







TensorFlow入门
参考资料:
- TensorFlow中文社区教程
- TENSORFLOW从入门到精通之——TENSORFLOW基本操作
- TensorFlow升级到1.0版本的问题
- Tensorflow save&restore遇到问题及解决应对 NotFoundError: Key Variable_10 not found in checkpoint
- TensorFlow的变量管理:变量作用域机制
- 深入浅出的TensorFlow可视化工具TensorBoard用法教程
- Tensorflow数据读取机制及tfrecords高效读取数据
- tensorflow中的队列和线程
- TensorFlow 教程1:线程和队列
- CPU和GPU之间的区别是什么
说明:以下代码示例基于Python3.7和TensorFlow1.13.1
简介
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
什么是数据流图(Data Flow Graph)?

数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点”一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
为什么Tensorflow要使用图模型?图模型有什么优势呢?
首先,图模型的最大好处是节约系统开销,提高资源的利用率,可以更加高效的进行运算。因为我们在图的执行阶段,只需要运行我们需要的op,这样就大大的提高了资源的利用率;其次,这种结构有利于我们提取中间某些节点的结果,方便以后利用中间的节点去进行其它运算;还有就是这种结构对分布式运算更加友好,运算的过程可以分配给多个CPU或是GPU同时进行,提高运算效率;最后,因为图模型把运算分解成了很多个子环节,所以这种结构也让我们的求导变得更加方便。
在Anaconda中查找tensorflow,勾选安装即可安装TensorFlow成功。
基本用法
使用 TensorFlow, 你必须明白 TensorFlow:
- 使用图 (graph) 来表示计算任务.
- 在被称之为
会话 (Session)的上下文 (context) 中执行图. - 使用 tensor 表示数据.
- 通过
变量 (Variable)维护状态. - 使用 feed 和 fetch 可以为任意的操作(arbitrary operation)赋值或者从其中获取数据.
综述
TensorFlow 是一个编程系统, 使用图来表示计算任务. 图中的节点被称之为 op (operation 的缩写). 一个 op 获得 0 个或多个 Tensor, 执行计算, 产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组. 例如,你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels].
一个 TensorFlow 图_描述_了计算的过程. 为了进行计算, 图必须在 会话 里被启动.
会话 将图的 op 分发到诸如 CPU 或 GPU 之类的 设备 上, 同时提供执行 op 的方法.
这些方法执行后, 将产生的 tensor 返回. 在 Python 语言中, 返回的 tensor 是
numpy ndarray 对象.
CPU和GPU之间的区别是什么?
CPU和GPU是嵌入式和电子系统的基本设备,但它们都可以用于不同的目的。CPU是用于根据操作(例如算术,逻辑,控制和输入 - 输出)执行程序给出的指令的微处理器。相反,GPU最初被设计为在计算机游戏中渲染图像。CPU强调低延迟,而在GPU中,重要性是高吞吐量。
| 比较的项目 | CPU | GPU |
|---|---|---|
| 代表 | 中央处理器 | 图形处理单元 |
| 专注于 | 低延迟 | 高吞吐量 |
| 擅长 | 处理串行指令 | 处理并行指令 |
| 包含 | 更少的强大核心 | 很多较弱的核心 |
| 特征 | 无序和推测执行的控制逻辑。 | 架构可以容忍内存延迟 |
| 速度 | 有效 | 可以高于CPU的 |
| 内存消耗 | 高 | 低 |
CPU的定义
**CPU(中央处理器)**是一种主要充当每个嵌入式系统的大脑的设备。它由用于临时存储数据和执行计算的ALU(算术逻辑单元)和执行指令排序和分支的CU(控制单元)组成。它还与计算机的其他单元(例如存储器,输入和输出)交互,用于执行来自存储器的指令,这是接口也是CPU的关键部分的原因。I / O接口有时包含在控制单元中。
它提供地址、数据和控制信号,同时接收在系统总线的帮助下处理的指令、数据、状态信号和中断。系统总线是一组各种总线,例如地址、控制和数据总线。与GPU不同,CPU为快速缓存分配更多硬件单元,而计算则分配的少。
GPU的定义
**GPU(图形处理单元)**是专门用于计算图形显示设计的处理器。它通常与CPU结合用于与CPU共享RAM,这对于大多数计算任务都是有益的。它是高端图形密集处理所必需的。独立GPU单元包含自己的RAM,称为VRAM,用于视频RAM。先进的GPU系统与多核CPU协同工作。起初,图形单元是由英特尔和IBM在20世纪80年代引入的。这些卡具有简单的功能,如区域填充,简单图像的更改,形状绘制等。
现代图形能够执行研究和分析任务,由于其极端的并行处理,通常超过CPU。在GPU中,几个处理单元被剥离在一起,其中不存在高速缓存一致性。
计算图
TensorFlow 程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op 的执行步骤被描述成一个图. 在执行阶段, 使用会话执行图中的 op.
例如, 通常在构建阶段创建一个图来表示和训练神经网络, 然后在执行阶段反复执行图中的训练 op.
TensorFlow 支持 C, C++, Python 编程语言. 目前, TensorFlow 的 Python库更加易用, 它提供了大量的辅助函数来简化构建图的工作, 这些函数尚未被 C 和 C++ 库支持.
三种语言的会话库 (session libraries) 是一致的.
构建图
构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant). 源 op 的输出被传递给其它 op 做运算.
Python 库中, op 构造器的返回值代表被构造出的 op 的输出, 这些返回值可以传递给其它 op 构造器作为输入.
TensorFlow Python 库有一个_默认图 (default graph)_, op 构造器可以为其增加节点. 这个默认图对许多程序来说已经足够用了.
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点
# 加到默认图中.
#
# 构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
默认图现在有三个节点, 两个 constant() op, 和一个matmul() op. 为了真正进行矩阵相乘运算, 并得到矩阵乘法的结果, 你必须在会话里启动这个图.
在一个会话中启动图
构造阶段完成后, 才能启动图. 启动图的第一步是创建一个 Session 对象, 如果无任何创建参数, 会话构造器将启动默认图.
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数.
# 上面提到, 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回
# 矩阵乘法 op 的输出.
#
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的.
#
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.
#
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print(result)
# ==> [[ 12.]]
# 任务完成, 关闭会话.
sess.close()
Session 对象在使用完后需要关闭以释放资源. 除了显式调用 close 外, 也可以使用 “with” 代码块来自动完成关闭动作.
with tf.Session() as sess:
result = sess.run([product])
print result
在实现上, TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU或 GPU). 一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测. 如果检测到 GPU, TensorFlow 会尽可能地利用找到的第一个 GPU 来执行操作.如果你的系统里有多个 GPU, 那么 ID 最小的 GPU 会默认使用。
指定设备
如果你想要手动指派设备, 你可以用 with tf.device 创建一个设备环境, 这个环境下的 operation 都统一运行在环境指定的设备上.
# 新建一个graph.
with tf.device('/cpu:0'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# 新建session with log_device_placement并设置为True.
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))
# 运行这个op.
print sess.run(c)
如果你指定的设备不存在, 你会收到 InvalidArgumentError 错误提示。为了避免出现你指定的设备不存在这种情况, 你可以在创建的 session 里把参数 allow_soft_placement 设置为 True, 这样 tensorFlow 会自动选择一个存在并且支持的设备来运行 operation.
Tensor
TensorFlow 程序使用 tensor 数据结构来代表所有的数据, 计算图中, 操作间传递的数据都是 tensor.
你可以把 TensorFlow tensor 看作是一个 n 维的数组或列表. 其中零维张量表示的是一个标量,也就是一个数;一维张量表示的是一个向量,也可以看作是一个一维数组;二维张量表示的是一个矩阵;同理,N维张量也就是N维矩阵。
# 导入tensorflow模块
import tensorflow as tf
a = tf.constant([[2.0, 3.0]], name = "a")
b = tf.constant([[1.0], [4.0]], name = "b")
result = tf.matmul(a, b, name = "mul")
print(result)
# 输出
# Tensor("mul_3:0", shape=(1, 1), dtype=float32)
上述程序的输出结果表明:构建图的运算过程输出的结果是一个Tensor,且其主要由三个属性构成:Name、Shape和Type。Name代表的是张量的名字,也是张量的唯一标识符,我们可以在每个op上添加name属性来对节点进行命名,Name的值表示的是该张量来自于第几个输出结果(编号从0开始),上例中的“mul_3:0”说明是第一个结果的输出。Shape代表的是张量的维度,上例中shape的输出结果(1,1)说明该张量result是一个二维数组,且每个维度数组的长度是1。最后一个属性表示的是张量的类型,每个张量都会有唯一的类型,常见的张量类型如下图所示。

我们需要注意的是要保证参与运算的张量类型相一致,否则会出现类型不匹配的错误。如下面程序所示,当参与运算的张量类型不同时,Tensorflow会报类型不匹配的错误:
import tensorflow as tf
m1 = tf.constant([5, 1])
m2 = tf.constant([2.0, 4.0])
result = tf.add(m1, m2)
TypeError: Input 'y' of 'Add' Op has type float32 that does not match type int32 of argument 'x'.
正如程序的报错所示:m1是int32的数据类型,而m2是float32的数据类型,两者的数据类型不匹配,所以发生了错误。所以我们在实际编程时,一定注意参与运算的张量数据类型要相同。
变量
变量Variables维护图执行过程中的状态信息.
下面的例子演示了如何使用变量实现一个简单的计数器.
# 创建一个变量, 初始化为标量 0.
state = tf.Variable(0, name="counter")
# 创建一个 op, 其作用是使 state 增加 1
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# 启动图后, 变量必须先经过`初始化` (init) op 初始化,
# 首先必须增加一个`初始化` op 到图中.
init_op = tf.global_variables_initializer()
# 启动图, 运行 op
with tf.Session() as sess:
# 运行 'init' op
sess.run(init_op)
# 打印 'state' 的初始值
print(sess.run(state))
# 运行 op, 更新 'state', 并打印 'state'
for _ in range(3):
sess.run(update)
print(sess.run(state))
# 输出:
# 0
# 1
# 2
# 3
代码中 assign() 操作是图所描绘的表达式的一部分, 正如 add() 操作一样. 所以在调用 run() 执行表达式之前, 它并不会真正执行赋值操作.
通常会将一个统计模型中的参数表示为一组变量. 例如, 你可以将一个神经网络的权重作为某个变量存储在一个 tensor 中. 在训练过程中, 通过重复运行训练图, 更新这个 tensor.
变量的初始化
当我们完成了变量的创建,接下来,我们要对变量进行初始化。变量在使用前一定要进行初始化,且变量的初始化必须在模型的其它操作运行之前完成。通常,变量的初始化有三种方式,如下所示:
# 创建两个变量, 初始化为标量 0.
W = tf.Variable(0, name="W")
b = tf.Variable(0, name="b")
# 初始化全部变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 初始化变量的子集
init_subset = tf.variables_initializer([W, b], name = "init_subset")
with tf.Session() as sess:
sess.run(init_subset)
# 初始化单个变量
init_var = tf.Variable(tf.zeros([2,5]))
with tf.Session() as sess:
sess.run(init_var.initializer)
上述程序说明了初始化变量的三种方式:初始化全部变量、初始化变量的子集以及初始化单个变量。首先,global_variables_initializer()方法是不管全局有多少个变量,全部进行初始化,是最简单也是最常用的一种方式;variables_initializer()是初始化变量的子集,相比于全部初始化化的方式更加节约内存;Variable()是初始化单个变量,函数的参数便是要初始化的变量内容。通过上述的三种方式,我们便可以实现变量的初始化,放心的使用变量了。
但有时一个变量的初始化依赖于其他变量的初始化,为了确保初始化顺序不会错,可以使用initialized_value()来获取初始化变量的值。你应该使用tf.Variable.initialized_value()而不是变量本身来初始化另一个变量,其值取决于此变量的值。
# Initialize 'v' with a random tensor.
v = tf.Variable(tf.truncated_normal([10, 40]))
# Use `initialized_value` to guarantee that `v` has been
# initialized before its value is used to initialize `w`.
# The random values are picked only once.
w = tf.Variable(v.initialized_value() * 2.0)
变量的保存和恢复
我们经常在训练模型后,希望保存训练的结果,以便下次再使用或是方便日后查看,这时就用到了Tensorflow变量的保存。变量的保存是通过tf.train.Saver()方法创建一个Saver管理器,来保存计算图模型中的所有变量。具体代码如下:
var1 = tf.Variable([1,3], name="v1")
var2 = tf.Variable([2,4], name="v2")
# 初始化全部变量
init = tf.global_variables_initializer()
# 调用Saver()存储器方法
saver = tf.train.Saver()
# 启动图
with tf.Session() as sess:
sess.run(init)
# 设置存储路径
save_path = saver.save(sess, "test/save.ckpt")
我们要注意,我们的存储文件save.ckpt是一个二进制文件,Saver存储器提供了向该二进制文件保存变量和恢复变量的方法。保存变量的方法就是程序中的save()方法,保存的内容是从变量名到tensor值的映射关系。完成该存储操作后,会在对应目录下生成如下图所示的文件:

Saver提供了一个内置的计数器自动为checkpoint文件编号。这就支持训练模型在任意步骤多次保存。此外,还可以通过global_step参数自行对保存文件进行编号,例如:global_step=2,则保存变量的文件夹为model.ckpt-2。
那如何才能恢复变量呢?首先,我们要知道一定要用和保存变量相同的Saver对象来恢复变量。其次,不需要事先对变量进行初始化。具体代码如下所示:
# 保存后模型恢复出来用于测试报错:NotFoundError: Key Variable_1 not found in checkpoint
# 原因:如果模型训练完保存后直接加载,相当于变量在前后定义了两次,
# 第一次创建的变量name="v1",加载时创建的变量虽然name="v1",
# 但是实际上name会变成"v1_1"(v1_n-1),
# 我们在保存的checkpoint中搜索的就是v1_n-1,因为搜索不到所以会报错,提示
# Key v1_1 not found in checkpoint
# 解决方法:
# (1)保存模型后,restart kernel后,再加载测试,就不会出错。
# (2)在加载过程中,定义 name 相同的变量前面加 tf.reset_default_graph()
# 清除默认图的堆栈,并设置全局图为默认图;
# 清除默认图的堆栈
tf.reset_default_graph()
var1 = tf.Variable([0,0], name="v1")
var2 = tf.Variable([0,0], name="v2")
# 调用Saver()存储器方法
saver = tf.train.Saver()
# 读取checkpoint文件
module_file = tf.train.latest_checkpoint("test/")
print(module_file)
# 启动图
with tf.Session() as sess:
saver.restore(sess, module_file)
# 打印变量的值
# evel()方法用于在session中计算并返回变量的值, 不传参数的话,则使用的是默认的session
print(var1.eval())
print(var2.eval())
# 输出
# test/save.ckpt
# INFO:tensorflow:Restoring parameters from test/save.ckpt
# [1 3]
# [2 4]
本程序示例中,我们要注意:变量的获取是通过restore()方法,该方法有两个参数,分别是session和获取变量文件的位置。我们还可以通过latest_checkpoint()方法,获取到该目录下最近一次保存的模型。
变量作用域
在深度学习中,你可能需要用到大量的变量集,而且这些变量集可能在多处都要用到。例如,训练模型时,训练参数如权重(weights)、偏置(biases)等已经定下来,要拿到验证集去验证,我们自然希望这些参数是同一组。以往写简单的程序,可能使用全局限量就可以了,但在深度学习中,这显然是不行的,一方面不便管理,另外这样一来代码的封装性受到极大影响。因此,TensorFlow提供了一种变量管理方法:变量作用域机制,以此解决上面出现的问题。
变量作用域机制在TensorFlow中主要由两部分组成:
tf.get_variable(<name>, <shape>, <initializer>):
通过所给的名字创建或是返回一个变量.tf.variable_scope(<scope_name>): 通过tf.get_variable()为变量名指定命名空间.
方法 tf.get_variable() 用来获取或创建一个变量,而不是直接调用tf.Variable.它采用的不是像tf.Variable这样直接获取值来初始化的方法.它的特殊之处在于,他还会搜索是否有同名的变量。一个初始化就是一个方法,创建其形状并且为这个形状提供一个张量.这里有一些在TensorFlow中使用的初始化变量:
tf.constant_initializer(value)初始化一切所提供的值,tf.random_uniform_initializer(a, b)从a到b均匀初始化,tf.random_normal_initializer(mean, stddev)用所给平均值和标准差初始化均匀分布.
创建变量作用域用法如下:
with tf.variable_scope("foo"):
with tf.variable_scope("bar"):
v = tf.get_variable("v", [1])
assert v.name == "foo/bar/v:0"
方法tf.variable_scope(scope_name),它会管理在名为scope_name的域(scope)下传递给tf.get_variable的所有变量名(组成了一个变量空间),根据规则确定这些变量是否进行复用。这个方法最重要的参数是reuse,有None,tf.AUTO_REUSE与True三个选项。具体用法如下:
-
reuse的默认选项是None,此时会继承父scope的reuse标志。
-
自动复用(设置reuse为tf.AUTO_REUSE),如果变量存在则复用,不存在则创建。这是最安全的用法,在使用新推出的EagerMode时reuse将被强制为tf.AUTO_REUSE选项。用法如下:
def foo(): with tf.variable_scope("foo", reuse=tf.AUTO_REUSE): v = tf.get_variable("v", [1]) return v v1 = foo() # Creates v. v2 = foo() # Gets the same, existing v. assert v1 == v2 -
复用(设置reuse=True):
with tf.variable_scope("foo"): v = tf.get_variable("v", [1]) with tf.variable_scope("foo", reuse=True): v1 = tf.get_variable("v", [1]) assert v1 == v -
捕获某一域并设置复用(scope.reuse_variables()):
with tf.variable_scope("foo") as scope: v = tf.get_variable("v", [1]) scope.reuse_variables() v1 = tf.get_variable("v", [1]) assert v1 == v1)非复用的scope下再次定义已存在的变量;或2)定义了复用但无法找到已定义的变量,TensorFlow都会抛出错误,具体如下:
with tf.variable_scope("foo"): v = tf.get_variable("v", [1]) v1 = tf.get_variable("v", [1]) # Raises ValueError("... v already exists ..."). with tf.variable_scope("foo", reuse=True): v = tf.get_variable("v", [1]) # Raises ValueError("... v does not exists ...").
Fetch
为了取回操作的输出内容, 可以在使用 Session 对象的 run() 调用 执行图时, 传入一些 tensor, 这些 tensor 会帮助你取回结果. 在之前的例子里, 我们只取回了单个节点 state, 但是你也可以取回多个tensor:
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
intermed = tf.add(input2, input3)
mul = tf.multiply(input1, intermed)
with tf.Session() as sess:
result = sess.run([mul, intermed])
print(result)
# 输出:
# [21.0, 7.0]
需要获取的多个 tensor 值,在 op 的一次运行中一起获得(而不是逐个去获取 tensor)。
Feed
上述示例在计算图中引入了 tensor, 以常量或变量的形式存储. TensorFlow 还提供了 feed 机制, 该机制可以临时替代图中的任意操作中的 tensor, 可以对图中任何操作提交补丁, 直接插入一个 tensor.
feed 使用一个 tensor 值临时替换一个操作的输出结果. 你可以提供 feed 数据作为 run() 调用的参数.
feed 只在调用它的方法内有效, 方法结束, feed 就会消失. 最常见的用例是将某些特殊的操作指定为 “feed” 操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符.
placeholder是一个数据初始化的容器,它与变量最大的不同在于placeholder定义的是一个模板,这样我们就可以session运行阶段,利用feed_dict的字典结构给placeholder填充具体的内容,而无需每次都提前定义好变量的值,大大提高了代码的利用率。
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run([output], feed_dict={input1:[7.], input2:[2.]}))
# 输出:
# [array([ 14.], dtype=float32)]
如果没有正确提供 feed, placeholder() 操作将会产生错误.
TensorBoard
1. Tensorboard简介
对大部分人而言,深度神经网络就像一个黑盒子,其内部的组织、结构、以及其训练过程很难理清楚,这给深度神经网络原理的理解和工程化带来了很大的挑战。为了解决这个问题,tensorboard应运而生。Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件,因而tensorboard和tensorflow程序在不同的进程中运行。
那如何启动tensorboard呢?下面代码定义了一个简单的用于实现向量加法的计算图。
import tensorflow as tf
# 定义一个计算图,实现两个向量的减法操作
# 定义两个输入,a为常量,b为变量
a=tf.constant([10.0, 20.0, 40.0], name='a')
b=tf.Variable(tf.random_uniform([3]), name='b')
output=tf.add_n([a,b], name='add')
# 生成一个具有写权限的日志文件操作对象,将当前命名空间的计算图写进日志中
writer=tf.summary.FileWriter('/path/to/logs', tf.get_default_graph())
writer.close()
在上面程序的8、9行中,创建一个writer,将tensorboard summary写入文件夹/path/to/logs,然后运行上面的程序,在程序定义的日志文件夹/path/to/logs目录下,生成了一个新的日志文件events.out.tfevents.1524711020.bdi-172,如下图1所示。当然,这里的日志文件夹也可以由读者自行指定,但是要确保文件夹存在。如果使用的tensorboard版本比较低,那么直接运行上面的代码可能会报错,此时,可以尝试将第8行代码改为file_writer=tf.train.SummaryWriter(‘/path/to/logs’, sess.graph)
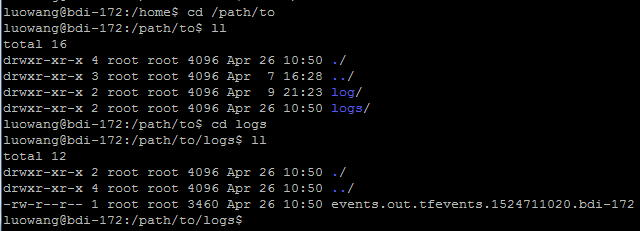
图1 日志目录下生成的events文件路径
接着运行如图2所示命令tensorboard --logdir /path/to/logs来启动服务。

图2 linux下启动tensorboard服务的命令
注意,当系统报错,找不到tensorboard命令时,则需要使用绝对路径调用tensorboard,例如下面的命令形式:
python tensorflow/tensorboard/tensorboard.py --logdir=path/to/log-directory
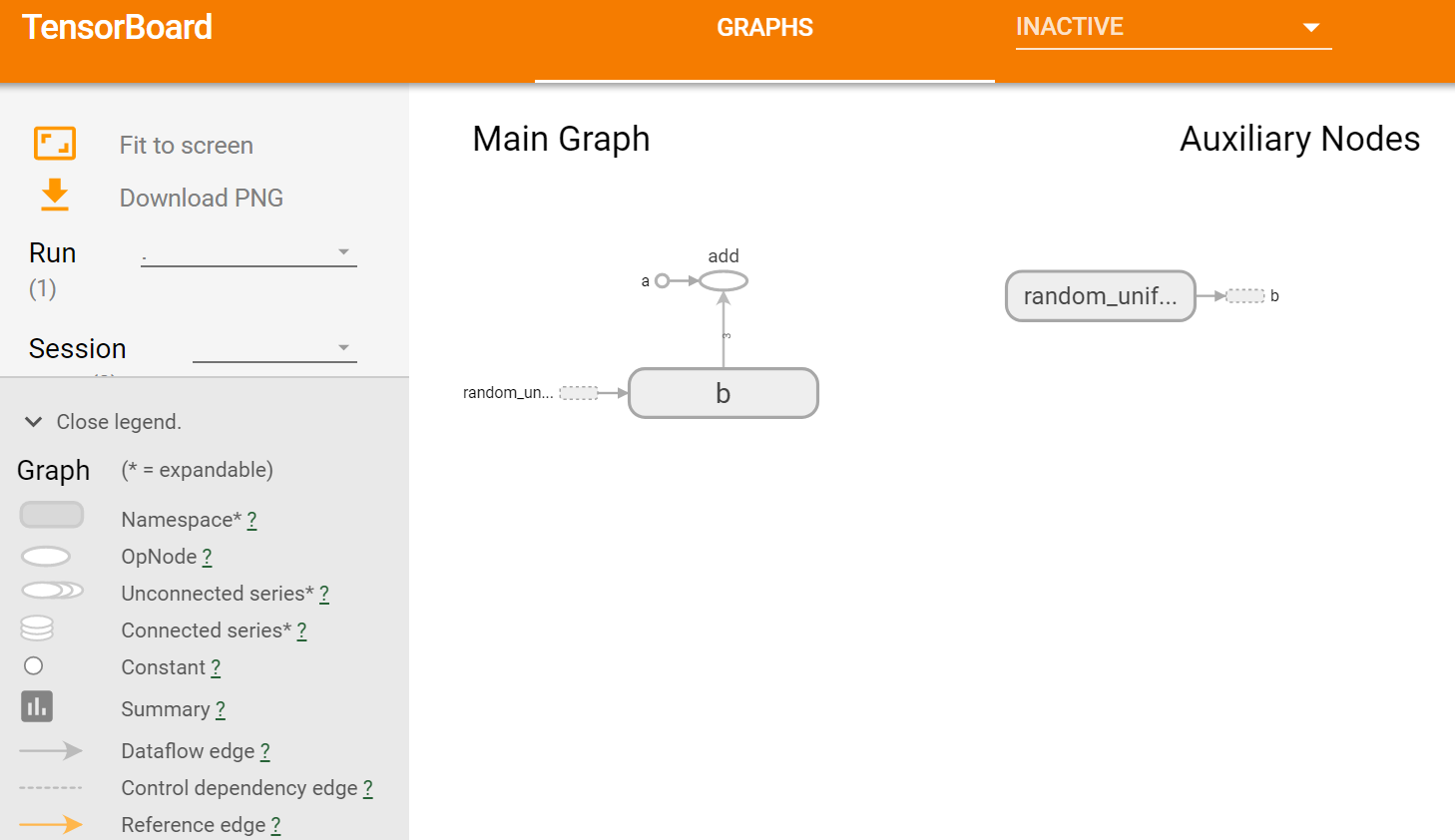
图3 tensorflow向量相加程序的计算图的可视化结果
启动tensorboard服务后,在本地浏览器中输入http://188.88.88.88:6006,会看到如上图3所示的界面。注意,由于本节程序是在Linux服务器上运行的,所以需要输入该服务器完整的IP地址(http://188.88.88.88:6006指本实验所使用的服务器IP地址,实际操作时需要修改成实际使用的服务器IP),若tensorflow程序是在本机上运行,则需将上述IP地址http://188.88.88.88:6006替换成localhost。
根据上述内容描述,tensorboard的启动过程可以概括为以下几步:
1.创建writer,写日志文件
writer=tf.summary.FileWriter('/path/to/logs', tf.get_default_graph())
2.保存日志文件
writer.close()
3.运行可视化命令,启动服务
tensorboard --logdir /path/to/logs
4.打开可视化界面
通过浏览器打开服务器访问端口http://xxx.xxx.xxx.xxx:6006
注意:tensorboard兼容Google浏览器或Firefox浏览器,对其他浏览器的兼容性较差,可能会提示bug或出现其他性能上的问题。
图4 tensorboard各栏目的默认界面
在这里使用tensorboard1.13.1,较以往版本有很多不同。首先从界面上,此版本的tensorboard导航栏中只显示有内容的栏目,如GRAPHS,其他没有相关数据的子栏目都隐藏在INACTIVE栏目中,点击这些子栏目则会显示一条如图4所示的提示信息,指示使用者如何序列化相关数据。除此之外,在栏目的数量上也有增加,新增了DISTRIBUTIONS、PROJECTOR、TEXT、PR CURVES、PROFILE五个栏目。
Tensorboard的可视化功能很丰富。SCALARS栏目展示各标量在训练过程中的变化趋势,如accuracy、cross entropy、learning_rate、网络各层的bias和weights等标量。如果输入数据中存在图片、视频,那么在IMAGES栏目和AUDIO栏目下可以看到对应格式的输入数据。在GRAPHS栏目中可以看到整个模型计算图结构。在HISTOGRAM栏目中可以看到各变量(如:activations、gradients,weights 等变量)随着训练轮数的数值分布,横轴上越靠前就是越新的轮数的结果。DISTRIBUTIONS和HISTOGRAM是两种不同形式的直方图,通过这些直方图可以看到数据整体的状况。PROJECTOR栏目中默认使用PCA分析方法,将高维数据投影到3D空间,从而显示数据之间的关系。
2. Tensorflow数据流图
从tensorboard中我们可以获取更多,远远不止图3所展示的。这一小节将从计算图结构和结点信息两方面详细介绍如何理解tensorboard中的计算图,以及从计算图中我们能获取哪些信息。
2.1 Tensorflow的计算图结构
如上图3展示的是一个简单的计算图,图结构中主要包含了以下几种元素:
 : Namespace,表示命名空间
: Namespace,表示命名空间
 :OpNode,操作结点
:OpNode,操作结点
 :Constant,常量
:Constant,常量
 :Dataflow edge,数据流向边,显示两个操作之间的tensor流程
:Dataflow edge,数据流向边,显示两个操作之间的tensor流程
 :Control dependency edge,控制依赖边
:Control dependency edge,控制依赖边
 :Reference edge,参考边
:Reference edge,参考边
除此之外,还有Unconnected series、Connected series、Summary等元素。

:彼此之间不连接的有限个节点序列。这个结构上的简化法叫做序列折叠(series collapsing)。 序列基序(Sequential motifs)是拥有相同结构并且其名称结尾的数字不同的节点,它们被折叠进一个单独的节点块(stack)中。对长序列网络来说,序列折叠极大地简化了视图,对于已层叠的节点,双击会展开序列。

:彼此之间相连的有限个节点序列
 :摘要节点
:摘要节点
 :引用边,表示出度操作节点可以使入度tensor发生变化。
:引用边,表示出度操作节点可以使入度tensor发生变化。
这些元素构成的计算图能够让我们对输入数据的流向,各个操作之间的关系等有一个清晰的认识。
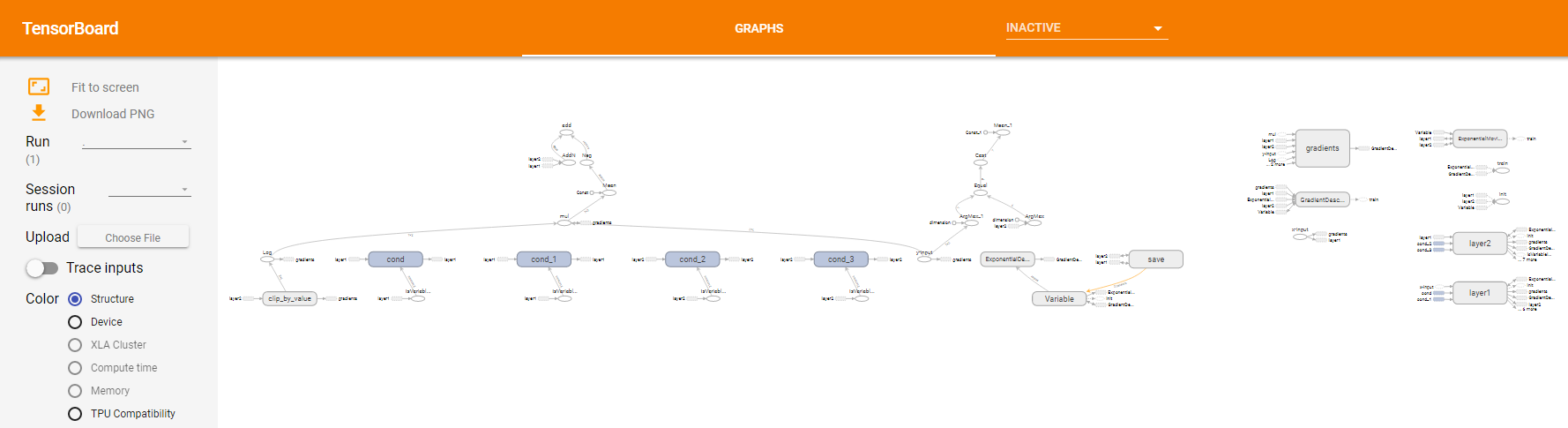
图5 初始的计算图结构
如上图5,是一个简单的两层全连接神经网络的计算图。仅仅从图5,我们很难快速了解该神经网络的主体数据流关系,因为太多的细节信息堆积在了一起。这还只是一个两层的简单神经网络,如果是多层的深度神经网络,其标量的声明,常量、变量的初始化都会产生新的计算结点,这么多的结点在一个页面上,那其对应的计算图的复杂性,排列的混乱性难以想象。所以我们需要对计算图进行整理,避免主要的计算节点淹没在大量的信息量较小的节点中,让我们能够更好的快速抓住主要信息。通过定义子命名空间,可以达到整理节点、让可视化效果更加清晰的目的。
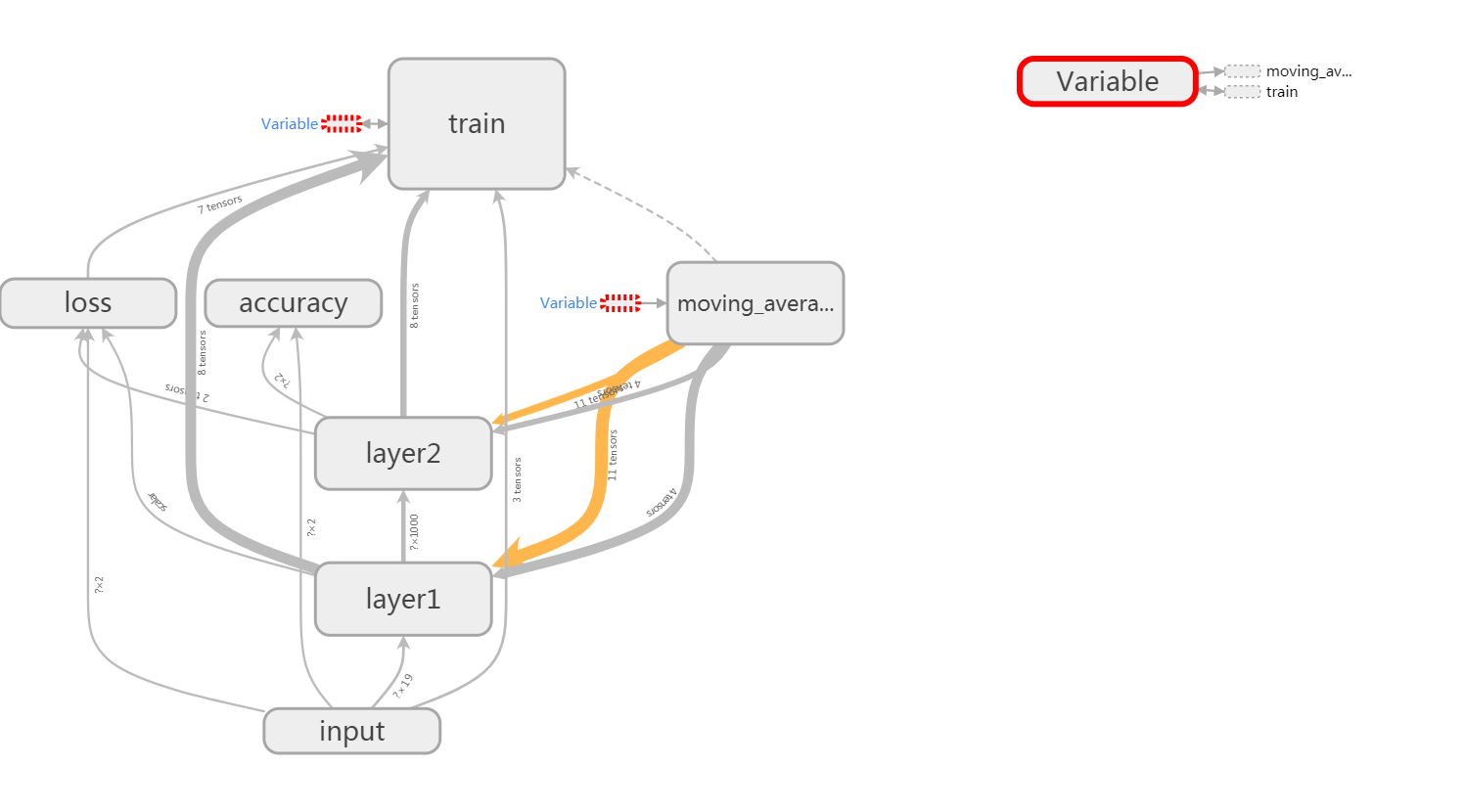
图6 整理后的计算图结构
如上图6,就是通过定义子命名空间整理结点后的效果。该计算图只显示了最顶层的各命名空间之间的数据流关系,其细节信息被隐藏起来了,这样便于把握主要信息。
图7为加入子命名空间后的部分代码截图。代码中,将输入数据都放在了input命名空间中,还使用了perdition、moving_averages、loss、train等命名空间去整理对应的操作过程。
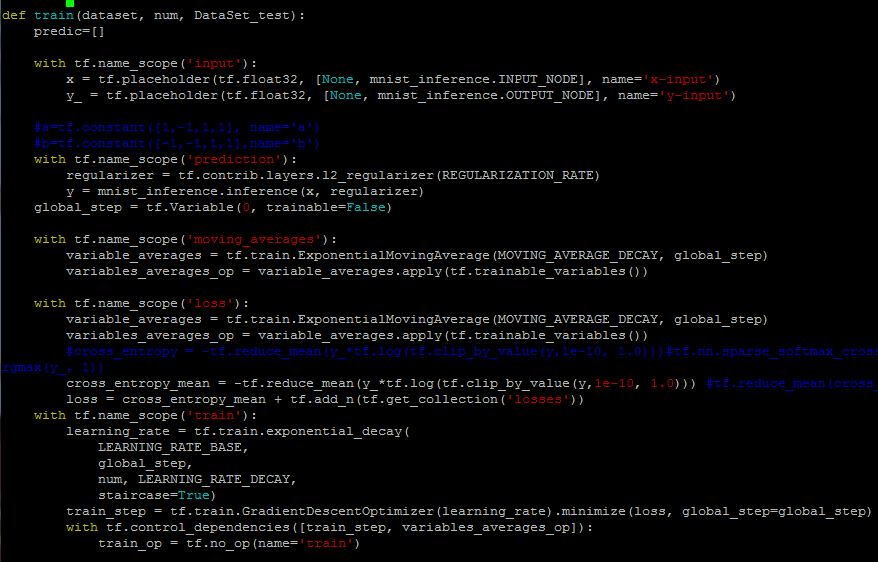
图7 用命名空间整理计算图的代码截图
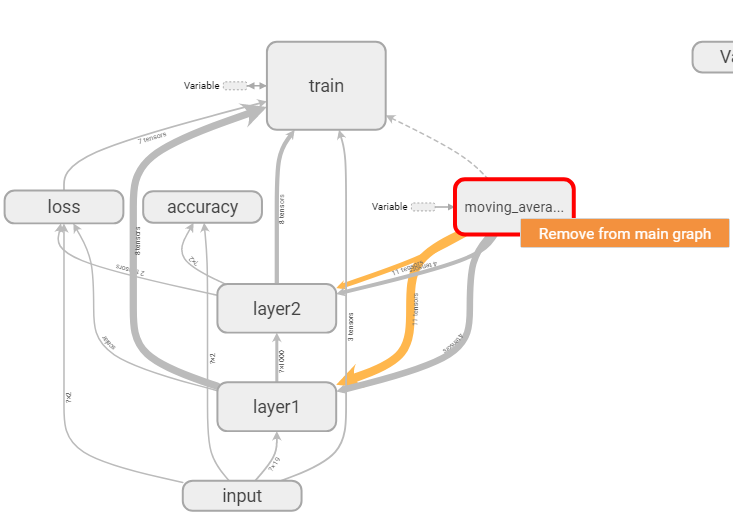
图8 手动将节点从主图中移除
除此之外,我们还可以通过手动将不重要的节点从主图中移除来简化计算图,如上图8,右键点击想要移除的节点,会出现“Remove from main graph”按钮,点击该按钮,就可以移除对应节点了。
2.2 结点的信息
Tensorboard除了可以展示整体的计算图结构之外,还可以展示很多细节信息,如结点的基本信息、运行时间、运行时消耗的内存、各结点的运行设备(GPU或者CPU)等。
2.2.1 基本信息
前面的部分介绍了如何将计算图的细节信息隐藏起来,但是有的时候,我们需要查看部分重要命名空间下的节点信息,那这些细节信息如何查看呢?对于节点信息,双击图8中的任意一个命名空间,就会展开对应命名空间的细节图(再次双击就可以收起细节图)。
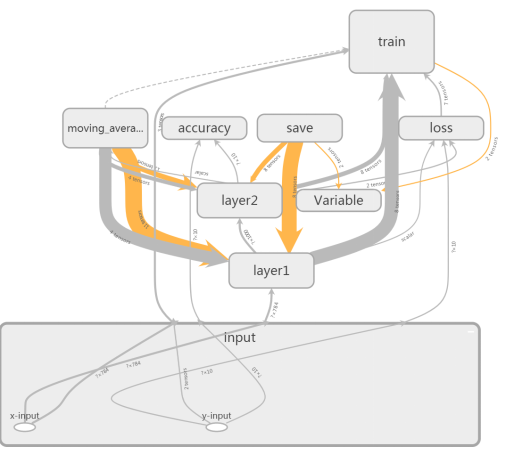
图9 展开input命名空间节点信息图
上图9是input命名空间的展开图,展开图中包含了两个操作节点(x_input和y_input)。除了了解具体包含的操作节点以及其他元素外,我们还可以获取粒度更小的信息。
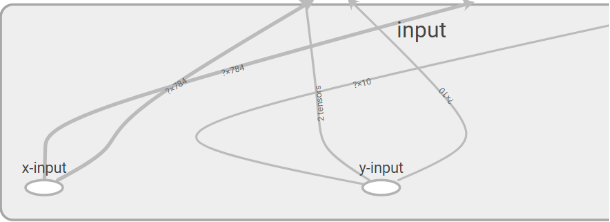
图10 input命名空间的放大的细节图
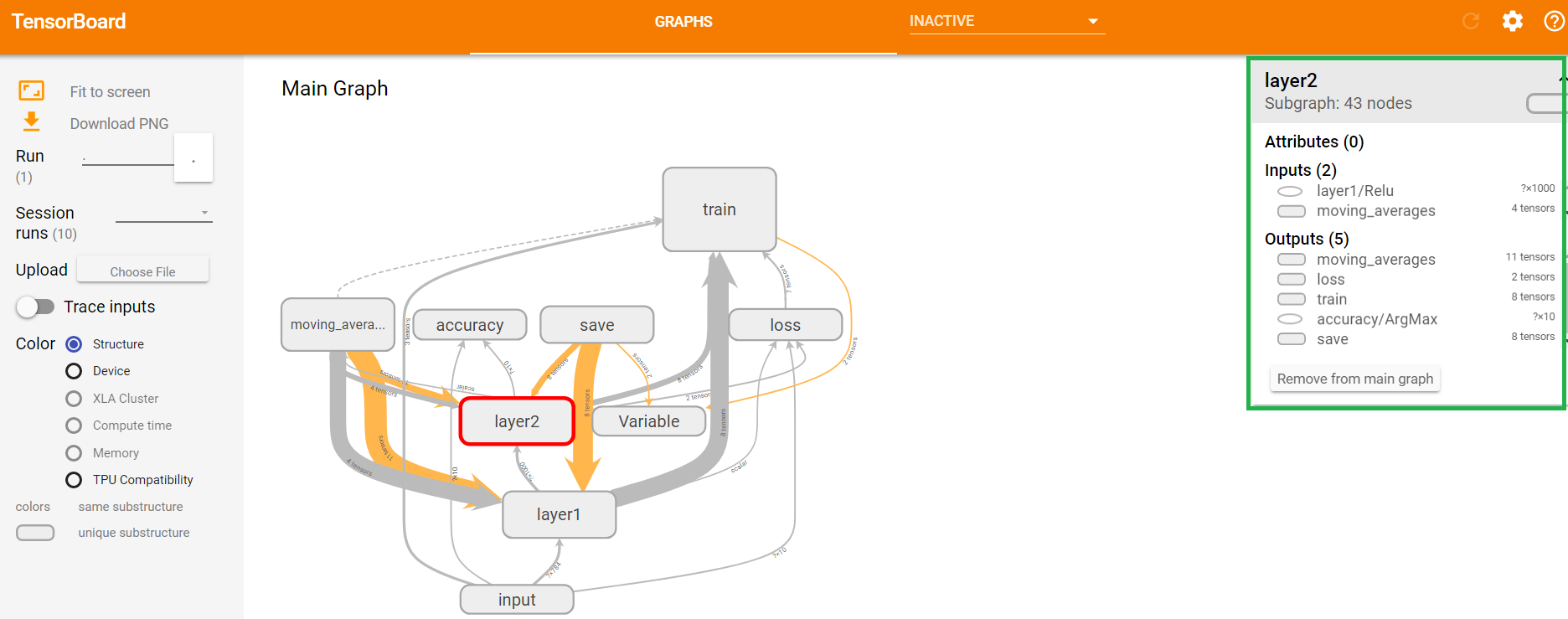
图11 命名空间的节点信息
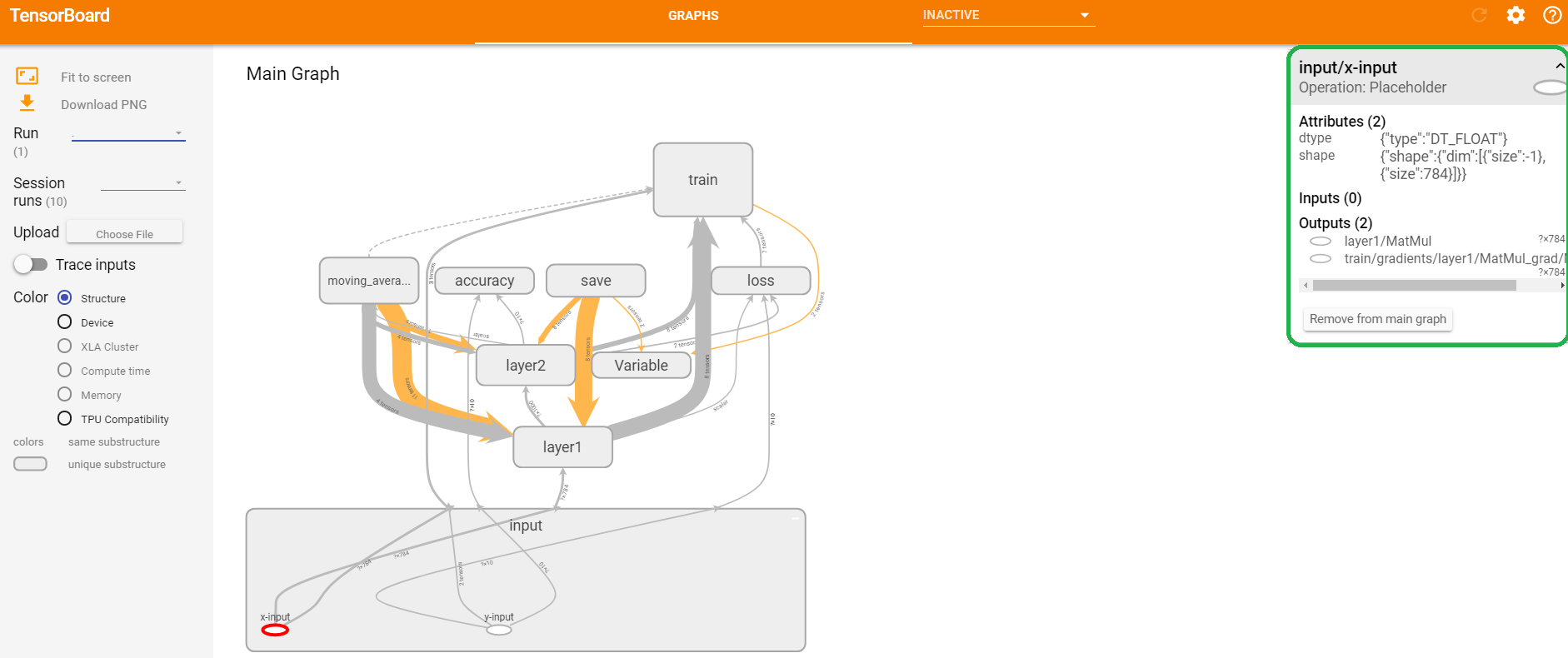
图12 计算节点的基本信息
上图10所示为图9中input命名空间展开图的放大图。观察图10,我们可以了解到输入数据x、y的维度,图中x的向量维度为784维,y为10维,?表示样本数量。本节演示中使用的是mnist数据集,mnist数据集是一个针对图片的10分类任务,输入向量维度是784,这说明可以通过计算图上这些信息,来校验输入数据是否正确。通过左键单击命名空间或者操作节点,屏幕的右上角会显示对应的具体信息。
如上图11中,右上角绿色框标注的部分为命名空间layer2的具体信息。如上图12中,右上角绿色框标注的部分为节点x_input的具体信息。
2.2.2 其他信息
除了节点的基本信息之外,tensorboard还可以展示每个节点运行时消耗的时间、空间、运行的机器(GPU或者CPU)等信息。本小节将详细讲解如何使用tensorboard展示这些信息。这些信息有助于快速获取时间、空间复杂度较大的节点,从而指导后面的程序优化。
将2.1节中图7所展示的代码的session部分改成如下所示的程序,就可以将程序运行过程中不同迭代轮数中tensorflow各节点消耗的时间和空间等信息写入日志文件中,然后通过读取日志文件将这些信息用tensorboard展示出来。
#创建writer对象
writer=tf.summary.FileWriter("/path/to/metadata_logs",tf.get_default_graph())
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
x_batch, y_batch=mnist.train.next_batch(BATCH_SIZE)
if i%1000==0:
#这里通过trace_level参数配置运行时需要记录的信息,
# tf.RunOptions.FULL_TRACE代表所有的信息
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
#运行时记录运行信息的proto,pb是用来序列化数据的
run_metadata = tf.RunMetadata()
#将配置信息和记录运行信息的proto传入运行的过程,从而记录运行时每一个节点的时间、空间开销信息
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: x_batch, y_: y_batch}, options=run_options, run_metadata=run_metadata)
#将节点在运行时的信息写入日志文件
writer.add_run_metadata(run_metadata, 'step %03d' % i)
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
writer.close()
运行上面的程序,生成日志文件存储在/path/to/metadata_logs/目录下,启动tensorboard服务,读取日志文件信息,将每一个节点在不同迭代轮数消耗的时间、空间等信息展示出来。
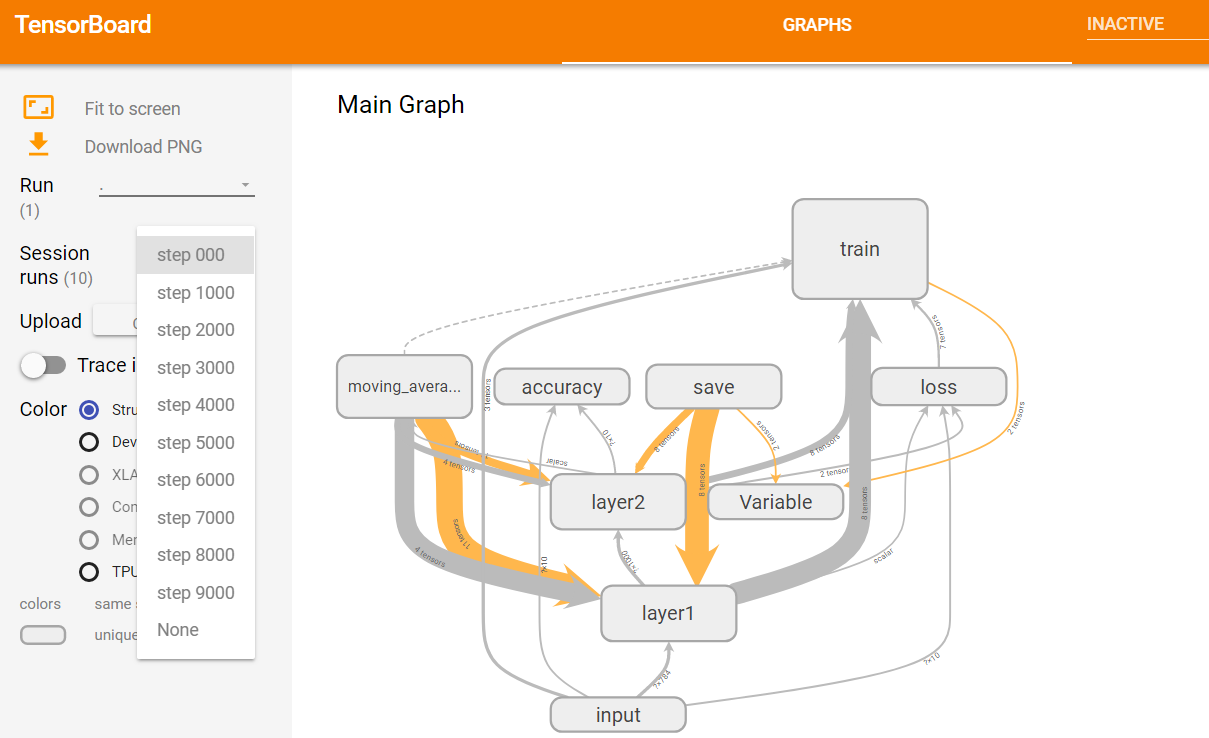
图13 选择迭代轮数对应记录页面
如上图13所示,在浏览器中打开可视化界面,进入GRAPHS子栏目,点击Session runs选框,会出现一个下拉菜单,这个菜单中展示了所有日志文件中记录的运行数据所对应的迭代轮数。任意选择一个迭代轮数,页面右边的区域会显示对应的运行数据。
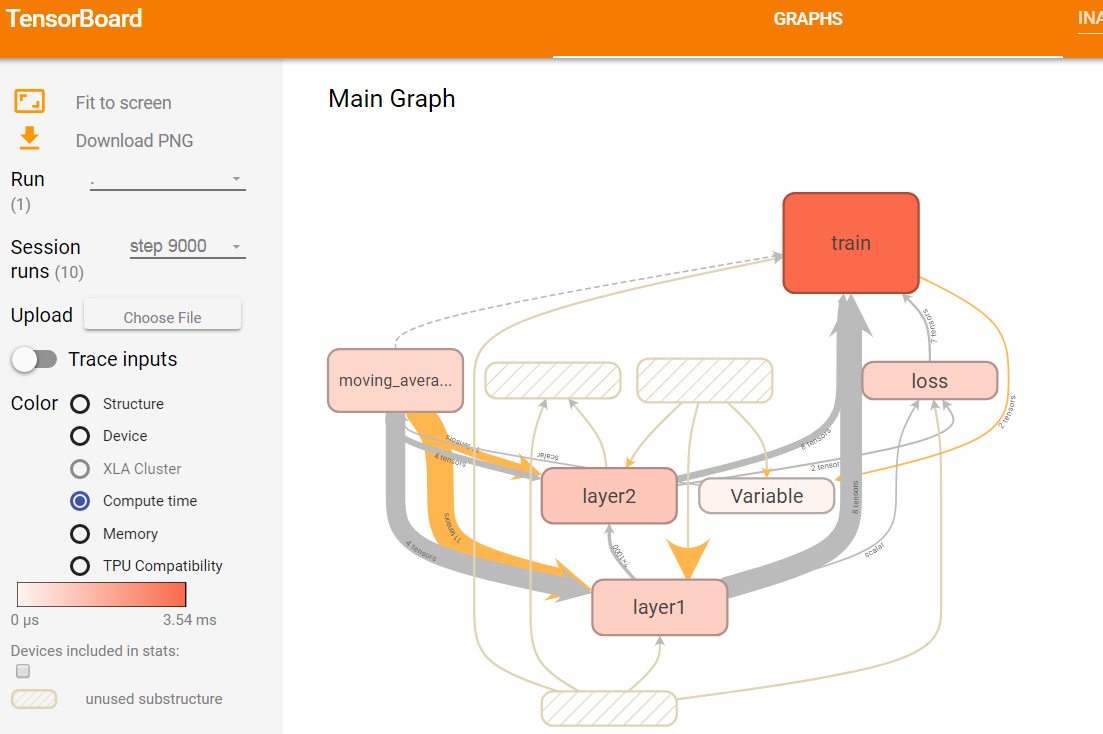
图14 第9000轮迭代时不同计算节点消耗时间的可视化效果图
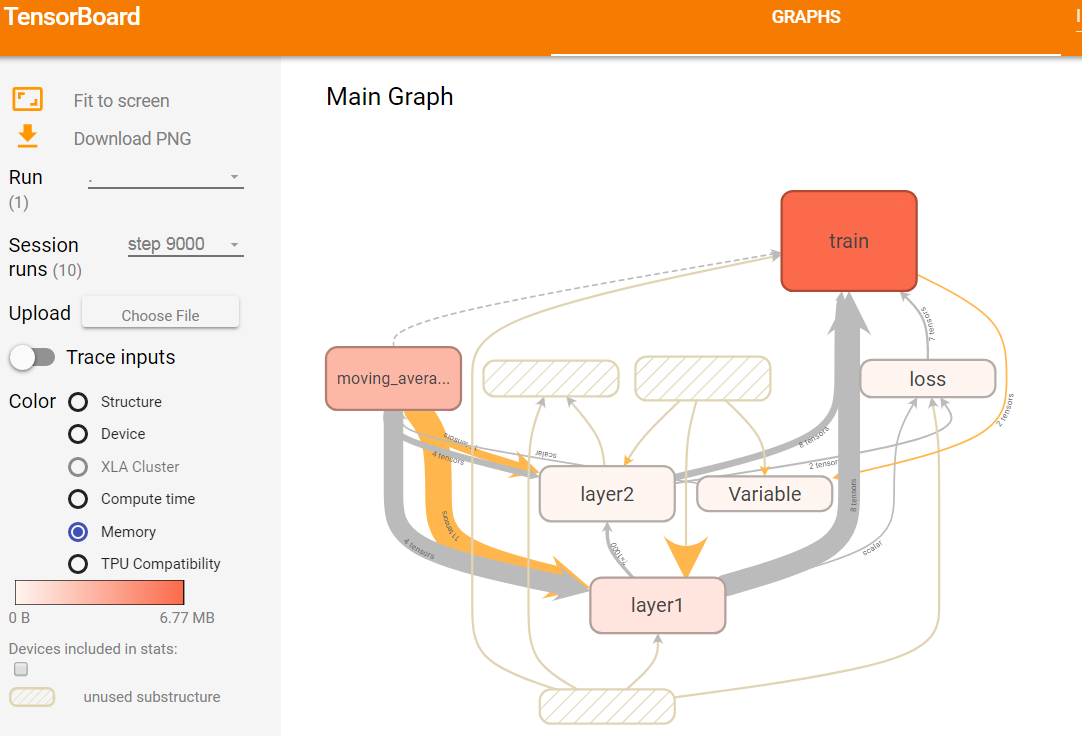
图15 第9000轮迭代时不同计算节点占有存储的可视化效果图
如上图14所示,选择了第9000轮的运行数据,然后选择Color栏目下的Compute time选项,GRAPHS栏目下就会显示tensorflow程序每个计算节点的运行时间。图中使用颜色的深浅来表示运行时间的长短,颜色深浅对应的具体运行时间可以从页面左侧的颜色条看出。由图14可知,train命名空间运行时所消耗的时间最长,Variable命名空间所消耗的时间比较短,无色表示不消耗时间。
如上图15展示了tensorflow各个节点所占用的空间大小。与衡量运行时所消耗的时间方法类似,使用颜色的深浅来标识所占用内存的大小。颜色条上的数字说明,占用的最大空间为677MB,最小空间为0B。train命名空间占用的存储空间最大。
除了时间和空间指标,tensorboard还可以展示各节点的运行设备(GPU还是CPU)、XLA Cluster、TPU Compatibility等,这些全部都在Color栏目下作为选项供选择。这些指标都是将节点染色,通过不同颜色以及颜色深浅来标识结果的。如下图16,是TPU Compatibility展示图。
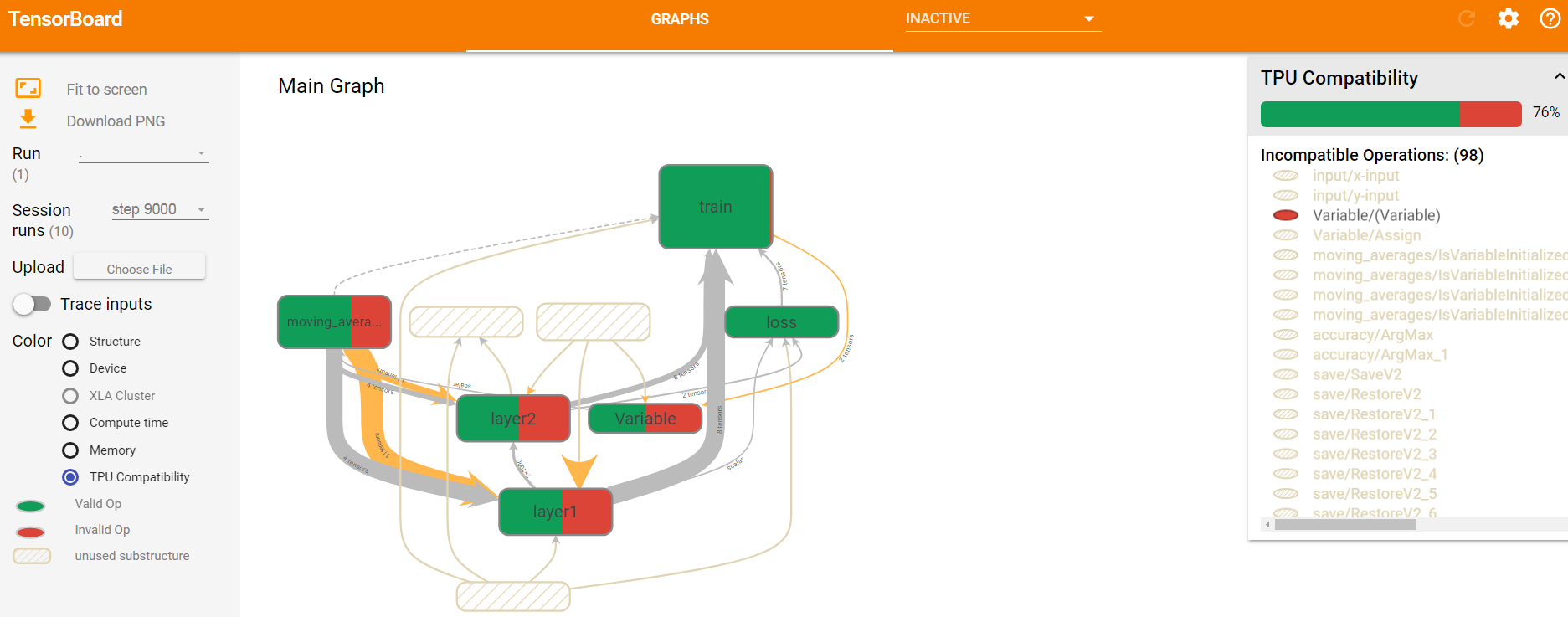
图16 第9000轮迭代时不同计算节点的TPU Compatibility效果展示图
3. Tensorflow监控指标可视化
除了GRAPHS栏目外,tensorboard还有IMAGES、AUDIO、SCALARS、HISTOGRAMS、DISTRIBUTIONS、FROJECTOR、TEXT、PR CURVES、PROFILE九个栏目,本小节将详细介绍这些子栏目各自的特点和用法。
3.1 IMAGES
图像仪表盘,可以显示通过tf.summary.image()函数来保存的png图片文件。
# 指定图片的数据源为输入数据x,展示的相对位置为[-1,28,28,1]
image_shape=tf.reshape(x, [-1, 28, 28,1])
# 将input命名空间下的图片放到summary中,一次展示10张
tf.summary.image('input', image_shape, 10)
如上面代码,将输入数据中的png图片放到summary中,准备后面写入日志文件。运行程序,生成日志文件,然后在tensorboard的IMAGES栏目下就会出现如下图17所示的内容(实验用的是mnist数据集)。仪表盘设置为每行对应不同的标签,每列对应一个运行。图像仪表盘仅支持png图片格式,可以使用它将自定义生成的可视化图像(例如matplotlib散点图)嵌入到tensorboard中。该仪表盘始终显示每个标签的最新图像。
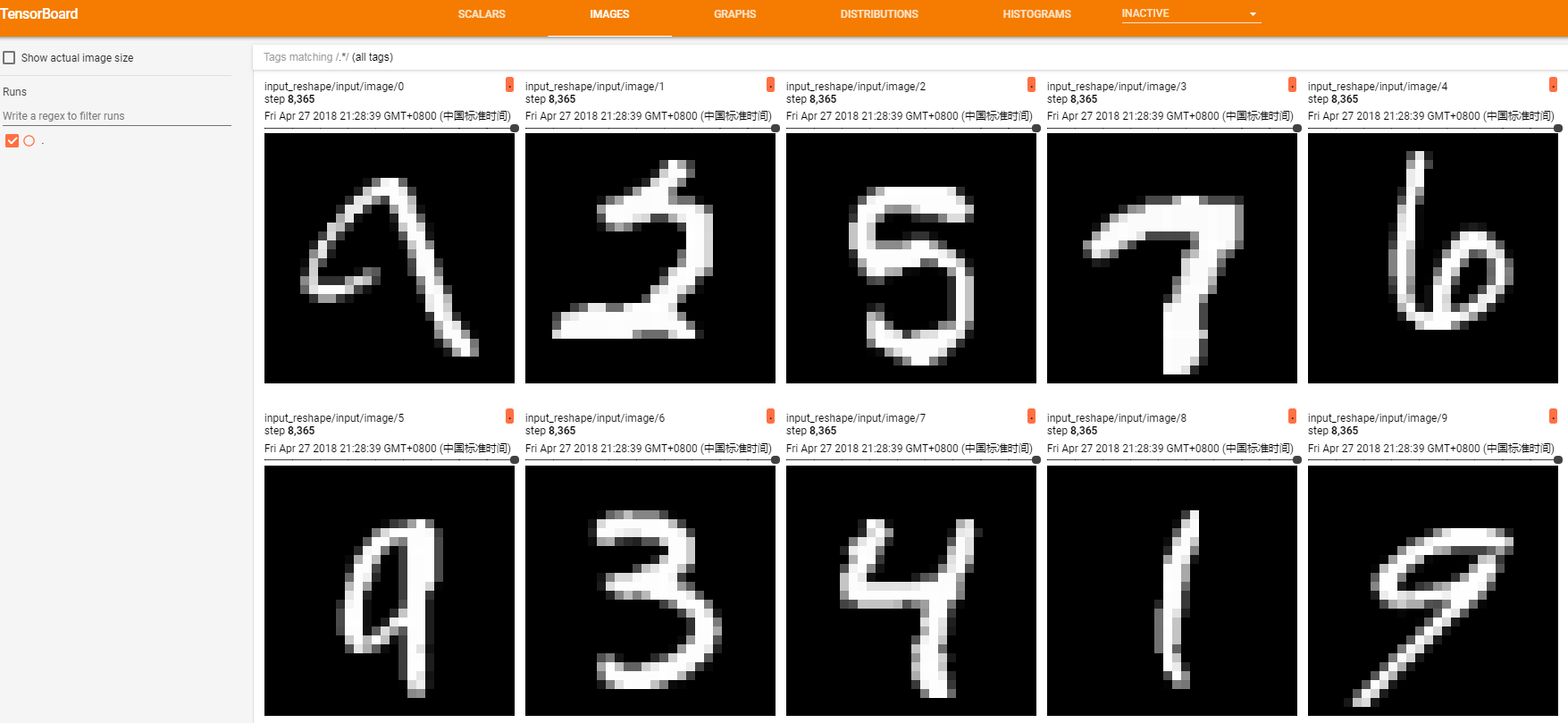
图17 tensorboard中的IMAGES栏目内容展开界面
3.2 AUDIO
音频仪表盘,可嵌入音频的小部件,用于播放通过tf.summary.audio()函数保存的音频。
tf.summary.audio('audio', audio, sampling_frequency)
audio是一个三维或者二维tensor,含义是[音频数, 每个音频的帧数, 每个音频的通道数]或者[音频数, 每个音频的帧数]。
sampling_frequency是音频的采样率。
仪表盘设置为每行对应不同的标签,每列对应一个运行。该仪表盘始终嵌入每个标签的最新音频。
3.3 SCALARS
Tensorboard 的标量仪表盘,统计tensorflow中的标量(如:学习率、模型的总损失)随着迭代轮数的变化情况。如下图18所示,SCALARS栏目显示通过函数tf.summary.scalar()记录的数据的变化趋势。如下所示代码可添加到程序中,用于记录学习率的变化情况。
# 在learning_rate附近添加,用于记录learning_rate
tf.summary.scalar('learning_rate', learning_rate)
Scalars栏目能进行的交互操作有:
- 点击每个图表左下角的蓝色小图标将展开图表
- 拖动图表上的矩形区域将放大
- 双击图表将缩小
- 鼠标悬停在图表上会产生十字线,数据值记录在左侧的运行选择器中。
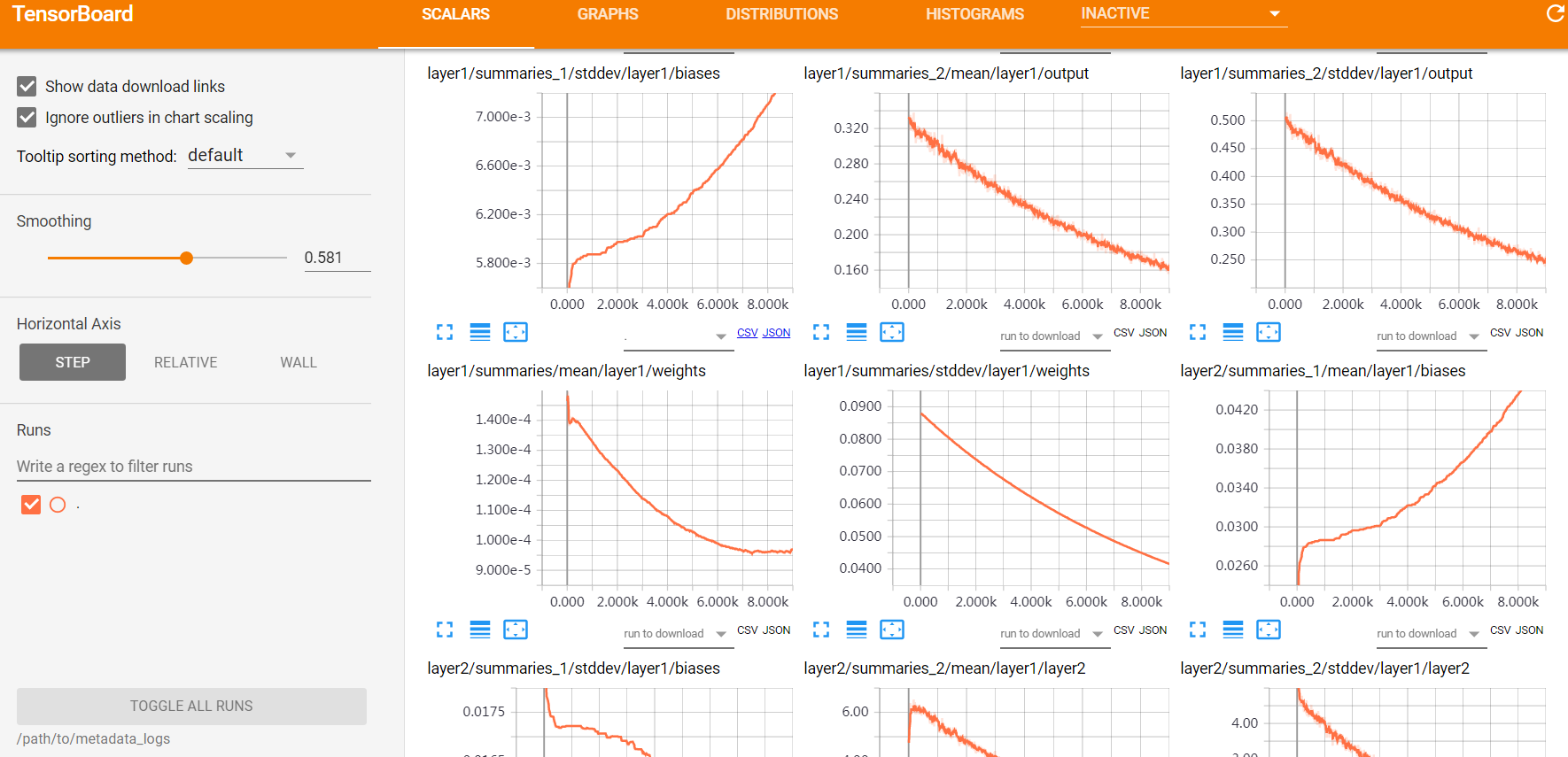
图18 tensorboard中的SCALARS栏目内容展开界面
此外,读者可通过在仪表盘左侧的输入框中,编写正则表达式来创建新文件夹,从而组织标签。
3.4 HISTOGRAMS
Tensorboard的张量仪表盘,统计tensorflow中的张量随着迭代轮数的变化情况。它用于展示通过tf.summary.histogram记录的数据的变化趋势。如下代码所示:
tf.summary.histogram(weights, 'weights')
上述代码将神经网络中某一层的权重weight加入到日志文件中,运行程序生成日志后,启动tensorboard就可以在HISTOGRAMS栏目下看到对应的展开图像,如下图19所示。每个图表显示数据的时间“切片”,其中每个切片是给定步骤处张量的直方图。它依据的是最古老的时间步原理,当前最近的时间步在最前面。通过将直方图模式从“偏移”更改为“叠加”,如果是透视图就将其旋转,以便每个直方图切片都呈现为一条相互重叠的线。
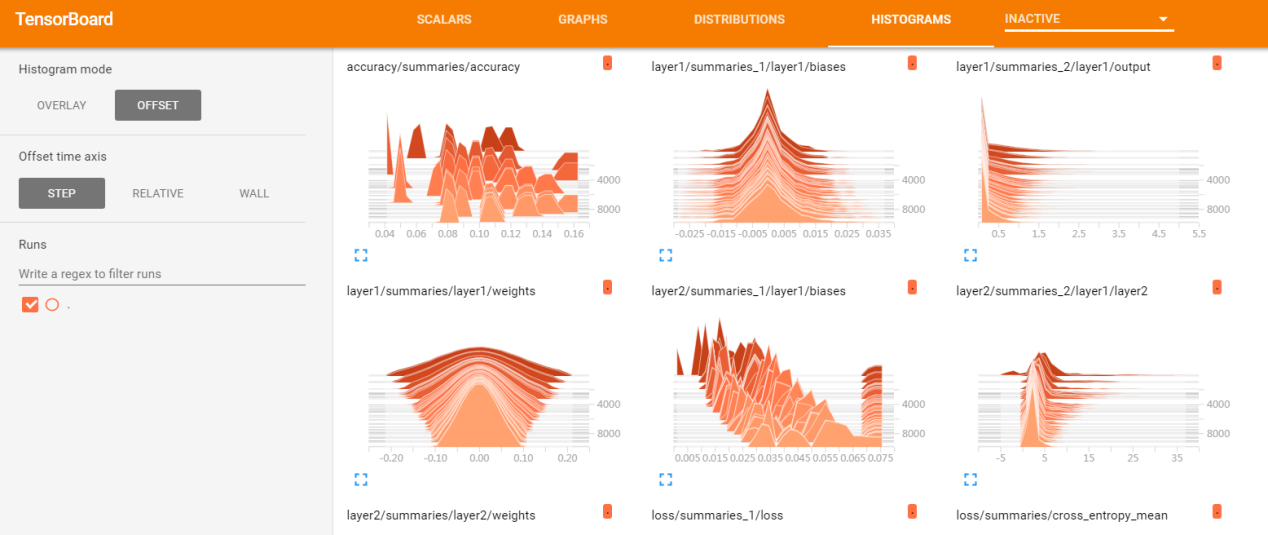
图19 tensorboard中的HISTOGRAMS栏目内容展开界面
3.5 DISTRIBUTIONS
Tensorboard的张量仪表盘,相较于HISTOGRAMS,用另一种直方图展示从tf.summary.histogram()函数记录的数据的规律。它显示了一些分发的高级统计信息。
如下图20所示,图表上的每条线表示数据分布的百分位数,例如,底线显示最小值随时间的变化趋势,中间的线显示中值变化的方式。从上至下看时,各行具有以下含义:[最大值,93%,84%,69%,50%,31%,16%,7%,最小值]。这些百分位数也可以看作标准偏差的正态分布:[最大值,μ+1.5σ,μ+σ,μ+0.5σ,μ,μ-0.5σ,μ-σ,μ-1.5σ,最小值],使得从内侧读到外侧的着色区域分别具有宽度[σ,2σ,3σ]。
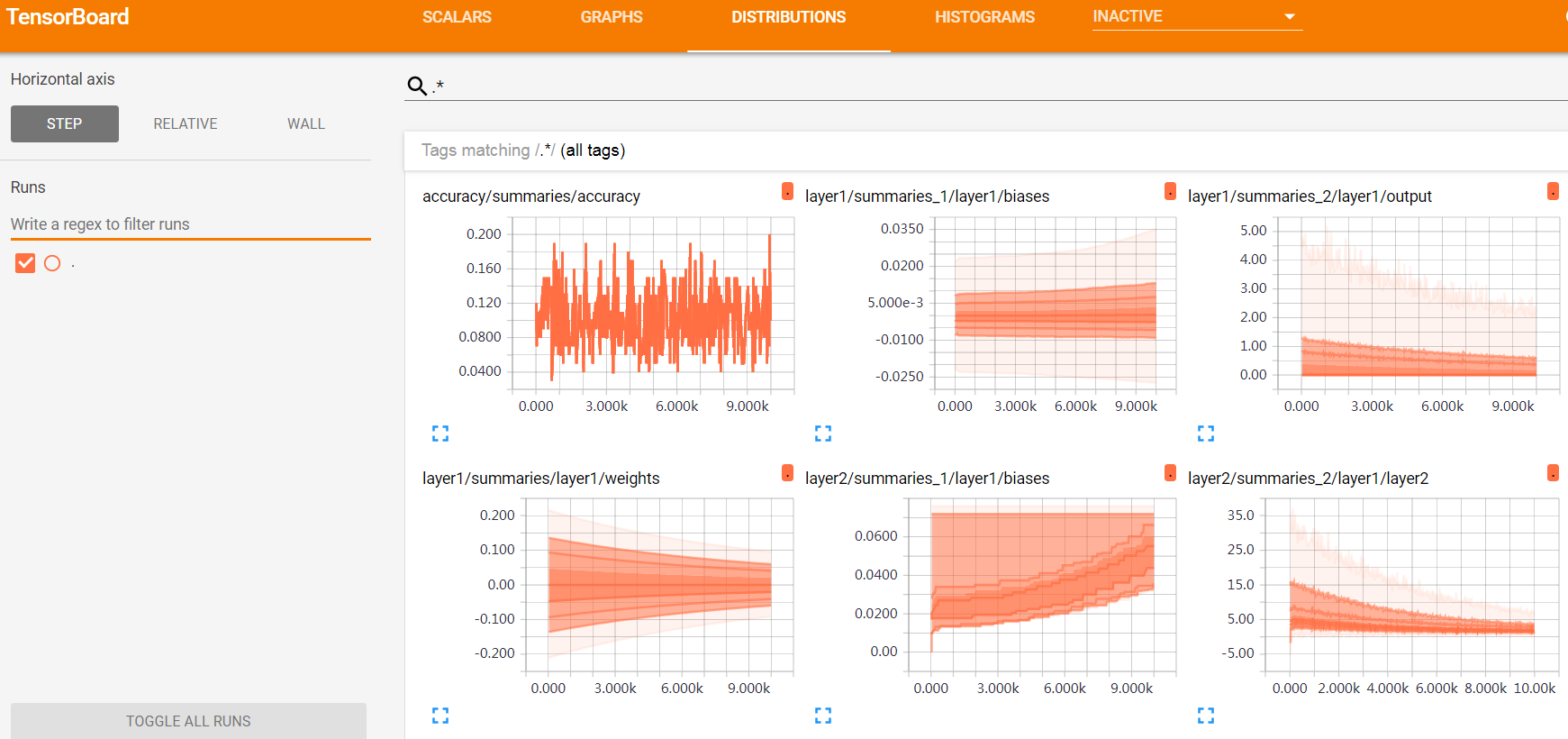
图20 tensorboard中的DISTRIBUTIONS栏目内容展开界面
3.6 PROJECTOR
嵌入式投影仪表盘,全称Embedding Projector,是一个交互式的可视化工具,通过数据可视化来分析高维数据。例如,读者可在模型运行过程中,将高维向量输入,通过embedding projector投影到3D空间,即可查看该高维向量的形式,并执行相关的校验操作。Embedding projector的建立主要分为以下几个步骤:
1)建立embedding tensor
#1. 建立 embeddings
embedding_var = tf.Variable(batch_xs, name="mnist_embedding")
summary_writer = tf.summary.FileWriter(LOG_DIR)
2)建立embedding projector 并配置
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
embedding.metadata_path = path_for_mnist_metadata #'metadata.tsv'
embedding.sprite.image_path = path_for_mnist_sprites #'mnistdigits.png'
embedding.sprite.single_image_dim.extend([28,28])
projector.visualize_embeddings(summary_writer, config)
3)将高维变量保存到日志目录下的checkpoint文件中
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"), 1)
4)将metadata与embedding联系起来,将 vector 转换为 images,反转灰度,创建并保存 sprite image
to_visualise = batch_xs
to_visualise = vector_to_matrix_mnist(to_visualise)
to_visualise = invert_grayscale(to_visualise)
sprite_image = create_sprite_image(to_visualise)
plt.imsave(path_for_mnist_sprites,sprite_image,cmap='gray')
5)运行程序,生成日志文件,启动服务,tensorboard中的PROJECTOR栏将展示投影后的数据的动态图,如下图21所示。
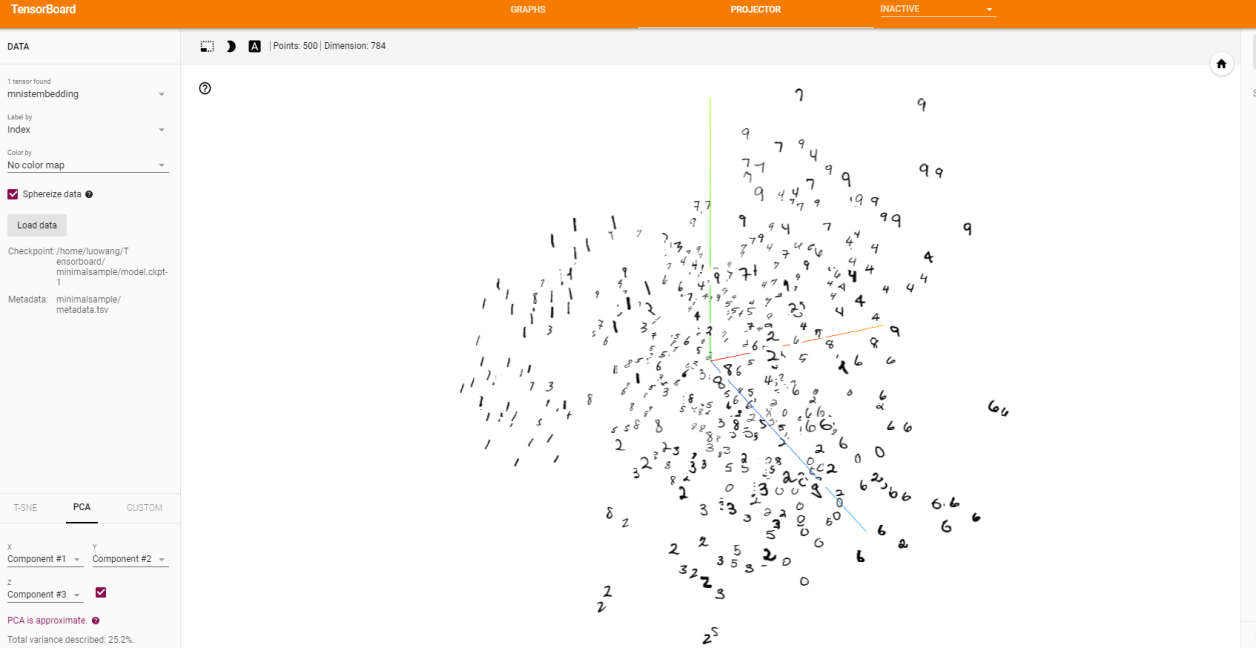
图21 tensorboard中的PROJECTOR栏目内容展开界面
Embedding Projector从模型运行过程中保存的checkpoint文件中读取数据,默认使用主成分分析法(PCA)将高维数据投影到3D空间中,也可以设置选择另外一种投影方法,T-SNE。除此之外,也可以使用其他元数据进行配置,如词汇文件或sprite图片。
3.7 TEXT
文本仪表盘,显示通过tf.summary.text()函数保存的文本片段,包括超链接、列表和表格在内的Markdown功能均支持。
3.8 PR CURVES
PR CURVES仪表盘显示的是随时间变化的PR曲线,其中precision为横坐标,recall为纵坐标。如下代码创建了一个用于记录PR曲线的summary。
# labels为输入的y, predition为预测的y值
# num_thresholds为多分类的类别数量
tensorboard.summary.pr_curve(name='foo',
predictions=predictions,
labels=labels,
num_thresholds=11)
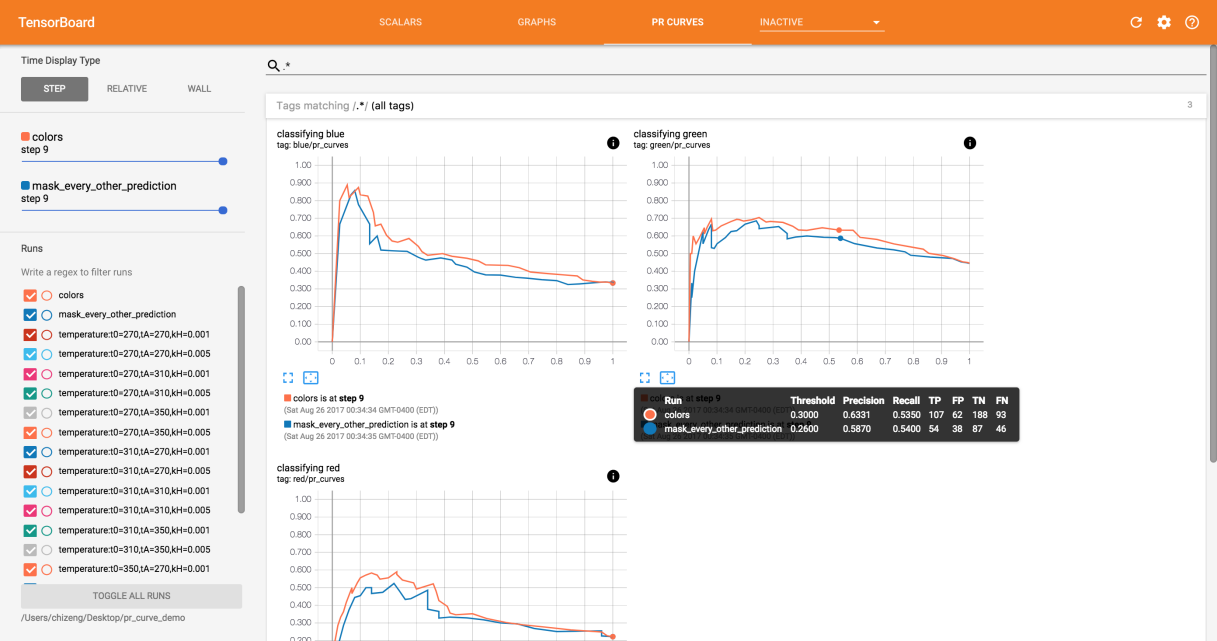
图22 tensorboard中的PR CURVES栏目内容展开界面
上图22为tensorboard上PR CURVES栏目在有内容时的首页,没有内容时就隐藏在INACTIVE栏目下。
训练模型时,经常需要在查准率和查全率之间权衡,PR曲线能够帮助我们找到这个权衡点。每条曲线都对应一个二分类问题,所以,针对多分类问题,每一个类都会生成一条对应的PR曲线。
3.9 PROFILE
Tensorboard的配置文件仪表盘,该仪表盘上包含了一套TPU工具,可以帮助我们了解,调试,优化tensorflow程序,使其在TPU上更好的运行。
但并不是所有人都可以使用该仪表盘,只有在Google Cloud TPU上有访问权限的人才能使用配置文件仪表盘上的工具。而且,该仪表盘与其他仪表盘一样,都需要在模型运行时捕获相关变量的跟踪信息,存入日志,方可用于展示。
在PROFILE仪表盘的首页上,显示的是程序在TPU上运行的工作负载性能,它主要分为五个部分:Performance Summary、Step-time Graph、Top 10 Tensorflow operations executed on TPU、Run Environment和Recommendation for Next Step。如下图23所示:
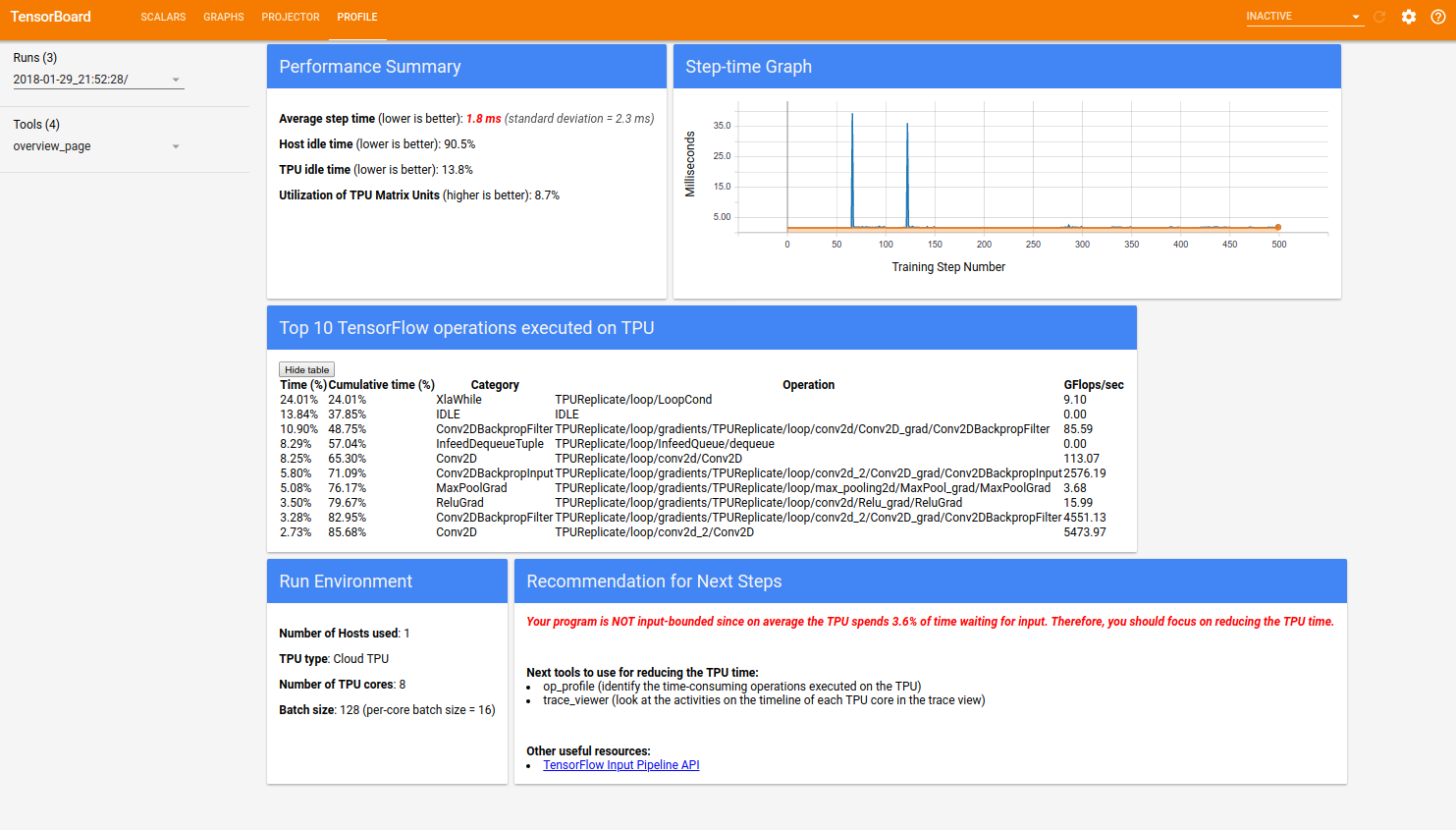
图23 tensorboard中的PROFILE栏目内容展开界面
其中,Performance Summary包括以下四项:
1)所有采样步骤的平均步长时间
2)主机空闲时间百分比
3)TPU空闲时间百分比
4)TPU矩阵单元的利用率
Run Environment(运行环境)包括以下五方面:
1)使用的主机数量
2)使用的TPU类型
3)TPU内核的数量
4)训练批次的大小(batch size)
5)作业信息(构建命令和运行命令)
4. 总结
本节主要介绍了tensorflow中一个非常重要的工具——tensorboard。Tensorboard是一个可视化工具,它能够以直方图、折线图等形式展示程序运行过程中各标量、张量随迭代轮数的变化趋势,它也可以显示高维度的向量、文本、图片和音频等形式的输入数据,用于对输入数据的校验。Tensorflow函数与tensorboard栏目的对应关系如下表所示。
| Tensorboard栏目 | tensorflow日志生成函数 | 内容 |
|---|---|---|
| GRAPHS | 默认保存 | 显示tensorflow计算图 |
| SCALARS | tf.summary.scalar | 显示tensorflow中的张量随迭代轮数的变化趋势 |
| DISTRIBUTIONS | tf.summary.histogram | 显示tensorflow中张量的直方图 |
| HISTOGRAMS | tf.summary.histogram | 显示tensorflow中张量的直方图(以另一种方式) |
| IMAGES | tf.summary.image | 显示tensorflow中使用的图片 |
| AUDIO | tf.summary.audio | 显示tensorflow中使用的音频 |
| TEXT | tf.summary.text | 显示tensor flow中使用的文本 |
| PROJECTOR | 通过读取checkpoint文件可视化高维数据 |
Tensorboard的可视化功能对于tensorflow程序的训练非常重要,使用tensorboard进行调参主要分为以下几步:
1)校验输入数据
如果输入数据的格式是图片、音频、文本的话,可以校验一下格式是否正确。如果是处理好的低维向量的话,就不需要通过tensorboard校验。
2)查看graph结构
查看各个节点之间的数据流关系是否正确,再查看各个节点所消耗的时间和空间,分析程序优化的瓶颈。
3)查看各变量的变化趋势
在SCALAR、HISTOGRAMS、DISTRIBUTIONS等栏目下查看accuracy、weights、biases等变量的变化趋势,分析模型的性能
4)修改code
根据3)和4)的分析结果,优化代码。
5)选择最优模型
6)用Embedding Projector进一步查看error出处
Tensorboard虽然只是tensorflow的一个附加工具,但熟练掌握tensorboard的使用,对每一个需要对tensorflow程序调优的人都非常重要,它可以显著提高调参工作的效率,帮助我们更快速地找到最优模型。
读取数据
1. tensorflow 的数据读取机制
以图像数据为例,数据读取过程如下所示:

假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
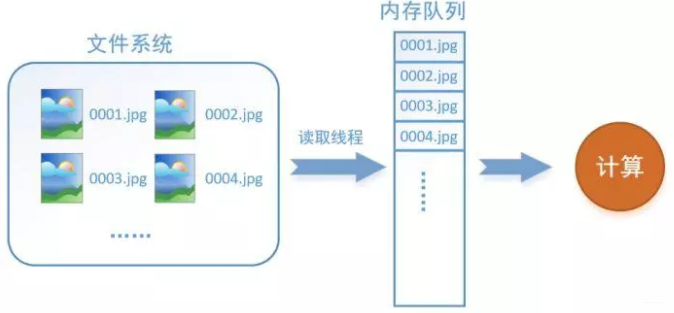
读取线程源源不断地将文件系统中的图片读入到内存队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的**“文件名队列”**。
为什么要添加这一层文件名队列?首先得了解机器学习中的一个概念:epoch(迭代)。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面用图片的形式来说明这个机制的运行方式。还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束,如下图。

程序运行后,内存队列首先读入A(此时A从文件名队列中出队),然后再读取B和C。



此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
2. TensorFlow数据读取机制对应的函数
如何在TensorFlow中创建这两个内存?
- 创建文件名队列 - tf.train.string_input_producer 阻塞态 + tf.train.start_queue_runners 激活态
把输入的数据按照要求排序成一个队列。最常见的是把一堆文件名整理成一个队列。如下操作:
filenames = [os.path.join(data_dir,'data_batch%d.bin' % i ) for i in xrange(1,6)]
filename_queue = tf.train.string_input_producer(filenames)
tf.train.string_input_producer有两个重要的参数,一个是num_epochs,它就是上文中提到的epoch数。另一个是shuffle,shuffle是指在epoch内文件顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变。如果设置shuffle=True,那么在epoch内,数据的前后顺序就会被打乱,具体如下图所示。


**其实,仅仅应用tf.train.string_input_producer构建的文件名队列是处于阻塞态的,并没有真正的将文件名读入到相应的文件名队列内存中,如下左图所示。为了完成在文件名队列内存中构建文件名队列(也就是我们说的读入数据),我们还需要tf.train.start_queue_runners进行启动,**如下右图所示。


我们通常也把tf.train.start_queue_runners叫做‘入栈线程启动器’,使用tf.train.start_queue_runners之后,才会真正启动填充队列的线程,这时系统就不再“阻塞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了。
- 创建数据内存序列
在tensorflow中,数据内存队列不需要自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了。所以TensorFlow高效读取数据机制中,最重要的是完成文件名队列的设计。
3. 为什么要使用TFRecords来进行文件的读写?
在tensorflow中数据的传入方式主要包含以下几种:
- 供给数据(feed): 在tensorflow程序运行的每一步, 让Python代码来供给数据。
- 从文件读取数据: 在tensorflow graph的起始, 让一个输入pipeline从文件中读取数据。
- 预加载数据: 在tensorflow graph中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
当我们遇到数据集比较大的情况时,第一种和最后一种方法会极其占内存,效率很差。那么为什么使用TFRecords会比较快?在于其使用二进制存储文件,也就是将数据存储在一个内存块中,相比其它文件格式要快很多,特别是如果你使用hdd(Hard Disk Drive)而不是ssd(Solid State Disk),因为它涉及移动磁盘阅读器头并且需要相当长的时间。总体而言,通过使用二进制文件,可以更轻松地分发数据,使数据更好地对齐,以实现高效的读取。
整个过程分两部分,一是使用tf.train.Example协议流将文件保存成TFRecords格式的.tfrecords文件,这里主要涉及到使用tf.python_io.TFRecordWriter(“train.tfrecords”)和tf.train.Example以及tf.train.Features三个函数,第一个是生成需要对应格式的文件,后面两个函数主要是将我们要传入的数据按照一定的格式进行规范化。
另一部分就是在训练模型时将我们生成的.tfrecords文件读入并传到模型中进行使用。这部分主要涉及到使用tf.TFRecordReader(“train.tfrecords”)和tf.parse_single_example两个函数。第一个函数是将我们的二进制文件读入,第二个则是进行解析然后得到我们想要的数据。
#### 生成train.tfrecords文件 ####
import os
import tensorflow as tf
from PIL import Image
cwd = os.getcwd()
''' 数据目录
-- img1.jpg
img2.jpg
img3.jpg
...
-- img1.jpg
img2.jpg
...
-- ...
'''
writer = tf.python_io.TFRecordWriter("train.tfrecords") # 定义train.tfrecords文件
for index, name in enumerate(classes): # 遍历每一个文件夹
class_path = cwd + name + "/" # 每一个文件夹的路径
for img_name in os.listdir(class_path): # 遍历每个文件夹中所有的图像
img_path = class_path + img_name # 每一张图像的路径
img = Image.open(img_path) # 打开图像
img = img.resize((224, 224)) # 图像裁剪
img_raw = img.tobytes() # 将图像转化为bytes
# 调用Example 和 Feature函数将数据格式化保存起来
# 注意:Features 传入参数为一个字典,方便后续读取数据时的操作
example = tf.train.Example(features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[index])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
#序列化为字符串,并写入数据
writer.write(example.SerializeToString())
writer.close()
基本的,一个Example中包含Features,Features里包含Feature(这里没s)的字典。最后,Feature里包含有一个 FloatList,或者ByteList,或者Int64List
就这样,我们把相关的信息都存到了一个文件中,不用单独的label文件,读取也很方便。
# 从tfrecords文件中读取记录的迭代器
for serialized_example in tf.python_io.tf_record_iterator("train.tfrecords"):
example = tf.train.Example()
example.ParseFromString(serialized_example)
image = example.features.feature['image'].bytes_list.value
label = example.features.feature['label'].int64_list.value
# 可以做一些预处理之类的
print(image, label)
4. 使用队列读取tfrecords数据
从TFRecords文件中读取数据, 首先需要用tf.train.string_input_producer生成一个解析队列。之后调用tf.TFRecordReader的tf.parse_single_example解析器。其原理如下图:

解析器首先读取解析队列,返回serialized_example对象,之后调用tf.parse_single_example操作将Example协议缓冲区(protocol buffer)解析为张量。
def read_and_decode(filename):
# 根据文件名生成文件名队列
filename_queue = tf.train.string_input_producer([filename])
# 定义reader
reader = tf.TFRecordReader()
# 返回文件名和文件
_, serialized_example = reader.read(filename_queue)
# 将协议缓冲区Protocol Buffer解析为张量tensor
# 注意到:我们写文件就是采用了字典的方式进行存储的,所以解析的时候依然用字典进行数据提取
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw' : tf.FixedLenFeature([], tf.string),
})
# 将编码为字符串的变量重新变回来,因为写进tfrecord里用to_bytes的形式,也就是字符串
img = tf.decode_raw(features['img_raw'], tf.uint8)
# 检查张量形状是否对齐
img = tf.reshape(img, [224, 224, 3])
# 图像数据格式化为tf.float32
img = tf.cast(img, tf.float32) * (1. / 255) - 0.5
# 标签数据格式化为tf.int32
label = tf.cast(features['label'], tf.int32)
return img, label
之后,在训练模型过程中,我们就会很方便用这些数据了,例如:
# 解析tfrecords文件的数据
img, label = read_and_decode("train.tfrecords")
# 通过随机打乱张量的顺序创建batch
# capacity = ( min_after_dequeue + (num_threads + aSmallSafetyMargin * batch_size) )
img_batch, label_batch = tf.train.shuffle_batch(
[img, label], # 入队的张量列表
batch_size=30, # 进行一次批处理的tensor数
capacity=2000, # 队列中最大的元素数
min_after_dequeue=1000,# 一次出列操作完成后,队列中元素的最小数量
num_threads=4 #使用多个线程在tensor_list中读取文件
)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 队列-入栈线程启动器
threads = tf.train.start_queue_runners(sess=sess)
for i in range(3):
val, loss= sess.run([img_batch, label_batch])
三个要点作为总结:
- tensorflow里的graph能够记住状态,这使得TFRecordReader能够记住tfrecord的位置,并且始终能返回下一个。而这就要求我们在使用之前,必须初始化整个graph,这里使用了函数tf.global_variables_initializer()来进行初始化
- tensorflow中的队列和普通的队列差不多,不过它里面的operation和tensor都是符号型的,在调用sess.run()时才执行。
- TFRecordReader会一直弹出队列中文件的名字,直到队列为空
线程和队列
在使用TensorFlow进行异步计算时,队列是一种强大的机制。
正如TensorFlow中的其他组件一样,队列就是TensorFlow图中的节点。这是一种有状态的节点,就像变量一样:其他节点可以修改它的内容。具体来说,其他节点可以把新元素插入到队列后端(rear),也可以把队列前端(front)的元素删除。
为了感受一下队列,让我们来看一个简单的例子。我们先创建一个“先入先出”的队列(FIFOQueue),并将其内部所有元素初始化为零。然后,我们构建一个TensorFlow图,它从队列前端取走一个元素,加上1之后,放回队列的后端。慢慢地,队列的元素的值就会增加。

Enqueue、 EnqueueMany和Dequeue都是特殊的节点。他们需要获取队列指针,而非普通的值,如此才能修改队列内容。我们建议您将它们看作队列的方法。事实上,在Python API中,它们就是队列对象的方法(例如q.enqueue(...))。
队列使用概述
队列,如FIFOQueue和RandomShuffleQueue,在TensorFlow的张量异步计算时都非常重要。
例如,一个典型的输入结构:是使用一个RandomShuffleQueue来作为模型训练的输入:
- 多个线程准备训练样本,并且把这些样本推入队列。
- 一个训练线程执行一个训练操作,此操作会从队列中移除最小批次的样本(mini-batches)。
TensorFlow的Session对象是可以支持多线程的,因此多个线程可以很方便地使用同一个会话(Session)并且并行地执行操作。然而,在Python程序实现这样的并行运算却并不容易。所有线程都必须能被同步终止,异常必须能被正确捕获并报告,回话终止的时候, 队列必须能被正确地关闭。
所幸TensorFlow提供了两个类来帮助多线程的实现:tf.Coordinator和
tf.QueueRunner。从设计上这两个类必须被一起使用。Coordinator类可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常。QueueRunner类用来协调多个工作线程同时将多个张量推入同一个队列中。
创建队列
操作队列的函数主要有:
-
FIFOQueue():创建一个先入先出(FIFO)的队列
-
RandomShuffleQueue():创建一个随机出队的队列
-
enqueue_many():初始化队列中的元素
-
dequeue():出队
-
enqueue():入队
1、FIFOQueue
FIFOQueue是先进先出队列,主要是针对一些序列样本。如:在使用循环神经网络的时候,需要处理语音、文字、视频等序列信息的时候,我们希望处理的时候能够按照顺序进行,这时候就需要使用FIFOQueue队列。
#先入先出队列,初始化队列,设置队列大小5
q = tf.FIFOQueue(5,"float")
#入队操作
init = q.enqueue_many(([1,2,3,4,5],))
#定义出队操作
x = q.dequeue()
y = x + 1
#将出队的元素加1,然后再加入到队列中
q_in = q.enqueue([y])
#创建会话
with tf.Session() as sess:
sess.run(init)
#执行3次q_in操作
for i in range(3):
sess.run(q_in)
#获取队列的长度
que_len = sess.run(q.size())
#将队列中的所有元素执行出队操作
for i in range(que_len):
print(sess.run(q.dequeue()))

2、RandomShuffleQueue
RandomShuffleQueue是随机队列,队列在执行出队操作的时候,是以随机的顺序进行的。随机队列一般应用在我们训练模型的时候,希望可以无序的获取样本来进行训练,如:在训练图像分类模型的时候,需要输入的样本是无序的,就可以利用多线程来读取样本,将样本放到随机队列中,然后再利用主线程每次从随机队列中获取一个batch进行模型的训练。
#初始化一个随机队列,设置队列大小为10,最小长度为2
q = tf.RandomShuffleQueue(capacity=10,min_after_dequeue=2,dtypes="float")
#创建会话
with tf.Session() as sess:
#定义10次入队操作
for i in range(10):
sess.run(q.enqueue(i))
#定义8次出队操作
for i in range(8):
print(sess.run(q.dequeue()))
注意:在使用随机队列的时候,我们设置了队列的容量为10,最小长度为2。当队列的长度已经等于队列的容量(10)再执行入队操作, 或队列的长度已经等于最小长度(2)再执行出队操作时,程序会发生阻断,即程序在执行,但是没有任何输出,如下图:
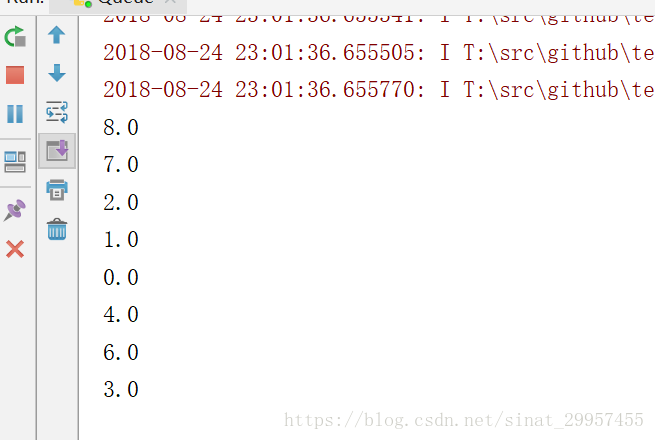
定义了10次出队操作,当队列出队8次之后,就被阻断了。我们可以通过设置会话在运行时的等待时间来解除阻断:
#初始化一个随机队列,设置队列大小为10,最小长度为2
q = tf.RandomShuffleQueue(capacity=10,min_after_dequeue=2,dtypes="float")
#创建会话
with tf.Session() as sess:
#定义10次入队操作
for i in range(10):
sess.run(q.enqueue(i))
#设置会话运行时等待时间,等待时长为5s
run_options = tf.RunOptions(timeout_in_ms=5000)
#定义10次出队操作
for i in range(10):
try:
#当队列进入阻断之后,超时就抛出异常
print(sess.run(q.dequeue(),options=run_options))
except tf.errors.DeadlineExceededError:
print("out of range")
#退出循环
break

当队列出队第9次的时候,进入阻断状态时,我们可以通过DeadlineExceededError来捕获阻断信息。
Coordinator
Coordinator类用来帮助多个线程协同工作,多个线程同步终止。
其主要方法有:
should_stop():如果线程应该停止则返回True。request_stop(<exception>): 请求该线程停止。join(<list of threads>):等待被指定的线程终止。
首先创建一个Coordinator对象,然后建立一些使用Coordinator对象的线程。这些线程通常一直循环运行,一直到should_stop()返回True时停止。
任何线程都可以决定计算什么时候应该停止。它只需要调用request_stop(),同时其他线程的should_stop()将会返回True,然后都停下来。
# 线程体:循环执行,直到`Coordinator`收到了停止请求。
# 如果某些条件为真,请求`Coordinator`去停止其他线程。
def MyLoop(coord):
while not coord.should_stop():
...do something...
if ...some condition...:
coord.request_stop()
# Main code: create a coordinator.
coord = Coordinator()
# Create 10 threads that run 'MyLoop()'
threads = [threading.Thread(target=MyLoop, args=(coord)) for i in xrange(10)]
# Start the threads and wait for all of them to stop.
for t in threads: t.start()
coord.join(threads)
QueueRunner
QueueRunner类会创建一组线程, 这些线程可以重复的执行Enquene操作, 他们使用同一个Coordinator来处理线程同步终止。此外,一个QueueRunner会运行一个_closer thread_,当Coordinator收到异常报告时,这个_closer thread_会自动关闭队列。
您可以使用一个queue runner,来实现上述结构。
首先建立一个TensorFlow图表,这个图表使用队列来输入样本。增加处理样本并将样本推入队列中的操作。增加training操作来移除队列中的样本。
example = ...ops to create one example...
# Create a queue, and an op that enqueues examples one at a time in the queue.
queue = tf.RandomShuffleQueue(...)
enqueue_op = queue.enqueue(example)
# Create a training graph that starts by dequeuing a batch of examples.
inputs = queue.dequeue_many(batch_size)
train_op = ...use 'inputs' to build the training part of the graph...
在Python的训练程序中,创建一个QueueRunner来运行几个线程, 这几个线程处理样本,并且将样本推入队列。创建一个Coordinator,让queue runner使用Coordinator来启动这些线程,创建一个训练的循环, 并且使用Coordinator来控制QueueRunner的线程们的终止。
# Create a queue runner that will run 4 threads in parallel to enqueue
# examples.
qr = tf.train.QueueRunner(queue, [enqueue_op] * 4)
# Launch the graph.
sess = tf.Session()
# Create a coordinator, launch the queue runner threads.
coord = tf.train.Coordinator()
enqueue_threads = qr.create_threads(sess, coord=coord, start=True)
# Run the training loop, controlling termination with the coordinator.
for step in xrange(1000000):
if coord.should_stop():
break
sess.run(train_op)
# When done, ask the threads to stop.
coord.request_stop()
# And wait for them to actually do it.
coord.join(threads)
异常处理
通过queue runners启动的线程不仅仅只处理推送样本到队列。他们还捕捉和处理由队列产生的异常,包括OutOfRangeError异常,这个异常是用于报告队列被关闭。
使用Coordinator的训练程序在主循环中必须同时捕捉和报告异常。
下面是对上面训练循环的改进版本。
try:
for step in xrange(1000000):
if coord.should_stop():
break
sess.run(train_op)
except Exception, e:
# Report exceptions to the coordinator.
coord.request_stop(e)
# Terminate as usual. It is innocuous to request stop twice.
coord.request_stop()
coord.join(threads)















 4326
4326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









