







Scrapy的安装流程:
1. 安装Python2.xx 如Python2.7.9
需要将python.exe 以及python/Scripts添加到系统环境变量
2.安装pip(高级点的Python版本都自带,不需要安装)
2.安装pywin32-219.win32-py2.7
3.安装lxml-3.2.2.win32-py2.7.exe
4.安装pyOpenSSL :在dos窗口中输入pip install pyOpenSSL 自动安装
5.安装Scrapy: 在dos窗输入:pip install Scrapy 自动安装
进行网络爬虫的步骤:
在dos 命令窗中输入:scrapy startproject folder 建一个Scrapy的框架,会形成一个文件夹目录,例如文件夹名为tutorial则生成的文件夹目录为:
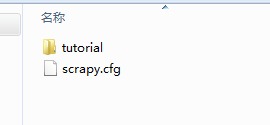
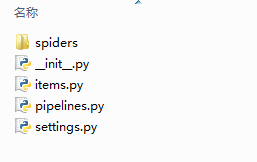
其中需要关注的是items.py,这个是接收网络爬虫返回数据的文件,在里面可以定义接收值的字段
例如:
class DmozItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
然后需要在spiders文件夹目录中编写爬虫程序:
建一个.py文件,实现网页内容获取的代码:
例子如下:
# -*- coding:utf-8 -*-
import scrapy
from tutorial.items import DmozItem
# 定义一个爬虫类
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ['dmoz.org'] # 限制爬虫的活动域名
start_urls = [
'http://www.dmoz.org/Computers/Programming/Languages/Python/Books/',
'http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/'
]
# 具体的爬取操作
def parse(self,response):
sel = scrapy.selector.Selector(response)
sites = sel.xpath('//ul[@class="directory-url"]/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.xpath('a/text()').extract()
item['link'] = site.xpath('a/@href').extract()
item['desc'] = site.xpath('text()').extract()
items.append(item)
return items
代码编写完成后就可以在dos窗中输入如下命令运行整个爬虫程序:
在命令行执行的命令是: scrapy crawl dmoz -o items.json -t json
dmoz 是爬虫的名字
-o 是输出文件命令
-t 是输出格式命令
常用的有四种格式:
json
xml
csv
jsonlines















 61万+
61万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









