






目录
第四章 函数
1 函数的概念
1:函数就是一段具有特定功能的代码片段;
2:函数的使用:两步走 A:先定义; B:后调用。
格式:
def 函数名(): # 结尾有:,函数使用def来定义
代码1 # 强制缩进 --操作步骤
代码2
...
1:!一般给函数命名: 动词() 动词_名词() play() play_ball()
2:当一个函数定义好后,一般具有特点:
①通用性;可以应用很多地方
②代码固定了;一旦定义好,函数内的代码尽可能不用更改.
1.2 函数的参数
1:没有参数的函数 = 无参函数(一般叫函数);有参数的函数,叫做有参函数;
2:形参:在【定义】函数时,函数名后面的参数就叫做形式参数,简称为形参; def 函数名(形参1,形参2,xxx)
3:实参:只有在【调用】了函数后,才会有实际参数,简称实参; 函数名(实参1,实参2,xxx) --有实际意义
4:在调用函数时,传递参数要注意:参数的个数、类型、顺序.
1.3 函数的返回值
函数完成一件事情后,最后要返回给函数的结果
返回值语法:
def 函数名([参数1,参数2,...]):
代码1
代码2
reyurn 值
)
eg:带有返回值的函数定义
# 1.定义函数
def get_multiply(a,b):
ret=a*b
return ret
# 2.调用函数
result=get_multiply(10,20) #也可以用变量来接收返回值
print(result)
注意:return关键字的作用有两个:把结果返回给函数,结束函数
2 变量的作用域
局部变量
1:局部变量:定义在函数内的变量,就叫做局部变量;
2:全局变量:与函数处于同一级别的变量,定义在模块(.py文件)中的变量,就叫做全局变量.
全局变量名 = 值
def 函数名([局部变量1,局部变量2,...]):
局部变量x = 值
代码...
代码...
3 函数的多种参数
3.1 位置参数
# 1.定义变量
# 2.显示数据,格式化符号
def show_info(name,age):
print("=="*10)
print("显示个人信息如下:")
print("姓名:%s"%name)
print("年龄:%d"%age)
print("=="*10)
# 3.调用
show_info("smile",19)
# show_info("smile","19") #报错 TypeError: %d format: a number is required, not str
#报错:缺少位置参数, positional argument:位置参数
TypeError: show_info() missing 1 required positional argument: 'age'
show_info("smile")
3.2 关键字参数
当函数调用时,也通过“键=值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。【个数、类型、顺序】
def 函数名(参数1,参数2,...):
代码
...
函数名(参数名1=值,参数名2=值,...) # 关键字参数
eg:定义一个显示姓名、年龄、性别的函数,在调用时使用关键字参数
def show_infos(name,age,sex):
print("个人信息如下:")
print(f"姓名:{name}")
print(f"年龄:{age}")
print(f"性别:{sex}")
# 调用
show_infos(age=24,name="smile",sex="男")
报错 关键字参数异常
show_infos(age=24,name="smlie",female="男")
运行结果如下:TypeError: show_infos() got an unexpected keyword argument 'female'

3.3 缺省参数!
缺省参数也叫默认参数,用于在定义函数时,为参数提供默认值。
1:当不给缺省参数传递值时,就默认使用默认值;
2:当给缺省参数传递了值时,以传递的值为准.
def show_info(name,age,sex="男"): # 缺省参数
print("个人信息如下:")
print(f"姓名:{name}")
print(f"年龄:{age}")
print(f"性别:{sex}")
show_info("smile",18,"女")
3.4 不定长参数!
不定长参数也叫可变参数。用于不确定调用时要传递多少个参数的场景,当然也可以不传递参数。
1:不定长参数可以使用*args、**kwargs; --规范! *fangge **kwfangge
2:*args表示的是元组形式,传递参数时使用位置参数;
3:**kwargs表示的是键值对形式(字典),传递参数时使用关键字参数;
4:两个参数可以一起使用,**kwargs放在结尾处.
定义函数:
def 函数名(参数1,..,*args,**kwargs):
代码
...
# # 1.函数1 *args 元组
def get_sum1(*args):
# print(args)
# pass
sum1=0
for temp in args:
sum1+=temp
print(f"多数之和为{sum1}")
get_sum1(1,2)
# 2.函数2 **kwargs 字典
def get_sum2(**kwargs):
# print(kwargs)
sum2=0
for value in kwargs.values():
sum2+=value
print(f"多数之和为{sum2}")
get_sum2(a=2,b=24)
# 3.函数3
def get_sum3(*args, **kwargs):
sum3 = 0
for temp in args:
sum3 += temp
sum4 = 0
for value in kwargs.values():
sum4 += value
print(f"多数之和为{sum4}")
get_sum3(10,20,30,40,a=19,b=199,c=178)
4 拆包和交换变量值
拆包
# 1.定义函数,返回多个数据
def get_sum_sub(a,b):
sum=a+b
sub=a-b
return sum,sub
# 拆包
ret1,ret2 =get_sum_sub(28,10)
print(f"和为:{ret1}")
print(f"差为:{ret2}")
# 2.items()处理
student={"name":"smile","age":"18","gender":"boy"}
# for (key,value) in student.items(): #要不要括号都行
for key,value in student.items():
print(f"{key}-->{value}")
(1)当要把一个组合的结果快速获取元素数据时,可以使用拆包来完成;
(2)注意:对列表、元组数据结果,都可以使用拆包方式。
!交换变量值
使用拆包方式可以用于交换变量的值。
1.拆包-呼唤两个数位置
a=10
b=98
# (a,b)=(b,a) #方法一
b,a=(a,b) #方法二
print(f"变量a={a},b={b}")
data = [12, 3, 14, 56, 7, 100, 1,199]
max_value = data[0]
min_value = data[0]
for temp in data:
if max_value < temp:
max_value = temp
if min_value > temp:
min_value = temp
print(f"最大值为:{max_value}")
print(f"最小值为:{min_value}")
5 扩展函数:引用&匿名函数
引用
引用可以通俗的称为内存地址值。在Python中,引用有两种表现形式:
(1)十进制数 5040624
(2)十六进制数 0x45AC6
查看引用语法:id(变量名)
我们可以把id()值理解为变量所在内存的地址值。
# 1.定义变量,查看引用
a=10
print(a)
print(id(a)) #140713865091008
# 内存地址值是操作系统随机分配的
alist=[1,2]
blist=[1,2]
print(alist==blist) # == 比较的是内容值
print(alist is blist) #is比较的是内存地址值
print(id(alist)) # 2559023101952
print(id(blist)) # 2559023101952
把引用当做参数传递
当定义函数时设定了参数,则在调用函数时也需要传递参数值。
而实际上,当给函数传递参数时,其本质就是:把引用当做参数进行传递。
# 1.定义有参数的函数
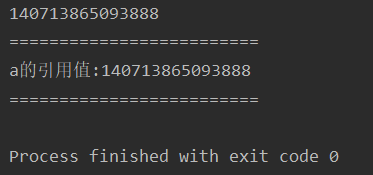
def func(a):
print("=========================")
print(f"a的引用值:{id(a)}")
print("=========================")
# 2.外面输出.函数内输出
numbers=100
print(id(numbers))
func(numbers)
运行结构如下:
匿名函数
用的较少,了解
定义匿名函数需要使用lambda关键字,可以创建小型匿名函数。
匿名函数表示没有名字的函数,这种函数得名于省略了用def关键字声明函数的标准步骤。
定义匿名函数语法:
lambda 参数列表 : 表达式
调用匿名函数语法:
函数名 = lambda 参数列表 : 表达式
函数名([参数列表])
eg:使用匿名函数,对比匿名函数
# 定义求和函数,调用
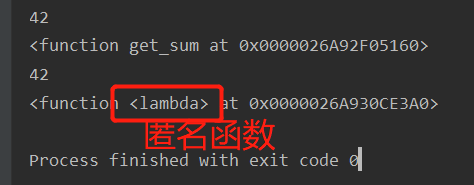
def get_sum(a,b):
c=a+b
return c
print(get_sum(19,23))
print(get_sum) #定义函数时会在内存开辟一块空间存此函数<function get_sum at 0x0000026A92F05160>
# 匿名函数
get_sum1=lambda a,b:a+b
print(get_sum1(19,23))
print(get_sum1) #定义函数时会在内存开辟一块空间存此函数<function <lambda> at 0x0000026A930CE3A0>
匿名函数有以下几个特点和用途:
简洁:通过lambda关键字定义的匿名函数比一般的函数定义更简洁。
方便传递:由于匿名函数没有函数名,因此可以方便地将其作为参数传递给其他函数。
节省内存:由于匿名函数没有函数名,因此不需要在内存中为其分配一个名称,节省了内存空间。
简单的功能实现:匿名函数通常用于实现一些简单的功能,例如排序和过滤等。
lambda的应用
在实际应用中,为便于简化函数传递处理,我们可以使用lambda表达式作为参数进行传递,但要注意:传递的是一个引用。
eg:(1)把lambda表达式当作参数传递给函数;
(2)求解两个数之和,注意:在函数中定义变量并传递。
def get_sum(func):
print("=============")
print(f"输出func的引用值:{func}") #十六进制引用值 输出func的引用值:<function <lambda> at 0x000002937974E3A0>
x=100
y=998
func(x,y)
print(f"求和:{func(x,y)}")
print("=============")
get_sum(lambda a,b:a+b)
第五章 文件操作、模块
1 文件操作
操作文件的步骤:变量名.函数名(xxx)
(1)打开文件,或新建一个文件; open()
(2)读取或写入数据内容; 读read() 写write()
(3)关闭文件。close()
1 打开文件
open(name,mode):创建一个新文件或打开一个已经存在的文件,name指的是文件名,mode指的是访问模式。
对于mode访问模式,如下:
| 模式 | 描述 |
|---|---|
| r | 以读数据的方式打开文件,这是默认模式,可以省略。 |
| rb | 以读二进制原始数据的方式打开文件。 |
| w | 以写数据的方式打开文件。如果文件已存在,则打开文件写入数据是会覆盖原有内容。如果文件不存在,则创建新文件。 |
| wb | 以写二进制原始数据的方式打开文件。 |
| a | 使用追加内容形式,打开一个文件。通常用于写数据,此时会把新内容写入到已有内容后。 |
2 读写数据
读数据
read():从文件中一次性读完整的数据。
readlines():按照行的方式把文件中的完整内容一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
readline():一次读取一行内容。 A.一行一行读取数据; B.当没有数据时,读取的内容就为空字符串 "“
# ---------------------03-快捷读取内容------------------------------
# (1)打开文件,或新建一个文件; open()
file=open("./file/hello.txt","r",encoding="utf-8")
# (2)写入数据内容; 读read()
text=file.read()
print(text)
# (3)关闭文件。close()
file.close()
print("已读取数据")
# ---------------------04-with open读取内容------------------------------
with open("./file/hello.txt","r",encoding="utf-8") as file1:
texts1=file1.read()
print(texts1)
其他读取方式:
readlines():按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。一行文本内容结尾:\n
# (1)打开文件,或新建一个文件; open()
file=open("./file/hello.txt","r",encoding="utf-8")
# (2)写入数据内容 # 使用readlines()读取
lines=file.readlines()
print(lines)
# (3)关闭文件。close()
file.close()
print("已读取数据")
readline():一次读取一行内容。
# 使用readline()读取
while True:
line=file.readline()
print(line)
if len(line)==0:
break
写数据
write(seq):将数据内容写入文件。
(1)一定要注意mode访问模式是w、wb,才能使用write();
(2)一般情况下,write()能写入字符串或二进制数据。 --若要把其他类型的数据写入文件,需转类型。
(3)read()读也是读取字符串或二进制数据。–若要把字符串类型的结果表示成其他类型,需转类型。
# (1)打开文件,或新建一个文件; open()
file=open("./file/test2.txt","w",encoding="utf-8") #中午需要设置编码encoding="utf-8"
# (2)读取或写入数据内容; 读read() 写write()
file.write("你好,python")
# (3)关闭文件。close()
file.close()
print("已写入数据")
3 关闭文件
close():关闭文件
file.close()
2 备份文件
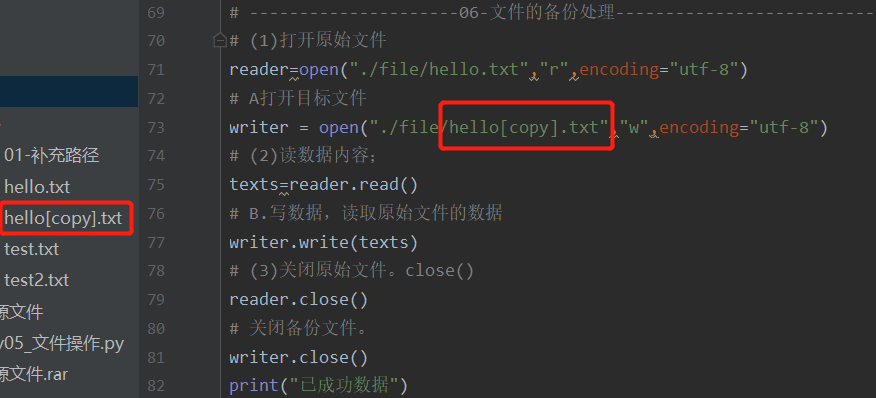
3 模块
Python模块(Module),指的是以.py结尾的Python文件。
模块名是标识符。它可以包含了Python对象定义和Python语句。
模块中能定义函数、变量和类,也能包含其他一些可执行的代码,例如print(xxx)等。
在使用模块前,需要想导入模块,有3种方式:
import 模块名1[, 模块名2...]
from 模块名 import 功能1[, 功能2, 功能3...]不推荐使用,通常用于对框架内容的导入,框架功能多便于细化
from 模块名 import *不推荐使用,加载缓慢,不好阅读程序
import导入模块时,搜索路径:
a.当前目录下找模块
b.找到PATH变量下的环境变量:当前python解释器所在的路径
c.去当前系统用户目录下
3.1 os模块
os模块包含有操作系统所具备的功能,如查看路径、创建目录、显示文件列表等
① 查看目录
exists(pathname):用来检验给出的路径是否存在。
isfile(pathname):用来检验给出的路径是否是一个文件。
isdir(pathname):用来检验给出的路径是否是一个目录。
abspath(pathname):获得绝对路径。
join(pathname,name):连接目录与文件名或目录。
basename(pathname):返回单独的文件名。
dirname(pathname):返回文件路径。
import os
path="./data/file/hello.txt"
print(os.path.exists(path))
# 是否是文件
print(os.path.isfile(path))
# 目录
print(os.path.isdir(path))
# 绝对路径
print(os.path.abspath(path))
# 单独文件名
print(os.path.basename(path))
② 目录的具体操作
getcwd():获得当前工作目录,即当前Python脚本工作的目录路径。
system(name):运行shell命令。
listdir(path):返回指定目录下的所有文件和目录名,即获取文件或目录列表。
mkdir(path):创建单个目录。
makedirs(path):创建多级目录。
remove(path):删除一个文件。
rmdir(path):删除一个目录。
rename(old, new):重命名文件。
import os
# 1.获取当前目录
path=os.getcwd()
print(path)
# 2.获取文件或列表信息
path_name="./data/file"
dir_lists=os.listdir(path_name)
print(dir_lists)
# 3.新建目录:当目录不存在时才需要创建,已存在则不创建
new_path_name="./data/file/hello/world/python"
if not os.path.exists(new_path_name): #如果目录不存在,创建目录
# 创建文件
os.makedirs(new_path_name)
print("创建成功")
Python路径问题
path1="F:\Study\code\pycode\pyproject\day05\data\file\hello.txt"
path2="F:\\Study\\code\\pycode\\pyproject\\day05\\data\\file\\hello.txt"
path3="F:/Study/code/pycode/pyproject/day05/data/file/hello.txt"
path4=r"F:\Study\code\pycode\pyproject\day05\data\file\hello.txt" #正则,原始字符串
3.2 math模块
pow(x, y):返回xy(x的y次方)的值。
sqrt(x):返回数值x的平方根。
# 1.导入模块
import math
# 2.求解次方
print(math.sqrt(16))
# 3.求解平方根
print(math.pow(2,10))
ceil(x):返回数值x的上入整数,如math.ceil(6.3)返回7。
floor(x):返回数值x的下舍整数。
# 1.导入模块
from math import ceil,floor
# 2.上入
print(ceil(3.14))
# 3.下舍
print(floor(3.14))
3.3 time模块
time模块用于表示时间日期,常用函数如下:
sleep(t):休眠,即延迟运行,注意参数t的单位为秒(s)。
time():返回时间戳,即当前时间毫秒数(与1970年1月1日午夜之间的时间差)。
# 1.导入模块
import time
# 2.使用方法
current_time=time.time()
print(current_time)
eg:5秒倒计时
i=5
while i>0:
print(i)
time.sleep(1)
i-=1
3.4 模块取别名
取了别名后只能用别名调用函数
# import math as m
from math import sqrt as sq
# print(m.sqrt(9))
# print(m.pow(2,10))
print(sq(9))
3.5 自定义模块(制作模块)
模块(模块)可以分为3类:
1:标准库 --Python自带的库;
2:扩展库(第三方库) 需要额外安装的库: pip install xxxx
3:自定义库:自定义模块. --定义模块、调用模块
A:模块 == 库
B:[当一个模块很强大时,专业的术语]框架. Django / PySpark / PyFlink
eg:定义与调用模块
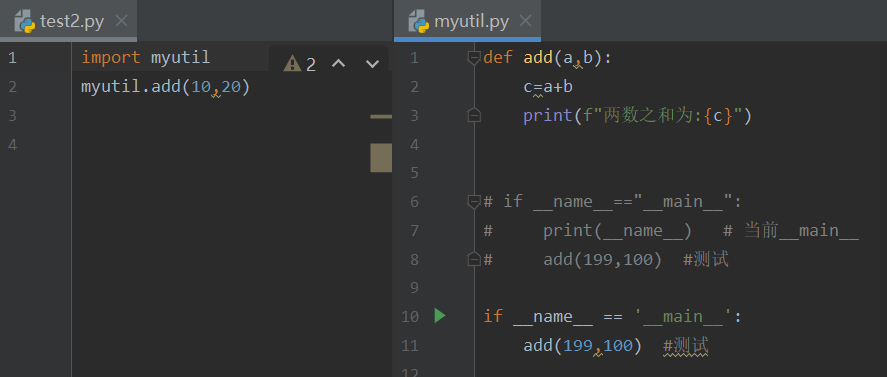
自定义模块,mytool.py文件内容如下:
def add(a,b):
c=a+b
print(f"两数之和为:{c}")
调用mytool自定义模块,mytest.py文件如下:
import mytool
mytool.add(10,20)
制作模块的几个注意事项
__name__ 变量
1:每个模块中都会有一个__name__变量;
2:当在当前模块输出__name__变量时的值__main__。
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息.,例如,在 mytool2.py 文件中添加测试代码。
此时就要注意每个模块中都有的 __name__ 变量,语法:
当__name__在当前模块下测试输出结果: __main__
当在另外的模块里调用输出时,结果: 当前模块名
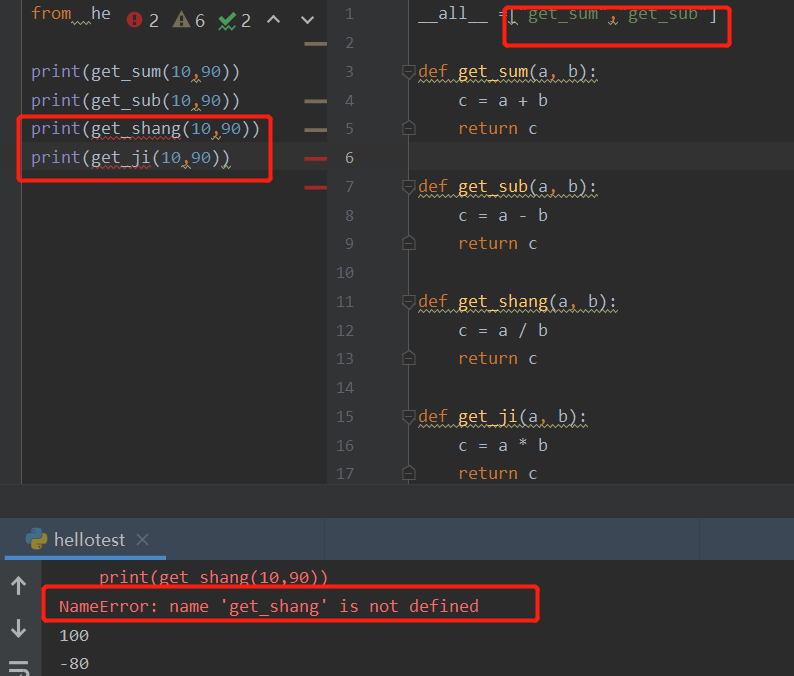
__all__ 变量
如果一个模块文件中有 all 变量,当使用 from xxx import * 导入时,只能导入这个列表中的元素。作用:限制*的取值范围。
语法:
__all__ = ["函数名1","函数名2",xxx]
例如,在自定义模块中有4个函数,但设置了 all 变量值,观察使用 from xxx import * 导入后的调用效果。
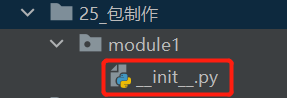
3.6 制作Python包
方法一:新建空白文件夹,在文件夹下新疆命名为__init__.py的Python文件
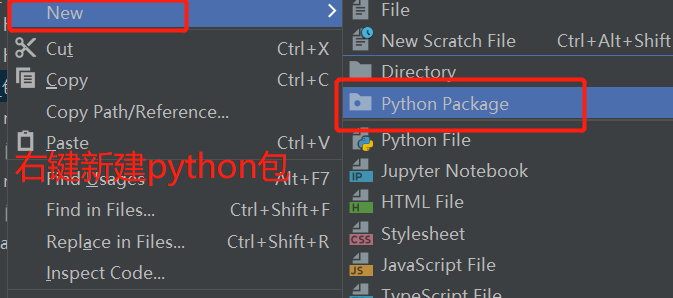
方法二:右键新疆python包
第六章 异常
1.常见的异常类型
1.NameError:直接使用未定义的变量
print(a)
print(a) NameError: name 'a' is not defined
2.IndexError:获取了一个远超列表索引值的元素
# 2.IndexError
strs="hello"
print(strs[100])
print(strs[100]) IndexError: string index out of range
3.KeyError
# 3.KeyError
dicts={}
print(dicts["name"])
print(dicts["name"]) KeyError: 'name'
4.TypeError
print("hello"+666)
print("hello"+666) TypeError: can only concatenate str (not "int") to str
strs="hello"
print("结果:%d"%strs)
print("结果:%d"%strs) TypeError: %d format: a number is required, not str
5.FileNotFoundError
open("./test.txt","r")
open("./test.txt","r") FileNotFoundError: [Errno 2] No such file or directory: './test.txt'
2 异常处理
当程序中遇到了异常时,通常程序会出现崩溃情况。
为了不让程序崩溃,就可以使用异常来快速处理。
异常处理语法:
try:
可能发生异常的代码
except:
如果出现异常时, 执行的代码
# 1.制造异常 2.处理
try:
datas=[1,2,3]
print(datas[100]) #异常 中断
except:
print("已经发生了异常")
print("1111111111") #当处理了异常后,程序可以稳定继续往后的代码
1 捕获一个异常
try:
可能发生异常的代码
except 异常类型名:
当捕获到该异常类型时,执行的代码
# 1.可能发生异常 # 2.捕获
print("1")
try:
print("2")
datas=[1,2,3]
print(datas[100]) #异常 中断
print("3")
except IndexError:
# except TypeError: #报错,IndexError捕获不到
print("4")
print("发生了IndexError异常")
print("5")
运行结果如下:
2 捕获多个异常
语法:
try:
可能发生异常的代码
except (异常类型1,类型2,...):
如果捕获到该异常类型时,执行的代码
# 1.可能发生异常的代码
try:
data=[1,2,3]
print(data[100])
dicts={}
print(dicts["name"])
except IndexError:
print("发生了IndexError异常")
except KeyError:
print("发生了KeyError异常")
print("11111111")
3 捕获所有异常
语法:
try:
可能发生异常的代码
except Exception[ as 变量]:
当捕获到该异常类型时,执行的代码
Exception的首字母要大写。
# 捕获所有异常
try:
data=[1,2,3]
print(data[100])
dicts={}
print(dicts["name"])
except Exception:
print("发生了异常...")
print("hello world")
异常的其他关键字:else,finally
# 1.制造异常 # 2.处理指定异常
try:
data=[1,2,3]
print(data[100])
except:
print("=====1======已发生异常信息")
else: # 3.else :没有发生异常时,处理的事情
print("没有发生异常时,才会执行代码")
finally: # 4.finally:文件必须关闭
print("无论如何,都会执行finally!!")
总结:
(1)关键字else、finally可以配合异常处理一起使用;
(2)注意:当使用finally部分代码时,可以用于完成一些必须完成的操作,例如关闭文件、关闭系统资源等。[思考]
异常面试题:
def test():
try:
strs="abc"
print(strs[60])
except:
# print("ssss")
return 1
finally:
return 2
print(test())
结果为2,因为返回值2覆盖了前面的返回值1
异常具有传递性:当一段可能发生异常的代码,发生了异常时,若不处理,则会传递给调用处















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









