







1.虚拟机搭建部分

























root登录
ip addr 查看当前的IP地址

2.克隆虚拟机(集群)





基础设置
vi /etc/sysconfig/network-scripts/ifcfg-ens33

设置BOOTPROTO 为 “static” 静态ip

四台虚拟机所设置的地址:
IPADDR:192.168.229.130
IPADDR:192.168.229.131
IPADDR:192.168.229.132
IPADDR:192.168.229.133
:wq
service network restart

设置主机名
vi /etc/hostname

关闭防火墙(永久)
systemctl disable firewalld

ssh免密码登录
ssh-keygen -t rsa
一直回车 直到返回命令行

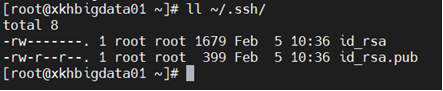
目录中有两个文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
重定向到密钥中 可以进行登陆访问

先创建一个目录来存放后续所需安装的soft
mkdir -p /data/soft
JDK1.8 安装配置
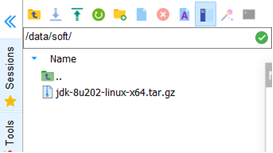
解压
tar -zxvf jdk-8u202-linux-x64.tar.gz
修改解压后的名称
mv jdk1.8.0_202/ jdk1.8
vi /etc/profile
export JAVA_HOME=/data/soft/jdk1.8
export PATH=.:
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:PATH

:wq
source /etc/profile
最后查看版本号
java -version
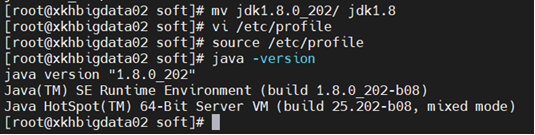
注:以上操作在四台机器中均需要进行一次操作
3.实现主从节点关系
在 xkhbigdata01、02、03、04虚拟机中
vi /etc/hosts
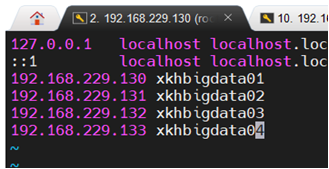
测试:(分别从01ping02、03、04)

不同节点间时间同步
先进行服务安装
yum install -y ntpdate
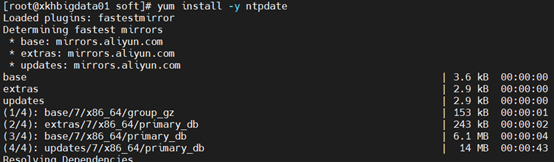
ntpdate -u ntp.sjtu.edu.cn (四台机器)

主节点到从节点的免密码登录
在xkhbigdata01中操作
scp ~/.ssh/authorized_keys xkhbigdata02:~/
scp ~/.ssh/authorized_keys xkhbigdata03:~/
scp ~/.ssh/authorized_keys xkhbigdata04:~/
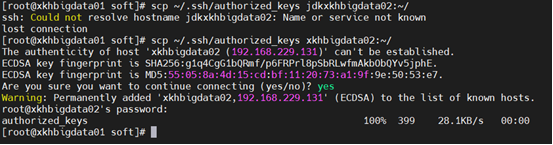
在02、03、04中操作
cat ~/authorized_keys >> ~/.ssh/authorized_keys

验证:

4.安装hadoop
在xkhbigdata01中安装 后分布至各节点
tar -zxvf hadoop-3.2.0.tar.gz

/data/soft/hadoop-3.2.0/etc/hadoop
vi hadoop-env.sh
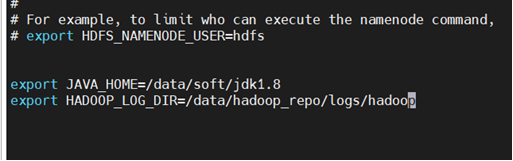
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://xkhbigdata01:9000</value> (主节点信息)
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xkhbigdata01:50090</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xkhbigdata01</value>
</property>
</configuration>
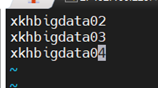
vi workers
/data/soft/hadoop-3.2.0/sbin
均为添加操作
vi start-dfs.sh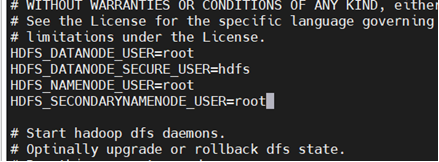
vi stop-dfs.sh
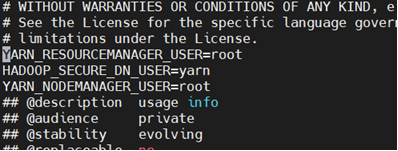
vi start-yarn.sh
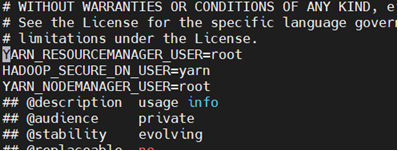
vi stop-yarn.sh
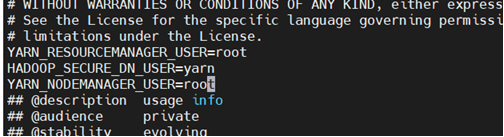
/data/soft
将配置好的hadoop发送至三台子节点虚拟机()
scp -rq hadoop-3.2.0 xkhbigdata02:/data/soft/
scp -rq hadoop-3.2.0 xkhbigdata03:/data/soft/
scp -rq hadoop-3.2.0 xkhbigdata04:/data/soft/

格式化namenode
bin/hdfs namenode -format

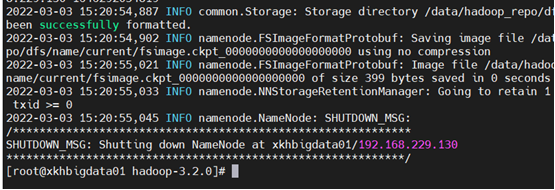
启动集群
sbin/start-all.sh

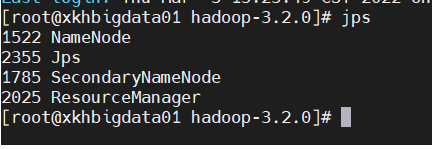
查看进程信息
主节点
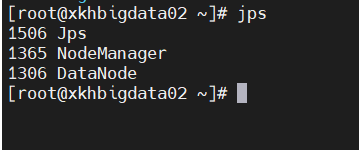
从节点

完成















 3021
3021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









