









入门
-
使用书本:深入理解计算机系统
-
《计算机系统基础》是犬数据技术、软件工程等专业的一门核心专业基础课程。
-
本课程旨在培养一类程序员,他们能够理解硬件、操作系统和编译系统对应用程序的性能和正确性的影响。(即:本书本课的重点是对于高级语言开发有用的计算机基础知识)
-
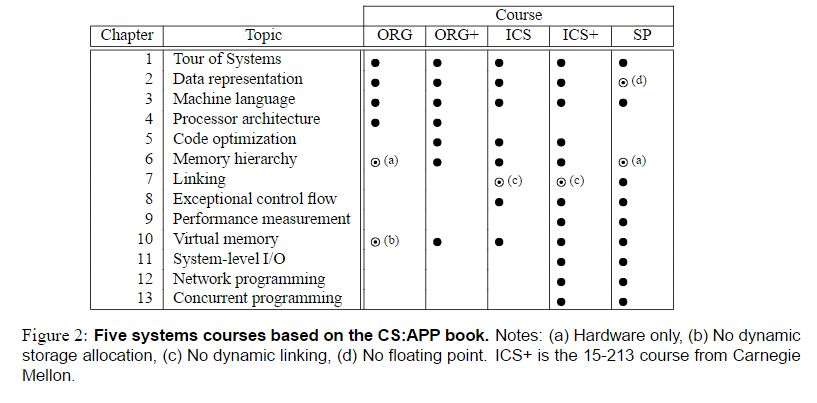
本书推荐了五种课程方式:ORG ORG+ ICS ICS+ SP,我们采取ICS教授法
-
关联课程:
-
计算机网络
操作系统
在考研中只考察这三个(俗称三样)
-
编译原理
-
由hello world想到的
-
数据即为位+上下文
- 源程序实际上就是一个由值0和1组成的位(又称为比特)序列,8个位被组织成一组,称为字节。每个字节表示程序中的某些文本字符。
- 像hello.c这样只由ASCII字符构成的文件称为文本文件,所有其他文件都成为二进制文件。
- hello.c的表示方法说明了一个基本思想:系统中所有的信息——包括磁盘文件、内存中的程序、内存中存放的用户数据以及网络上传送的数据,都是由一串比特表示的。区分不同数据对象的唯一方法是我们读到这些数据对象时的上下文1。
-
编译系统
-
为了在系统上运行hello.c程序,每条C语句都必须被其他程序转化为一系列低级机器语言指令。然后这些指令按照一种称为可执行目标程序的格式打好包,并以二进制磁盘文件即可执行文件的形式存放起来。
-
C语言中编译的过程

-
预处理阶段: 预处理器 (
cpp) 根据以字符#开头的命令(预编译命令),修改源程序 结果就得到了另一个C程序 -
编译阶段:编译器 (ccl) 将文本文件 hello.i 翻译成文本文件 hello.s 包含了一个 汇编语言程序。以上两阶段具体过程详见编译原理
-
上两个阶段产生汇编语言,即低级机器指令
asm main: subq 8,8, %rsp movl .LCO, %dei call puts movl 0,0, %eax addq 8, %rsp ret -
汇编阶段:将汇编翻译为机器语言,汇编器 (
as) 将hello.s翻译成机器语言指令,把这些指令打包成一种 可重定位目标程序 的格式,并将 结果保存在目标文件hello.o中。hello.o文件是一个二进制文件; -
链接阶段:链接器 (
ld) 将程序中使用的不同库文件(比如printf.o)预编译好的.o文件合并, 结果得到可执行目标文件,可以被加载到内存中,由系统执行。-
链接是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(或被拷贝)到存储器并执行。链接可以执行于编译时(源代码被翻译成机器代码时);也可以执行于加载时(程序被加载器加载到存储器并执行时);还可以执行与运行时,由应用程序来执行。
-
目标文件三种形式:
-
可重定位目标文件
-
可执行目标文件
-
共享目标文件。可以在加载或者运行时被动态地加载到存储器并链接。
-
-
理解链接器将帮助你构造大型程序;将帮助你避免一些编程错误;将帮助你理解语言的作用域规则如何实现;有助于理解和使用共享库等。
-
-
-
为什么要了解编译过程?
优化程序性能。现代编译器通常可以生成很好的代码,我们无需了解编译器的内部工作。 但是,为了在
C程序中做出好编码选择,需要了解一些机器代码以及编译器将不同的 C 语句转化为机器代码的方式。理解链接时出现的错误。最令人困扰的程序错误往往都与 链接器 操作有关,尤其是构建大型软件系统时。
避免安全漏洞。缓冲区溢出 错误是造成安全漏洞的主要原因。由于很少有程序员 理解 数据 和 控制信息 存储在程序栈上的方式会引起的后果。
-
-
运行
-
在shell或者其它调用操作系统命令的程序中打开可执行文件,如
./hello -
在硬件上可执行文件的处理过程:
-
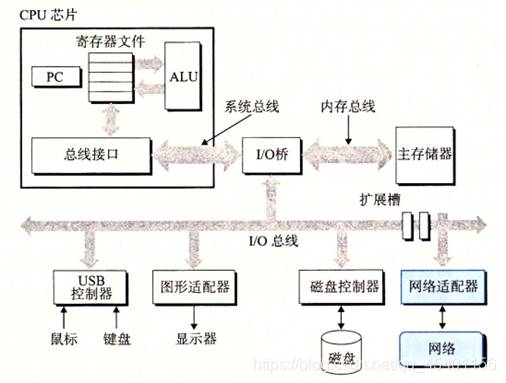
-
解析:
-
1、CPU程序计数器 PC:是一个 4 字节或是 8 字节的存储空间,里面存放的是某一条指令的地址。
-
2、总线
内存和处理器之间通过总线来进行数据传递。实际上,总线贯穿了整个计算机系统,
它负责将信息从一个部件传递到另外一个部件。通常总线被设计成传送固定长度的
字节块,也就是字(word),至于这个字到底是多少个字节,各个系统中是不一样的,
32 位的机器,一个字长是 4 个字节;而 64 位的机器,一个字长是 8 个字节. -
3、输入输出设备:
控制器与适配器主要区别是在于它们的封装方式
资料:控制器是置于I/O设备本身的或者系统的主印制电路板(通常成为主板)上的芯片组,而适配器则是一块插在主板插槽上的卡。数据从一个地方搬运到另外一个地方需要花费时间,系统设计人员的一个主要任务就是缩短信息搬运所花费的时间。
-
-
过程:
- 命令字符读入寄存器再读入内存,由shell程序解析命令;
- 运用DMA(直接存储器存取)技术,将程序需要输出的字符串直接输入内存;
- 处理器执行机器语言指令,并将需输出字符串拉到寄存器;
- 从寄存器文件中复制数据到总线接口2,再复制到显示适配器,最后在屏幕上显示。
-
-
计算机系统的简略结构如下所示:

-
关于寄存器与高速缓存:
-
根据机械原理,较大的存储设备比较小的存储设备运行的慢,比如一个磁盘比主存大1000倍,但是处理器从磁盘上读取一个字的时间开销比从主存读取的开销大1000倍。类似的,寄存器只存储几百个字节,但是主存存放几十亿字节,所以从寄存器读数据,比从主存块100倍。
-
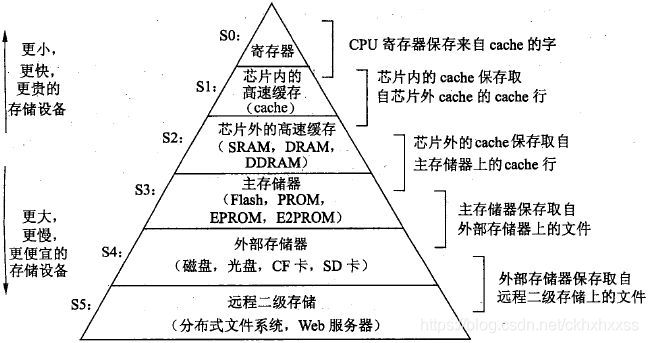
存储器的层次结构:上一层的存储器作为下一层的高速缓存,因此寄存器文件是L1的高速缓存,L1是L2的高速缓存…
-
为了缩小处理器和主存之间的差异,采用高速缓存存储器作为寄存器的补充
-
-
-
关于操作系统:
-
操作系统的两个基本功能:
- 防止硬件被失控的应用程序滥用
- 向应用程序提供简单一致的机制来控制复杂的低级硬件设备
-
操作系统是用户和应用与硬件间的媒介,操作系统操纵硬件
-
操作系统所应用的三个基本的抽象概念:
-
进程:对处理器、主存和 I/O 设备的抽象表示
-
进程是操作系统对正在运行的程序的一种抽象
-
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位
-
一个进程由多个线程组成,每个线程都运行在进程的上下文中,共享同样的代码和数据。
-
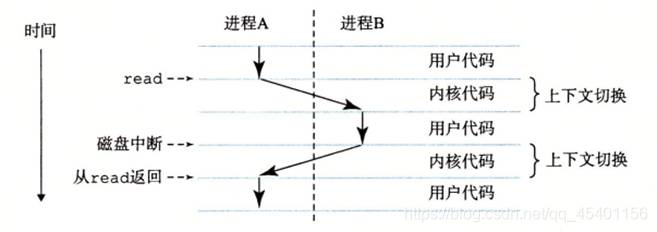
并发运行是指一个进程的指令和另一个进程的指令交错执行(也即,并行是在快速地切换进程),多个进程同时活动。一个CPU通过上下文切换实现并发执行多个程序。
-
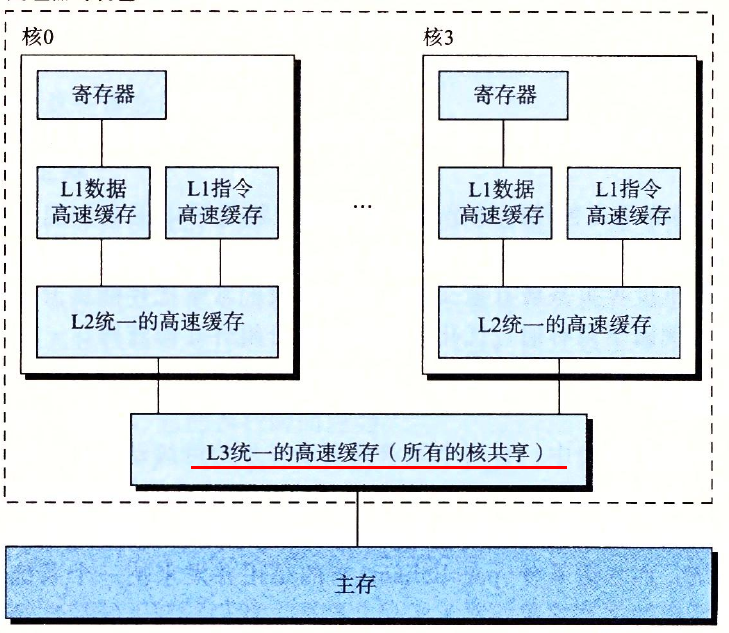
多处理器系统:
-
超线程又称同时多线程,它允许一个 CPU 执行多个控制流。 CPU 有的硬件有多个备份,比如程序计数器和寄存器文件,而其他硬件只有一份,比如浮点算术运算单元。常规 CPU 需要约 20000 个时钟周期来切换线程,超线程 CPU 可以在单个周期的基础上切换线程,比如一个线程在等待数据装在到高速缓存,CPU 就可以去执行另一个线程。
-
-
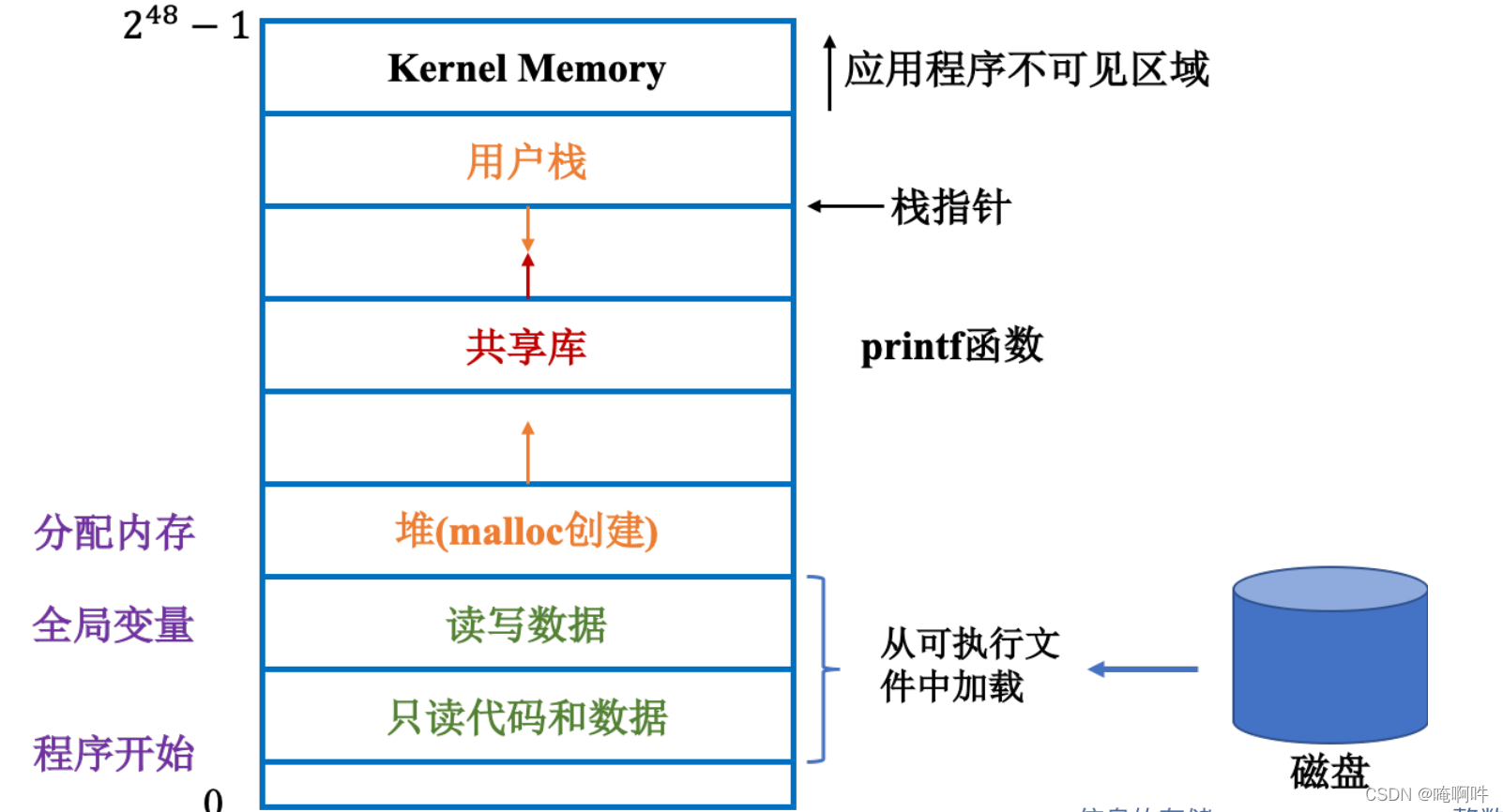
虚拟内存:对主存和磁盘的抽象表示
- 每个进程看到的内存都是一致的,称为虚拟地址空间。
- 仿佛每个进程都在独立使用主存
-
文件:字节与数据的序列。对 I/O 设备及其所存的数据的抽象表示
-
在Unix中有一个概念曰“万物皆文件”
-
文件描述符:在linux系统中打开文件就会获得文件描述符,它是个很小的正整数。每个进程在PCB(Process Control Block)中保存着一份文件描述符表,文件描述符就是这个表的索引,每个表项都有一个指向已打开文件的指针。
-
文件指针:C语言中使用文件指针做为I/O的句柄。文件指针指向进程用户区中的一个被称为FILE结构的数据结构。FILE结构包括一个缓冲区和一个文件描述符。而文件描述符是文件描述符表的一个索引,因此从某种意义上说文件指针就是句柄的句柄(在Windows系统上,文件描述符被称作文件句柄)。
-
-
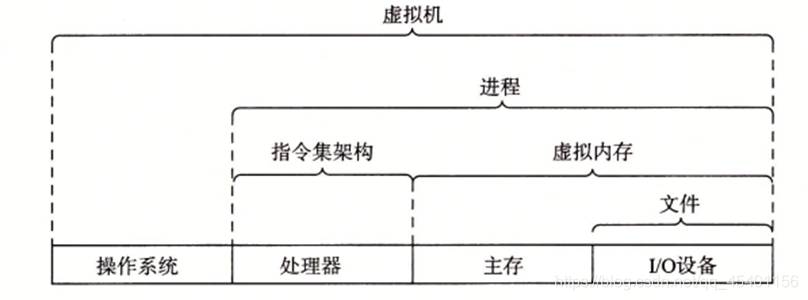
计算机的抽象:
-
-
指令集架构是对 CPU 硬件的抽象,使用这个抽象,CPU 看起来好像一次只执行机器代码程序的一条指令,实际上底层硬件并行地执行多条指令。
虚拟机是对整个计算机系统的抽象,包括操作系统、处理器和程序。
-
-
-
-
网络通信
- telnet网络连接的原理

- 网络的具体实现和应用参见计算机网络的相关课程,
- telnet网络连接的原理
-
Amdahl定律:
Amdahl 定律(也叫阿姆达尔定律)的主要思想是:当我们对系统的某个部分加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度。
公式: T n e w = ( 1 − α ) T o l d + ( α T o l d ) / k = [ ( 1 − α ) + α / k ] T o l d T_{new}=(1-\alpha)T_{old}+(\alpha T_{old})/k=[(1-\alpha)+\alpha/k]T_{old} Tnew=(1−α)Told+(αTold)/k=[(1−α)+α/k]Told即 S = T o l d T n e w = 1 / [ ( 1 − α ) + α / k ] S=\frac{T_{old}}{T_{new}}=1/[(1-\alpha)+\alpha/k] S=TnewTold=1/[(1−α)+α/k]
变量及公式解释:
- 假设原来在一个系统中执行一个程序需要时间 T o l d T_{old} Told,现在需要 T n e w T_{new} Tnew,其中某一个部分占的时间百分比为 α \alpha α,其优化倍数为 k k k,即这一部分原来需要的时间为 ( α T o l d ) (\alpha T_{old}) (αTold) ,现在需要的时间变为 ( α T o l d ) / k (\alpha T_{old})/k (αTold)/k
- 可以看出即使一个系统的主要部分(main part)性能提升了很多,整个系统的性能提升远远小于此部分的提升。 α \alpha α越大,效果会相对明显
- 极端一点,令 k → ∞ k \to \infty k→∞,则 lim k → ∞ 1 / [ ( 1 − α ) + α / k ] = 1 / ( 1 − α ) \lim_{k \to \infty}{1/[(1-\alpha)+\alpha/k]}=1/(1-\alpha) limk→∞1/[(1−α)+α/k]=1/(1−α),即k的提升远不及 α \alpha α的整体提升有价值
















 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











