










 本文介绍如何使用pandas和matplotlib进行数据探索,包括基础统计分析、数据可视化及算法辅助探索。涵盖柱状图、曲线图、热图等多种图表制作,并探讨特征间关系及异常值检测。
本文介绍如何使用pandas和matplotlib进行数据探索,包括基础统计分析、数据可视化及算法辅助探索。涵盖柱状图、曲线图、热图等多种图表制作,并探讨特征间关系及异常值检测。
简介
对于数据科学而言,我们要做的第一件事情,必然是了解我们的数据.而在数据探索期间,pandas和matplotlib 则是我们进行数据探索的利器.本文主要分为三个部分,第一部分是利用pandas进行一些基础的数据分析,第二部分是利用pandas自身功能进行一些有用的数据探索,最重要的是第三部分,利用pandas与matplotlib ,scikit-learn中的工具以及数据与算法本身的一些特性对数据进行进一步的分析与探索.
此外本文中所有的内容都会给出源码,并附带数据文件.供大家参考.长文多图,部分图片仅仅为了放松气氛,与数据探索无关.
准备
在阅读文章之前,你也许需要一些准备
1.win下Pandas,matplotlib 无法显示中文问题 解决方案
2.Ubuntu下Pandas,matplotlib 无法显示中文
3.下载数据文件与全部代码
或者从UCI读取并存储文件的CODE:
def ReadAndSaveDataByPandas(save = False):
target_url = ("http://archive.ics.uci.edu/ml/machine-"
"learning-databases/wine-quality/winequality-red.csv")
wine = pd.read_csv(target_url, header=0, sep=";")
if save == True:
wine.to_csv("E:/Data//UCI/WINE/wine.csv",index=False)
def GetDataByPandas():
wine = pd.read_csv("E:/Data//UCI/WINE/wine.csv")
y = np.array(wine["quality"])
del wine["quality"]
X = np.array(wine)
return X,y,np.array(wine.columns)

(pandas?不对,pandas应该是一群)
利用Pandas进行基础的统计分析
- 基础性的统计分析
# 给出样品的基本描述
# print(wine.mean()) # 均值
# print(wine.std()) # 标准差
# print(wine.max()) # 最大值
# print(wine.min()) # 最小值
# 综合
# print(wine.describe()) #综合描述,见图1-1
# print(wine.var()) # 方差
# print(wine.sum()) # 求和
# 计算协方差
# print(wine.cov())
# skew/kurt 偏度/峰度
# print(wine.skew())
# print(wine.kurt())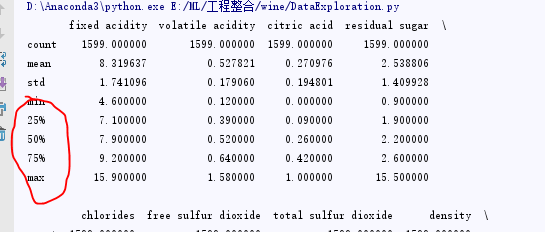
图1 - 1
wine.describe()输出的下部分是数据的四分位数.这个功能在之后的箱形图(Box-plot)时会使用到,同时之前的所有数据其实都在我们之后可视化部分可能用到.
- 累计计算
# 累计计算
# print(wine.cumsum())
# print(wine.cumprod())
# print(wine.cummax())
# print(wine.cummin())
# 滚动计算
# 给出样品的基本描述
# print(wine.iloc[1:5,0:2])
# print(wine.iloc[1:5,0:2].rolling(window=2).mean())
# print(wine.iloc[1:5,0:2].rolling(window=2).std())
# print(wine.iloc[1:5,0:2].rolling(window=2).max())
# 综合
# print(wine.iloc[1:5,0:2].rolling(window=2,axis=0).var())
# print(wine.iloc[1:5,0:2].rolling(window=2,axis=1).var())
# print(wine.iloc[1:5,0:2].rolling(window=2,axis=0).sum())
# print(wine.iloc[1:5,0:2].rolling(window=2,axis=1).sum())
# 计算协方差
# print(wine.iloc[1:5,0:2].rolling(window=2).cov())
# skew/kurt 偏度/峰度
# print(wine.rolling(window=5).skew())
# print(wine.rolling(window=2).kurt())Pandas,matplotlib 利用数据可视化进行数据探索
柱状图,基础的统计分析,灵活多样但是易学难精
柱状图基本上算是数据可视化中的helloWorld,利用柱状图,但是柱状图可不仅仅是看看统计数据这么简单
最基本的我们对所有的数据绘制柱状图
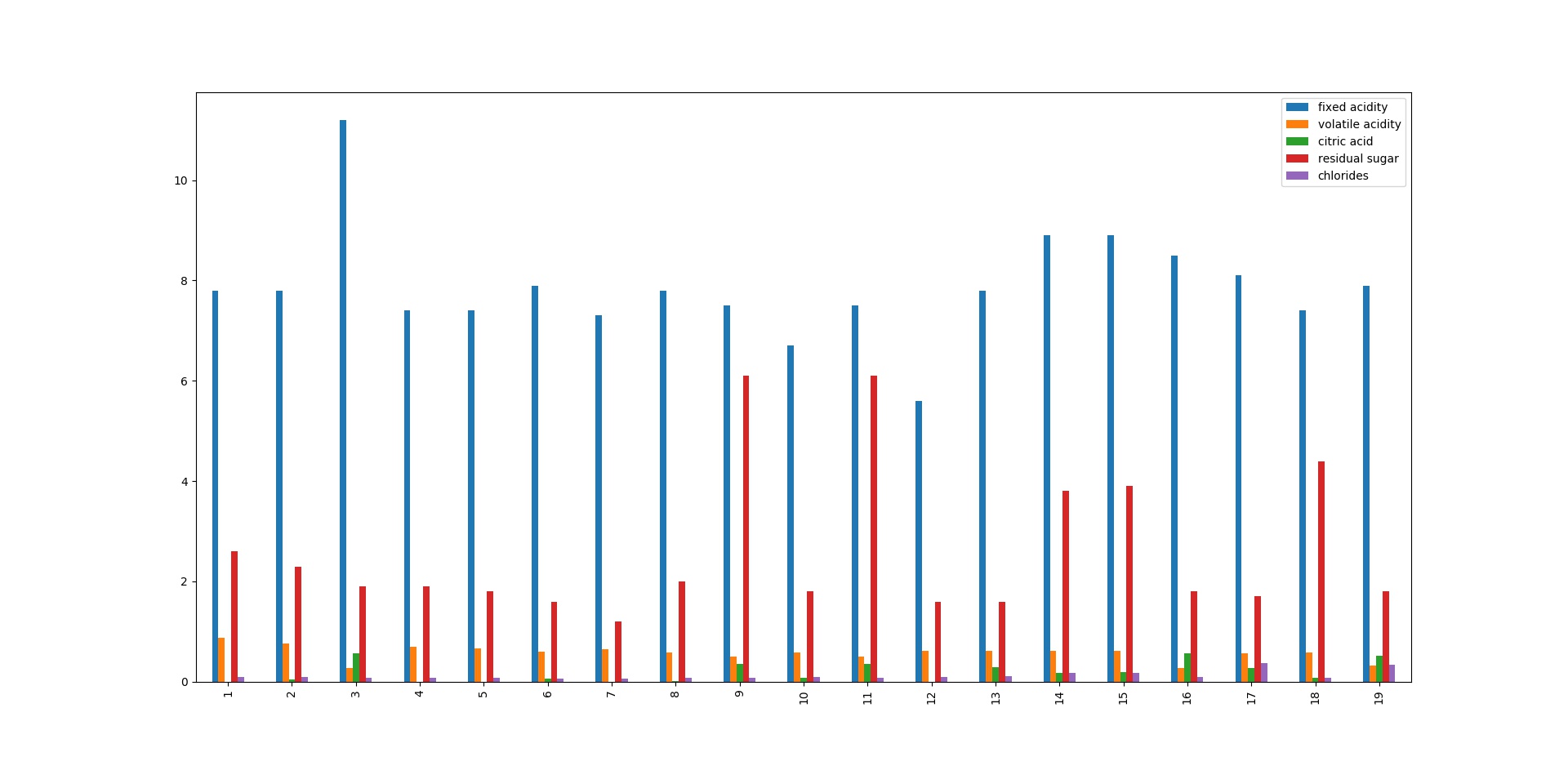
但是这样的数据很难展示出,太大的价值,一个不错的做法就是将所有的数据进行排序,以此展示数据之间的关系.很多时候我们都可以通过数据集之间的关系发现目标与特征之间的特殊关系,有些时候关系是线性的,有些时候则与特征平方,开平方,log等呈线性关系,而必要的可视化则可以帮助我们尽快地发现这一情况.
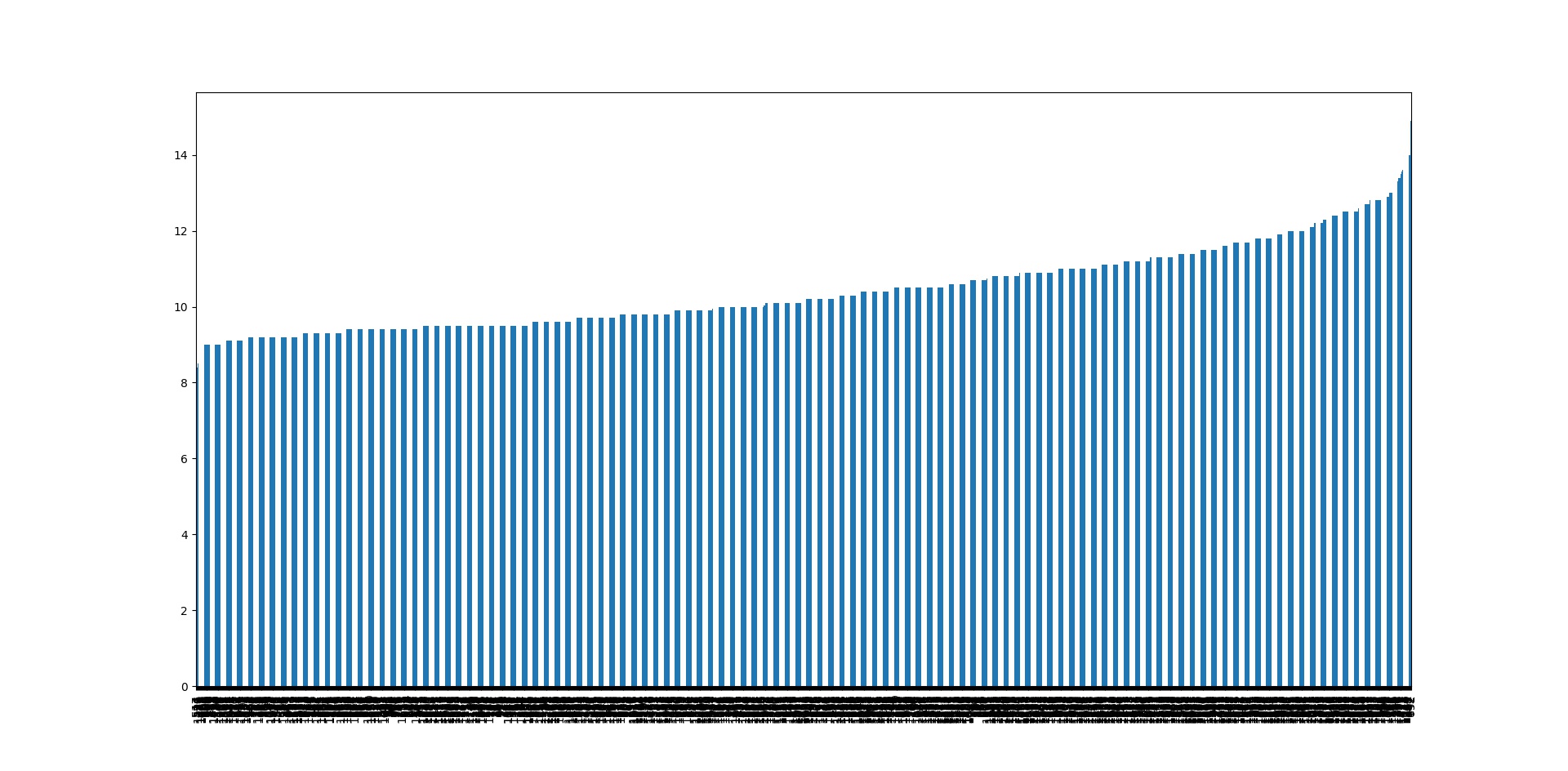
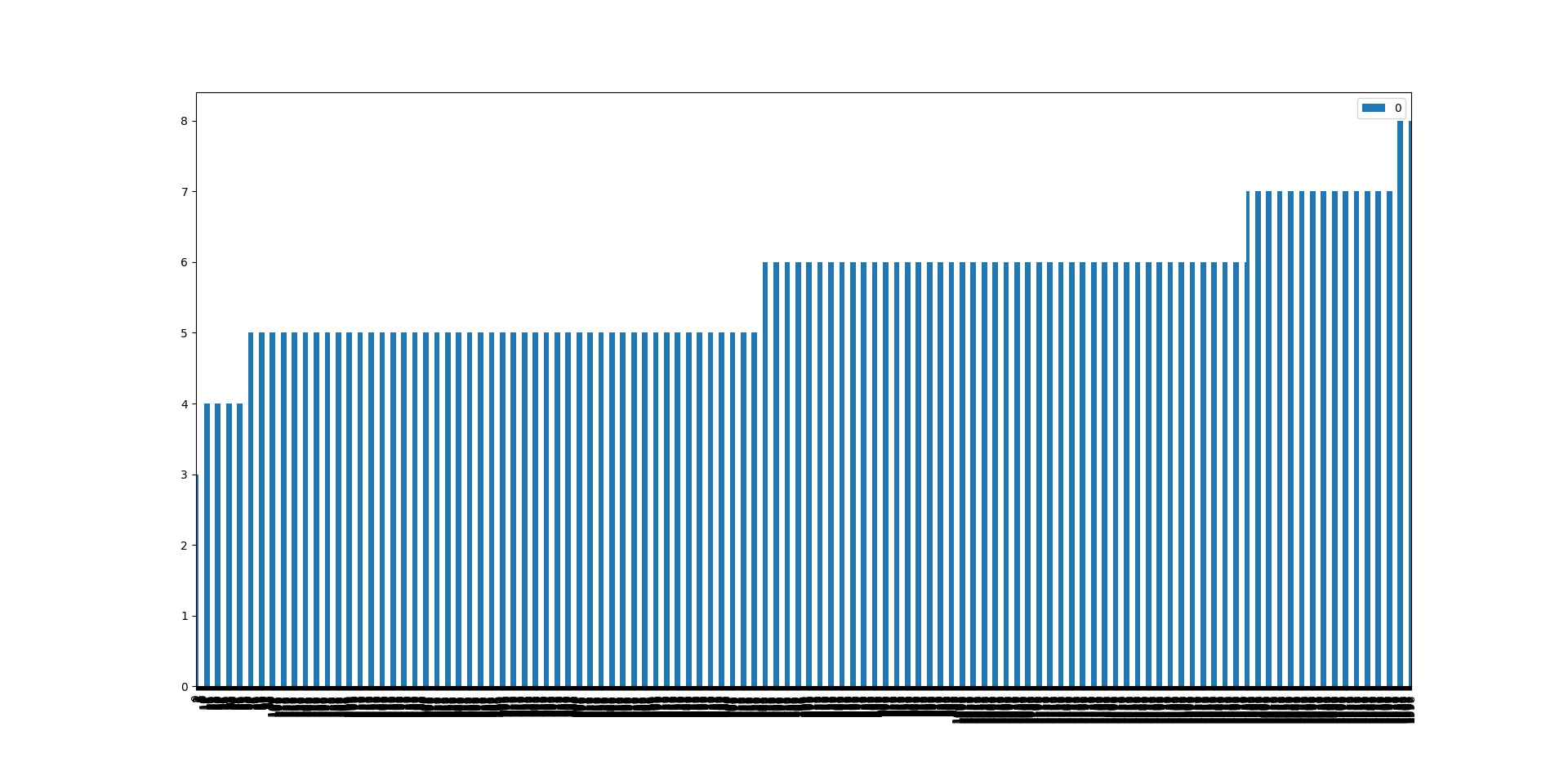
本例子中,我们使用的是红酒口感得分的数据集,由专业知识我们可知,一般红酒口感的得分,与酒精的平方呈线性关系,虽然这是我们通过专业知识得到的,确实通过了解专业知识我们能够更快地找到新的特征,但是事实上,仅仅是已有的知识是很难对我们要处理的数据进行跟好的处理的,很多时候,自己去理解数据才能构造与发现更好的特征,这也就是数据探索的一大重要意义.
至于特征构造,
1.3 变量变换的常用方法是什么?
变换变量有许多方法,如平方根,立方根,对数,合并,倒数等等。来看看这些方法的细节和利弊。
对数(log):变量求对数是用于在分布图上更改变量分布形状的常用变换方法。通常用于减少变量的右偏差,虽然,它也不能应用于零值或负值。
平方/立方根:变量的平方和立方根对改变变量的分布有效果。然而,它不如对数变换那么有效。立方根有自己的优势,可以应用于包括零和负值,平方根可以应用于包括零的正值。
分箱(Binning):用于对变量进行分类。以原始值,百分位数或频率进行分类,分类技术的决策是基于对于业务的理解。例如,可以将收入分为三类:高,中,低,也可以对多个变量执行分箱。
此处文章你可以参考:http://www.jianshu.com/p/73b35d4d144c
手机打开可能有一些问题,那么你也可以浏览我转载后的文章:http://blog.csdn.net/fontthrone/article/details/78186578
除此之外,如果是文本信息,那么你也可以参考:http://blog.csdn.net/fontthrone/article/details/76358665
多重曲线图,发现特征与得分之间的关系
假如仅仅是查看数据之间的关系的话,那么很多时候曲线图确实也是一个不错的工具
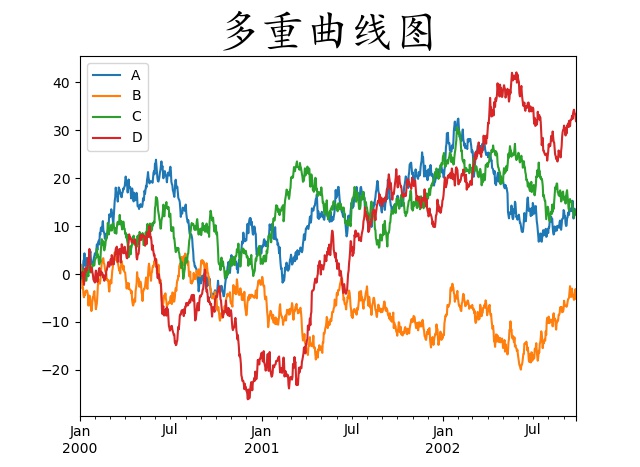
我们使用多重曲线图对之前的酒精特征与wine口感得分的关系进行分析
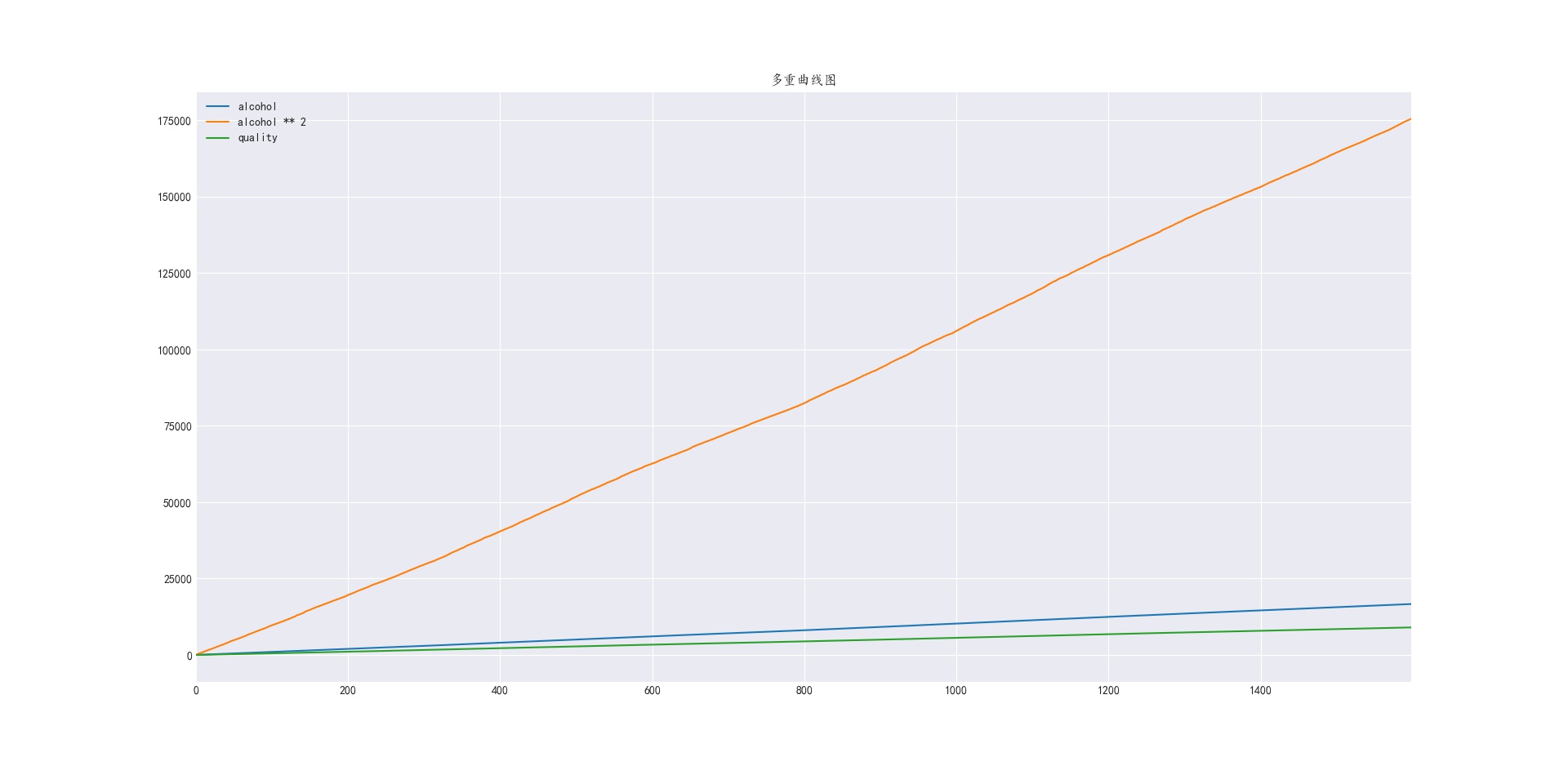
从图中可见,确实红酒口感得分与酒精 的平方 呈线性关系而非究竟特征本身,同样对于数据与特征关系的数据探索,也可以类推到立方,平方根,立方根,log等多种变量转换上。
热图,线性关系的探索
我们可以利用pandas自带的功能,计算各个特征之间的线性相关性,以及各个特征与得分之间的线性关系的热图
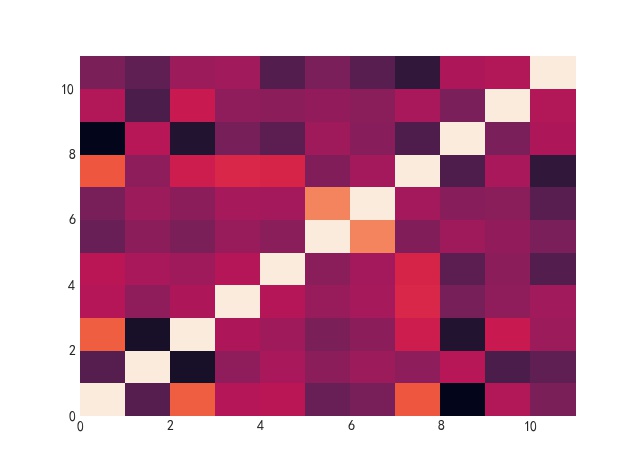
似乎即使是同一个版本的,在不同环境中的配色也是不同的,此图中线性关系最高的也就是每个特征与自己本身,而颜色相反的(本图中为黑色)则是闲心关系最低的.
def ShowCorrHeatMap(Data,method = 'pearson'): # 相关性热图
#calculate correlation matrix
corMat = DataFrame(Data.corr(method=method))
#visualize correlations using heatmap
plot.pcolor(corMat)
plot.show()
ShowCorrHeatMap(Data=wine,method="pearson")
ShowCorrHeatMap(Data=wine,method="kendall")
ShowCorrHeatMap(Data=wine,method="spearman")
# 一共有三种计算方法,差异不大,我个人偏好皮尔逊箱形图,查看数据分布,查找异常点
首先上图
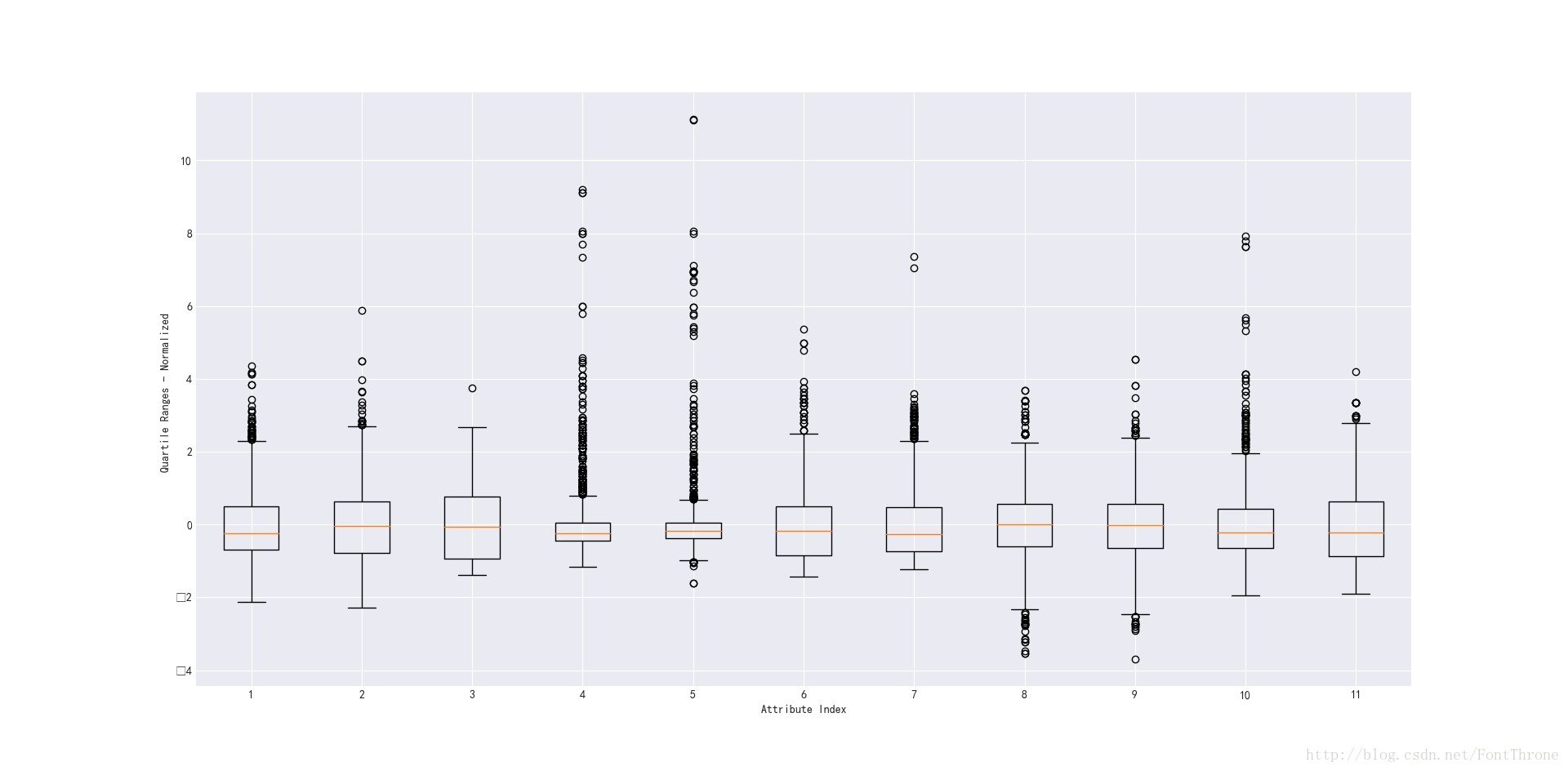
箱形图构成解析
- 长方形中间的横线,第50百分位数,也就是中位数
- 长方形,上下边分别是数据的第25百分位数和第75百分位数,也就是第一四分位数和第三四分位数
- 长方形外两根黑色的横线,即为四分位间距,也就是第25百分位数和第75百分位数的1.4倍.当数据本身的范围小于这个范围时,黑色横线向中位数方向收缩,而超过黑色横线的数据点都可以视为异常数据点.
彩色平行坐标图,线性关系的判别.
彩色平行坐标图展示:
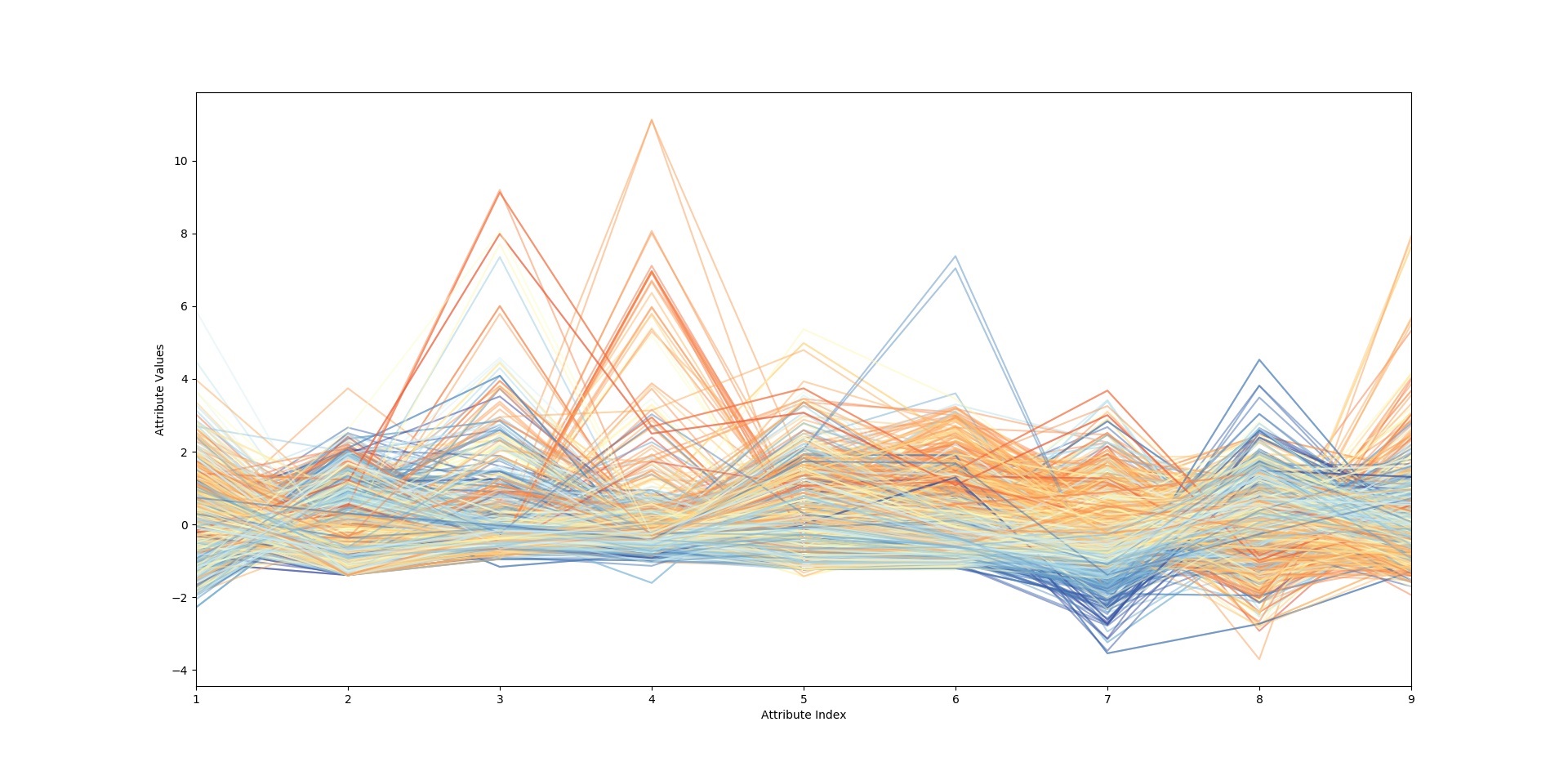
由图可见,其中蓝色部分与橙色部分在许多特征点上都可以比较清晰的展示出来,这就可以证明当前数据及可以较好地分类当前的数据,下面再给出分对数转换之后的彩色平行坐标图
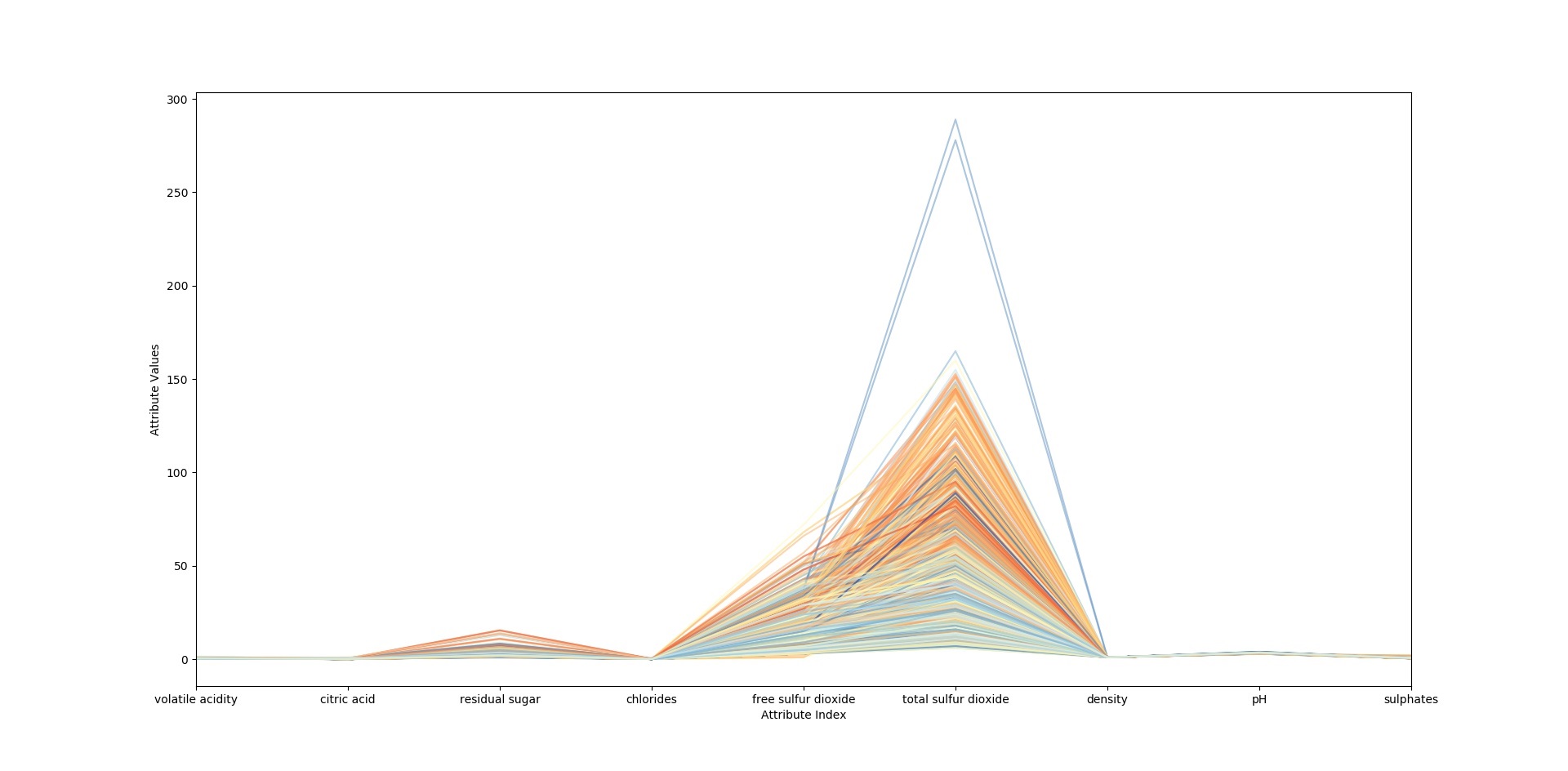
这里因为图片大小原因,所以图片细节展示的不是十分清晰,你可以运行代码,然后利用进行程序的放大镜查看.这样可以比较好的观察到图片细节.
散点图,两维数据的关系判别
首先是连续数据的分布关系
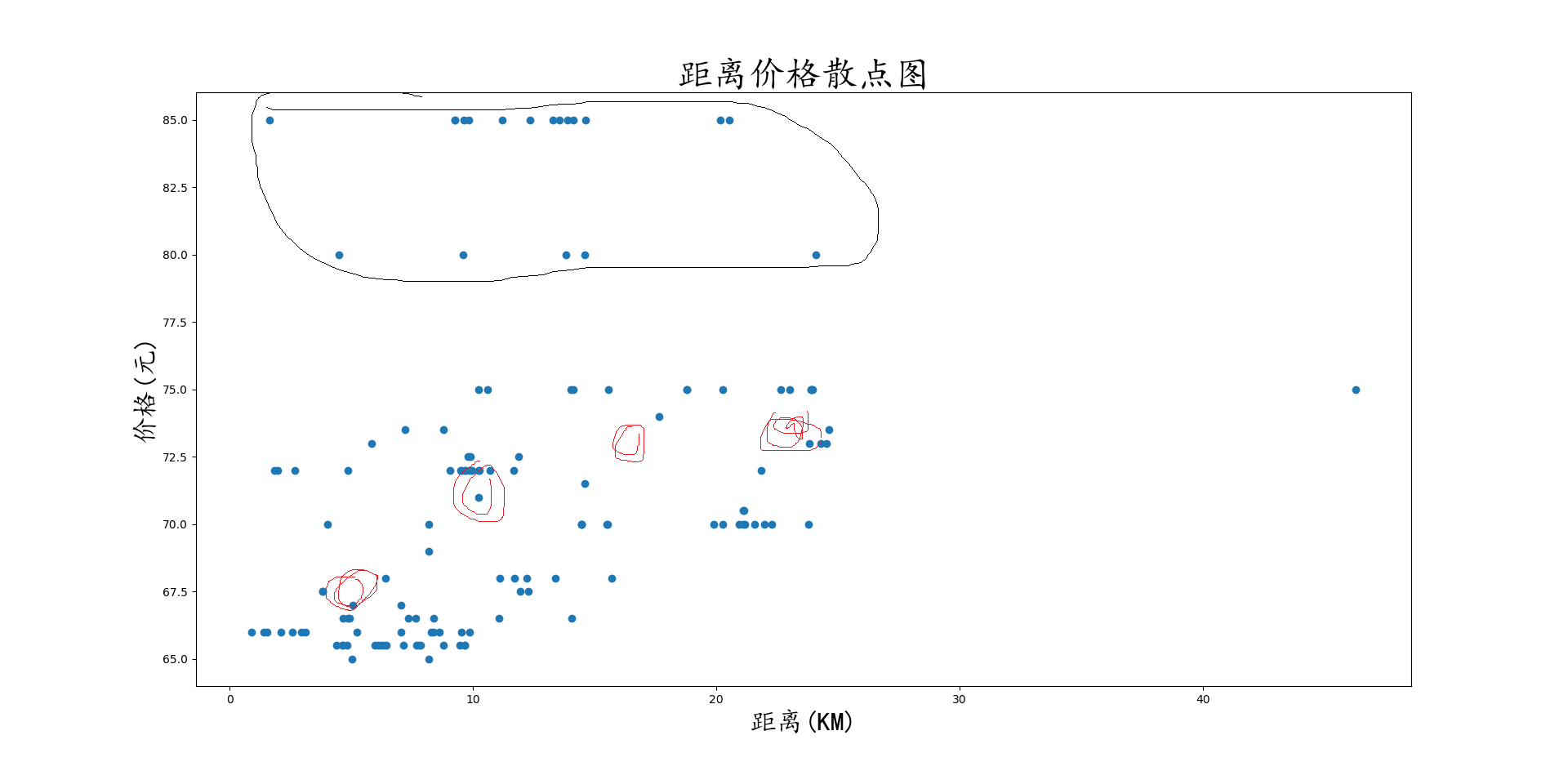
在此图中,我们进行一些简单的判断,比如大量的数据异常点(主要分布于>77.5的区域),而去除异常点之后,我们则可以发现,不同区间的价格随着距离的增大而成一定的关系,因为数据点较少,我们比较难判断到底是线性关系还是log关系,但是我们大概确定了其关系的存在,并且数据分布范围很大,也在告诉着我们很可能价格仍然受其他因素的影响,我们需要寻找其他特征来确定该模型.
然后是分类问题的散点图.
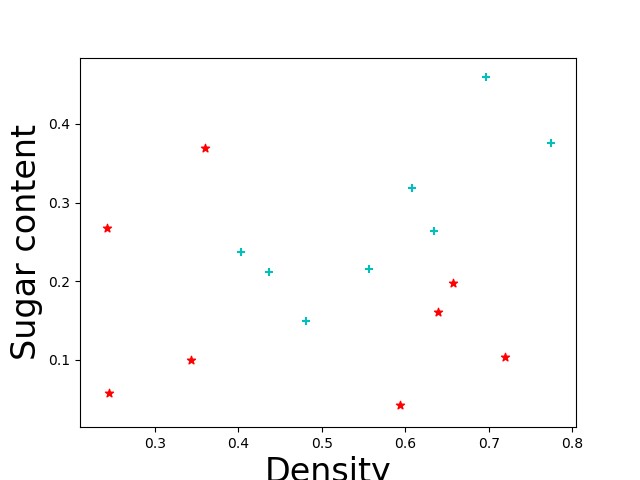
通过该图,我们可以得到两条重要信息,
第一:两个类别在该维度上的关系并不是线性的,我们需要其它维度或者通过构造维度,或者选取非线性分类模型来分类这两类数据
第二: 数据丰富度不够,我们很难通过现有的数据画出明确的边界,我们这时候就要拿出相应的对抗策略,比如复制数据等增加数据集的手段,而在模型选取上,我们也需要更适合小型数据集的算法来进行数据分类.
本部分给出了一些常用的数据探索手段,但是更多的手段还在等待着你去学习
至于更多文本分析的内容请参考我的专栏,我会慢慢补充:剑指汉语自然语言处理
关于绘图中中文乱码的问题,你可以参考我前面的文章,不过Ubuntu下中文显示虽然有点麻烦,但是ubuntu仍然是数据科学的最爱,不信你看:

(Ubuntu娘-动漫版)

(Ubuntu娘-真人版)
是不是很招人喜欢?
更复杂的策略,数据探索与算法
这里要分为三个部分讲,第一个部分是数据探索为一些算法的使用做准备,比如降维,缺失值,空白值处理,,数据探索可以让我们更好的选择算法,比如缺失值的处理,到底是使用插值补全,还是均值或者不处理等等.该部分内容较多,只能下次再写一篇文章,此处只一笔带过.
第二个部分,则是进行数据探索的算法,比如聚类算法,图为距离聚类算法(使用sklearn),通过聚类算法,我们可以发现数据点之间的一些关联信息,或者相近程度.在需要的时候,我们还可以使用sklearn中的加权聚类,进行进一步的分析.
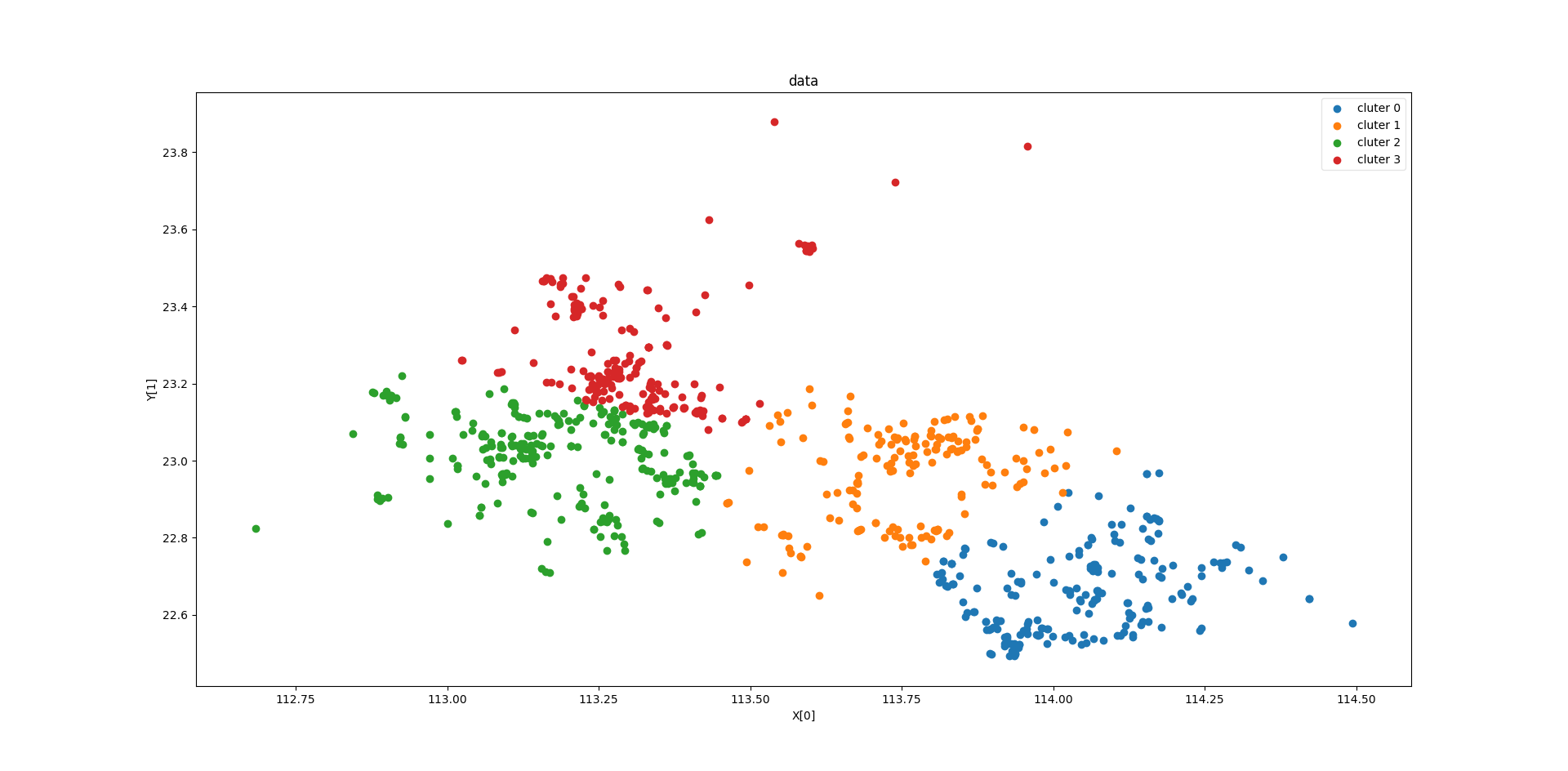
又或是关联度分析,通过关联度分析也可以很好的发现数据之间的关系.(使用sklearn)
等等等等(这里也需要另外一篇文章来补全,我会尽快写)
再或是特征重要程度的确认,我们可以通过前向逐步回归,来进行特征选择,而且是这和我们之前可视化的作用是一致的,都是在寻找特征与y值之间的关系.但是相较于前向逐步回归等方式来确认特征的重要程度,不如借用一些算法的特性来确认特征的重要程度
第三个部分则是利用一些模型特性来进行特征选择,比如利用岭回归中,各类别系数的大小,去除w值较小的内容,又或是利用决策树中对不同属性重要程度的划分,提出一些不重要的属性.这是利用算法本身进行的一些特征选择的处理,但是他和我们之前所做的检测各个特征之间的线性关系等可视化措施效果是类似的,因此我们在进行模型选择是.不妨也将线性回归与决策树算法(决策树集成算法也可以)中这一算法特性作为数据探索的一个手段,来确认特征本身对于y值的重要程度.
该部分的算法我们都可以通过sklearn实现
- 首先以惩罚性线性回归为例(篇幅原因,以下算法的具体计算均不作详细介绍,代码请见下载文件)
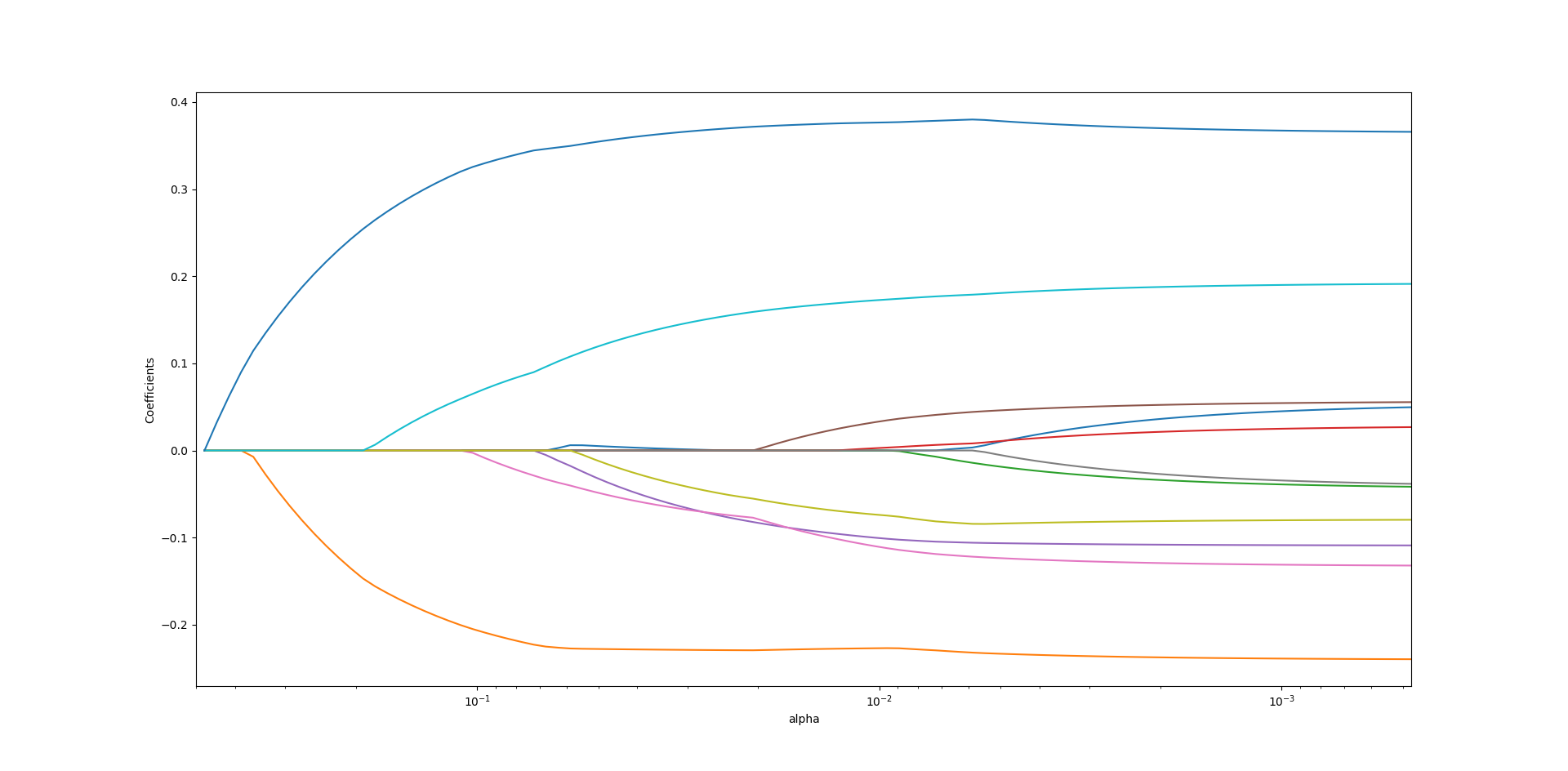
(lasso回归中的各个属性关系关系变化)
如图中所示,在惩罚想的系数,超参数-alpha的不同取值时,所需要用到的属性种类及重要程度都在不断的变化,先加入的特征最终的系数不一定比后加入的系数大,随着alpha的变化,属性重要程度不一定在增加,反而可能会减小.通过lasso回归算法本身的特性).
通过该方式,我们可以很好的确认不同特征对于红酒口感得分的重要程度.
- 然后以随机森林为例
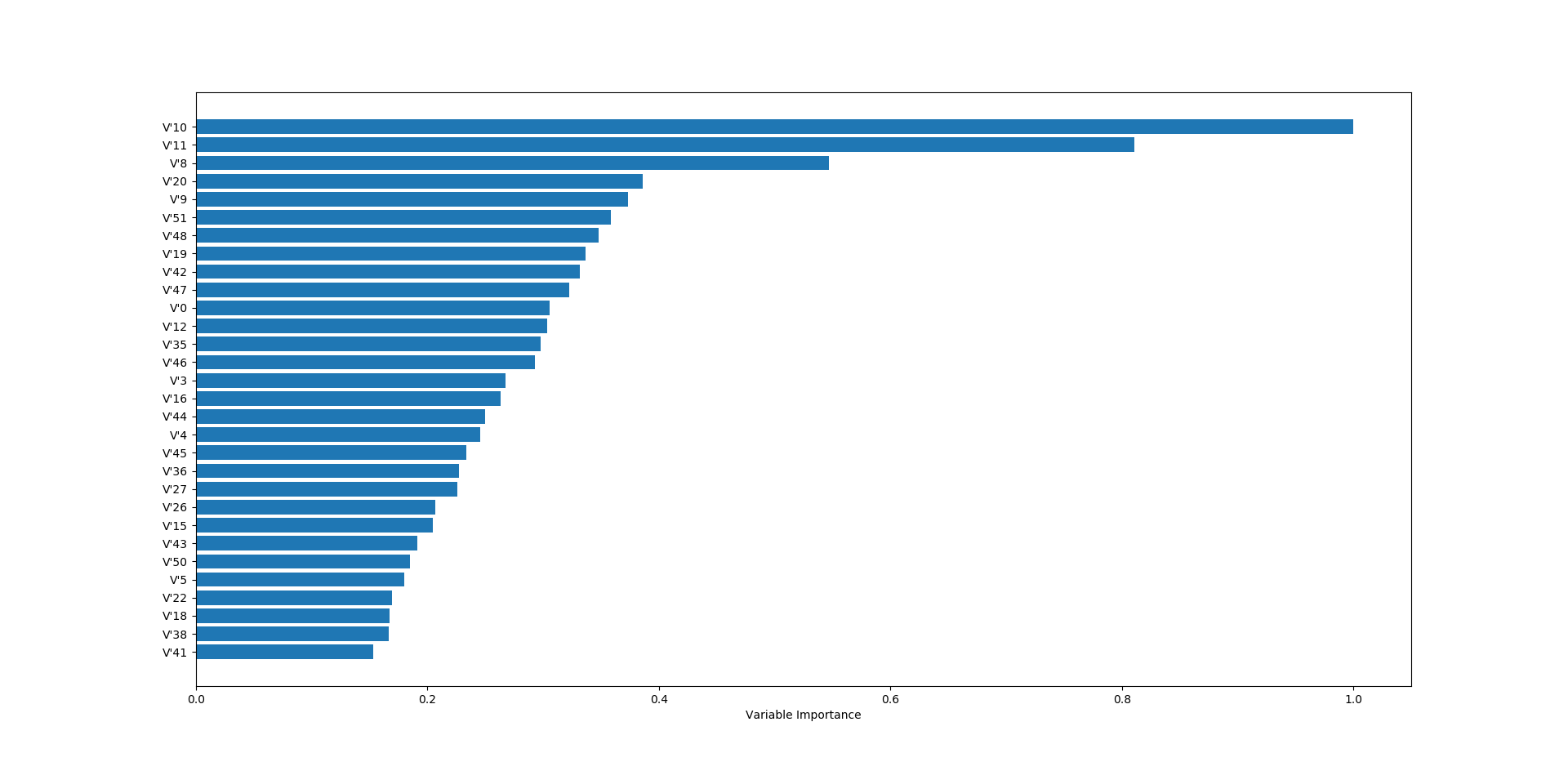
利用调用sklearn中RF算法自带的功能,我们可以获取,每个特征的重要程度,但是要注意的是,RF(决策树类)得出的特征重要程度排名可能与惩罚性线性回归得出的结果又略微的差异,这个需要我们进一步的分析.而从刚刚的图中可得.重要程度最高的仍然是V10属性.当然利用程序我们可以获取更多的详细信息,你可以试着运行我的代码,来探索这些数据与算法.
参考资料
- << Machine Learning in Python_ Essential Techniques for Predictive Analysis >>
- << 机器学习实战-数据探索(变量变换、生成) >> http://www.jianshu.com/p/73b35d4d144c



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











