







一、什么是TLB?
TLB(Translation Lookaside Buffer)转换检测缓冲区是一个内存管理单元,用于改进虚拟地址到物理地址转换速度的缓存。
TLB是一个小的,虚拟寻址的缓存,其中每一行都保存着一个由单个PTE(Page Table Entry,页表项)组成的块。如果没有TLB,则每次取数据都需要两次访问内存,即查页表获得物理地址和取数据。
根据TLB的功能也许"页表cache”会更加符合吧。
二、TLB的工作原理
TLB在设计上非常靠近CPU而目访问速度非常快,有了TLB,MMU再进行地址转換时会首先去TLB中查找页表映射信息,如果TLB中正好有该信息的话那么接下来将无需访问内存,这将极大的加快地址转换速度,TLB的应用使得页式内存管理方法在地址转换速度上达到了实用的程度。
当MMU从虛拟地址中提取出页号后直接去查找TLB,如果TLB中保存了该页号对于的页表项那么TLB直接返回查找结果和页表项,这被称为TLB命令(TLB hit),接下来的过程想必大家就很清楚啦,如果页表项的保护位允许我们访问该页,那么从虛拟地址中提取出页内偏移,拼接上页帧号就得到最终的物理内存地址了,而如果TLB中并没有该页号对应的页表项信息,那么TLB未命中,即TLB miss。这时将不得不访问一次内存从页表中查找对应的页表项信息,如果页表项表明进程尚未使用该页,那么将产生段错误,segmentationault,此后操作系统将接管系统来处理该进程。而如果页表项表明该进程不能访问该页,那么将产生保护错误,protection fault,此后操作系统同样接管系统来处理该进程;
如果丁LB命中那么本次地址转换速度将会很快;但如果并没有命中,我们将不得不访问一次内存,速度将会非常慢,如果你的程序在执行过程中持续出现TLB不能命中的情况,那么程序运行速度将显著减慢,因此作为程序员我们应该写出对TLB友好的程序,这是什么意思呢?接下来看一个例子就明白啦。
为了更加清楚的展示TLB的作用,在这里我们使用一个简单的访问数组的代码来说明丁LB是如何提高系统性能的。假设程序中使用了一个包含有12个整数的二维数组A,其中:
A[0][0]-A[0][2]占据了第5号页,映射到了第第10号页帧;
A[1][0]-A[1][2]占据了第6号页,映射到了第8号页帧;
A[2][0]-A[2][2]占用了第7号页,映射到了第第13号页帧中;
A[3][0]-A[3][2]占用了第8号页,映射到了第第7号页帧中;
现在需要计算数组元素的和,代码如下:
int nsum = 0;
for(int i = 0;i<4;i++)
{
for(int j = 0;j<3;j++)
{
nsum+=A[i][j];
}
}
该代码中首先访问的是A[0][0], CPU向内存发出读取A[0][0]指令后,MMU提取A[0][0]虛拟地址(&A[0][0])所在的页号,即5,然后去TLB中查找是否有页号5的信息,显然TLB中还没有第5号页的信息(假设开始时TLB为空,这并不会影响我们的讨论),因此此次访问TLB不能命中,这时将不得不访问一次内存,查找页表后将第5号页的信息写入TLB,重新执行此次的机器指令,由于第5号页的映射信息已经写入TLB,那么这时TLB命中,MMU将虚拟地址转换为物理内存地址,该物理内存地址就是A[0][0]所在的
物理内存地址。
接下来访问的是A[0][1],A[0][1]和A[0][0]在同一页中,也就是第5号页,由于在访问A[0][0]时,第5号的映射信息已经装入TLB中,因此本次虛拟地址转换查找TLB将会命中(图书管理员这次不用再跑一趟啦),同样的道理由于A[0][2]和A[0][1]以及A[0][0]在同一页,因此访问A[0][2]时TLB也将命中.
访问完A[0][0]-A[0][2]后,CPU继续执行指令访问A[1][0]-A[1][2],这个和访问A[0][0]-A[0][2]类似就不再说了。
接下来看另外一个反例
int nsum = 0;
for(int j = 0;j<3;j++)
{
for(int i = 0;i<4;i++)
{
nsum+=A[i][j];
}
}
这段代码和之前的相比,仅仅就是改变了数组的遍历顺序而已,第一段代码是按行遍历,这段代码是按列来遍历。
首先数组中的A[0][0]被访问,A[0][0]位于进程的第5号页中,因此地址转换时需要在TLB中查找第5号页的映射信息,刚开始时TLB为空,因此TLB不会命中,这种情况下将不得不访问一次内存,将页表中第5页的映射信息写入下LB中,此后重新执行访问A[0][0]的机器指令并成功从TLB中查找到相应的信息。
接下来访问的是A[1][0],注意到和按行遍历不同的是,A[1][0]位于第6页中A[1][0]并没有和A[1][0]位于同一页,因此访问A[1][0]时写入TLB的映射信息在此时起不了作用,也就是说访问A[1][0]进行地址转换时依然无法命中TLB,我们依然需要访问内存将第6号页的映射信息写入TLB中,此后重新执行访问A[1][0]的机器指令,该过程和之前一样.
因为TLB的容量很小,所以不足于将A[0][0],A[1][0],A[2][0],A[3][0]的信息都存下,当访问A[0][1]的时候,A[0][0]的信息早已被覆盖,又得走A[0][0]的路子。所以上述代码空间局部性很差。
三、案例对比
下面给个实际的例子解说一下:
int a[100000][1000] = { 0,1,2,3,4 };
void fun1()
{
a[100][2] = 100;
a[99][1] = 200;
a[672][11] = 300;
clock_t t1 = clock();
int nsum = 0;
for (int i = 0;i<100000;i++)
{
for (int j = 0;j< 1000;j++)
{
nsum += a[i][j];
}
}
clock_t t2 = clock();
cout <<"按行访问时间:"<< t2 - t1 << endl;
cout << "求和:" << nsum << endl;
}
void fun2()
{
a[100][2] = 100;
a[99][1] = 200;
a[672][11] = 300;
clock_t t1 = clock();
int nsum = 0;
for (int i = 0; i < 1000; i++)
{
for (int j = 0; j < 100000; j++)
{
nsum += a[j][i];
}
}
clock_t t2 = clock();
cout << "按列访问时间:" << t2 - t1 << endl;
cout << "求和:"<<nsum << endl;
}
void main()
{
fun1();
fun2();
system("pause");
}
结果:
第一次执行
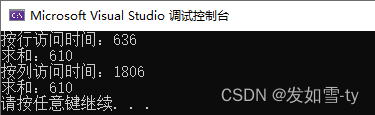
第二次执行:

第三次执行:
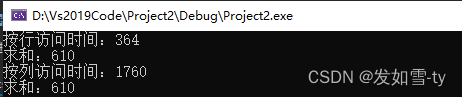
调换顺序执行:
void main()
{
fun1();
fun2();
system("pause");
}
第一次
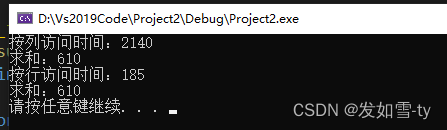
第二次:
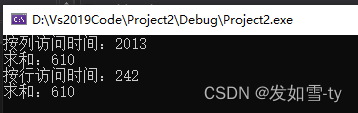
第三次:
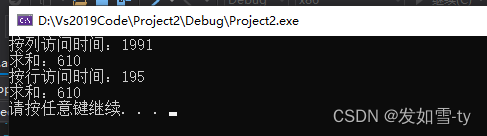
从结果看出,同样的数据,遍历花费的时间差别很大。因此作为程序员,这给我们的启示就是如果对性能要求较高那么我们就必须写出对下LB友好的程序,也就是说我们的程序要有很好的局部性来提高TLB的cache命中率从而加快程序执行速度。

















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











