









事先说明,本章内容对于真正的优化有用,但作用也有限,最大头的优化在于算法数据结构的合理、操作系统与程序系统的合理线程和资源分配,etc.
性能优化
- 性能比时间复杂度(asymptotic complexity,渐进时间复杂度/渐进复杂性)更重要
- 常数因子也很重要!
- 代码编写不同,性能会差10倍
- 要在多个层次进行优化:
- 算法、数据表示、过程、循环
- 性能优化一定要理解系统
- 程序是怎样被编辑和执行的
- 现代处理器+存储系统是怎么运作的
- 怎样测量程序性能、确定“瓶颈”
- 如何在不破坏代码模块性和通用性的前提下提高性能
编译器优化
在编译器上进行优化。在gcc中,使用-O1/-O2/-O3选项可以决定编译器优化的强度。
编译器优化的主要方法
-
方法:提供从程序到机器的有效映射
- 寄存器分配
- 代码选择与排序 (调度)
- 消除死代码
- 消除轻微的低效率问题
-
(通常) 不提高渐进效率(asymptotic efficiency)
- 由程序员来选择最佳的总体算法
- 大O(时间复杂度)常常比常数因子更重要
- 但常数因子也很重要
-
难以克服“优化障碍”
- 潜在的内存别名使用 memory aliasing
- 潜在的函数副作用
编译器优化的局限性
- 不能改变程序行为,对数据结构和算法导致的低效无解
- 通常阻止它进行优化那些只会影响到病态条件下的行为
- 对程序员来说很明显的行为,可能会因语言和编码风格而变得模糊混乱
- 数据的范围可能比变量类型对应的范围更小
- 大多数分析只在过程范围内进行
- 全程序分析过于低效
- 新版本的gcc可以在单个文件中作过程间分析
- 大多数分析是基于静态信息,因编译器难以预测运行输入
- 编译器在遇到问题时倾向保守
通常有用的优化
这些优化在编译器中是普遍使用的,但是在自行编写程序时,也可以利用以进一步优化,尤其在编译器因无法判定逻辑而不动的地方。
代码移动
-
减少计算执行的频率
-
若计算总是产生相同的效果,将其从循环等地移动出来
void set_row(double *a, double *b, long i, long n) { long j; for (j = 0; j < n; j++) a[n*i+j] = b[j]; } #可以转换为 long j; int ni = n*i; for (j = 0; j < n; j++) a[ni+j] = b[j]; -
编译器生成的代码移动 (-O1)
以上述函数为例:
set_row: testq %rcx, %rcx # Test n jle .L1 # If 0, goto done imulq %rcx, %rdx # ni = n*i leaq (%rdi,%rdx,8), %rdx # rowp = A + ni*8 movl $0, %eax # j = 0 .L3: # loop: movsd (%rsi,%rax,8), %xmm0 # t = b[j] movsd %xmm0, (%rdx,%rax,8) # M[A+ni*8 + j*8] = t addq $1, %rax # j++ cmpq %rcx, %rax # j:n jne .L3 # if !=, goto loop .L1: # done: rep;ret
-
复杂运算的简化
复杂运算简化(Reduction in Strength)
-
用更简单的方法替代昂贵的操作
- 移位、加代替乘法/除法
- 这是编译器里常见的操作
- 移位、加代替乘法/除法
-
16*x --> x << 4
-
实际效果依赖于机器
-
取决于乘法或除法指令的成本
-
Intel Nehalem CPU, 整数乘法需要3个CPU周期
-
-
识别乘积的顺序(Recognize sequence of products)
共享公共的子表达式
-
重用表达式的一部分
-
GCC使用 –O1 选项实现这个优化
/* Sum neighbors of i,j */ up = val[(i-1)*n + j ]; down = val[(i+1)*n + j ]; left = val[i*n + j-1]; right = val[i*n + j+1]; sum = up + down + left + right; //可以优化为 //复用表达 long inj = i*n + j; up = val[inj - n]; down = val[inj + n]; left = val[inj - 1]; right = val[inj + 1]; sum = up + down + left + right;
妨碍编译器优化的因素
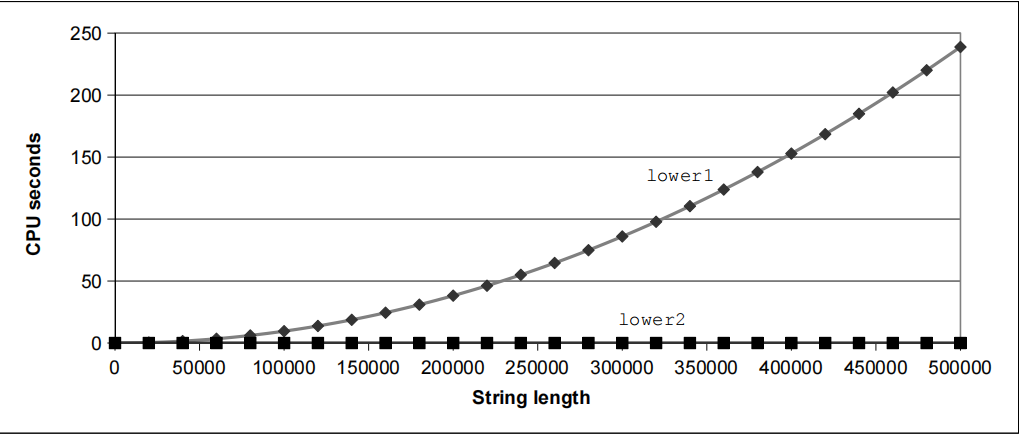
妨碍优化的因素:函数调用
下有一个将字符串全转换成小写字母之函数
void lower(char *s) {
size_t i;
for (i = 0; i < strlen(s); i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
此函数在字符串长度较长时效率较低,原因是每次迭代时都要重新调用strlen函数,考虑到函数本身的使用可能会改变变量、部分高级语言甚至有重载,因此编译器不大会动函数,即
-
编译器将函数调用视为黑盒
-
在函数附近进行弱优化
优化:
void lower(char *s) {
size_t i; size_t len = strlen(s);
for (i = 0; i < len; i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
妨碍优化的因素: 内存别名使用
别名使用
-
两个不同的内存引用指向相同的位置
-
C很容易发生
-
因为允许做地址运算
-
直接访问存储结构
-
-
养成使用局部变量的习惯
-
在循环中累积
-
告诉编译器不要检查内存别名使用的方法
-
示例:
/* Sum rows is of n X n matrix a and store in vector b */
void sum_rows1(double *a, double *b, long n) {
long i, j;
for (i = 0; i < n; i++) {
b[i] = 0;
for (j = 0; j < n; j++)
b[i] += a[i*n + j];
}
}
//优化
/* Sum rows is of n X n matrix a and store in vector b */
void sum_rows2(double *a, double *b, long n) {
long i, j;
for (i = 0; i < n; i++) {
//开一个局部变量val
double val = 0;
//将数组a的迭代值转移到val
for (j = 0; j < n; j++)
val += a[i*n + j];
//将val传到b
b[i] = val;
}
}
利用指令级并行进行优化
-
需要理解现代处理器的设计
-
硬件可以并行执行多个指令
-
性能受数据依赖的限制
-
-
简单的转换可以带来显著的性能改进
-
编译器通常无法进行这些转换
-
浮点运算缺乏结合性和可分配性
-
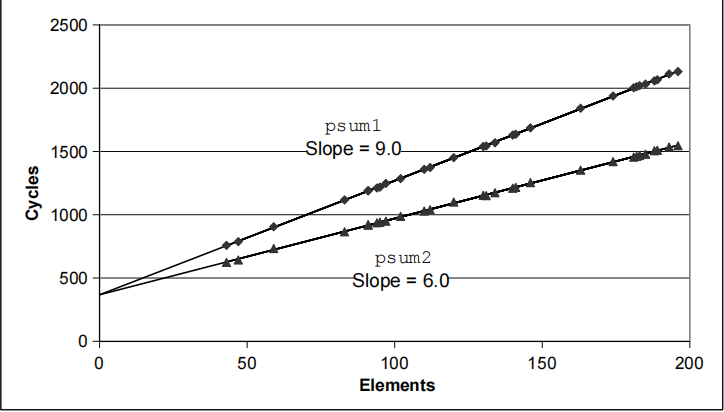
评测优化效能
每个元素的周期数(Cycles Per Element ,CPE)
-
表示向量或列表操作的程序性能的方便方式
-
Length = n
-
In our case: CPE = cycles per OP
-
T = CPE*n + 经常开销Overhead
-
CPE 是线的斜率
获得高性能的总结
-
好的编译器和标志
-
别做傻事(一些一直在做的,有问题,但不明显的事)
-
留意隐藏的算法效率低下
-
编写对编译器友好的代码
- 小心妨碍优化的隐私: 函数调用 & 内存引用
-
仔细观察最内层循环 (多数工作在那里完成)
-
-
为机器优化代码
-
利用指令级并行
-
避免不可预测的分支
-
使代码能较好地缓存 (在后续的章节介绍)
-
-

















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











