







医疗图像分割中有限标注情况下的全局和局部特征的对比学习
论文信息
- Paper:
Contrastive learning of global and local features for medical image segmentation with limited annotations - Link:
[NIPS 2020 oral presentation]
https://papers.nips.cc/paper/2020/file/949686ecef4ee20a62d16b4a2d7ccca3-Paper.pdf - Code:
https://github.com/krishnabits001/domain_specific_cl
1 背景梳理
有监督学习的成功依赖大量有标注的数据集,然而在医疗图像分析中,这种条件很难满足。自监督学习提供了一种利用无标签数据预训练网络的策略,随后利用少量有标签的数据针对下游任务进行微调。对比学习是自监督学习的一种变体,能够学习到图片级别的表示。本文提出的方法,利用了domain-specific和problem-specific的线索,拓展了在少量标注数据情况下,针对3D医疗图像分割的对比学习框架。
2 论文贡献
本文的主要贡献点有2个:
- 提出了一种新的对比策略,利用了3D医疗图像中结构相似的特征(文中称之为domian-specific cue)。
- 提出了局部版本的对比损失函数,能够从局部区域学到特征表示,有助于像素级别的分割(文中称之为problem-specific cue)。
在三个MRI数据集(ACDC、Prostate、MMWHS)上做了实验,在有限标注的数据情况下,本文提出的方法相对于其他自监督和半监督的学习方法有很大的提升。在利用简单的数据增强的前提下,本文提出的方法仅用2个有标注的MRI volumes进行训练,就能取得和利用全部数据进行全监督训练的结果8%以内的差距。
3 方法
我们首先来介绍一下全局对比损失函数
Global contrastive loss:
对一个给定的编码器
e
(
⋅
)
e(\cdot)
e(⋅),对比损失被定义成如下:
l
(
x
~
,
x
^
)
=
−
log
e
sim
(
z
~
,
z
^
)
/
τ
e
sim
(
z
~
,
z
^
)
/
τ
+
∑
x
ˉ
∈
Λ
−
e
sim
(
z
~
,
g
1
(
e
(
x
ˉ
)
)
)
/
τ
,
z
~
=
g
1
(
e
(
x
~
)
)
,
z
^
=
g
1
(
e
(
x
^
)
)
l(\tilde{x}, \hat{x})=-\log \frac{e^{\operatorname{sim}(\tilde{z}, \hat{z}) / \tau}}{e^{\operatorname{sim}(\tilde{z}, \hat{z}) / \tau}+\sum_{\bar{x} \in \Lambda^{-}} e^{\operatorname{sim}\left(\tilde{z}, g_{1}(e(\bar{x}))\right) / \tau}}, \tilde{z}=g_{1}(e(\tilde{x})), \hat{z}=g_{1}(e(\hat{x}))
l(x~,x^)=−logesim(z~,z^)/τ+∑xˉ∈Λ−esim(z~,g1(e(xˉ)))/τesim(z~,z^)/τ,z~=g1(e(x~)),z^=g1(e(x^))
在上式中,
x
~
\tilde{x}
x~和
x
^
\hat{x}
x^是对同一张图片
x
x
x的进行不同变换得到的,这两张图片是相似的,因此它们的特征表示也被鼓励是相似的。作为对比,集合
Λ
−
\Lambda^{-}
Λ−包含的是和
x
x
x不相似的图片,这个集合可以包含除
x
x
x以外的所有图片。我们最小化损失
l
(
x
~
,
x
^
)
l(\tilde{x}, \hat{x})
l(x~,x^)从而增加
x
~
\tilde{x}
x~和
x
^
\hat{x}
x^的特征表示间的相似度,同时尽可能增大
x
x
x和与它不相似的图片的不相似度。上面表达式中,图片的特征表示
z
z
z是先经过编码器
e
(
⋅
)
e(\cdot)
e(⋅),再经过一个比较浅的全连接网络
g
1
(
⋅
)
g_1(\cdot)
g1(⋅)得到的,
g
1
(
⋅
)
g_1(\cdot)
g1(⋅)被称之为投影头[1],它的存在给了
e
(
⋅
)
e(\cdot)
e(⋅)一定的灵活性,能够保留与变换相关的信息[1, 2]。隐空间的相似性是由余弦相似度来定义的,也就是
sim
(
a
,
b
)
=
a
T
b
/
∥
a
∥
∥
b
∥
\operatorname{sim}(a, b)=a^{T} b /\|a\|\|b\|
sim(a,b)=aTb/∥a∥∥b∥,
τ
\tau
τ是一个尺度参数。全局对比损失定义如下:
L
g
=
1
∣
Λ
+
∣
∑
∀
(
x
~
,
x
^
)
∈
Λ
+
[
l
(
x
~
,
x
^
)
+
l
(
x
^
,
x
~
)
]
L_{g}=\frac{1}{\left|\Lambda^{+}\right|} \sum_{\forall(\tilde{x}, \hat{x}) \in \Lambda^{+}}[l(\tilde{x}, \hat{x})+l(\hat{x}, \tilde{x})]
Lg=∣Λ+∣1∀(x~,x^)∈Λ+∑[l(x~,x^)+l(x^,x~)]
全局对比损失是建立在对比损失的基础上的,这里不仅仅是变量位置的交换,注意对比损失表达式分母求和项中
x
x
x的形式。在该表达式中
Λ
+
\Lambda^{+}
Λ+表示图片的所有相似对的集合。
文章提到,利用domain-specific的知识有助于从立体医疗图像中提取全局的线索,而利用problem-specific的知识能够为分割提供局部的线索,在下面的讨论中,文章以2D的编码器解码器结构为例,对他们的方法进行了说明,他们用Encoder提取全局的表示,用Decoder层提取互补性的局部表示。
Leveraging structure within medical volumes for global contrastive loss
先放上整体的模型结构图
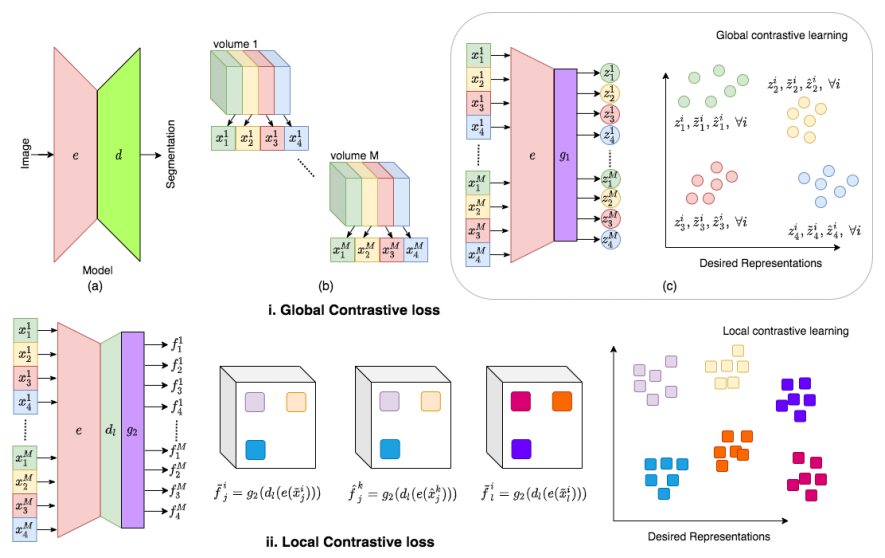
文中提到,对于医疗图像而言,不同病人的相同器官结构区域的图像,通常都包含着相似的内容。这是本文方法的前提,同时本文所使用的数据集的原始数据也都已经被大致配准过了。
现在结合着上面给出的图进行讲解,假设我们有M个volumes,每个都包含Q张图片,我们把这Q张图片划分为S个区,每个区都包含着连续的slices,我们用 x s i x^i_s xsi表示来自第 i i i个volume的第s个分区的某一张图片。我们对所有的volume都采用了相同的划分方式,因此不同volume的相同分区被认为捕获了相似的解剖结构。举个例子, x s i x^i_s xsi和 x s j x^j_s xsj被认为包含了相似的区域,因此它们的特征表达应该尽可能相近,当然,原图经过变换后的特征表达,也应该是相似的。
Local contrastive loss
全局对比损失鼓励从相似图像提取出的图像级别表示尽可能相似,而从不相似图像提取出的则不相似,这个策略对于下游任务非常有用,比如分类任务。对于分割任务而言,我们需要像素级别的预测,好的局部特征表示可能对区分相邻区域有帮助。
文中提出了一种自监督的策略,来鼓励decoder提取局部表示,从而与encoder提取出的全局表示形成互补。具体而言,我们使用局部对比损失训练decoder部分的前l层,特征表示 d l ( x ) ∈ R W 1 × W 2 × C d_{l}(x) \in \mathbb{R}^{W_{1} \times W_{2} \times C} dl(x)∈RW1×W2×C中不同的局部区域应该是不相似的,相同的局部区域特征应该是相似的。
对一个相似块的局部对比损失的定义如下:
l
(
x
~
,
x
^
,
u
,
v
)
=
−
log
e
sim
(
f
~
(
u
,
v
)
,
f
^
(
u
,
v
)
)
/
τ
e
sim
(
f
~
(
u
,
v
)
,
f
^
(
u
,
v
)
)
/
τ
+
∑
(
u
′
,
v
′
)
∈
Ω
−
e
sim
(
f
~
(
u
,
v
)
,
f
^
(
u
′
,
v
′
)
)
/
τ
l(\tilde{x}, \hat{x}, u, v)=-\log \frac{e^{\operatorname{sim}(\tilde{f}(u, v), \hat{f}(u, v)) / \tau}}{e^{\operatorname{sim}(\tilde{f}(u, v), \hat{f}(u, v)) / \tau}+\sum_{\left(u^{\prime}, v^{\prime}\right) \in \Omega^{-}} e^{\operatorname{sim}\left(\tilde{f}(u, v), \hat{f}\left(u^{\prime}, v^{\prime}\right)\right) / \tau}}
l(x~,x^,u,v)=−logesim(f~(u,v),f^(u,v))/τ+∑(u′,v′)∈Ω−esim(f~(u,v),f^(u′,v′))/τesim(f~(u,v),f^(u,v))/τ
我们将每个特征图划分为A个局部区域,维度是
K
×
K
×
C
K\times K\times C
K×K×C,其中
K
<
m
i
n
(
W
1
,
W
2
)
K \lt min(W_1,W_2)
K<min(W1,W2)。
Ω
+
\Omega^+
Ω+和
Ω
−
\Omega^-
Ω−和全局对比损失中的
Λ
\Lambda
Λ含义相似,这里用不同符号只是为了区分。
(
u
,
v
)
(u,v)
(u,v)表示局部区域的索引。
局部对比损失的定义如下:
L
l
=
1
∣
X
∣
∑
x
∈
X
1
2
A
∑
(
u
,
v
)
∈
Ω
+
[
l
(
x
~
,
x
^
,
u
,
v
)
+
l
(
x
^
,
x
~
,
u
,
v
)
]
,
x
~
=
t
~
(
x
)
,
x
^
=
t
^
(
x
)
,
t
~
,
t
^
∼
T
L_{l}=\frac{1}{|\mathbf{X}|} \sum_{x \in \mathbf{X}} \frac{1}{2 A} \sum_{(u, v) \in \Omega^{+}}[l(\tilde{x}, \hat{x}, u, v)+l(\hat{x}, \tilde{x}, u, v)], \tilde{x}=\tilde{t}(x), \hat{x}=\hat{t}(x), \tilde{t}, \hat{t} \sim \mathcal{T}
Ll=∣X∣1x∈X∑2A1(u,v)∈Ω+∑[l(x~,x^,u,v)+l(x^,x~,u,v)],x~=t~(x),x^=t^(x),t~,t^∼T
上式中
T
\mathcal{T}
T表示对图片变换方法的集合。
Pre-training using global and local contrastive losses
首先用一个浅层的dense网络 g 1 g_1 g1来预训练编码器 e e e,使用全局对比损失,接下来丢掉 g 1 g_1 g1并且冻结 e e e的权重,接上 d e c o d e r decoder decoder的前 l l l层,和浅层全连接网络 g 2 g_2 g2来训练 d l d_l dl,这里使用局部对比损失,接下来丢弃 g 2 g_2 g2。在经过这两个阶段的训练后, e e e和 d l d_l dl被期望能提取全局和局部的有用信息。最后我们接上 d e c o d e r decoder decoder剩下的所有层,用小量的有标注数据来 f i n e t u n e finetune finetune整个网络。
文中有提到可以将这些损失函数加在一起整体训练网络,分阶段训练的好处是可以避免针对每个损失权重的超参数选择。
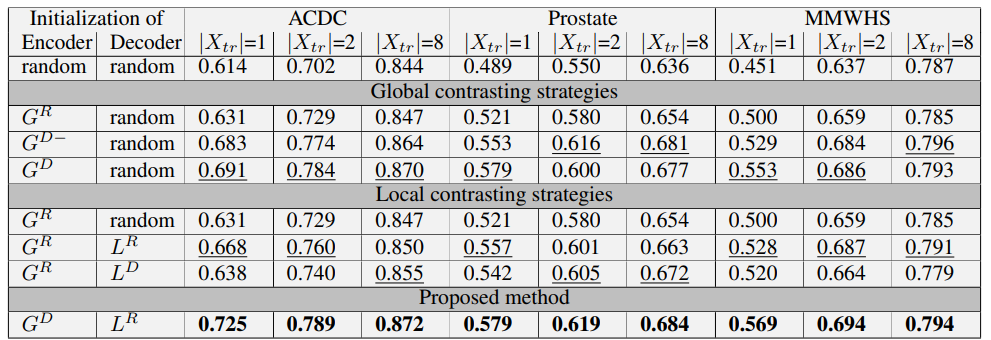
训练提取全局特征的 E n c o d e r Encoder Encoder的采样策略(针对原始输入图像)
- G R G^R GR,随机采样,从所有volumes中随机采样N张图片,同时对这些图片进行一对随机变换 t ~ \tilde{t} t~和 t ^ \hat{t} t^,这样我们就得到了2N张图片, Λ + \Lambda^+ Λ+由 ( x ~ s i , x ^ s i ) (\tilde{x}^i_s, \hat{x}^i_s) (x~si,x^si)对组成, Λ − \Lambda^- Λ−由剩下的 2 N − 2 2N-2 2N−2张图片组成
- P r o p o s e d Proposed Proposed,首先从所有的 M M M个 v o l u m e s volumes volumes中随机采样 m m m个,然后针对每个 v o l u m e volume volume,我们知道每个体都被划分为了 S S S个分区,我们从每个分区中随机采样1张图片,这样从每个 v o l u m e volume volume都能得到 S S S张图片,接下来对每张图片进行随机变换,得到变换对 ( x ~ s i , x ^ s i ) (\tilde{x}^i_s,\hat{x}^i_s) (x~si,x^si)
- G D − G^{D-} GD−,这种采样方式在 G R G^R GR的基础上做了一些限制,对比图片不能来自和原图相同的分区,得从其它分区里面挑,正如前面提到过的,每个 v o l u m e volume volume的相同分区,我们都假设它包含了相似的信息,所以不能作为对比图像。这种采样方式可以表示为 Λ − = { x k l , x ~ k l , x ^ k l ∣ ∀ k ≠ s , ∀ l } \Lambda^{-}=\left\{x_{k}^{l}, \tilde{x}_{k}^{l}, \hat{x}_{k}^{l} \mid \forall k \neq s, \forall l\right\} Λ−={xkl,x~kl,x^kl∣∀k=s,∀l}, Λ + \Lambda^+ Λ+则可以包含 ( x s i , x ~ s i ) , ( x s i , x ^ s i ) \left(x_{s}^{i}, \tilde{x}_{s}^{i}\right),\left(x_{s}^{i}, \hat{x}_{s}^{i}\right) (xsi,x~si),(xsi,x^si) 和 ( x ~ s i , x ^ s i ) \left(\tilde{x}_{s}^{i}, \hat{x}_{s}^{i}\right) (x~si,x^si)
- G D G^D GD,建立在 G R G^R GR的基础上,相似对可以是来自不同 v o l u m e volume volume的相同分区,也即 ( x ~ s i , x ^ s j ) \left(\tilde{x}_{s}^{i}, \hat{x}_{s}^{j}\right) (x~si,x^sj), Λ − \Lambda^- Λ−则保持和 G D − G^{D-} GD−中一样
训练提取局部特征的 D e c o d e r Decoder Decoder的采样策略(针对特征块)
- L R L^R LR,随机采样, Ω + \Omega^+ Ω+包含 ( f ~ s i ( u , v ) , f ^ s i ( u , v ) ) \left(\tilde{f}_{s}^{i}(u, v), \hat{f}_{s}^{i}(u, v)\right) (f~si(u,v),f^si(u,v)),也就是来自第 i i i个 v o l u m e volume volume的第 S S S个分区的图片在 d l d_l dl输出的特征图中的第 ( u , v ) (u,v) (u,v)块。 Ω − \Omega^- Ω−则包含相同特征图中,除 ( u , v ) (u,v) (u,v)块以外的所有其它块
- L D L^D LD,在 L R L^R LR的基础上,相似块可以来自不同 v o l u m e volume volume的相同分区,也即 ( f s i ( u , v ) , f s j ( u , v ) ) \left(f_{s}^{i}(u, v), f_{s}^{j}(u, v)\right) (fsi(u,v),fsj(u,v))
4 实验结果
在不同采样策略下,实验结果如下:
在不同方法,不同训练样本数的情况下,实验结果如下:
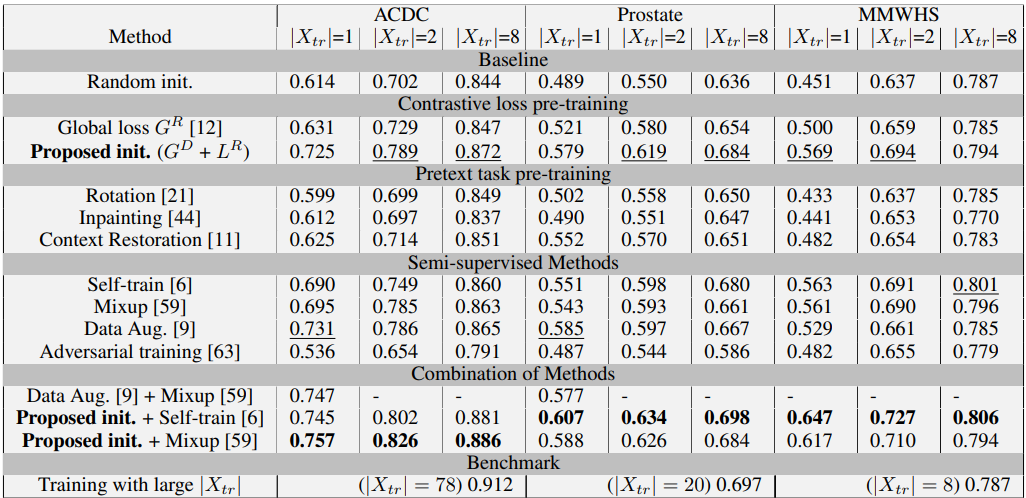
结果还是比较明显的,利用如此少量的训练样本,就能取得和用全部数据进行全监督的训练能够相比较(8%以内)的结果。
5 总结
本文针对医疗影像分割中少量样本标注的问题提供了一种解决方案,提出的预训练方案建立在对比学习的基础上。文中主要提出了对比损失的局部版本,以及几种对比组的采样策略,并在三个数据集上取得了不错的结果。对比学习拉近相似块间的距离,增大不相似块间的距离。同时文中提到的利用 E n c o d e r Encoder Encoder提取全局的特征,而利用 D e c o d e r Decoder Decoder提取局部特征是通过采样方式和损失函数来约束实现的。文中提到的对比学习方法,以及按块来设计局部损失都有值得学习的地方。
6 参考文献
[1] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709 (2020)
[2] Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297 (2020)















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









