







 本篇博客深入探讨了逻辑回归模型,用于解决二分类问题,对比了线性回归并介绍了逻辑回归的Sigmoid转换。同时,文章详细阐述了如何使用最大似然函数来推导逻辑回归的最优参数,通过梯度下降法进行参数更新,并解释了最大似然估计的基本思想及其在求解模型参数中的应用。
本篇博客深入探讨了逻辑回归模型,用于解决二分类问题,对比了线性回归并介绍了逻辑回归的Sigmoid转换。同时,文章详细阐述了如何使用最大似然函数来推导逻辑回归的最优参数,通过梯度下降法进行参数更新,并解释了最大似然估计的基本思想及其在求解模型参数中的应用。
(本章节介绍逻辑回归模型及如何使用似然函数推导最优参数,并在最后介绍什么是最大似然算法;下一章节将介绍如何使用牛顿法求解参数及代码展示)
逻辑回归属于分类问题中的一种,与线性回归问题不同的是,逻辑回归的输出是有限个离散值,而线性回归的输出是连续型数值。首先我们关注二分类问题,可以考虑这样的实际应用场景,如判断邮件是否是垃圾邮件,判断肿瘤是是否是恶性肿瘤,网上购物商城根据用户购买记录预测用户是否会点击特定商品等等问题。
对于二分类问题,定义输出类别标签 y∈{ 0,1} ,即当 y=0 时,表示数据属于负样本,否则数据属于正样本。最直接的想法是使用前面介绍的线性回归模型对数据建模,当输出大于某个阈值时,认为是负样本,否则认为数据是正样本。这样设计很容易存在问题,首先线性回归的输出不仅局限在 [0,1] 的,其次很容易受到数据分布的影响,如下图,因为孤立数据的影响,导致分界面的偏移,部分数据无法正确分类。
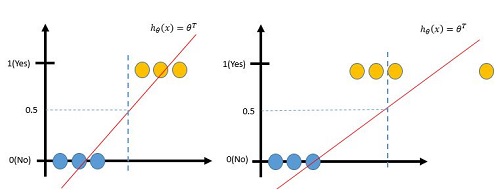
1.1逻辑回归
由此,我们引入逻辑回归问题,主要形式为,
其中 g(z) 为sigmoid函数,值域为 [0,1] ,所以 hθ(x) 的输出范围被控制在 [0,1] 内。
sigmoid函数 g(z) 的基本形式 g(z)=11+e−z ,其数据分布为,
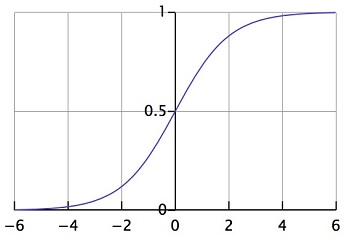
这样,对于分类问题,当有输出 hθ(x)>0.5 时,预测分类值为 y=1 ,否则,有预测值为 y=0 。也就是说,当 θTx>0 时,预测分类为1,当 θTx<0 时,预测分类为0。由此可以看出,参数 θ 控制分类界面。
接下来,我们将使用最大似然函数的思想求解最优参数 θ 值。
1.2参数 θ 求解
数据的分布模型我们已经定义好了,那么接下来的问题是给定输入数据 x 和标签数据
我们假设数据之间采样是独立的,且数据分布满足,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









