







人岗智能匹配系统(上)
- 项目概述
- 搭建大数据环境
- 数据采集
- 数据预处理
- 数据存储
- 数据分析
- 数据可视化
人岗智能匹配系统的设计与实现
摘 要
企业招聘需求日益多元化、精细化,招聘服务的开展难度正面临日益严峻的挑战。通过自然语言处理、机器学习等技术手段,建立海量企业招聘岗位画像、个人用户画像,在人才推荐、岗位推荐等方向提供数据智能服务,从而提高企业人才招聘效率。
本系统的功能包括用户管理功能和人岗匹配功能,用户管理功能是系统的基本功能,包括用户注册和用户登录,用户分为个人求职者和企业招聘人员;人岗匹配功能是系统的核心功能,用户注册成功后,需要填写相关简历(或招聘)信息;个人求职者登录成功以后,系统计算出用户最适合的岗位匹配率前20的岗位呈现给该用户,由该用户根据自己个人喜好对岗位提出申请;企业招聘人员登录成功后,系统调用系统自动随机挑选适合岗位需求的求职者推荐给该用户,用户可以从网页中查看企业招聘岗位画像、个人用户画像。
关键词:人岗匹配;自然语言处理;机器学习;数据可视化
目 录
1 项目概述 1
1.1 项目需求和目标 1
1.2 项目架构设计及技术选取 1
2 搭建大数据集群环境 1
2.1 安装准备 1
2.1.1 系统版本 1
2.1.2 网络配置 2
2.2 安装和配置组件环境 2
2.2.1 配置ssh无密码登录 2
2.2.2 jdk安装与配置 3
2.2.3 安装 hadoop完全分布式 3
2.2.4 spark搭建与安装 10
2.2.5 安装scala 11
2.2.6 python3 12
2.2.7 mysql 12
2.2.8 flume 12
2.2.9 zookeeper 15
2.2.10 kafka 17
3 数据采集 17
3.1 已有数据采集 17
4 数据预处理 19
4.1 求职者基本信息:person.csv 19
4.2 求职意向:person_cv.csv 23
4.3 工作经历:person_job_hist.csv 26
4.4 专业证书:person_pro_cert 28
4.5 项目经验:person_project.csv 29
4.6 招聘岗位信息:recruit.csv 33
4.6.1 数据变化 33
4.6.2 数据清洗 34
5 数据存储 34
5.1 数据库版本 35
5.2 数据库设计 35
6 特征工程 41
6.1 特征提取 41
6.2 合并特征 42
6.3 输出特征 42
7 模型训练 43
6.1 模型选择 43
6.2 划分数据集 43
6.3 模型调参 44
6.4 模型预测 44
6.5 模型评估 44
8 数据可视化 45
8.1 招聘者工作经验以及其中一年经验以下年龄分布 46
8.2 个人和企业学历 46
8.3 企业对于专业要求 47
8.4 行业 47
8.5 地域分布 48
8.6 词云 48
9 系统实现 49
9.1 Flask简介 49
9.2 导入所需的包 49
9.3 初始化配置 49
9.4 mysql数据库 50
9.4.1 使用SQLAlchemy连接数据库 50
9.4.2 使用flask_sqlalchemy 50
9.5 Session会话对象 51
9.5.1 Session的定义 51
9.5.2 对Session的操作 51
9.6 各模块效果图及重要代码 52
9.6.1 父模板及首页 52
9.6.2 登录及注册 52
9.6.3 岗位推荐 54
10 总结 56
1 项目概述
1.1 项目需求和目标
在线招聘服务的产生与发展不断冲击着就业市场上的传统招聘模式。如今,互联网上存在着数亿规模的求职者简历以及岗位招聘信息。如此大规模的数据给互联网招聘带来了新的挑战:如何能够自动并准确地将合适的岗位描述文档与简历文档相匹配,以便高效地将合适的人才配置到与之相应的岗位上。因此,学习并构建完善的人岗自动匹配推荐系统显得十分重要,这既有助于招聘人员找到合适的候选人,也有助于求职者能够找到合适的岗位。现有针对人岗匹配推荐问题的研究通常集中在学习简历文档以及岗位描述文档自身的表示后计算双方的匹配度。
本文的目标是给定一个求职者和一个招聘岗位作为输入,去预测求职者与招聘岗位之间的匹配分数,从而判断将求职者推荐给该岗位是否合适。
1.2 项目架构设计及技术选取
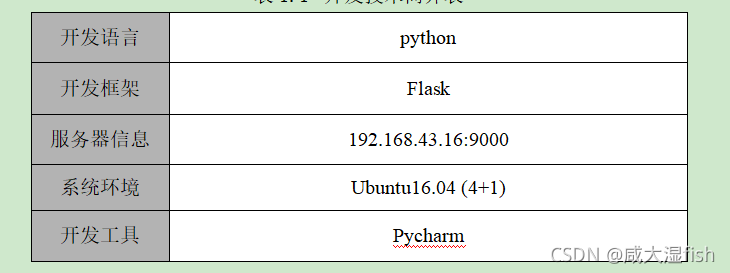
2 搭建大数据集群环境
2.1 安装准备
2.1.1 系统版本
Master:ubuntu 16.04
Slaves:ubuntu 20.04
2.1.2 网络配置
192.168.43.16 master
192.168.43.247 slave1
192.168.43.188 slave2
192.168.43.166 slave3
192.168.43.164 slave4
2.2 安装和配置组件环境
2.2.1 配置ssh无密码登录
(1)在 master 节点,用 hadoop 用户登录,在其主目录里使用 ssh-keygen 产生公钥与私钥对。输入命令“ssh-keygen -t rsa”,
接着按三次 Enter 键。 ssh-keygen 用来生成 RSA 类型的密钥以及管理该密钥,
参数“-t”用于指定要创建的 SSH 密钥的类型为 RSA。
在~/.ssh 目录里生成私有密钥 id_rsa 和公有密钥 id_rsa.pub 两个文件。
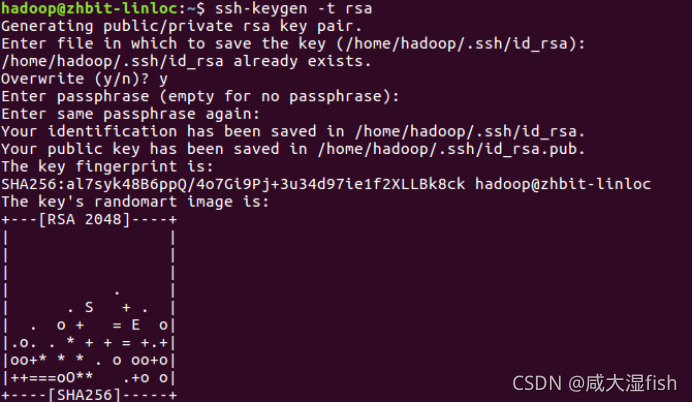
(2)用 ssh-copy-id 命令将生成的公钥 id_rsa.pub 复制到远程机器 master、slave1、slave2、slave3 中。
ssh-copy-id –i ~/.ssh/id_rsa.pub master
ssh-copy-id –i ~/.ssh/id_rsa.pub slave1
ssh-copy-id –i ~/.ssh/id_rsa.pub slave2
ssh-copy-id –i ~/.ssh/id_rsa.pub slave3
ssh-copy-id –i ~/.ssh/id_rsa.pub slave4
2.2.2 jdk安装与配置
配置~/.bashrc

查看版本

2.2.3 安装 hadoop完全分布式
2.2.3.1 hadoop版本
Hadoop2.6.5
2.2.3.2 解压
tar -zxf hadoop-2.6.5.tar.gz -C ~/tools
2.2.3.3 修改配置文件
修改 Hadoop 安装目录下的 etc/hadoop 目录里的如下配置文件:
1)hadoop-env.sh 文件
将 hadoop-env.sh 文件中的 JAVA_HOME 修改为前面安装 JDK 的目录。

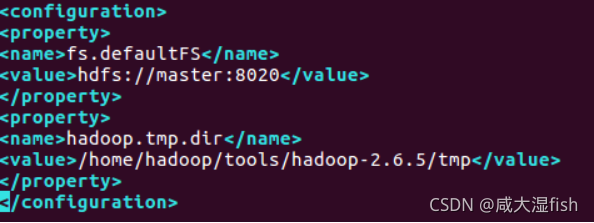
2)core-site.xml 文件
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
/home/hadoop/tools/hadoop-2.6.5/tmp
先在/home/hadoop/hadoop-2.6.5/下创建目录 tmp
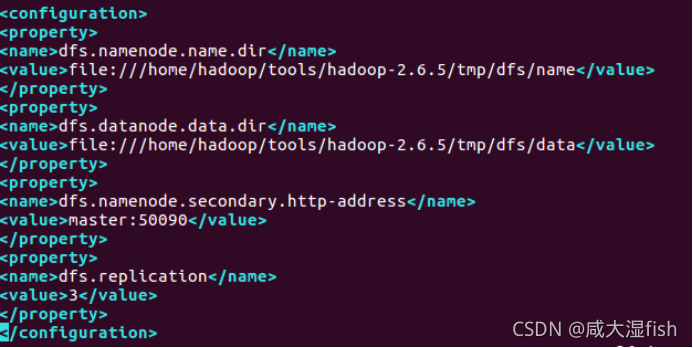
3)hdfs-site.xml 文件
dfs.namenode.name.dir
file:///home/hadoop/tools/hadoop-2.6.5/tmp/dfs/name
dfs.datanode.data.dir
file:///home/hadoop/tools/hadoop-2.6.5/tmp/dfs/data
dfs.namenode.secondary.http-address
master:50090
dfs.replication
3
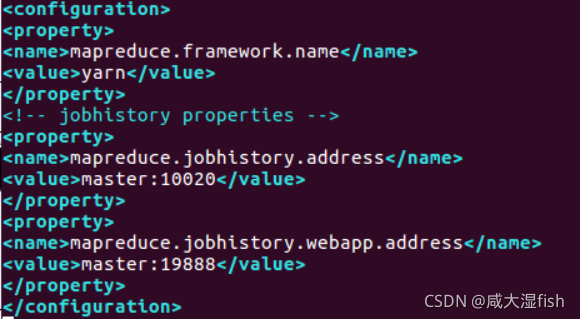
4)mapred-site.xml 文件
复制或重命名 cp mapred-site.xml.template mapred-site.xml
修改 mapred-site.xml 文件:
mapreduce.framework.name
yarn
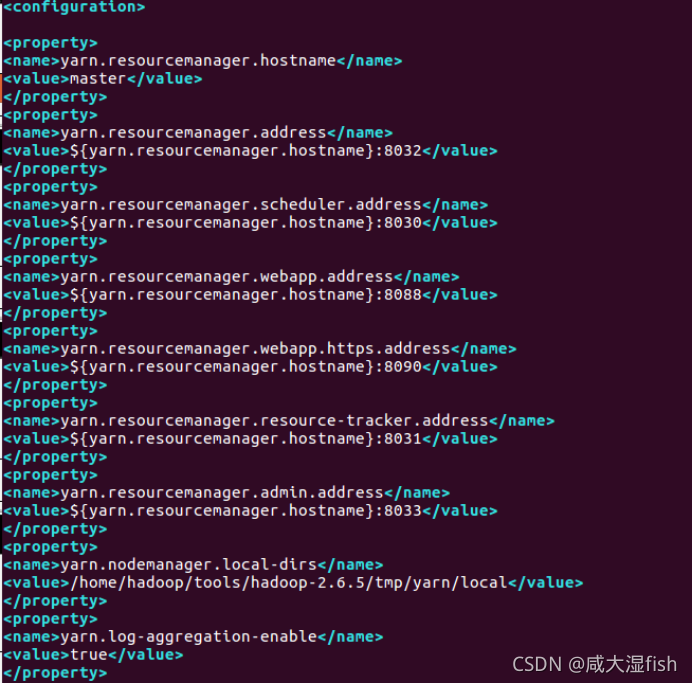
5)yarn-site.xml 文件
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
y
a
r
n
.
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
.
h
o
s
t
n
a
m
e
:
8032
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
p
r
o
p
e
r
t
y
>
<
n
a
m
e
>
y
a
r
n
.
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
.
s
c
h
e
d
u
l
e
r
.
a
d
d
r
e
s
s
<
/
n
a
m
e
>
<
v
a
l
u
e
>
{yarn.resourcemanager.hostname}:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>
yarn.resourcemanager.hostname:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>{yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address
y
a
r
n
.
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
.
h
o
s
t
n
a
m
e
:
8088
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
p
r
o
p
e
r
t
y
>
<
n
a
m
e
>
y
a
r
n
.
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
.
w
e
b
a
p
p
.
h
t
t
p
s
.
a
d
d
r
e
s
s
<
/
n
a
m
e
>
<
v
a
l
u
e
>
{yarn.resourcemanager.hostname}:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address</name> <value>
yarn.resourcemanager.hostname:8088</value></property><property><name>yarn.resourcemanager.webapp.https.address</name><value>{yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
y
a
r
n
.
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
.
h
o
s
t
n
a
m
e
:
8031
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
p
r
o
p
e
r
t
y
>
<
n
a
m
e
>
y
a
r
n
.
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
.
a
d
m
i
n
.
a
d
d
r
e
s
s
<
/
n
a
m
e
>
<
v
a
l
u
e
>
{yarn.resourcemanager.hostname}:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>
yarn.resourcemanager.hostname:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>{yarn.resourcemanager.hostname}:8033
yarn.nodemanager.local-dirs
/home/hadoop/tools/hadoop-2.6.5/tmp/yarn/local
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/home/hadoop/tools/hadoop-2.6.5/tmp/yarn/logs
yarn.log.server.url
http://master:19888/jobhistory/logs/
URL for job history server
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.memory-mb
2048
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
mapreduce.map.memory.mb
2048
mapreduce.reduce.memory.mb
2048
yarn.nodemanager.resource.cpu-vcores
1
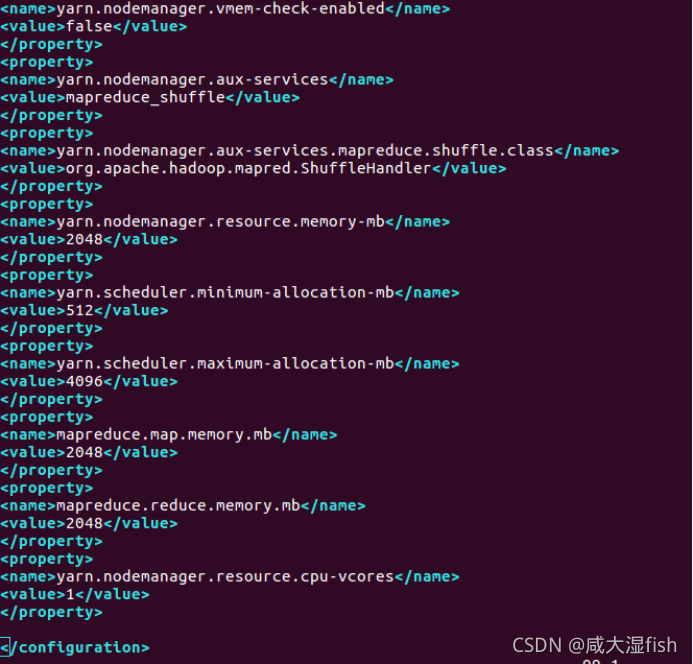
(6)yarn-env.sh 文件
在 yarn-env.sh 文件增加 JAVA_HOME 变量,为前面安装 JDK 的目录。
export JAVA_HOME=/home/hadoop/tools/jdk2.8.0_221

(7)masters 和 slaves 文件
(masters 文件是配置运行第二 namenode 的机器列表,每行一个,默认与namenode 在同一机器,这里不配置此文件)
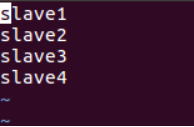
修改 slaves 文件如下:
删除 localhost,添加:
slave1
slave2
slave3
slave4
2.3.3.4 从主节点向集群中从节点复制 hadoop
scp -r /home/hadoop/tools/hadoop-2.6.5 slave1:/home/hadoop/tools
scp -r /home/hadoop/tools/hadoop-2.6.5 slave2:/home/hadoop/tools
scp -r /home/hadoop/tools/hadoop-2.6.5 slave3:/home/hadoop/tools
2.3.3.5 格式化 Hadoop 完全分布式集群
运行 Hadoop 安装目录下的 bin 目录里的 hdfs 命令进行格式化,如下:
./hdfs namenode -format
2.2.4 spark搭建与安装
2.2.4.1解压包
通过集群脚本分别传输到slave机器上, 并且解压.
#!/bin/bash
需要安装的机器(也可以从配置文件读取)
cluster_nodes=“master,slave1,slave2,slave3,slave4”
cluster_nodes=${cluster_nodes//,/ }
安装名字
app_tar_name=“spark-2.4.0-bin-hadoop2.6.tgz”;
安装目录
install_folder="/home/hadoop/tools/spark"
循环所有的结点
for i in ${cluster_nodes}; do
make dir
ssh hadoop@${i} "mkdir -p ${install_folder};"
tar -zxvf spark-2.4.0-bin-hadoop2.6.tgz
分发
scp ${app_tar_name} hadoop@${i}:${install_folder}/
解压
ssh hadoop@${i} "cd ${install_folder};tar -zxvf spark-2.4.0-bin-hadoop2.6.tgz; mv spark-2.4.0-bin-hadoop2.6.tgz spark-2.4.0;"
done
2.2.4.2 更改spark-env.sh与slaves文件并分发到四台机器上.
spark-env.sh
export SPARK_MASTER_IP=192.168.43.16
export SPARK_WORKER_MEMORY=1g
export SPARK_EXECUTOR_CORES=2
export master=spark://192.168.43.16:7077
slaves
A Spark Worker will be started on each of the machines listed below.
slave1
slave2
slave3
slave4
传输配置文件(此操作可以在脚本内完成)
scp spark-env.sh hadoop@master:/home/hadoop/spark/spark-2.4.0/conf/
scp spark-env.sh hadoop@slave1:/home/hadoop/spark/spark-2.4.0/conf/
scp spark-env.sh hadoop@slave2:/home/hadoop/spark/spark-2.4.0/conf/
scp spark-env.sh hadoop@slave3:/home/hadoop/spark/spark-2.4.0/conf/
scp spark-env.sh hadoop@slave4:/home/hadoop/spark/spark-2.4.0/conf/
scp slaves root@master:/home/hadoop/spark/spark-2.4.0/conf/
scp slaves root@slave1:/home/hadoop/spark/spark-2.4.0/conf/
scp slaves root@slave2:/home/hadoop/spark/spark-2.4.0/conf/
scp slaves root@slave3:/home/hadoop/spark/spark-2.4.0/conf/
scp slaves root@slave4:/home/hadoop/spark/spark-2.4.0/conf/
2.2.4.3: 通过start-all.sh脚本启动Spark集群.
2.2.4.4: 通过访问master节点的8080端口进行访问.
http://192.168.43.16:8080
2.2.5 安装scala
配置~/.bashrc


2.2.6 python3

2.2.7 mysql
2.2.8 flume
配置flume-to-spark文件
#flume-to-spark.conf: A single-node Flume configuration
# Name the components on this agent
A1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 33333
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port =44444
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
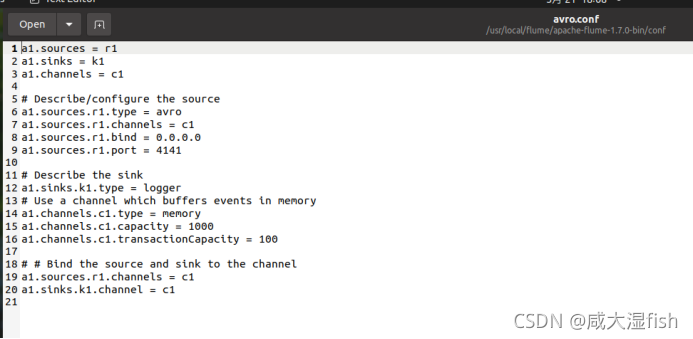
对 avro.conf 文件进行编辑
2.2.9 zookeeper
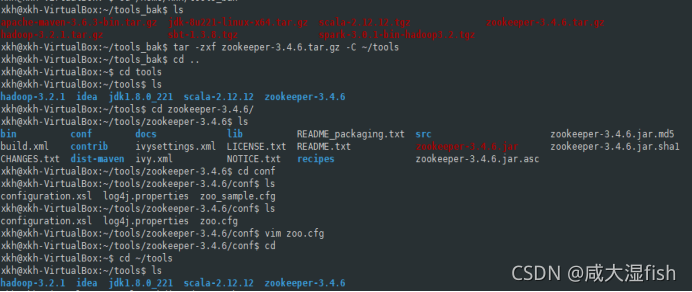
进入conf目录
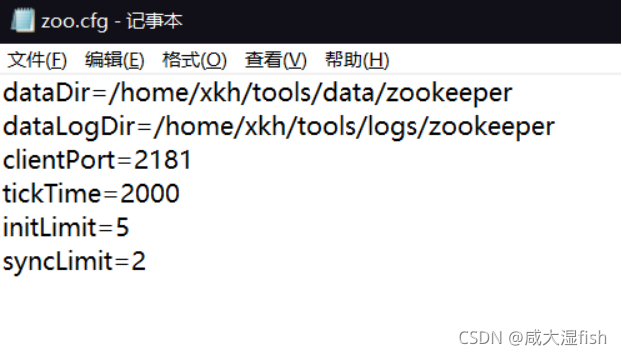
修改zoo.cfg(由zoo_sample.cfg 修改得到)
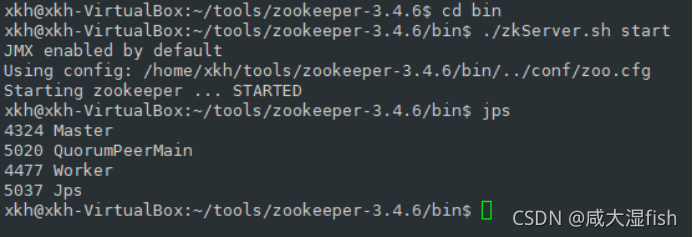
3 数据采集
3.1 已有数据采集
数据下载:https://www.sodic.com.cn/competitions/900008/datasets?utm_referer=sodic
数据简介: 数据为一段时期内单位收藏、处理的简历以及求职者投递的简历,数据已做脱敏处理。
数据来源: 深圳市人才集团有限公司
数据类型说明:
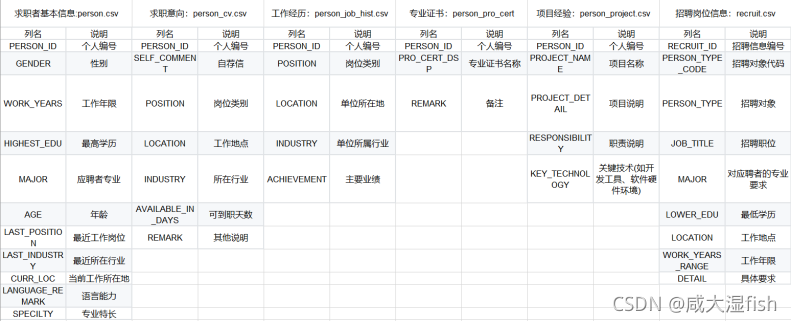
4 数据预处理
4.1 求职者基本信息:person.csv
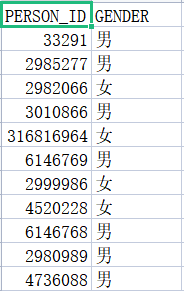
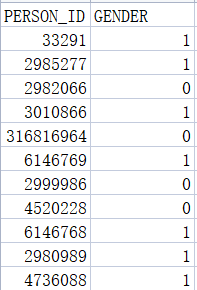
对“GENDER”的性别替换为1(男)和0(女)
代码:
class_map1 = {'男':1,'女':0}
data['GENDER'] = data['GENDER'].map(class_map1)
结果
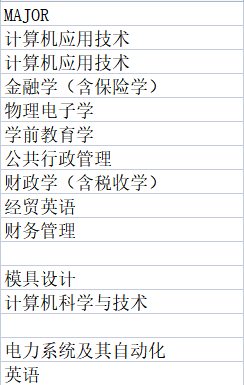
对“MAJOR”列的专业名称进行格式修改,并将空值替换为“不限”
代码:
data[‘MAJOR’] = data.MAJOR.str.strip("【")
data[‘MAJOR’] = data.MAJOR.str.strip("】")
data[‘MAJOR’] = data[‘MAJOR’].fillna(‘不限’)

对“LANGUAGE_REMARK”列的脱敏进行处理,并将空值替换为“不限”
代码:
data[‘LANGUAGE_REMARK’] = data.LANGUAGE_REMARK.str.replace("*","")
data[‘LANGUAGE_REMARK’] = data.LANGUAGE_REMARK.str.replace(“语”,"")
data[‘LANGUAGE_REMARK’] = data[‘LANGUAGE_REMARK’].fillna(‘不限’)


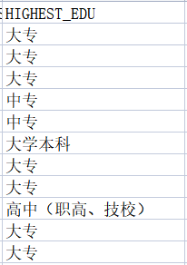
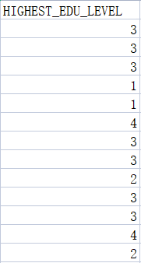
对“HIGHEST_EDU”列的学历进行分值处理划分并用分值的平均值填充空值信息,并将分值信息作为新的列“HIGHEST_EDU_LEVEL”插入person表,并对其进行数据类型的转换(转为int型)
代码:
class_map = {‘其它’:0,‘中专’:1,‘高中(职高、技校)’:2,‘大专’:3,‘大学本科’:4,‘硕士研究生’:5,‘博士研究生’:6,‘博士后’:7}#用字典将最高学历转换为分级数值属性
data['HIGHEST_EDU_LEVEL'] = data['HIGHEST_EDU'].map(class_map)
data['HIGHEST_EDU'] = data['HIGHEST_EDU'].fillna(list(class_map.keys())[list(class_map.values()).index(data['HIGHEST_EDU_LEVEL'].mean().astype(int))])
data['HIGHEST_EDU_LEVEL'] = data['HIGHEST_EDU_LEVEL'].fillna(data['HIGHEST_EDU_LEVEL'].mean())
data['HIGHEST_EDU_LEVEL'] = pd.to_numeric(data['HIGHEST_EDU_LEVEL']).round(0).astype(int)
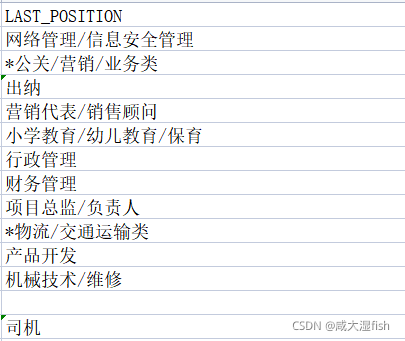
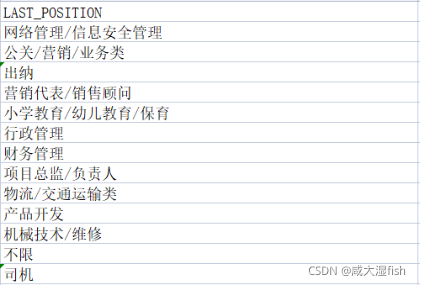
对“LAST_POSITION”列进行特殊字符的去除并将空值替换为“不限”
代码:
data[‘LAST_POSITION’] = data[‘LAST_POSITION’].fillna(‘不限’)
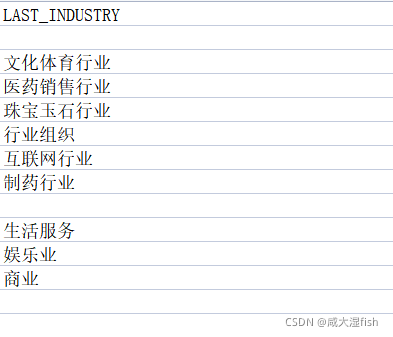
对“LAST_INDUSTRY”列的空值替换为“不限”
代码:
data[‘LAST_INDUSTRY’] = data[‘LAST_INDUSTRY’].fillna(‘不限’)
对“CURR_LOC”列的空值替换为“不限”
代码:
data[‘CURR_LOC’] = data[‘CURR_LOC’].fillna(‘不限’)
4.2 求职意向:person_cv.csv
对“POSITION”列的脱敏进行处理
代码:
data[‘POSITION’] = data.POSITION.str.replace("","")


对“SELF_COMMENT”列进行特殊字符的去除以及脱敏的处理,并将空值替换为“不限”
代码:
data[‘SELF_COMMENT’] = data.SELF_COMMENT.str.strip(“●”)
data[‘SELF_COMMENT’] = data[‘SELF_COMMENT’].fillna(‘不限’)
结果:


4.3 工作经历:person_job_hist.csv
对“ACHIEVEMENT”列进行特殊字符的去除以及脱敏的处理,并将空值替换为“不限”
代码:
data1[‘ACHIEVEMENT’] = data1.ACHIEVEMENT.str.replace("","")
data1[‘ACHIEVEMENT’] = data1[‘ACHIEVEMENT’].fillna(‘不限’)
data1[‘ACHIEVEMENT’] = data1.ACHIEVEMENT.str.strip(“◆”)
data1[‘ACHIEVEMENT’] = data1.ACHIEVEMENT.str.strip(“★”)
data1[‘ACHIEVEMENT’] = data1.ACHIEVEMENT.str.strip(“●”)
data1[‘ACHIEVEMENT’] = data1.ACHIEVEMENT.str.replace(“●”,"")


4.4 专业证书:person_pro_cert
对“REMARK”列进行特殊字符的去除以及脱敏的处理,并将空值替换为“不限”
代码:
data2[‘REMARK’] = data2.REMARK.str.replace("","")
data2[‘REMARK’] = data2[‘REMARK’].fillna(‘不限’)
data2[‘REMARK’] = data2.REMARK.str.strip(“▌”)
结果:


4.5 项目经验:person_project.csv
对“PROJECT_NAME”列的脱敏进行处理
代码:
data3[‘PROJECT_NAME’] = data3.PROJECT_NAME.str.replace("","")
结果:

将每个表分别保存为新的表
代码:
data.to_csv("./处理的数据/person(new).csv",index=False)
data.to_csv("./处理的数据/person_cv(new).csv",index=False)
data1.to_csv("./处理的数据/person_job_hist(new).csv",index=False)
data2.to_csv("./处理的数据/person_pro_cert(new).csv",index=False)
data3.to_csv("./处理的数据/person_project(new).csv",index=False)
结果:

通过pandas的merge函数将5个处理的新表通过“PERSON_ID”列进行合并
代码:
data = pd.merge(data1,data2,on='PERSON_ID')
data = pd.merge(data,data3,on='PERSON_ID')
data = pd.merge(data,data4,on='PERSON_ID')
data = pd.merge(data,data5,on='PERSON_ID')
data.to_csv('./处理的数据/person合并表.csv',index=False)
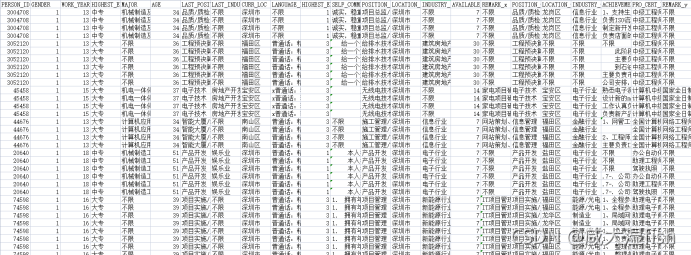
4.6 招聘岗位信息:recruit.csv
原始数据:
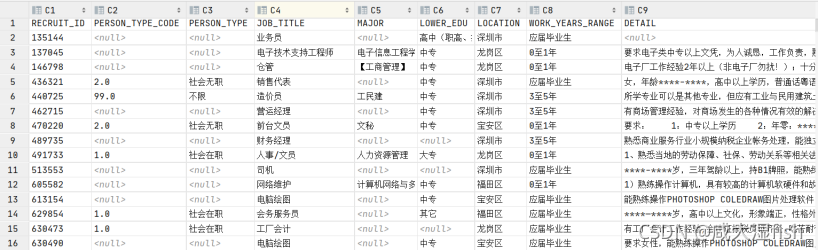
4.6.1 数据变化
将最低学历LOWER_EDU和工作年限WORK_YEARS_RANGE转换为分级数值属性
先建立字典类型

使用map方法将其转换为分级数值类型并添加到新的一列

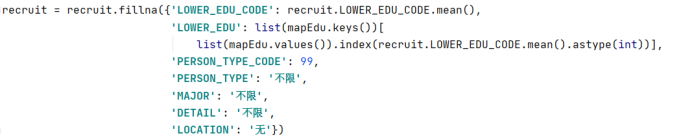
4.6.2 数据清洗
异常值处理
将专业要求MAJOR和招聘职位JOB_TITLE列中的“【】”删除

将具体要求DETAIL中脱敏替代符“*”删除

空值处理
将最低学历以所有人的平均值填补


















 6103
6103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









