







结论:
1. 前提在train模式下,nn.BatchNormxd中的参数track_running_stats必须为True, 这样才能保存训练时的统计参数: running_mean,running_var; 以及训练时的学习参数: weight,bias(其中weight,bias是缩放系数,在训练时weigth和bias是可训练的参数) 。
2. nn.BatchNormxd在eval模式下计算过程如下:
- 使用在训练模式下保存的统计参数running_mean,running_var作为mean和var
- 使用在训练模型下保存的学习参数weight,bias
- 计算公式(MyBatchnorm1d的forward方法)
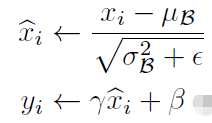
其中:
是running_mean,
是running_var,
是weight,
是bias
代码笔记:
1. 给模型添加可训练参数的方法:用torch.nn.Parameter()定义的参数是可训练的参数
self.weight = torch.nn.Parameter(torch.ones(num_features).float()) self.bias = torch.nn.Parameter(torch.zeros(num_features).float())2. 给模型添加不可训练的参数的方法:
#register_buffer相当于requires_grad=False的Parameter,所以两种方法都可以 #方法一: self.register_buffer('running_mean',torch.zeros(num_features)) self.register_buffer('running_var',torch.zeros(num_features)) self.register_buffer('num_batches_tracked',torch.tensor(0)) #方法二: # self.running_mean = torch.nn.Parameter(torch.zeros(num_features),requires_grad=False) # self.running_var = torch.nn.Parameter(torch.ones(num_features),requires_grad=False) # self.num_batches_tracked = torch.nn.Parameter(torch.tensor(0),requires_grad=False)3. 模型参数名称和个数相同的情况下,两个模型可以参数互加载(比如加载预训练模型的参数)
4. 模型参数名称和个数不一致的情况下,也可以加载,但需要手动进行参数对应
第一步:模型训练,并保存模型参数
定义模型SimpleModel进行训练,训练是一个简单的训练,主要是为保存参数,便于后面的验证
# -*- coding: utf-8 -*-
import torch
from torch.autograd import Variable
import torch.optim as optim
batchsize = 16
rawdata = torch.randn([64,3])
y = Variable(torch.FloatTensor([4,5]))
dataset = [Variable(rawdata[curpos:curpos+batchsize]) for curpos in range(0,len(rawdata),batchsize)]
class SimpleModel(torch.nn.Module):
def __init__(self):
super(SimpleModel,self).__init__()
linear1_features = 5
self.linear1 = torch.nn.Linear(3,linear1_features)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(linear1_features,2)
#设计时batchnorm放在linear1后面,所以这里用linear1的输出维度
self.batch_norm = torch.nn.BatchNorm1d(linear1_features) #标准库中的Barchnorm,track_running_stats默认为True
# self.batch_norm = torch.nn.BatchNorm1d(linear1_features,track_running_stats=True) #标准库中的Barchnorm
def forward(self,x):
x = self.linear1(x)
x = self.relu(x)
x = self.batch_norm(x)
x = self.linear2(x)
return x
model = SimpleModel()
print(list(model.parameters()))
#查看模型的初始参数
print(model.state_dict().keys())
# for i, j in model.named_parameters():
for i, j in model.state_dict().items():
print('++++',i)
print('\t',j)
train_demo = 1
if train_demo == 1:
loss_fn = torch.nn.MSELoss(size_average=False)
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
model.train()
for t,x in enumerate(dataset):
y_pred = model(x)
loss = loss_fn(y_pred,y)
print(t,loss.data)
model.zero_grad()
loss.backward()
optimizer.step()
#查看训练后的模型参数
print('##################The trained Model parameters###############')
print(model.state_dict().keys())
# for i, j in model.named_parameters():
for i,j in model.state_dict().items():
print('++++',i)
print('\t',j)
#保存模型参数
state = {'model':model.state_dict()}
torch.save(state,'test_batchnorm.pth')
第二步:自定义模型,按自己的理解定义BatchNorm
1. 按自己理解的Batchnorm计算过程定义MyBatchnorm1d
2. 创建模型DebugSimpleModel,与SimpleModel的唯一区别就是batchnorm用的是自定义的MyBatchnorm1d
3. 加载预训练模型SimpleModel的参数到DebugSimpleModel中
4. 验证相同的输入是否具有相同的输出,如果输出相同,那么说明自定义的batchnorm是正确的(与标准库的batchnorm算法一样)
'''
自定义Batchnorm,目的是通过自己的理解来验证标准Batchnorm在eval模式下batchnorm的计算过程.
结论:如果自定义模型的输出与标准模型的输出结果一样,就可以证明自己的理解是对的,自定义的Batchnorm与标准模型的算法一样
前提在train模式下,nn.BatchNorm中的参数track_running_stats必须为True,
这样才能保存训练时的统计参数:
running_mean,running_var;
以及训练时的学习参数:
weight,bias(其中weight,bias是缩放系数,在训练时weigth和bias是可训练的参数)
Batchnorm在eval模式下batchnorm的计算过程如下:
1. 使用在训练模式下保存的统计参数running_mean,running_var作为mean和var
2. 使用在训练模型下保存的学习参数weight,bias
3. 计算公式就是MyBatchnorm1d的forward方法
'''
class MyBatchnorm1d(torch.nn.Module):
def __init__(self,num_features):
super(MyBatchnorm1d,self).__init__()
self.weight = torch.nn.Parameter(torch.ones(num_features).float())
self.bias = torch.nn.Parameter(torch.zeros(num_features).float())
#register_buffer相当于requires_grad=False的Parameter,所以两种方法都可以
#方法一:
self.register_buffer('running_mean',torch.zeros(num_features))
self.register_buffer('running_var',torch.zeros(num_features))
self.register_buffer('num_batches_tracked',torch.tensor(0))
#方法二:
# self.running_mean = torch.nn.Parameter(torch.zeros(num_features),requires_grad=False)
# self.running_var = torch.nn.Parameter(torch.ones(num_features),requires_grad=False)
# self.num_batches_tracked = torch.nn.Parameter(torch.tensor(0),requires_grad=False)
def forward(self,x):
eps = 1e-5
x_normalized = (x - self.running_mean) / torch.sqrt(self.running_var + eps)
results = self.weight * x_normalized + self.bias
return results
class DebugSimpleModel(torch.nn.Module):
def __init__(self):
super(DebugSimpleModel,self).__init__()
linear1_features = 5
self.linear1 = torch.nn.Linear(3,linear1_features)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(linear1_features,2)
self.batch_norm = MyBatchnorm1d(linear1_features) #使用自定义的Batchnorm
def forward(self,x):
x = self.linear1(x)
x = self.relu(x)
x = self.batch_norm(x)
x = self.linear2(x)
return x
'''
#自定义模型实例化
实验方法:
1. 加载预训练模型的参数作为自定义模型的参数
2. 在eval模式下输出模型的结果与标准模型进行对比
'''
debug_demo = 1
if debug_demo == 1:
debug_model = DebugSimpleModel()
#因为自定义的模型参数与标准模型的参数完全一样,所以把标准模型作为预训练的模型(即可以加载标准模型的训练后的参数作为自己的参数)
debug_model.load_state_dict(torch.load('test_batchnorm.pth')['model'])
debug_model.eval()
#查看加载的参数情况是否正确(与标准模型训练后的参数保持一致)
# print(debug_model.state_dict().keys())
# # for i, j in test_model.named_parameters():
# for i,j in debug_model.state_dict().items():
# print('++++',i)
# print('\t',j)
print('++++++++++++ Mymodel Output ++++++++++++++')
for t,x in enumerate(dataset):
y_pred = debug_model(x)
print(y_pred)
'''
标准模型的实例化与输出结果,与自定义模型的输出进行对比,看是否一致。
如果一致说明自定义模型的batchnorm算法是正确的,与标准库的Batchnorm算法一样
'''
test_demo = 1
if test_demo == 1:
test_model = SimpleModel()
test_model.load_state_dict(torch.load('test_batchnorm.pth')['model'])
test_model.eval()
print('\n++++++++++ Norm output ++++++++++++++++')
for t,x in enumerate(dataset):
y_pred = test_model(x)
print(y_pred)















 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









