







文章目录
1.函数
1.1函数的引入
0.常用的内置函数:
max,min,sum, divmod
#函数必须有输入和输出。
max_num = max(1, 2, 3)
print(max_num) #3
1.如何创建函数?定义函数,函数内容并不会执行
函数的输入专业叫参数, 函数的输出叫返回值。
重点:
- 形参: 形式参数,不是真实的值(定义函数时的参数)
- 实参:实际参数, 是真实的值(调用函数时的参数)
def get_max(num1, num2):
result = num1 if num1 > num2 else num2
return result
2. 如何调用函数?
max_num = get_max(30, 80)
print(max_num)
1.2变量的作用域
可变数据类型:list, dict,set
不可变数据类型: 数值型, str, tuple
1. 全局变量: 全局生效的变量。函数外面的变量。
name = 'admin'
def login():
print(name)
login()

2. 局部变量: 局部生效的变量。函数内部的变量。
def logout():
age = 19
print(age)
logout()
print(age)

3. 函数内部修改全局变量
- money是局部变量还是全局变量? 全局变量
- 如果要在函数中修改全局的变量,不能直接修改。 需要用global关键字声明修改的变量是全局变量。
- 不可变数据类型修改全局变量一定要global声明, 可变数据类型不需要。
def hello():
global money
money += 1
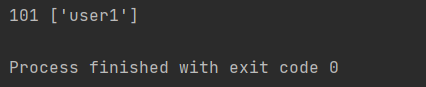
users.append('user1')
print(money, users)
money = 100 # 不可变数据类型
users = [] # 可变数据类型
hello()
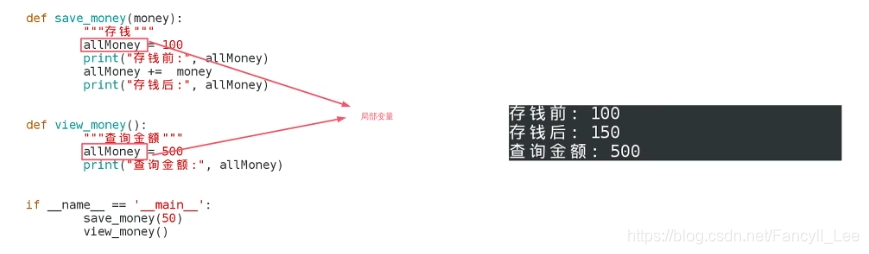
函数内的i局部变量互不影响
1.3参数传递
- 形参和实参
- 参数检查:isinstance(var, int)判断变量var是否为int
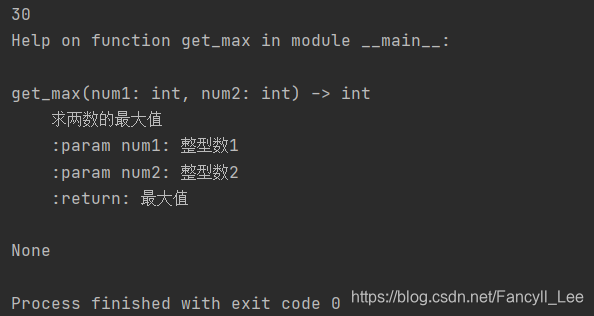
def get_max(num1:int, num2:int)->int: #期望传入参数为整型
"""
求两数的最大值
:param num1: 整型数1
:param num2: 整型数2
:return: 最大值
"""
if isinstance(num1, int) and isinstance(num2, int): #判断是否都是整型
return num1 if num1 > num2 else num2
else:
return 0
result = get_max(20, 30)
print(result)
print(help(get_max)) #help(函数)可以将函数内引号内容打印出来
1.4常见的四类形参
必选参数:必须要传递的参数
默认参数:
可变参数:*args - 元组
关键字参数:**kwargs - 字典
1. 必选参数:必须要传递的参数
def get_max(num1: int, num2: int) -> int:
return num1 if num1 > num2 else num2
result = get_max(20, 30)
print(result)

2. 默认参数:可传可不传的参数
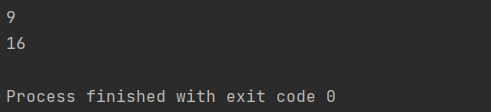
def pow(x, y=2):
return x ** y
result = pow(3) # x=3, y=2, result=9
print(result)
result = pow(2, 4) # x=2,y=4, result=2**4=8
print(result)
3. 可变参数: 参数的个数会变化,可以传0,1,2,3,…n
#args是元组
#args=arguments
def my_sum(*args):
return sum(args)
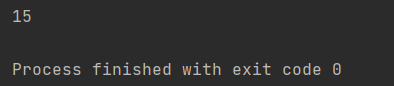
result = my_sum(4, 5, 6) # 15
print(result)
4. 关键字参数:可以传递key和value
#kwargs存储在字典中
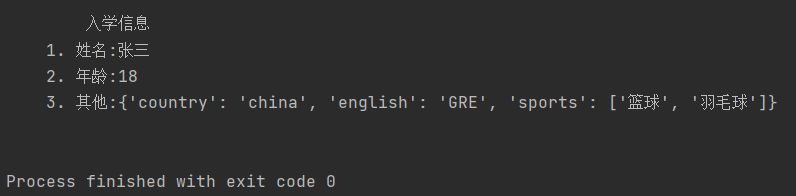
def enroll(name, age=18, **kwargs):
print(f"""
入学信息
1. 姓名:{name}
2. 年龄:{age}
3. 其他:{kwargs}
""")
enroll('张三', country='china', english='GRE', sports=['篮球', '羽毛球'])
from collections import namedtuple
1.5匿名函数
匿名函数指一类无须定义标识符的函数或子程序。Python用lambda语法定义匿名函数,一般比较短,无需特别定义
def get_max(num1: int, num2: int) -> int:
return num1 if num1 > num2 else num2
lambda改写后:
get_max = lambda num1, num2: num1 if num1 > num2 else num2
print(get_max(10, 20))
def pow(x, y=2):
return x ** y
改写后:
pow = lambda x, y=2: x ** y
print(pow(4))
print(pow(2,3))
1.6匿名函数对应的leecode题目
给定一个整形数组, 将数组中所有的0移动到末尾, 非0项保持不变;
- 输入: 数组的记录;0 7 0 2
- 输出: 调整后数组的内容; 7 2 0 0
0 7 0 2 -before sort
=====
1 0 1 0 - rule: (1 if num==0 else 0)
0 0 1 1
=====
7 2 0 0 -after sort
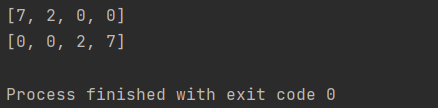
nums = [0, 7, 0, 2]
nums.sort(key=lambda num: 1 if num==0 else 0)
print(nums)
#需求: 将所有的偶数排前面,所有的奇数排后面。
nums = [0,7,0,2]
nums.sort(key=lambda num: 0 if num%2==0 else 1)
print(nums)
sorted()函数可以自定义参数,使得数组按自定义规则排序,但是并不改变原数组内容
1.7递归函数
函数可以调用函数。结论: 一个函数在内部调用自己本身,这个函数就是递归函数。
需求: 计算阶乘 factorial: n! = 1 * 2 * 3 * … * n
Leetcode 二叉树的题目, 大部分需要用递归。
需求: 求n的阶乘。 n!=n*(n-1)(n-2)…1
方法1: for循环
res = 1
n = 3 # 3!=3*2*1=1*2*3=6
for i in range(1,n+1):
res = res * i # res=1*1*2*3
print(res)
2. 方法2: 递归
- 递归的规律
- 退出递归的条件
3! = 3 * 2! = 3 * 2 * 1! = 6
n! = n*(n-1)!
def f(n):
"""计算阶乘"""
if n == 1:
return 1
return n * f(n-1)
print(f(5))
重点: return n * f(n-1)
1.8递归实现fib数列
def fib(n):
"""fib数列"""
if n == 1 or n == 2:
return 1
return fib(n-1) + fib(n-2)
#1, 1, 2, 3, 5, 8
print(fib(5))
2.文件操作
- 默认数据是加载到内存中,结果也是保存到内存中, 程序执行结束,所有的数据释放。
- 在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件。
open(文件名,访问模式) e.g. f = open(‘test.txt’, ‘w’)
如果文件不存在那么创建,如果存在那么就先清空,然后写入数据
2.1文件的基本操作
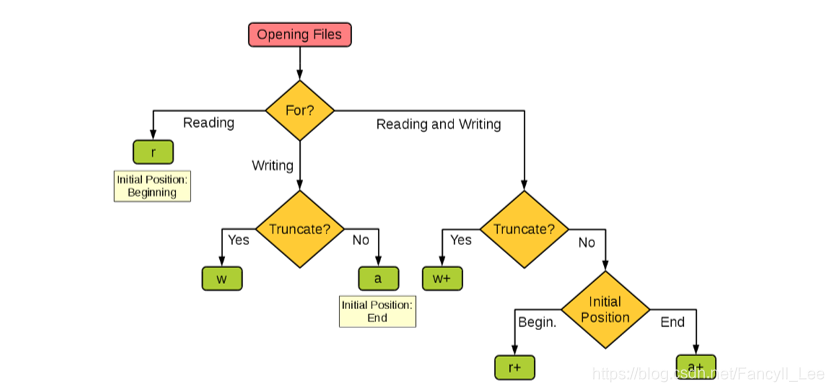
- 打开文件
mode:
r: 只能读文件
w: 只能写入(清空文件内容)
a+: 读写(文件追加写入内容)
f = open('doc/hello.txt',mode='a+')
注:
2. 文件读写操作
print(f.read()) #读
f.write('java\n') #写
3. 关闭文件
f.close()
注:文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
2.2with语句
python引入了with语句来自动帮助我们调用close()方法
python中的with语句使用于对资源进行访问的场合,保证不管处理过程中是否发生错误或者异常都会自动执行规定的(“清理”)操作,释放被访问的资源,比如有文件读写后自动关闭、线程中锁的自动获取和释放等。
在此涉及指针,with语句写入文件时,指针默认停留在内容末尾处,此时read函数不能读取指针之前的内容,需要调整指针位置:
seek(offset, from)有2个参数: offset:偏移量 from:方向
- 0:表示文件开头;
- 1:表示当前位置;
- 2:表示文件末尾
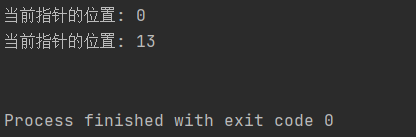
with open('doc/test.txt', 'w+') as f:
f.write('hello world\n') # 写入文件
f.seek(0, 0) # ****: 移动指针到文件最开始
print("当前指针的位置:", f.tell())
f.seek(0, 2) # 移动指针到文件末尾
print("当前指针的位置:", f.tell())
print(f.read()) # 读取文件内容
2.3os模块
os,语义为操作系统,处理操作系统相关的功能,可跨平台。 比如显示当前目录下所有文件/删除某个文件/获取文件大小
import os
import platform
1. 获取操作系统类型
print(os.name)
2. 获取主机信息,windows系统使用platform模块, 如果是Linux系统使用os模块
try: 可能出现报错的代码
excpt: 如果出现异常,执行的内容
finally:是否有异常,都会执行的内容
try:
uname = os.uname()
except Exception:
uname = platform.uname()
finally:
print(uname)

3.获取系统的环境变量
envs = os.environ
#os.environ.get('PASSWORD')
print(envs)
4. 目录名和文件名拼接
#os.path.dirname获取某个文件对应的目录名
#__file__当前文件
#join拼接, 将目录名和文件名拼接起来。
BASE_DIR = os.path.dirname(__file__)
setting_file = os.path.join(BASE_DIR, 'dev.conf')
print(setting_file)

2.4_json模块
import json
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。
JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。
这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。

1. 将python对象编码成json字符串
users = {'name':'westos', "age":18, 'city':'西安'}
json_str = json.dumps(users) #将python字符串通过dumps转换为json字符串
with open('doc/hello.json', 'w') as f:
# ensure_ascii=False:中文可以成功存储
# indent=4: 缩进为4个空格
json.dump(users, f, ensure_ascii=False, indent=4)
print("存储成功")
print(json_str, type(json_str))

json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
encoding="utf-8", default=None, sort_keys=False, **kw)
- ensure_ascii=False: 中文存储需要设定为关闭
- indent=4: 增加缩进,增强可读性,但缩进空格会使数据变大
- separators=(’,’,’:’): 自定义分隔符,元素间分隔符为逗号, 字典key和value值的分隔符为冒号
- sort_keys=True: 字典排序
2. 将json字符串解码成python对象
with open('doc/hello.json') as f:
python_obj = json.load(f)
print(python_obj, type(python_obj))

2.5存储为excel文件
如何安装pandas?
pip install pandas -i https://pypi.douban.com/simple
如何安装对excel操作的模块?
pip install openpyxl -i https://pypi.douban.com/simple
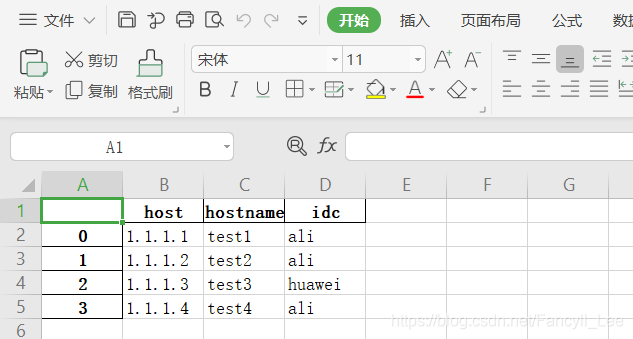
将下述信息存为excel:
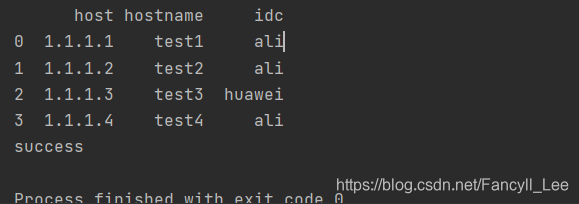
import pandas
hosts = [
{'host':'1.1.1.1', 'hostname':'test1', 'idc':'ali'},
{'host':'1.1.1.2', 'hostname':'test2', 'idc':'ali'},
{'host':'1.1.1.3', 'hostname':'test3', 'idc':'huawei'},
{'host':'1.1.1.4', 'hostname':'test4', 'idc':'ali'}
#1. 转换数据类型
df = pandas.DataFrame(hosts)
print(df)
#2. 存储到excel文件中
df.to_excel('doc/hosts.xlsx')
print('success')















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









