







人岗智能匹配系统(中)
5.1 数据库版本
Mysql 5.7
5.2 数据库设计
在导入数据之前,首先要创建所对应的表的列名和数据类型,再将/var/lib/mysql-files/中的csv文件导入到创建好的表中
/var/lib/mysql-files/的csv文件
在Sql语句中,每一次存储数据之前都要执行“set sql_mode=’’;”语句,目的是为了提高数据库的效率,清除默认的模式信息
创建person表
列名:PERSON_ID,GENDER,WORK_YEARS,HIGHEST_EDU,MAJOR,AGE ,LAST_POSITION ,LAST_INDUSTRY,CURR_LOC,LANGUAGE_REMARK,SPECILTY
Sql语句:
create table person(PERSON_ID varchar(20) primary key,GENDER varchar(20),WORK_YEARS varchar(20),HIGHEST_EDU varchar(20),MAJOR varchar(20),AGE varchar(20),LAST_POSITION varchar(100),LAST_INDUSTRY varchar(100),CURR_LOC varchar(20),LANGUAGE_REMARK varchar(100),SPECILTY varchar(100))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/person(new).csv’ into table person fields terminated by ‘,’ lines terminated by ‘\n’;
person表的数据类型:

person表的部分数据

创建person_cv表
列名:PERSON_ID,SELF_COMMENT,POSITION_CV,LOCATION_CV,INDUSTRY_CV ,AVAILABLE_IN_DAYS,REMARK_CV
Sql语句:
create table person_cv(PERSON_ID varchar(20) primary key,SELF_COMMENT varchar(100),POSITION_CV varchar(100),LOCATION_CV varchar(100),INDUSTRY_CV varchar(100),AVAILABLE_IN_DAYS varchar(100),REMARK_CV varchar(100))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/person_cv(new).csv’ into table person_cv fields terminated by ‘,’ lines terminated by ‘\n’;
person_cv的数据类型

person_cv表的部分数据

创建person_job_hist表
列名:PERSON_ID,POSITION_JOB,LOCATION_JOB,INDUSTRY_JOB,ACHIEVEMENT
Sql语句:
create table person_job_hist(PERSON_ID varchar(20),POSITION_JOB varchar(100),LOCATION_JOB varchar(100),INDUSTRY_JOB varchar(100),ACHIEVEMENT varchar(100))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/person_job_hist(new).csv’ into table person_job_hist fields terminated by ‘,’ lines terminated by ‘\n’ ignore 1 lines;
person_job_hist表的数据类型

person_job_hist表的部分数据

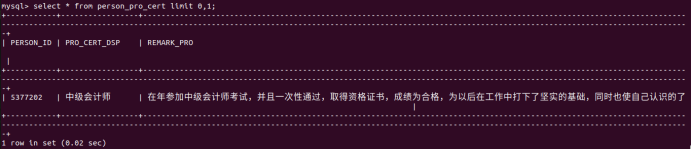
创建person_pro_cert表
列名:PERSON_ID,PRO_CERT_DSP,REMARK_PRO
Sql语句:
create table person_pro_cert(PERSON_ID varchar(20) ,PRO_CERT_DSP varchar(100),REMARK_PRO varchar(100))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/person_pro_cert(new).csv’ into table person_pro_cert fields terminated by ‘,’ lines terminated by ‘\n’ ignore 1 lines;
person_pro_cert表的数据类型

person_pro_cert表的部分数据
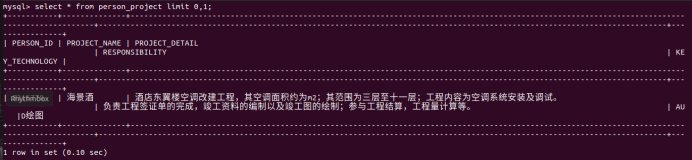
创建person_project表
列名:PERSON_ID,PROJECT_NAME,PROJECT_DETAIL,RESPONSIBILITY ,KEY_TECHNOLOGY
Sql语句:
create table person_project(PERSON_ID varchar(20) ,PROJECT_NAME varchar(100),PROJECT_DETAIL varchar(100),RESPONSIBILITY varchar(100),KEY_TECHNOLOGY varchar(100))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/person_project(new).csv’ into table person_project fields terminated by ‘,’ lines terminated by ‘\n’ ignore 1 lines;
person_project表的数据类型

person_project表的部分数据
创建recruit表
列名:RECRUIT_ID,PERSON_TYPE_CODE,PERSON_TYPE,JOB_TITLE varchar(20),MAJOR ,LOWER_EDU,LOCATION,WORK_YEARS_RANGE,DETAIL
Sql语句:
create table recruit( RECRUIT_ID varchar(20) primary key,PERSON_TYPE_CODE varchar(20),PERSON_TYPE varchar(20),JOB_TITLE varchar(20),MAJOR varchar(20),LOWER_EDU varchar(20),LOCATION varchar(20),WORK_YEARS_RANGE varchar(20),DETAIL varchar(100))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/recruit(new).csv’ into table recruit fields terminated by ‘,’ lines terminated by ‘\n’;
recruit表的数据类型

recruit表的部分数据

在完成对已有数据的存储之后,还要对新生成的数据和用于计算匹配度的数据进行数据库的存储,也就是要创建user表进行新数据的存储,创建person_feature表和person_recruit_feature表存储用于计算的数据
创建user表
列名:id,password,name,type
Sql语句:
create table user(id int(10) primary key,password varchar(20),name varchar(20),type varchar(20))charset=utf8;
user表的数据类型

创建person_recruit_feature表
列名:PERSON_ID,RECRUIT_ID,EDU_MATCHING,WORK_YEARS_MATCHING ,WORK_YEARS_LONGER,WORK_YEARS_LONGER_YEAR,MAJOR_MATCHING ,MAJOR_MATCHING_NOLIMIT,JOB_MATCHING,LOCATION_MATCHING ,LOCATION_MATCHING_ALL,SEX_MATCHING,KEY_TECHNOLOGY_COUNT ,KEY_TECHNOLOGY_MATCHING_MAX,SPECILTY_MATCHING
Sql语句:
create table person_recruit_feature(PERSON_ID int(10) ,RECRUIT_ID int(10) ,EDU_MATCHING int(5),WORK_YEARS_MATCHING int(5),WORK_YEARS_LONGER int(5),WORK_YEARS_LONGER_YEAR int(5),MAJOR_MATCHING float(10),MAJOR_MATCHING_NOLIMIT int(5),JOB_MATCHING float(10),LOCATION_MATCHING int(5),LOCATION_MATCHING_ALL int(5),SEX_MATCHING int(5),KEY_TECHNOLOGY_COUNT int(5),KEY_TECHNOLOGY_MATCHING_MAX int(5),SPECILTY_MATCHING float(10),primary key(PERSON_ID,RECRUIT_ID))charset=utf8;
set sql_mode=’’;
load data infile ‘/var/lib/mysql-files/person_recruit_feature.csv’ into table person_recruit_feature fields terminated by ‘,’ lines terminated by ‘\n’;
person_recruit_feature表的数据类型

6 特征工程
6.1 特征提取
提取求职者和招聘者的交叉特征
学历是否匹配
t1 = feature[['PERSON_ID', 'RECRUIT_ID', 'HIGHEST_EDU_LEVEL', 'LOWER_EDU_CODE']]
t1 = t1[t1.HIGHEST_EDU_LEVEL >= t1.LOWER_EDU_CODE][['PERSON_ID', 'RECRUIT_ID']]
t1['EDU_MATCHING'] = 1
t1.drop_duplicates(inplace=True)
工作时长是否匹配
t2 = feature[['PERSON_ID', 'RECRUIT_ID', 'WORK_YEARS', 'WORK_YEARS_RANGE_CODE']]
t2.WORK_YEARS_RANGE_CODE = t2.WORK_YEARS_RANGE_CODE.apply(get_year_range)
t2['WORK_YEARS_MATCHING'] = t2.apply(lambda x: 1 if x.WORK_YEARS in x.WORK_YEARS_RANGE_CODE else 0, axis=1)
t2 = t2[['PERSON_ID', 'RECRUIT_ID', 'WORK_YEARS_MATCHING']]
t2.drop_duplicates(inplace=True)
求职者工作时长是否超过招聘要求
t3 = feature[['PERSON_ID', 'RECRUIT_ID', 'WORK_YEARS', 'WORK_YEARS_RANGE_CODE']]
t3.WORK_YEARS = t3.WORK_YEARS.apply(get_year_code)
t3 = t3[t3.WORK_YEARS > t3.WORK_YEARS_RANGE_CODE]
t3['WORK_YEARS_LONGER'] = 1
t3 = t3[['PERSON_ID', 'RECRUIT_ID', 'WORK_YEARS_LONGER']]
t3.drop_duplicates(inplace=True)
求职意向岗位和招聘岗位匹配率
t5 = feature[['PERSON_ID', 'RECRUIT_ID', 'POSITION_CV', 'JOB_TITLE']]
t5['JOB_MATCHING'] = t5.apply(lambda x: SequenceMatcher(None, x.POSITION_CV, x.JOB_TITLE).ratio(), axis=1)
t5 = t5[['PERSON_ID', 'RECRUIT_ID', 'JOB_MATCHING']]
t5.drop_duplicates(inplace=True)
专业匹配率
t4 = feature[['PERSON_ID', 'RECRUIT_ID', 'MAJOR_x', 'MAJOR_y']]
t4['MAJOR_MATCHING'] = t4.apply(lambda x: SequenceMatcher(None, x.MAJOR_x, x.MAJOR_y).ratio(), axis=1)
t4['MAJOR_MATCHING_NOLIMIT'] = t4.apply(lambda x: 1 if x.MAJOR_y == '不限' else 0, axis=1)
t4 = t4[['PERSON_ID', 'RECRUIT_ID', 'MAJOR_MATCHING', 'MAJOR_MATCHING_NOLIMIT']]
t4.drop_duplicates(inplace=True)
工作地点匹配
t6 = feature[['PERSON_ID', 'RECRUIT_ID', 'LOCATION_CV', 'LOCATION']]
t6['LOCATION_MATCHING'] = t6.apply(lambda x: SequenceMatcher(None, x.LOCATION_CV, x.LOCATION).ratio(), axis=1)
t6 = t6[['PERSON_ID', 'RECRUIT_ID', 'LOCATION_MATCHING']]
t6.drop_duplicates(inplace=True)
6.2 合并特征
person_recruit = pd.merge(all_person_recruit, t1, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t2, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t3, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t4, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t5, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t6, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t7, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t9, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t10, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit = pd.merge(person_recruit, t11, on=['PERSON_ID', 'RECRUIT_ID'], how='left')
person_recruit.drop_duplicates(inplace=True)
person_recruit.reset_index(drop=True, inplace=True)
6.3 输出特征
person_recruit.to_csv('./data/处理后/person_recruit_feature.csv', index=False)
7 模型训练
7.1 模型选择
做匹配预测,选择决策树作为训练模型较好
在项目中,选择xgboost(eXtreme Gradient Boosting)作为训练模型,是boosting迭代型、树类算法

7.2 划分数据集
在选择特征的过程中,作为决策树,要先将’RECRUIT_ID’,‘PERSON_ID’,'LABEL’这三列去除(招聘信息,个人编号,正负样本分类),然后进行模型的训练。
先将数据分成测试集和训练集
75:25 训练集75 测试集25

7.3 模型调参
通过模型的参数设置
booster 选择迭代模型 gbtree 基于树的模型
eta 减小每一步的权重,提高模型的鲁棒性
min_child_weight 决定最小叶子节点样本权重 避免过于拟合
max_depth 树的最大深度
subsample 控制对于每棵树 随机采样的比例
7.4 模型预测

训练完成后 可以观察到测试集与训练集的预测情况
7.5 模型评估
 同时 我们可以输出各个属性的重要性
同时 我们可以输出各个属性的重要性
能够为后续训练完成后模型的使用
作为一种筛选分类的方式

最后生成 xgb.json 模型 对后续输入进行预测
8 数据可视化
采用python中的matplotlib和pyechart库绘制,主要是针对招聘者的工作经验、招聘人员和企业的学历、企业所需专业、个人所在行业以及地域分布进行比较绘制,数据采用预处理过后表。
8.1 招聘者工作经验以及其中一年经验以下年龄分布

绘图采用matplotlib的bar绘制,该图片采用饼图的方式展现招聘者的工作经验占比,将数据中具体的工作经验进行处理,划分为四部分——一年以下,一到五年,五到十年,以及十年以上。其中5-10年者占大多数,1-5年占比最小。还特别对一年以下者的年龄分布做更细的研究。
8.2 个人和企业学历

采用matplotlib,图中企业要求的最低学历大专占主要部分,同时招聘者的学历也是大专最多,本科中专高职次之。对于高学历(研究生、博士等)略微较少。
8.3 企业对于专业要求

8.4 行业

8.5 地域分布

使用pyechart,图中为深圳市地图,其中是招聘者所在地区,宝安区的人数最多,龙岗区次之。
8.6 词云

该词云统计是根据招聘者跟企业的文本细节绘制















 1477
1477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









