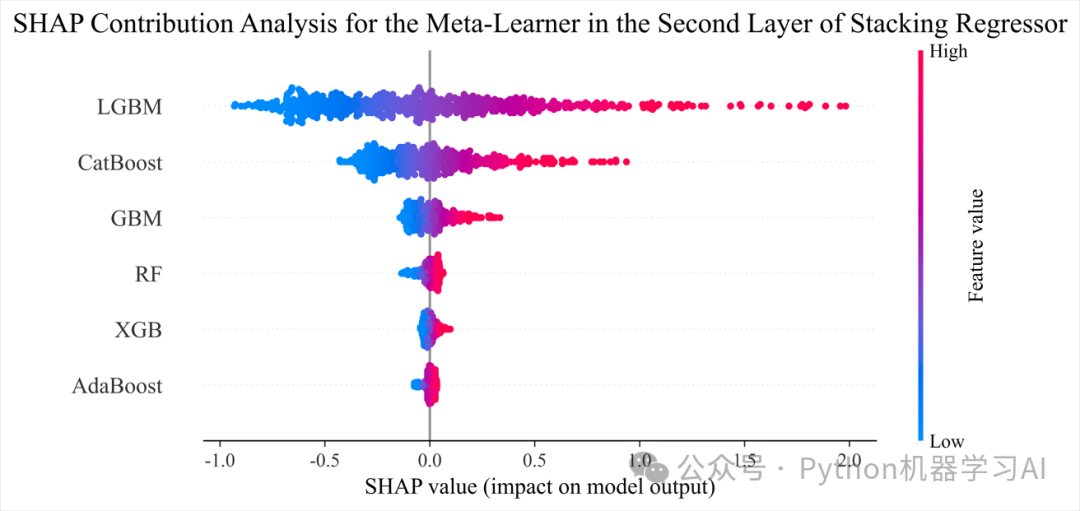
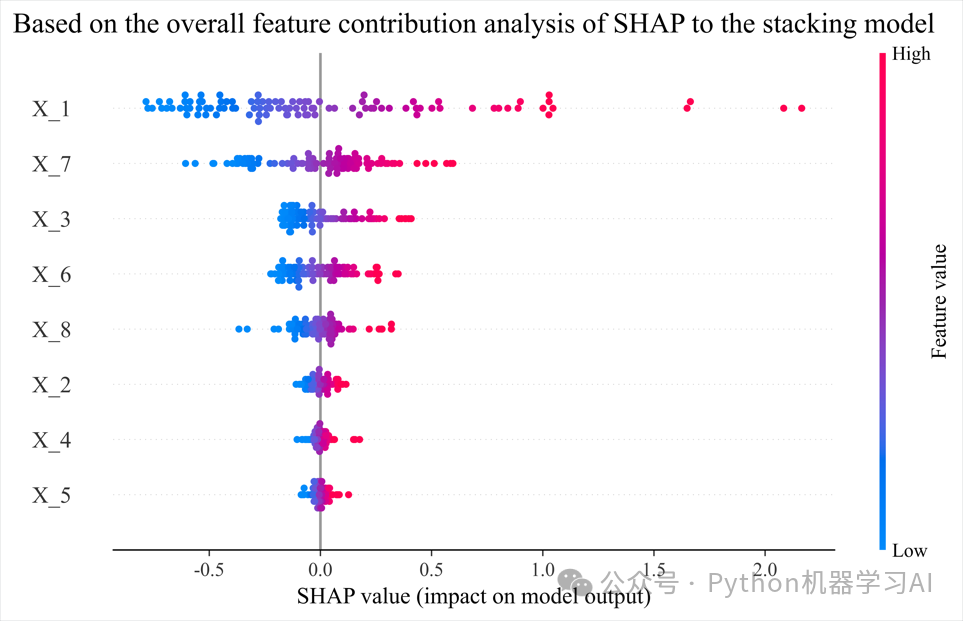
逐步拆解Stacking结构,分别解释基学习器和元学习器的行为,将Stacking模型视为整体的“黑箱”进行解释(仅关注输入特征与最终预测输出的关系),详情参考文章——如何用SHAP解读集成学习Stacking中的基学习器和元学习器以及整体模型贡献
APP部署
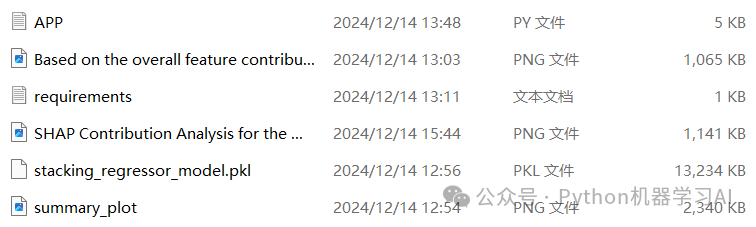
这些文件是为利用Streamlit进行APP部署而准备的,每个文件的作用如下:
-
APP.py:主程序文件,包含了Streamlit应用的代码逻辑,用于构建交互式Web界面
-
requirements.txt:依赖文件,列出了应用运行所需的Python库及其版本,方便部署环境的快速搭建
-
stacking_regressor_model.pkl:保存的Stacking模型文件,用于加载模型进行预测,无需重新训练
-
summary_plot.png:基学习器的SHAP特征贡献分析图,展示第一层学习器的特征重要性
-
SHAP Contribution Analysis for the...png:元学习器的SHAP特征贡献分析图,展示二级学习器的特征重要性
-
Based on the overall feature contribution...png:整体Stacking模型的SHAP特征贡献分析图,用于在应用中可视化显示
接下来将所有文件上传至GitHub仓库
将代码和相关文件上传至GitHub,然后在 Streamlit Cloud 部署APP,通过生成的公开URL实现在线实时运行与分享
代码与数据集获取:如需获取本文的源代码和数据集,请添加作者微信联系
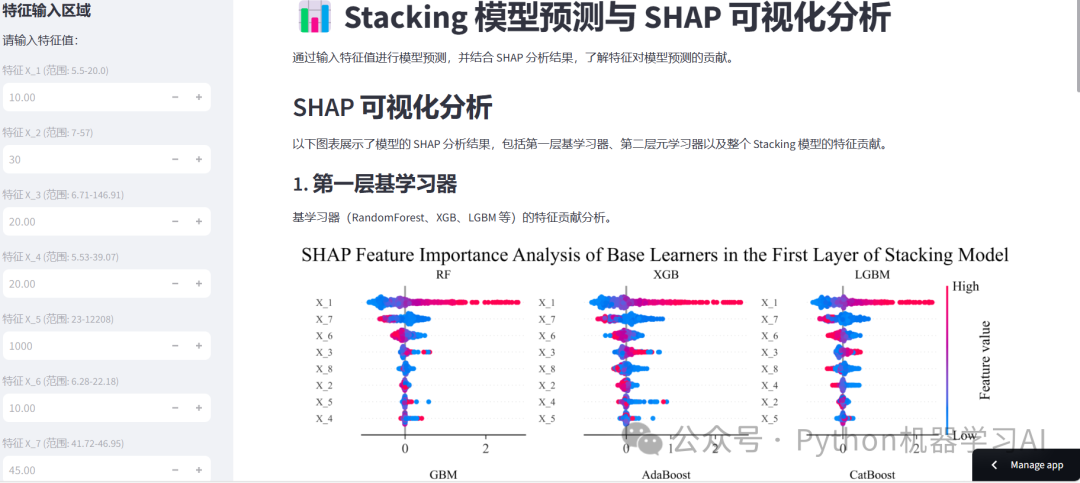
APP简介
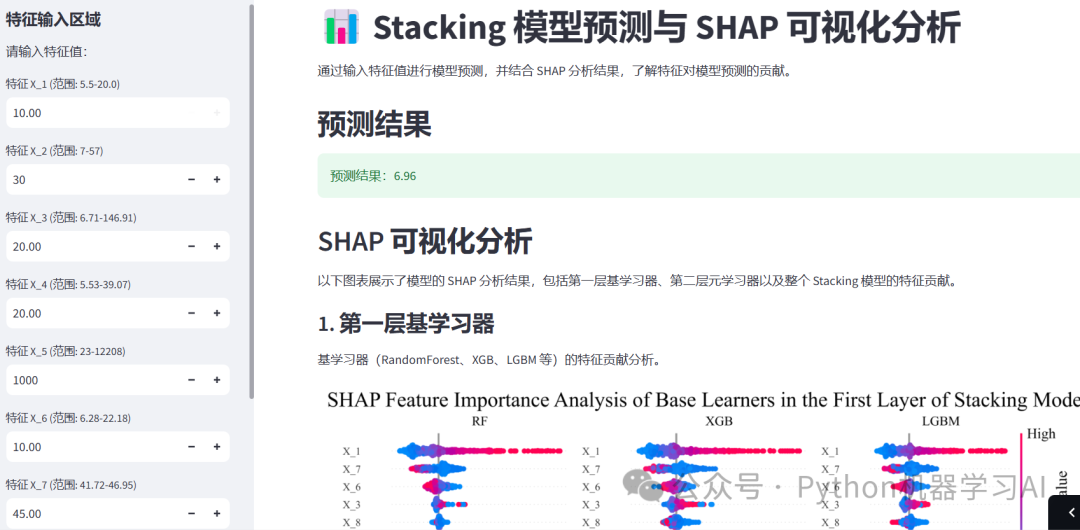
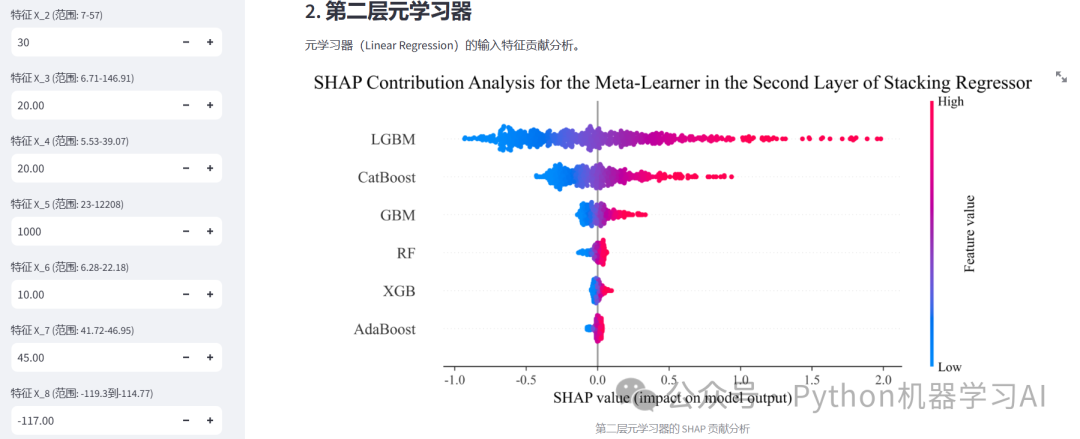
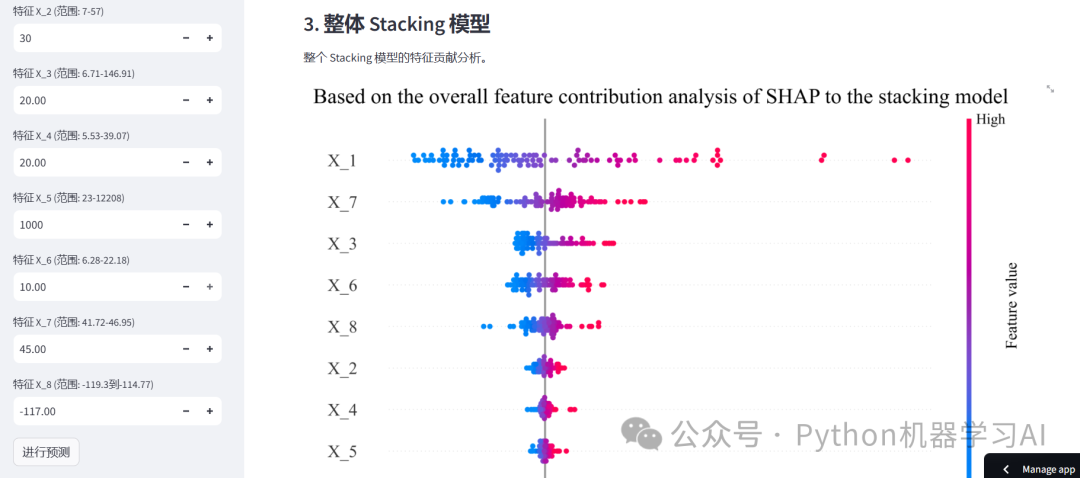
这个APP利用Streamlit框架实现了一个交互式工具,支持用户通过输入特征值对Stacking模型进行实时预测,同时结合SHAP(SHapley Additive exPlanations)分析,提供了模型的多层次特征贡献可视化。用户可以查看第一层基学习器(如随机森林、XGBoost等)、第二层元学习器(线性回归)的特征重要性分析,以及整个Stacking模型的整体特征贡献。这一工具不仅实现了预测功能,还直观展示了模型的解释性分析,帮助用户理解特征对模型预测结果的影响,代码与数据集获取:如需获取本文的源代码和数据集,请添加作者微信联系
往期推荐
复现SCI文章 SHAP 依赖图可视化以增强机器学习模型的可解释性
复现 Nature 图表——基于PCA的高维数据降维与可视化实践及其扩展



















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











