







今天想用武大的RSOD数据集来做小目标检测,发现数据集中的txt文件夹内容是图片路径+图片类别+坐标信息的格式,和yolov标准版的类别索引+坐标的格式有所区别,于是自己进行了转换,现在把代码贴出来。
首先需要将图片和旧的txt标签数据存放于两个独立的文件夹。如下所示:

然后直接使用我下面的代码:
from PIL import Image
import os
# 旧标签的路径
old_label_path = r'D:\datasets\small-object-detection-datasets\武汉大学RSOD数据集\RSOD\old_label\\'
# 旧的图片数据集的路径
f_path = r'D:\datasets\small-object-detection-datasets\武汉大学RSOD数据集\RSOD\JPEGImages'
# 将要存储的labels的路径
new_file_path = r'D:\datasets\small-object-detection-datasets\武汉大学RSOD数据集\RSOD\\label\\'
# 目标类别以及对应的编号
class_to_index = {'aircraft': 0, 'oiltank': 1, 'overpass': 2, 'playground': 3}
# 获取old_label_path下所有txt文件的文件名列表
txt_files = [file for file in os.listdir(old_label_path) if file.endswith(".txt")]
new_data = [0,0.00,0.00,0.00,0.00]
# 遍历每个txt文件
for txt_file in txt_files:
# 构建txt文件的完整路径
old_label_file_path = os.path.join(old_label_path, txt_file)
i = 0
with open(old_label_file_path, 'r') as file:
for line in file:
# 使用空格分割每一行的数据
data = line.split()
# 其中有些步骤只需要执行一次,如创建新的txt文件夹,和读取图片的路径等等
if i == 0:
# 将.jpg的后缀更换为txt
new_string = data[0].replace(".jpg", ".txt")
new_file_path_concat = os.path.join(new_file_path, new_string)
i += 1
# 检查是否有足够的数据
if len(data) >= 1:
# 将图片路径进行赋值
img_path = os.path.join(f_path, data[0])
# 读取图片的长宽
with Image.open(img_path) as img:
# 获取图片的长宽尺寸
width, height = img.size
print('图片的长为:', height, " ,宽为", width)
# 获取第二个数据(类别)
category = data[1]
# 判断类别是否在映射关系字典中
if category in class_to_index:
# 获取类别对应的索引
index = class_to_index[category]
new_data[0] = index
new_data[1] = int(data[2]) / width
new_data[3] = int(data[4]) / width
new_data[2] = int(data[3]) / height
new_data[4] = int(data[5]) / height
print(data[0])
print(new_data)
else:
print("该行数据不完整")
# 将new_data写入新的txt文件
with open(new_file_path_concat, 'a') as new_file:
for item in new_data:
new_file.write(str(item) + ' ')
new_file.write('\n')
print(f"处理完成: {txt_file}")
通过以上的操作之后就可以直接进行转换了,其实过程还是很简单的,可以尝试看一下转换过程,自己怕以后代码找不到了所以就发出来也方便各位需要的伙伴。
转换之后的结果如下,可以看出是符合yolo标准格式的索引,加坐标的范围的形式: 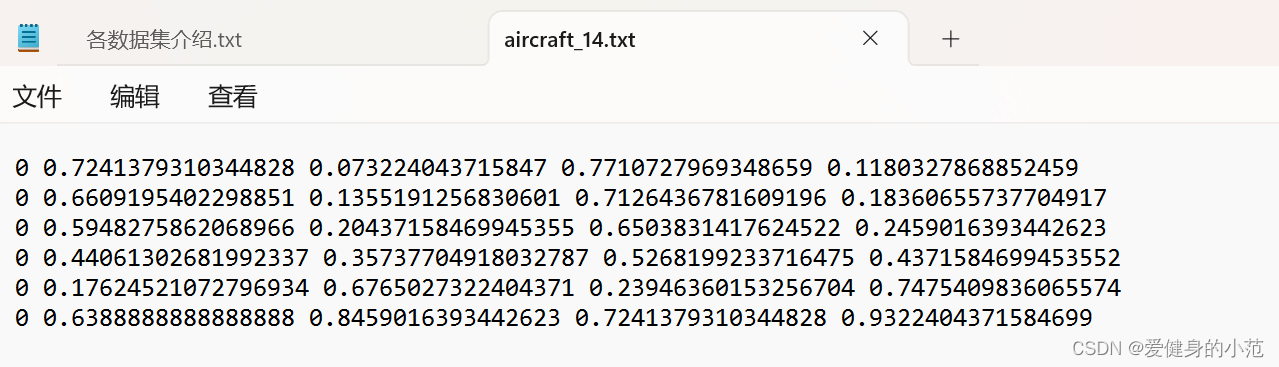 非常抱歉,之前忽略了yolo格式的标签是中心坐标加上矩形框的宽高信息,以下是修改文件直接在目前的基础上进行修改。
非常抱歉,之前忽略了yolo格式的标签是中心坐标加上矩形框的宽高信息,以下是修改文件直接在目前的基础上进行修改。
import os
def convert_coordinates(input_folder, output_folder):
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取输入文件夹中的所有txt文件
txt_files = [file for file in os.listdir(input_folder) if file.endswith(".txt")]
# 遍历每个txt文件
for txt_file in txt_files:
input_path = os.path.join(input_folder, txt_file)
output_path = os.path.join(output_folder, txt_file)
# 处理每个txt文件
with open(input_path, 'r') as infile, open(output_path, 'w') as outfile:
# 逐行读取并处理数据
for line in infile:
# 将每一行的数据拆分为列表
data = line.strip().split()
if len(data) == 5:
# 提取类别标签和矩形框坐标
category = int(data[0])
x1, y1, x2, y2 = map(float, data[1:5])
# 计算矩形中心坐标和宽高
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
width = x2 - x1
height = y2 - y1
# 将转换后的数据写入新文件
outfile.write(f"{category} {cx} {cy} {width} {height}\n")
else:
print(f"Ignoring invalid data in {txt_file}: {line.strip()}")
if __name__ == "__main__":
# 指定输入文件夹和输出文件夹路径
#todo:这个路径是左上右下的标签路径
input_folder = 'D:\datasets\small-object-detection-datasets/NWPU VHR-10 dataset\左上右下labels'
#todo:这个路径是中心+宽高的标签路径
output_folder = 'D:\datasets\small-object-detection-datasets/NWPU VHR-10 dataset\labels'
# 执行坐标转换
convert_coordinates(input_folder, output_folder)
至此,才完成全部的文件转换。















 2693
2693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









