







What is OLAP and OLTP?
OLTP stands for Online Transaction Processing (OLTP) while OLAP stands for Online Analytic Processing (OLAP). The main difference is their target. Both of them are two types of database.
OLTP is designed for transactions (Insert, Access, or modify a limited number of rows) in ACID properties. Performance is measured in number of transactions per second. In an OLTP system data are frequently updated and queried. So a fast response to a request is required. Since OLTP systems involve a large number of update queries, the database tables are optimized for write operations[1].
OLAP is designed for analysis. Therefore, the queries in OLAP are mostly multi-dimension queries like join and aggregation. Data in OLAP is commonly organized in star-like schema. OLAP (Online Analytical Processing) deals with historical data or archival data. Historical data are those data that are archived over a long period of time. Data from OLTP are collected over a period of time and stored in a very large database called a Data Warehouse [1].
看过一个很好的比喻,数据仓库好比是粮仓,数据好比是大米。一袋袋装着的大米(OLTP)堆在一起组成了粮仓。但是这个比喻的不足一袋袋的大米可以经常更新,而数据仓库的数据经常是一个月才同步一次。
What is star-like schema?
There must be a centre table(fact tables) and other dimension tables in a star-like schema. Here is a good picture to state this[1]:
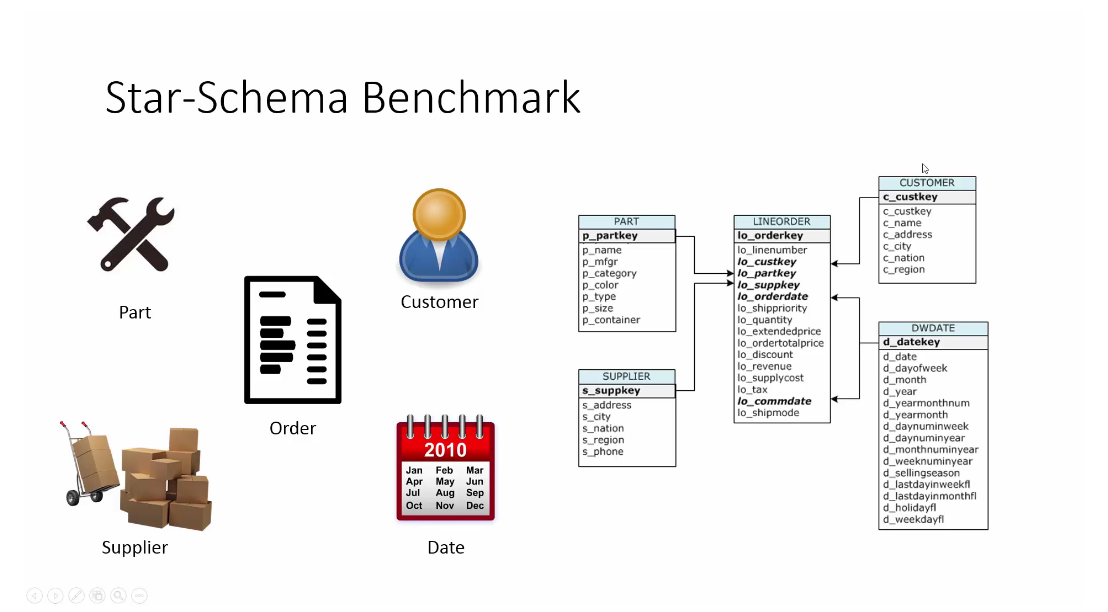
Line order is the fact table while the other tables are dimension table.
Data warehouses are highly optimized for read and aggregation (SELECT) operation.
OLAP queries are of analytical form, meaning that they need to access a large amount of data and require many aggregations. It accesses a large number of records from database tables and performs filtering and aggregations on the required columns[1].
Hive/ Impala and Redshift
1) Hive
Hive is built on top of Hadoop and facilitates querying and managing large amount of data stored in Hadoop's HDFS and other compatible file systems such as Amazon S3 [1]. Hive has the ability of transforming the SQL command into map-reduce job. Users are not required to write a map-reduce job by themselves to make a query. However, since Hive was designed to use the MapReduce framework to finish the query, it is by design heavyweight and high-latency. It's mostly used for batch processing [1].
Hive is designed to make query in a big dataset which is stored in HDFS (make it really huge, with fault-tolerance and scalable).
Here is a good picture to stated the architecture[1]:
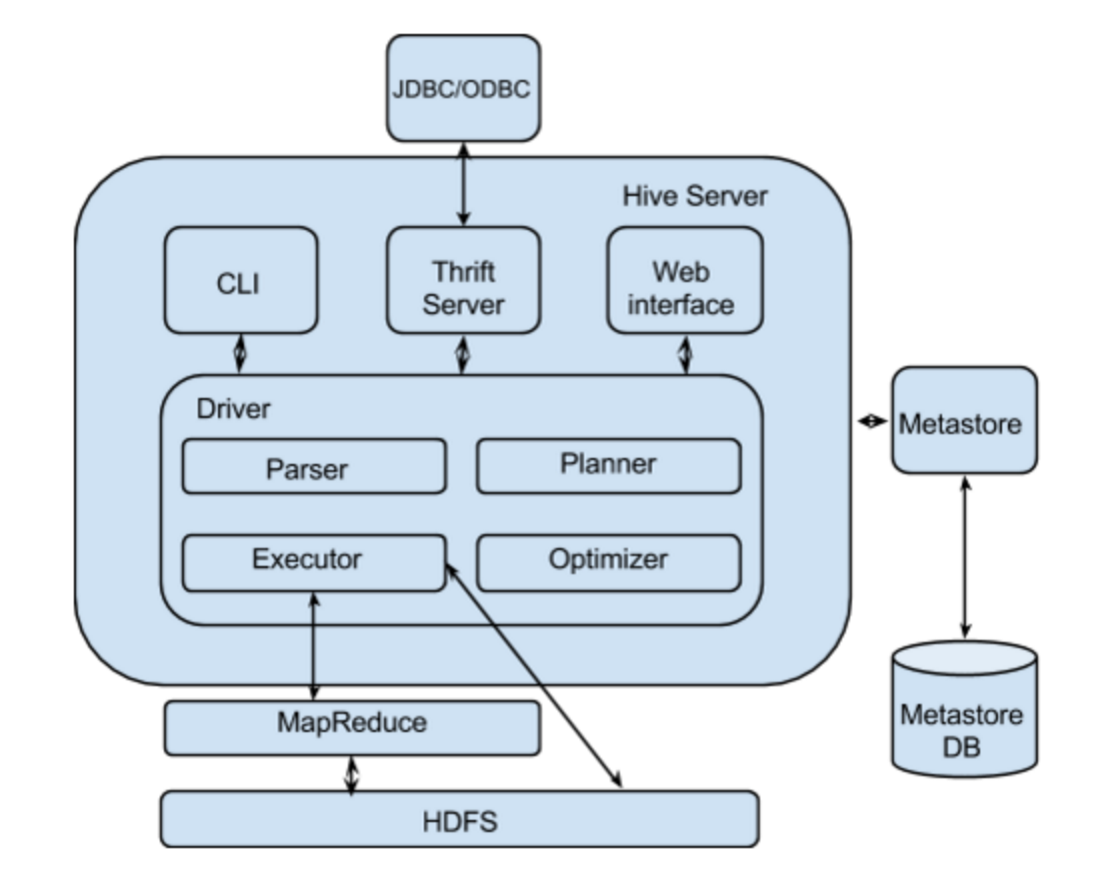
The Hive server has a SQL parser, planner, executor and optimizer that will transform the SQL query to a MapReduce job that runs on top of Hadoop and HDFS. The Hive metastore service stores the metadata for Hive tables and partitions in a relational database, and provides clients (including Hive) access to this information via the metastore service API. The metadata contains information like IDs of database, IDs of tables, IDs of index, the time of creation of an index, the time of creation of a table, IDs of roles assigned to a particular user, inputFormat used for a Table, OutputFormat used for a Table and etc [1].
Hive uses HiveQL. The difference between HiveQL and SQL can see: http://hortonworks.com/hadoop/hive/#section_5
2) Impala
While retaining a familiar user experience as Hive, Impala provides high performance real-time SQL queries on Apache Hadoop. Instead of using MapReduce, Impala leverages a massively parallel processing (MPP) engine similar to that found in traditional relational database management systems (RDBMS). It is a brand-new engine written in both C++ and Java. With this architecture, you can query your data in HDFS (or HBase tables) very quickly, and leverage Hadoop's ability to process diverse data types and provide schema at runtime. It is so far the fastest SQL-on-Hadoop system, especially for multi-user scenarios (where multiple users are querying the warehouse at the same time) [1].
Here we can see a brief architecture of Impala[1].
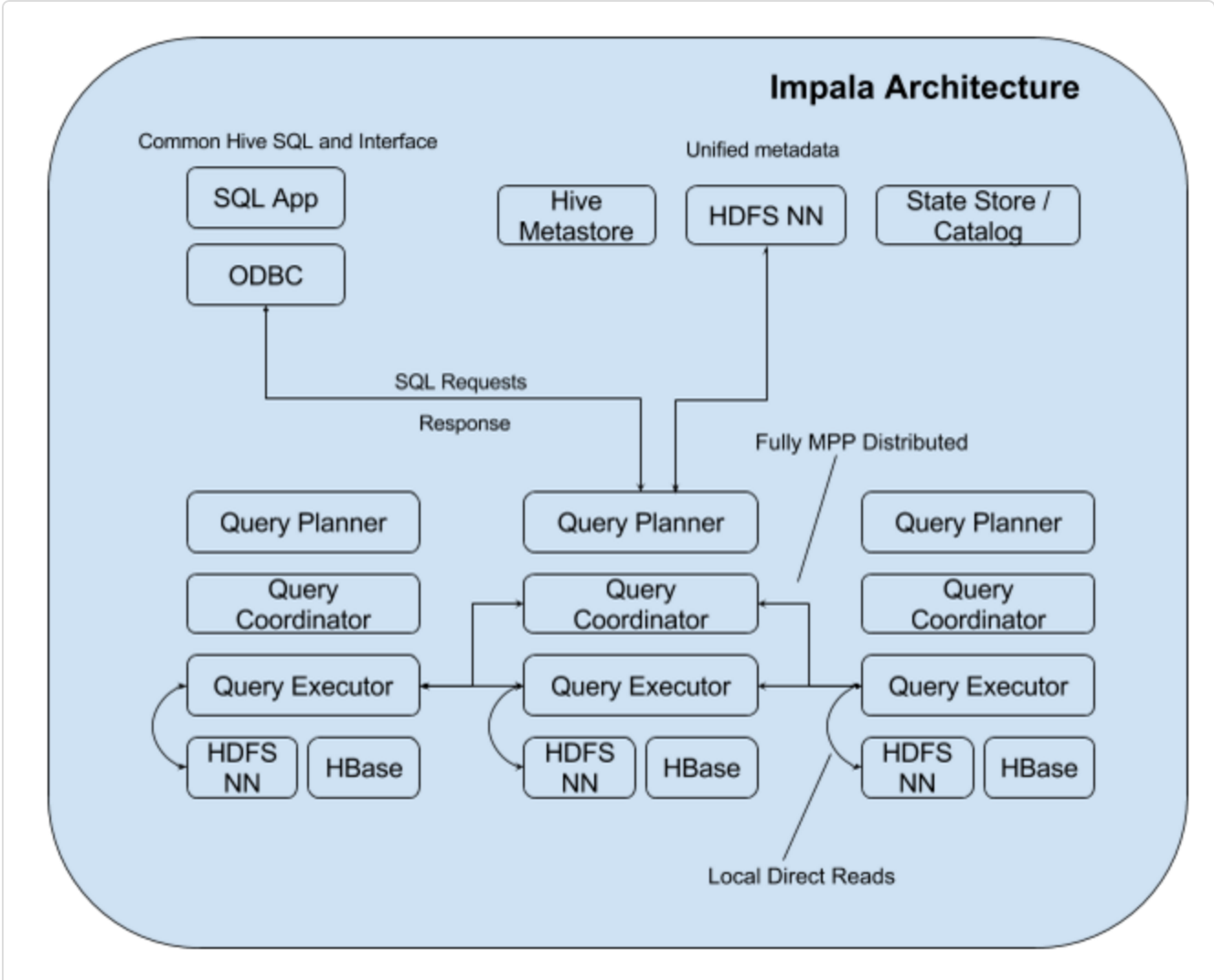
About the MPP, here are some basic concepts [1]:
It consists of different daemon processes that run on specific hosts within your EMR cluster.
The Impala Daemon
Impala Daemon process is the core component of the Impala Cluster. Each DataNode of the cluster has a daemon process running on top of it, which is represented by the impalad process. The daemon process accepts queries transmitted from the user application through JDBC, ODBC, impala-shell command etc. It then parallelizes the queries, distributes the work to other DataNodes across the cluster, and transmits intermediate query results back to the central coordinator node that receives the query. Once the aggregations are completed on the coordinator, the final result will be returned to the user. The instance of the daemon process that receives the query serves as the coordinator node for that query. The coordinator could be selected randomly or in a round-robin manner. All DataNodes in the cluster are all symmetric so any one of the nodes can be the coordinator for any query.
The Impala daemons are in constant communication with the statestore, to confirm which nodes are healthy and can accept new work. Broadcast messages from the catalogd daemon are also received whenever any metadata is changed.
The Impala Statestore
The statestore the component of the Impala server which constantly checks on the health state of Impala daemons on all the DataNodes in a cluster, and relays the updates to all those daemons. The statestore is represented by a daemon process called statestored. Only one such process is needed in the whole cluster. If any nodes of the cluster go offline due to network error, software issue or hardware failure, the statestore notifies all the other Impala daemons so that future queries will not be propagated to those unreachable nodes.
The Impala Catalog Service
Impala Catalog service takes care of any changes of the metadata in the cluster. It relays the metadata changes from Impala SQL statements to all the DataNodes in a cluster.The Catalog service exists as a daemon process named catalogd. Like the statestore, only one such process is needed on one host in the cluster. Because the requests are passed through the statestore daemon, it makes sense to run the statestored and catalogd services on the same host.
3) Redshift [1]
Amazon Redshift is fully managed by AWS and it runs on top of EC2 with optimizations such as locally attached storage, high bandwidth interconnect across compute nodes and so on.
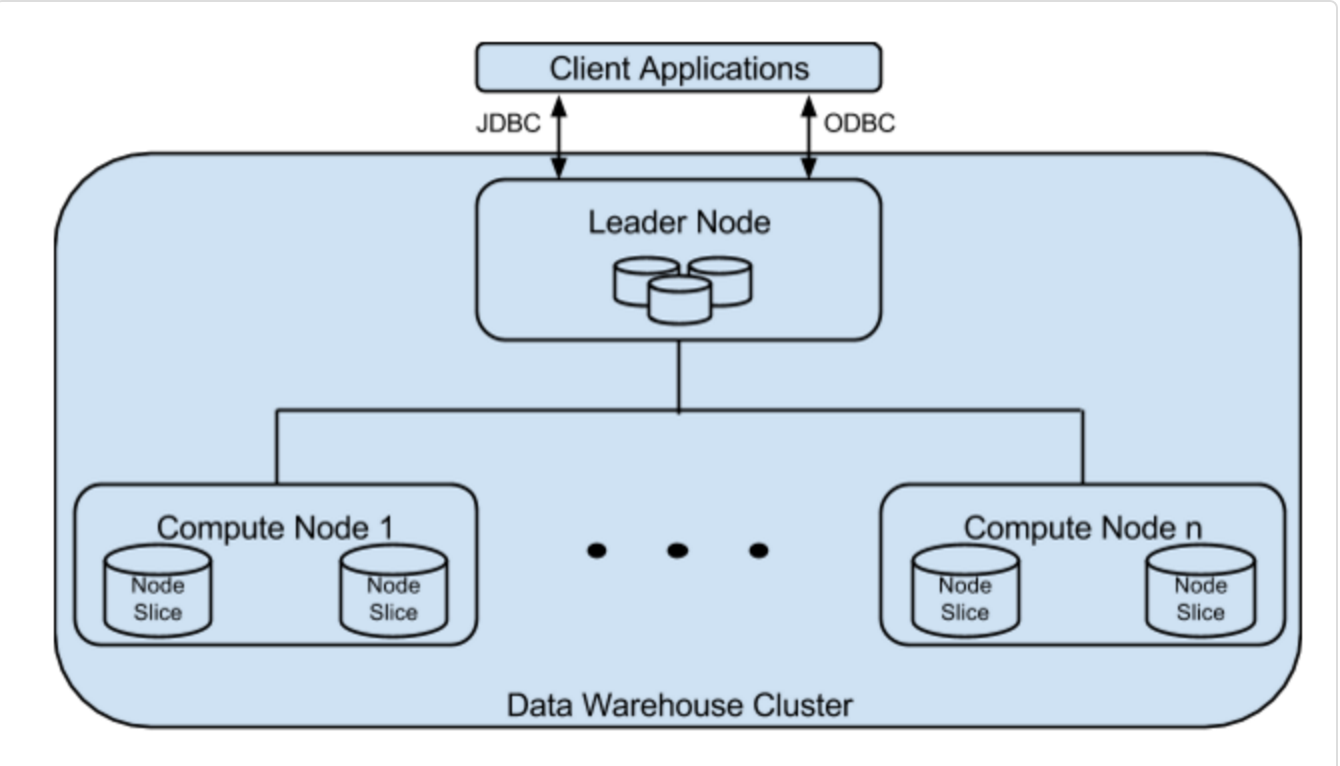
Leader Node
The leader node manages communications with client programs and all communication with compute nodes. It parses and develops execution plans to carry out database operations. An execution plan conists of the series of steps necessary to obtain results for a complex query. Based on the execution plan, the leader node compiles code, distributes the compiled code to the compute nodes, and assigns a portion of the data to each compute node.
Compute Nodes
The leader node compiles code for individual elements of the execution plan and assigns the code to individual compute nodes. The compute nodes execute the compiled code and send intermediate results back to the leader node for final aggregation. Each compute node has its own dedicated CPU, memory, and attached disk storage, which are determined by the node type.
Node Slices
A compute node is partitioned into slices; one slice for each core of the node's multi-core processor. Each slice is allocated a portion of the node's memory and disk space, where it processes a portion of the workload assigned to the node. The leader node manages distributing data to the slices and assigns the workload for any queries or other database operations to the slices. The slices then work in parallel to complete the operation.
When you create a table, you can optionally specify one column as the distribution key. When the table is loaded with data, the rows are distributed to the node slices according to the distribution key that is defined for a table. Choosing a good distribution key enables Amazon Redshift to use parallel processing to load data and execute queries efficiently.
Reference:
[1] CMU 15619 Cloud Computing















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









