







客户端业务逻辑处理太慢,导致两次poll之间的间隔时间太久,心跳检测poll超时,会触发leaveGroup,从而进行rebalance,可以调整参数 max.poll.recordfs减低该数值,建议远远小于<单个线程每秒消费的条数><消费线程的个数><max.poll.interval.ms>的积
max.poll.interval.ms:该值要大于<max.poll.records>/(<单个线程每秒消费的条数>*<消费线程的个数>)的值。
提高客户端的消费速度,消费逻辑另外起线程进行处理
减少 Group 订阅 Topic 的数量,一个 Group 订阅的 Topic 最好不要超过 5个,建议只订阅一个
Kafka完全入门指南
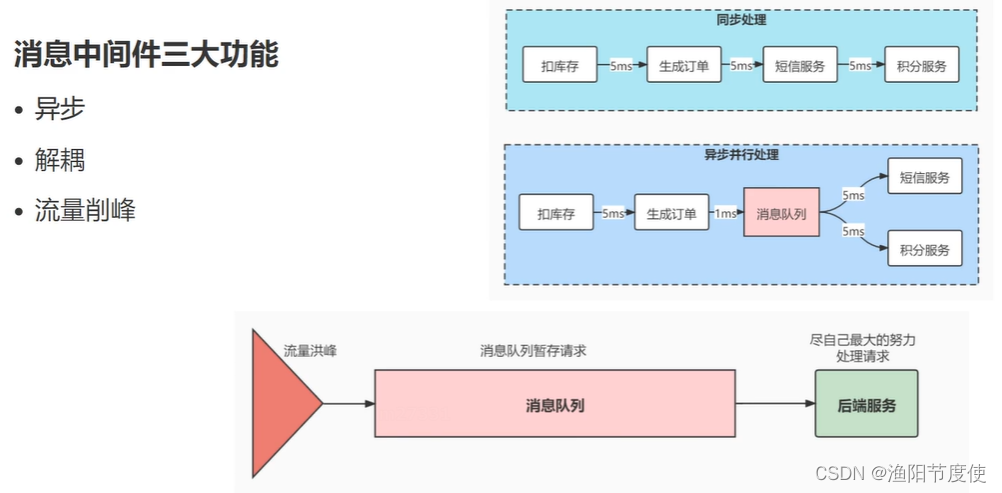
消息中间件的作用
- 异步
- 解耦
- 削峰填谷
kafka额外功能 - 日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下:
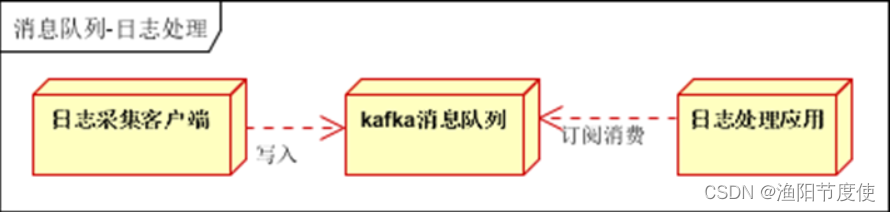
日志采集客户端,负责日志数据采集,定时写入Kafka队列:Kafka消息队列,负责日志数据的接收,存储和转发;日志处理应用:订阅并消费kafka队列中的日志数据;
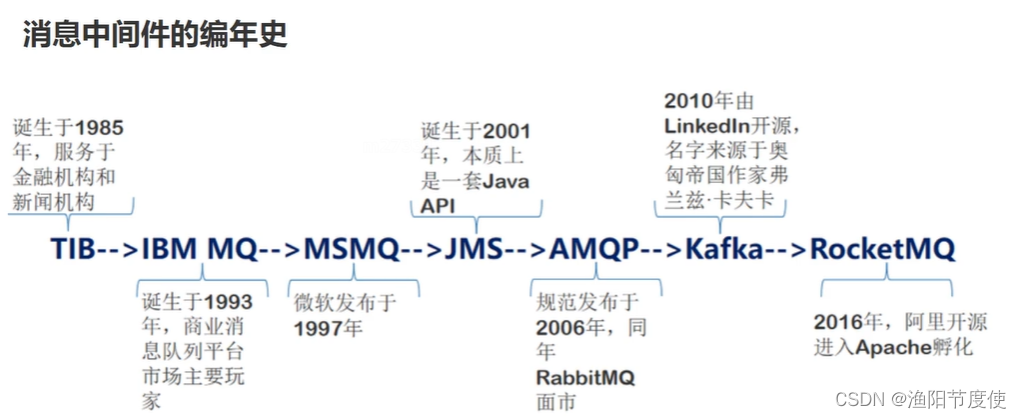
MQ对比
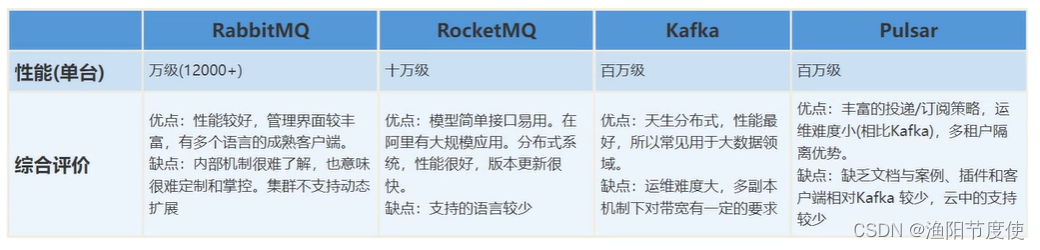
RabbitMQ
优点:管理界面最好用;支持语言较多;
缺点:不支持扩展(集群)
主要流程:生产者发送消息给交换机,通过路由机制投递到对应的队列中
RocketMQ
优点:在阿里有大规模应用
缺点:支持语言较少
Kafka
优点:天生分布式,性能好,支持多语言
缺点:运维难度大
Kafka启动
正常情况下端口为9092
linux的脚本上少一级目录
zookeeper-server-start.bat ../../config/zookeeper.properties
kafka-server-start.bat ../../config/server.properties
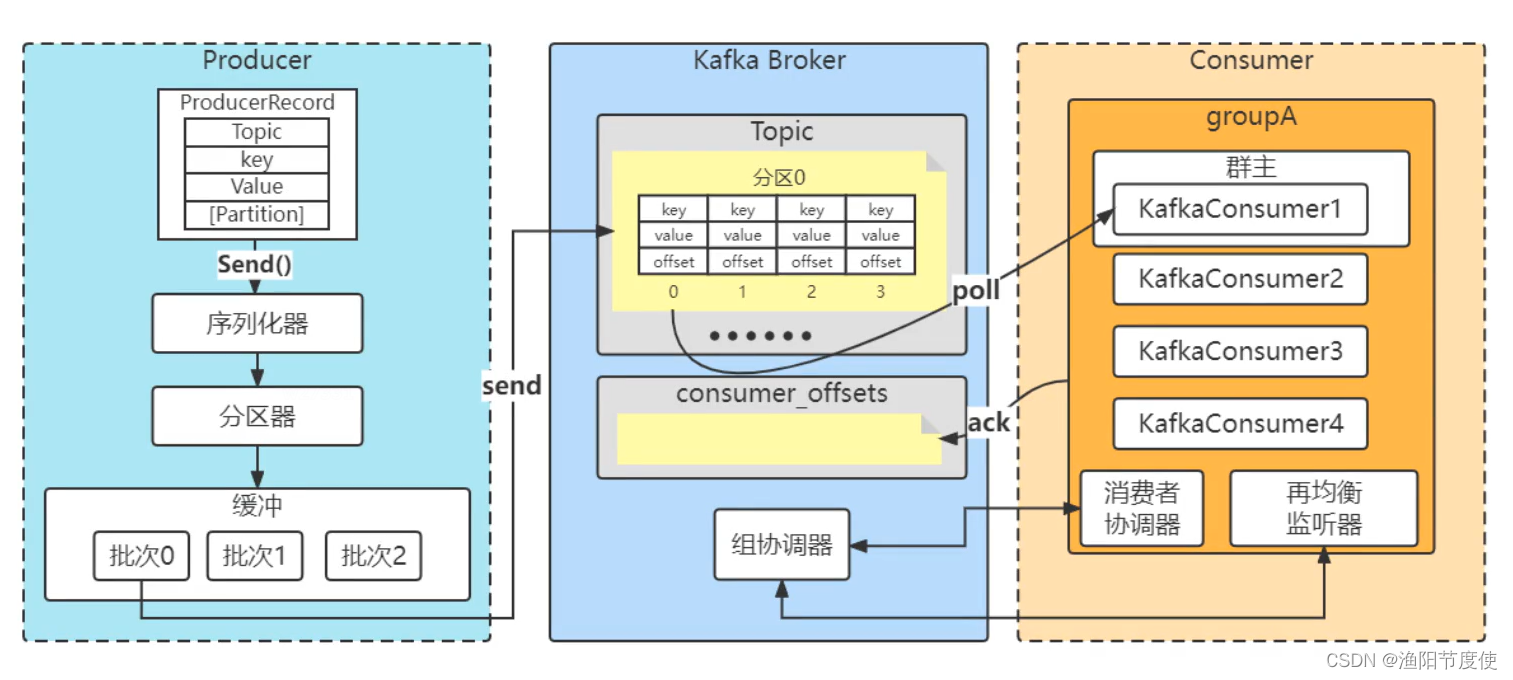
Kafka生产和消费的过程
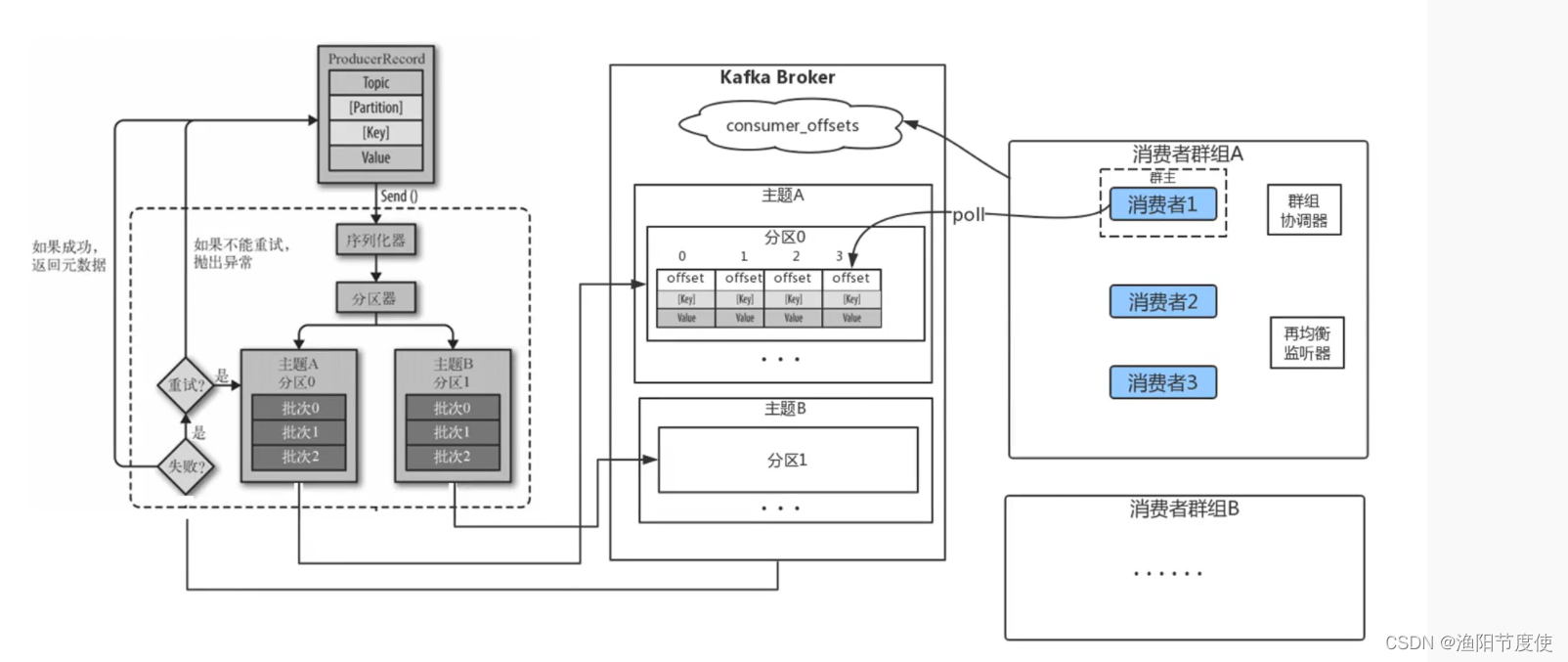
Kafka中的核心概念
消息和批次
消息 ,Kafka里的数据单元,也就是一般消息中间件里的消息的概念(可以比作数据库中一条记录)。消息由字节数组组成。消息还可以包含键(可选元数据,也是字节数组),主要用于对消息选取分区。
作为一个高效的消息系统,为了提高效率,消息可以被分批写入Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果只传递单个消息,会导致大量的网络开销,把消息分成批次传输可以减少这开销。但是,这个需要权衡(时间延迟和吞吐量之间),批次里包含的消息越多,单位时间内处理的消息就越多,单个消息的传输时间就越长(吞吐量高延时也高)。如果进行压缩,可以提升数据的传输和存储能力,但需要更多的计算处理。
对于Kafka来说,消息是晦涩难懂的字节数组,一般使用序列化和反序列化技术,格式常用的有JSON和XML,还有Avro(Hadoop开发的一款序列化框架),具体怎么使用依据自身的业务来定。
主题和分区
Kafka里的消息用主题进行分类(主题好比数据库中的表),主题下有可以被分为若干个 分区(分表技术) 。分区本质上是个提交日志文件,有新消息,这个消息就会以追加的方式写入分区(写文件的形式),然后用先入先出的顺序读取。
分区(Partition)(可以理解为队列):用于将主题(Topic)中的数据划分成多个片段,以实现数据的水平扩展和并行处理。每个主题可以划分为一个或多个分区,每个分区在 Kafka 集群中由一组 Kafka 服务器(Broker)来管理
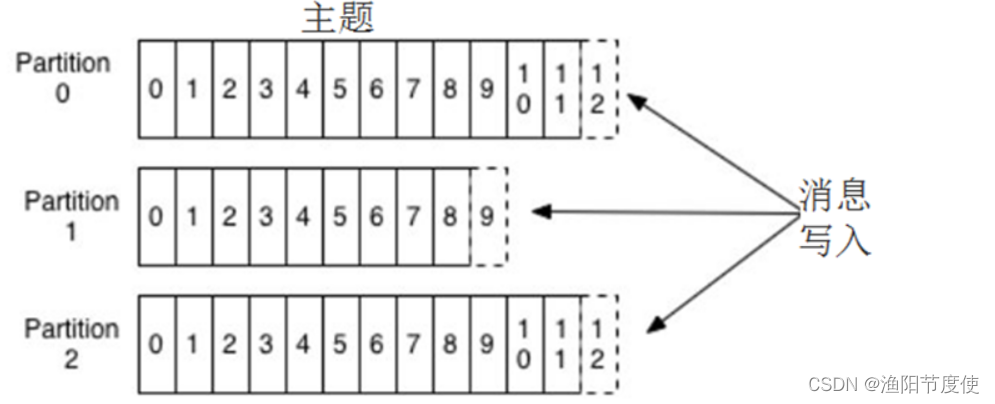
因为主题会有多个分区,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证。
Kafka通过分区来实现数据冗余和伸缩性,因为分区可以分布在不同的服务器上,那就是说一个主题可以跨越多个服务器(这是Kafka高性能的一个原因,多台服务器的磁盘读写性能比单台更高)。
分区怎么划分:消息的消费没有顺序的要求 则根据生产和消费能力;要做到完全的顺序消息,就设置一个分区
生产者和消费者、偏移量、消费者群组
一般消息中间件里生产者和消费者的概念。一些其他的高级客户端API,像数据管道API和流式处理的Kafka Stream,都是使用了最基本的生产者和消费者作为内部组件,然后提供了高级功能。
生产者默认情况下把消息均衡分布到主题的所有分区上,如果需要指定分区,则需要使用消息里的消息键和分区器。
消费者订阅主题,一个或者多个,并且按照消息的生成顺序读取。消费者通过检查所谓的偏移量来区分消息是否读取过。偏移量是一种元数据,一个不断递增的整数值,创建消息的时候,Kafka会把他加入消息。在一个主题中一个分区里,每个消息的偏移量是唯一的。每个分区最后读取的消息偏移量会保存到Zookeeper或者Kafka上,这样分区的消费者关闭或者重启,读取状态都不会丢失。(偏移量)
多个消费者可以构成一个消费者群组。怎么构成?共同读取一个主题的消费者们,就形成了一个群组。群组可以保证每个分区只被一个消费者使用。
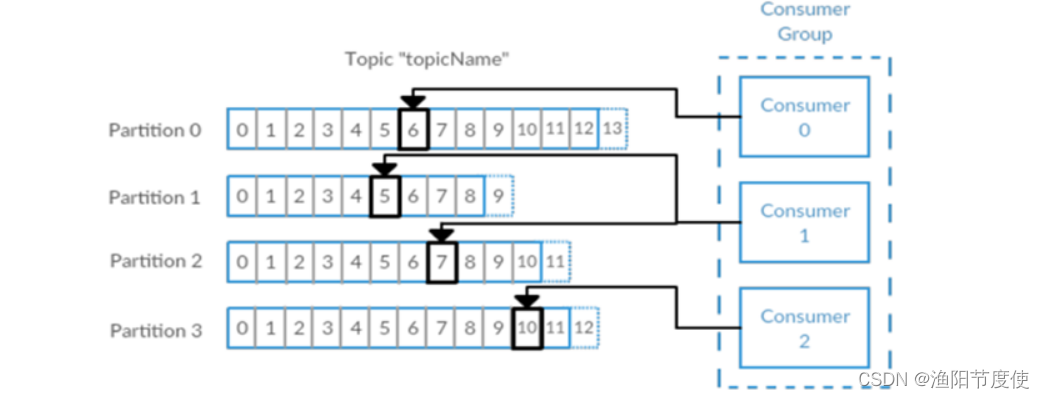
消费者和分区之间的这种映射关系叫做消费者对分区的所有权关系,很明显,一个分区只有一个消费者,而一个消费者可以有多个分区。
(吃饭的故事:一桌一个分区,多桌多个分区,生产者不断生产消息(消费),消费者就是买单的人,消费者群组就是一群买单的人),一个分区只能被消费者群组中的一个消费者消费(不能重复消费),如果有一个消费者挂掉了<James跑路了>,另外的消费者接上)
Broker和集群
一个独立的Kafka服务器叫Broker。broker的主要工作是,接收生产者的消息,设置偏移量,提交消息到磁盘保存;为消费者提供服务,响应请求,返回消息。在合适的硬件上,单个broker可以处理上千个分区和每秒百万级的消息量。(要达到这个目的需要做操作系统调优和JVM调优)
多个broker可以组成一个集群。每个集群中broker会选举出一个集群控制器。控制器会进行管理,包括将分区分配给broker和监控broker。
集群里,一个分区从属于一个broker,这个broker被称为首领。但是分区可以被分配给多个broker,这个时候会发生分区复制。
集群中Kafka内部一般使用管道技术进行高效的复制。
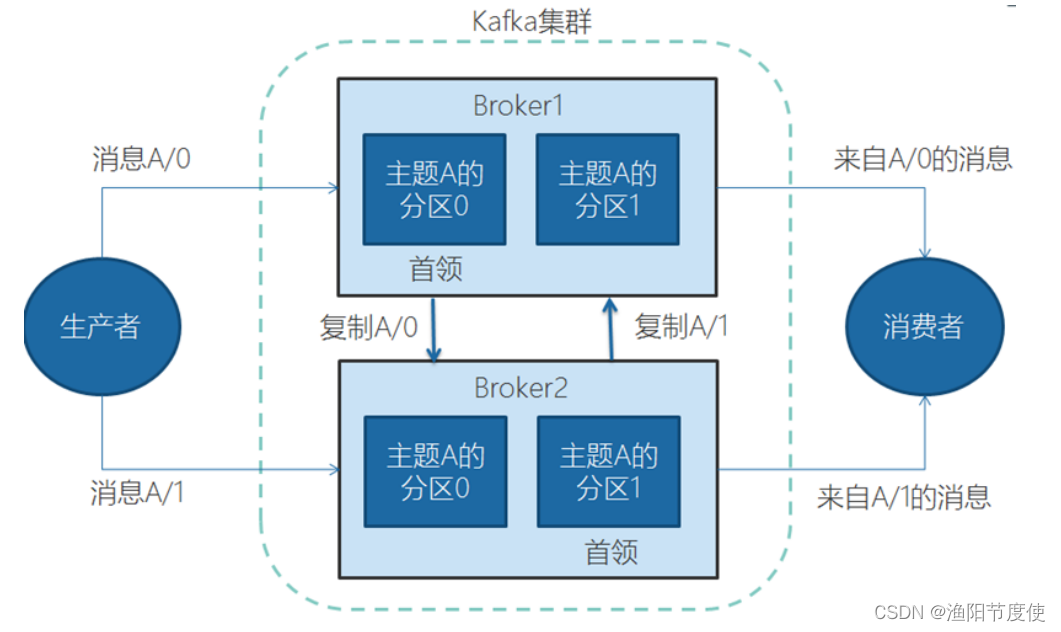
分区复制带来的好处是,提供了消息冗余。一旦首领broker失效,其他broker可以接管领导权。当然相关的消费者和生产者都要重新连接到新的首领上。
保留消息
在一定期限内保留消息是Kafka的一个重要特性,Kafka broker默认的保留策略是:要么保留一段时间(7天),要么保留一定大小(比如1个G)。到了限制,旧消息过期并删除。但是每个主题可以根据业务需求配置自己的保留策略(开发时要注意,Kafka不像Mysql之类的永久存储)。
为什么选择Kafka
优点
多生产者和多消费者
基于磁盘的数据存储,换句话说,Kafka的数据天生就是持久化的。
高伸缩性,Kafka一开始就被设计成一个具有灵活伸缩性的系统,对在线集群的伸缩丝毫不影响整体系统的可用性。
高性能,结合横向扩展生产者、消费者和broker,Kafka可以轻松处理巨大的信息流(LinkedIn公司每天处理万亿级数据),同时保证亚秒级的消息延迟。
常见场景
活动跟踪
跟踪网站用户和前端应用发生的交互,比如页面访问次数和点击,将这些信息作为消息发布到一个或者多个主题上,这样就可以根据这些数据为机器学习提供数据,更新搜素结果等等(头条、淘宝等总会推送你感兴趣的内容,其实在数据分析之前就已经做了活动跟踪)。
传递消息
标准消息中间件的功能
收集指标和日志
收集应用程序和系统的度量监控指标,或者收集应用日志信息,通过Kafka路由到专门的日志搜索系统,比如ES。(国内用得较多)
提交日志
收集其他系统的变动日志,比如数据库。可以把数据库的更新发布到Kafka上,应用通过监控事件流来接收数据库的实时更新,或者通过事件流将数据库的更新复制到远程系统。
还可以当其他系统发生了崩溃,通过重放日志来恢复系统的状态。(异地灾备)
流处理
操作实时数据流,进行统计、转换、复杂计算等等。随着大数据技术的不断发展和成熟,无论是传统企业还是互联网公司都已经不再满足于离线批处理,实时流处理的需求和重要性日益增长
。
近年来业界一直在探索实时流计算引擎和API,比如这几年火爆的Spark
Streaming、Kafka Streaming、Beam和Flink,其中阿里双11会场展示的实时销售金额,就用的是流计算,是基于Flink,然后阿里在其上定制化的Blink。
Kafka的安装、管理和配置
安装
预备环境
Kafka是Java生态圈下的一员,用Scala编写,运行在Java虚拟机上,所以安装运行和普通的Java程序并没有什么区别。
安装Kafka官方说法,Java环境推荐Java8。
Kafka需要Zookeeper保存集群的元数据信息和消费者信息。Kafka一般会自带Zookeeper,但是从稳定性考虑,应该使用单独的Zookeeper,而且构建Zookeeper集群。
运行
Kafka with ZooKeeper
启动Zookeeper
进入Kafka目录下的bin\windows
执行kafka-server-start.bat …/…/config/server.properties
Linux下与此类似,进入bin后,执行对应的sh文件即可

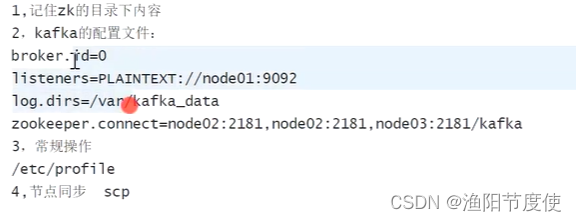
Kafka with KRaft
1、生成集群id

2、格式化存储目录

3、启动服务

启动正确后的界面如下:
kafka基本的操作和管理
列出所有主题
./kafka-topics.sh --bootstrap-server localhost:9092 --list
列出所有主题的详细信息
./kafka-topics.sh --bootstrap-server localhost:9092 --describe
创建主题主题名 my-topic ,1副本,8分区
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --replication-factor 1 --partitions 8
增加分区,注意:分区无法被删除
./kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic my-topic --partitions 16
创建生产者(控制台)
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
创建消费者(控制台)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning --consumer.config ../config/consumer.properties
kafka终止命令
./kafka-server-stop.sh
kafka基本的操作和管理
## 列出所有主题
./kafka-topics.sh --bootstrap-server localhost:9092 --list
## 列出所有主题的详细信息
./kafka-topics.sh --bootstrap-server localhost:9092 --describe
## 创建主题主题名 my-topic ,1副本,8分区
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --replication-factor 1 --partitions 8
##增加分区,注意:分区无法被删除
./kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic my-topic --partitions 16
## 创建生产者(控制台)
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
## 创建消费者(控制台)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning --consumer.config ../config/consumer.properties
## kafka终止命令
./kafka-server-stop.sh
Broker配置
常规配置
broker.id
在单机时无需修改,但在集群下部署时往往需要修改。它是个每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
listeners
监听列表(以逗号分隔 不同的协议(如plaintext,trace,ssl、不同的IP和端口)),hostname如果设置为0.0.0.0则绑定所有的网卡地址;如果hostname为空则绑定默认的网卡。如果没有配置则默认为java.net.InetAddress.getCanonicalHostName()。
如:PLAINTEXT://myhost:9092,TRACE://:9091或 PLAINTEXT://0.0.0.0:9092,
zookeeper.connect
zookeeper集群的地址,可以是多个,多个之间用逗号分割。(一组hostname:port/path列表,hostname是zk的机器名或IP、port是zk的端口、/path是可选zk的路径,如果不指定,默认使用根路径)
log.dirs
Kafka把所有的消息都保存在磁盘上,存放这些数据的目录通过log.dirs指定。可以使用多路径,使用逗号分隔。如果是多路径,Kafka会根据“最少使用”原则,把同一个分区的日志片段保存到同一路径下。会往拥有最少数据分区的路径新增分区。
num.recovery.threads.per.data.dir
每数据目录用于日志恢复启动和关闭时的线程数量。因为这些线程只是服务器启动(正常启动和崩溃后重启)和关闭时会用到。所以完全可以设置大量的线程来达到并行操作的目的。注意,这个参数指的是每个日志目录的线程数,比如本参数设置为8,而log.dirs设置为了三个路径,则总共会启动24个线程。
auto.create.topics.enable
是否允许自动创建主题。如果设为true,那么produce(生产者往主题写消息),consume(消费者从主题读消息)或者fetch
metadata(任意客户端向主题发送元数据请求时)一个不存在的主题时,就会自动创建。缺省为true。
delete.topic.enable=true
删除主题配置,默认未开启
主题配置
新建主题的默认参数
num.partitions
每个新建主题的分区个数(分区个数只能增加,不能减少 )。这个参数一般要评估,比如,每秒钟要写入和读取1000M数据,如果现在每个消费者每秒钟可以处理50MB的数据,那么需要20个分区,这样就可以让20个消费者同时读取这些分区,从而达到设计目标。(一般经验,把分区大小限制在25G之内比较理想)
log.retention.hours
日志保存时间,默认为7天(168小时)。超过这个时间会清理数据。bytes和minutes无论哪个先达到都会触发。与此类似还有log.retention.minutes和log.retention.ms,都设置的话,优先使用具有最小值的那个。(提示:时间保留数据是通过检查磁盘上日志片段文件的最后修改时间来实现的。也就是最后修改时间是指日志片段的关闭时间,也就是文件里最后一个消息的时间戳)
log.retention.bytes
topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes。-1没有大小限制。log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除。(注意如果是log.retention.bytes先达到了,则是删除多出来的部分数据),一般不推荐使用最大文件删除策略,而是推荐使用文件过期删除策略。
log.segment.bytes
分区的日志存放在某个目录下诸多文件中,这些文件将分区的日志切分成一段一段的,称为日志片段。这个属性就是每个文件的最大尺寸;当尺寸达到这个数值时,就会关闭当前文件,并创建新文件。被关闭的文件就开始等待过期。默认为1G。
如果一个主题每天只接受100MB的消息,那么根据默认设置,需要10天才能填满一个文件。而且因为日志片段在关闭之前,消息是不会过期的,所以如果log.retention.hours保持默认值的话,那么这个日志片段需要17天才过期。因为关闭日志片段需要10天,等待过期又需要7天。
log.segment.ms
作用和log.segment.bytes类似,只不过判断依据是时间。同样的,两个参数,以先到的为准。这个参数默认是不开启的。
message.max.bytes
表示一个服务器能够接收处理的消息的最大字节数,注意这个值producer和consumer必须设置一致,且不要大于fetch.message.max.bytes属性的值(消费者能读取的最大消息,这个值应该大于或等于message.max.bytes)。该值默认是1000000字节,大概900KB~1MB。如果启动压缩,判断压缩后的值。这个值的大小对性能影响很大,值越大,网络和IO的时间越长,还会增加磁盘写入的大小。
Kafka设计的初衷是迅速处理短小的消息,一般10K大小的消息吞吐性能最好(LinkedIn的kafka性能测试)
硬件配置对Kafka性能的影响
为Kafka选择合适的硬件更像是一门艺术,就跟它的名字一样,分别从磁盘、内存、网络和CPU上来分析,确定了这些关注点,就可以在预算范围之内选择最优的硬件配置。
磁盘吞吐量/磁盘容量
磁盘吞吐量(IOPS 每秒的读写次数)会影响生产者的性能。因为生产者的消息必须被提交到服务器保存,大多数的客户端都会一直等待,直到至少有一个服务器确认消息已经成功提交为止。也就是说,磁盘写入速度越快,生成消息的延迟就越低。(SSD固态贵单个速度快,HDD机械偏移可以多买几个,设置多个目录加快速度,具体情况具体分析)
磁盘容量的大小,则主要看需要保存的消息数量。如果每天收到1TB的数据,并保留7天,那么磁盘就需要7TB的数据。
(磁盘容量越大越好)
内存
Kafka本身并不需要太大内存,内存则主要是影响消费者性能。在大多数业务情况下,消费者消费的数据一般会从内存(页面缓存,从系统内存中分)中获取,这比在磁盘上读取肯定要快的多。一般来说运行Kafka的JVM不需要太多的内存,剩余的系统内存可以作为页面缓存,或者用来缓存正在使用的日志片段,所以一般Kafka不会同其他的重要应用系统部署在一台服务器上,因为他们需要共享页面缓存,这个会降低Kafka消费者的性能。
(建议单独一台服务器部署kafka,提升kafka消费能力;如果想人kafka消费能力较高,请单独部署在一台服务器上)
网络
网络吞吐量决定了Kafka能够处理的最大数据流量。它和磁盘是制约Kafka拓展规模的主要因素。对于生产者、消费者写入数据和读取数据都要瓜分网络流量。同时做集群复制也非常消耗网络。
CPU
Kafka对cpu的要求不高,主要是用在对消息解压和压缩上。所以cpu的性能不是在使用Kafka的首要考虑因素。
总的来说,要为Kafka选择合适的硬件时,优先考虑存储,包括存储的大小,然后考虑生产者的性能(也就是磁盘的吞吐量),选好存储以后,再来选择CPU和内存就容易得多。网络的选择要根据业务上的情况来定,也是非常重要的一环。
选举:raft协议和zab协议
redis集群选举也是基于raft协议
Kafka生产与消费全流程
Kafka消息发送和消费的流程(非集群)
简单入门
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
producer类
必选属性
创建生产者对象时有三个属性必须指定。
bootstrap.servers
该属性指定broker的地址清单,地址的格式为host:port。
清单里不需要包含所有的broker地址,生产者会从给定的broker里查询其他broker的信息。不过最少提供2个broker的信息(用逗号分隔,比如:127.0.0.1:9092,192.168.0.13:9092),一旦其中一个宕机,生产者仍能连接到集群上。
key.serializer
生产者接口允许使用参数化类型,可以把Java对象作为键和值传broker,但是broker希望收到的消息的键和值都是字节数组,所以,必须提供将对象序列化成字节数组的序列化器。
key.serializer必须设置为实现org.apache.kafka.common.serialization.Serializer的接口类
Kafka的客户端默认提供了ByteArraySerializer,IntegerSerializer,StringSerializer,也可以实现自定义的序列化器。
三种发送方式
value.serializer
同 key.serializer。
发送并忘记
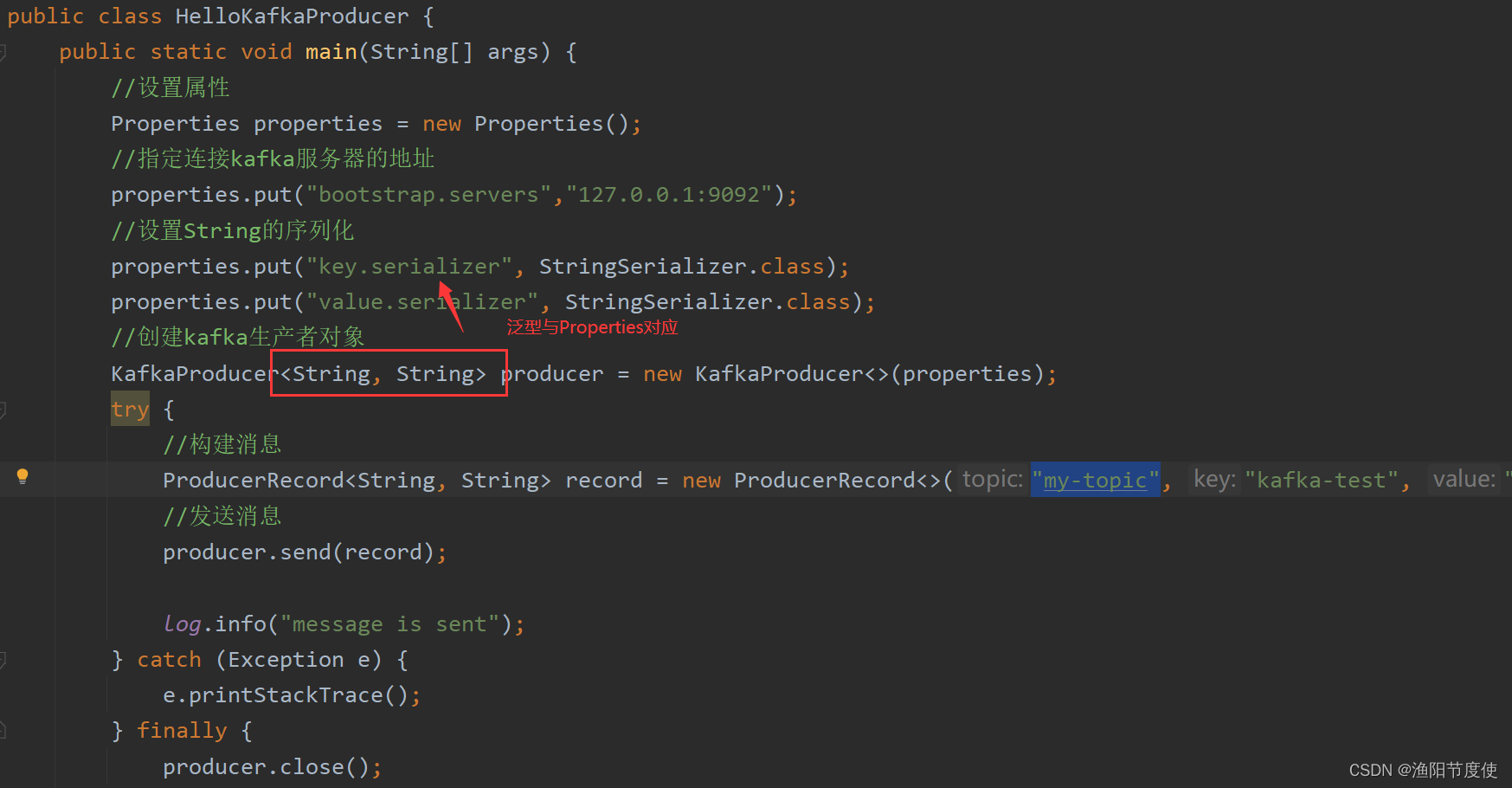
同步发送
/**
* 类说明:发送消息--同步模式
*/
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的序列化
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
try {
ProducerRecord<String,String> record;
try {
// 构建消息
record = new ProducerRecord<String,String>("my-topic", "kafka-test","yuyang");
// 发送消息
Future<RecordMetadata> future =producer.send(record);
RecordMetadata recordMetadata = future.get();
if(null!=recordMetadata){
System.out.println("offset:"+recordMetadata.offset()+","
+"partition:"+recordMetadata.partition());
}
} catch (Exception e) {
e.printStackTrace();
}
} finally {
// 释放连接
producer.close();
}
异步发送
/**
* 类说明:发送消息--异步模式
*/
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的序列化
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
try {
ProducerRecord<String,String> record;
try {
// 构建消息
record = new ProducerRecord<String,String>("msb", "teacher","lijin");
// 发送消息
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null){
// 没有异常,输出信息到控制台
System.out.println("offset:"+recordMetadata.offset()+"," +"partition:"+recordMetadata.partition());
} else {
// 出现异常打印
e.printStackTrace();
}
}
});
} catch (Exception e) {
e.printStackTrace();
}
} finally {
// 释放连接
producer.close();
}
consumer类
必选属性
创建消费者对象时一般有四个属性必须指定。
bootstrap.servers、value.Deserializer key.Deserializer 含义同生产者
可选属性
group.id 并非完全必需,它指定了消费者属于哪一个群组,但是创建不属于任何一个群组的消费者并没有问题。不过绝大部分情况都会使用群组消费。
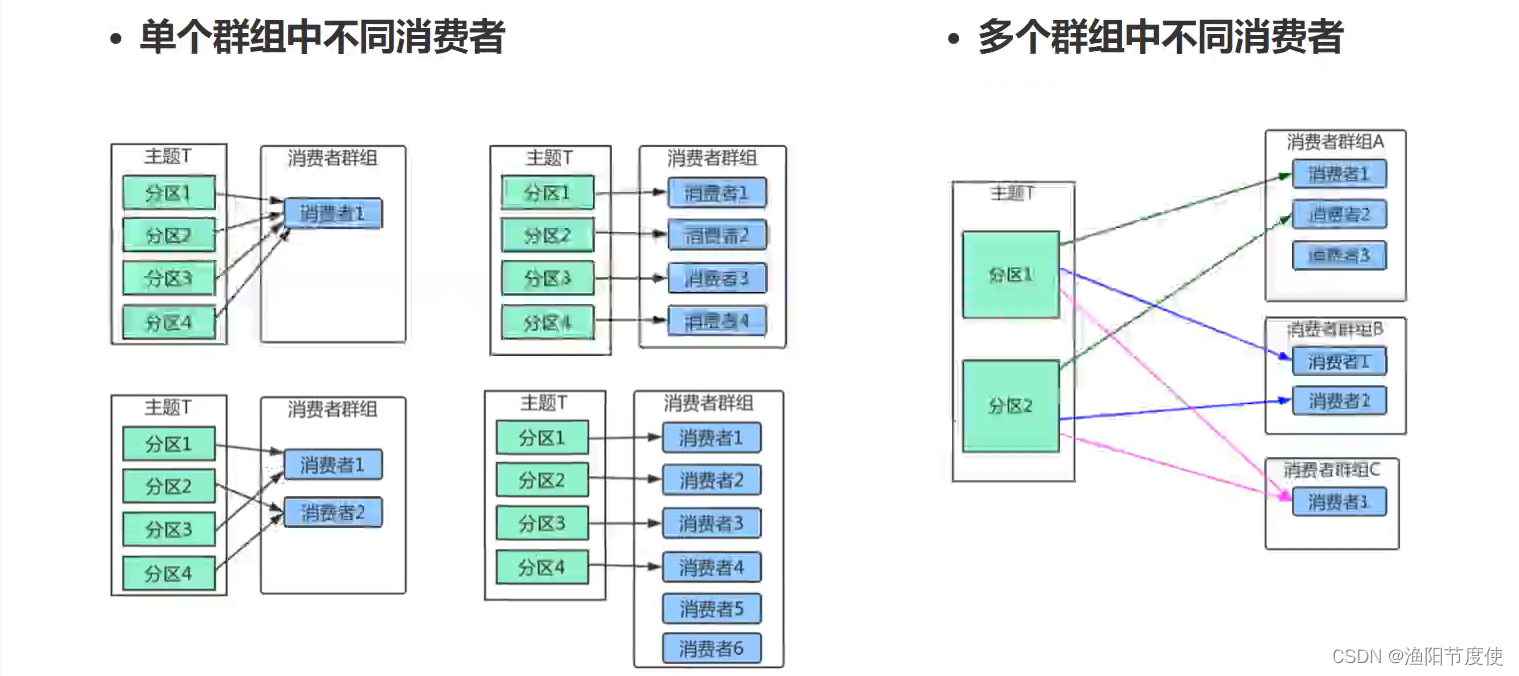
消费者群组
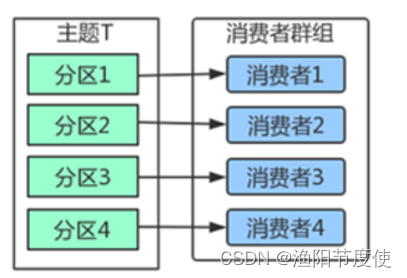
Kafka里消费者从属于消费者群组,一个群组里的消费者订阅的都是同一个主题,每个消费者接收主题一部分分区的消息。
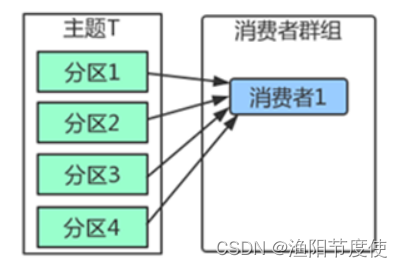
主题T有4个分区,群组中只有一个消费者,则该消费者将收到主题T1全部4个分区的消息。
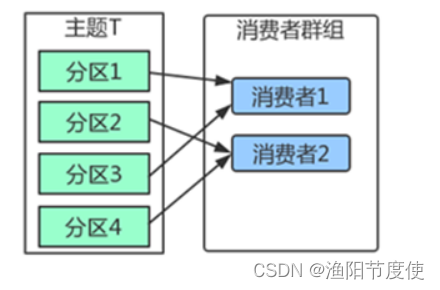
在群组中增加一个消费者2,那么每个消费者将分别从两个分区接收消息,上图中就表现为消费者1接收分区1和分区3的消息,消费者2接收分区2和分区4的消息。
群组中有4个消费者,那么每个消费者将分别从1个分区接收消息。
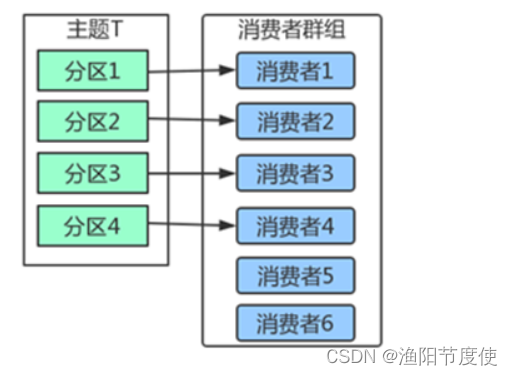
但是,当增加更多的消费者,超过了主题的分区数量,就会有一部分的消费者被闲置,不会接收到任何消息。
往消费者群组里增加消费者是进行横向伸缩能力的主要方式。所以有必要为主题设定合适规模的分区,在负载均衡的时候可以加入更多的消费者。但是要记住,一个群组里消费者数量超过了主题的分区数量,多出来的消费者是没有用处的。
消费者代码
序列化
自定义序列化,反序列化器
创建生产者对象必须指定序列化器,默认的序列化器并不能满足所有的场景。完全可以自定义序列化器。只要实现org.apache.kafka.common.serialization.Serializer接口即可。
自定义序列化
实体类
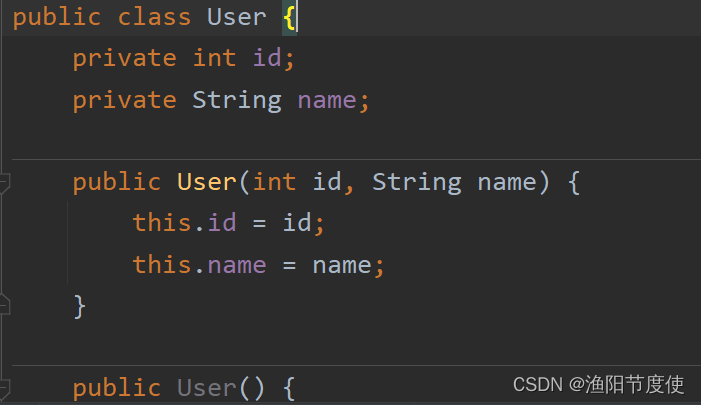
id的长度4个字节,字符串的长度描述4个字节, 字符串本身的长度nameSize个字节
序列化器
/**
* @author
* 自定义序列化器
* @create 2023-08-04 12:20
*/
public class UserSerializer implements Serializer<User> {
public byte[] serialize(String topic, User data) {
try {
byte[] name;
int nameSize;
if(data==null){
return null;
}
if(data.getName()!=null){
name = data.getName().getBytes("UTF-8");
//字符串的长度
nameSize = data.getName().length();
}else{
name = new byte[0];
nameSize = 0;
}
/*id的长度4个字节,字符串的长度描述4个字节,
字符串本身的长度nameSize个字节*/
ByteBuffer buffer = ByteBuffer.allocate(4+4+nameSize);
buffer.putInt(data.getId());//4
buffer.putInt(nameSize);//4
buffer.put(name);//nameSize
return buffer.array();
} catch (Exception e) {
throw new SerializationException("Error serialize User:"+e);
}
}
}
自定义序列化容易导致程序的脆弱性。上面的实现里,有多种类型的消费者,每个消费者对实体字段都有各自的需求,比如,有的将字段变更为long型,有的会增加字段,这样会出现新旧消息的兼容性问题。特别是在系统升级的时候,经常会出现一部分系统升级,其余系统被迫跟着升级的情况。
解决这个问题,可以考虑使用自带格式描述以及语言无关的序列化框架。比如Protobuf,Kafka官方推荐的Apache Avro
分区
因为在Kafka中一个topic可以有多个partition,所以当一个生产发送消息,这条消息应该发送到哪个partition,这个过程就叫做分区。
在新建消息的时候,可以指定partition,只要指定partition,那么分区器的策略则失效。

系统分区器
DefaultPartitioner 默认分区策略
全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略
采用默认分区的方式,键的主要用途有两个:
一,用来决定消息被写往主题的哪个分区,拥有相同键的消息将被写往同一个分区。
二,还可以作为消息的附加消息。
RoundRobinPartitioner 分区策略
全路径类名:org.apache.kafka.clients.producer.internals.RoundRobinPartitioner
- 如果消息中指定了分区,则使用它
- 将消息平均的分配到每个分区中。
即key为null,那么这个时候一般也会采用RoundRobinPartitioner
UniformStickyPartitioner 纯粹的粘性分区策略
全路径类名:org.apache.kafka.clients.producer.internals.UniformStickyPartitioner
他跟DefaultPartitioner 分区策略的唯一区别就是。
DefaultPartitionerd 如果有key的话,那么它是按照key来决定分区的,这个时候并不会使用粘性分区
UniformStickyPartitioner 是不管你有没有key, 统一都用粘性分区来分配
另外关于粘性分区策略
从客户端最新的版本上来看(3.3.1),有两个序列化器已经进入 弃用阶段。
这个客户端在3.1.0都还不是这样。关于粘性分区策略
如果感兴趣可以看下这篇文章
自定义分区器
/**
* 类说明:自定义分区器,以value值进行分区
*/
public class SelfPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
int num = partitionInfos.size();
int parId = Utils.toPositive(Utils.murmur2(valueBytes)) % num;//来自DefaultPartitioner的处理
return parId;
}
}
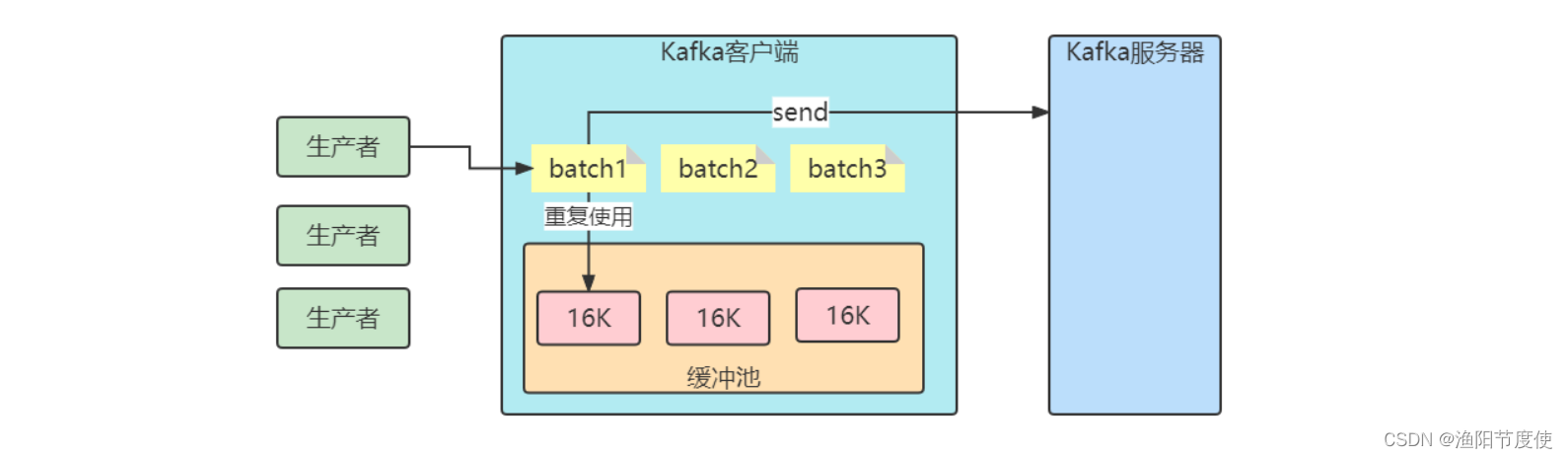
生产缓冲机制
客户端发送消息给kafka服务器的时候、消息会先写入一个内存缓冲中,然后直到多条消息组成了一个Batch,才会一次网络通信把Batch发送过去。
主要有以下参数:
buffer.memory
设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果数据产生速度大于向broker发送的速度,导致生产者空间不足,producer会阻塞或者抛出异常。缺省33554432 (32M)
buffer.memory: 所有缓存消息的总体大小超过这个数值后,就会触发把消息发往服务器。此时会忽略batch.size和linger.ms的限制。
buffer.memory的默认数值是32 MB,对于单个 Producer 来说,可以保证足够的性能。 需要注意的是,如果您在同一个JVM中启动多个 Producer,那么每个 Producer 都有可能占用 32 MB缓存空间,此时便有可能触发 OOM。
batch.size
当多个消息被发送同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次内存被填满后,批次里的所有消息会被发送出去。但是生产者不一定都会等到批次被填满才发送,半满甚至只包含一个消息的批次也有可能被发送(linger.ms控制)。缺省16384(16k) ,如果一条消息超过了批次的大小,会写不进去。
linger.ms
指定了生产者在发送批次前等待更多消息加入批次的时间。它和batch.size以先到者为先。也就是说,一旦获得消息的数量够batch.size的数量了,他将会立即发送而不顾这项设置,然而如果获得消息字节数比batch.size设置要小的多,需要“linger”特定的时间以获取更多的消息。这个设置默认为0,即没有延迟。设定linger.ms=5,例如,将会减少请求数目,但是同时会增加5ms的延迟,但也会提升消息的吞吐量。
为何要设计缓冲机制
(算一道面试题)
1、减少IO的开销(单个 ->批次)但是这种情况基本上也只是linger.ms配置>0的情况下才会有,因为默认inger.ms=0的,所以基本上有消息进来了就发送了,跟单条发送是差不多!!
2、减少Kafka中Java客户端的GC。
比如缓冲池大小是32MB。然后把32MB划分为N多个内存块,比如说一个内存块是16KB(batch.size),这样的话这个缓冲池里就会有很多的内存块。
你需要创建一个新的Batch,就从缓冲池里取一个16KB的内存块就可以了,然后这个Batch就不断的写入消息
下次别人再要构建一个Batch的时候,再次使用缓冲池里的内存块就好了。这样就可以利用有限的内存,对他不停的反复重复的利用。因为如果你的Batch使用完了以后是把内存块还回到缓冲池中去,那么就不涉及到垃圾回收了。
消费者偏移量提交
一般情况下,调用poll方法的时候,broker返回的是生产者写入Kafka同时kafka的消费者提交偏移量,这样可以确保消费者消息消费不丢失也不重复,所以一般情况下Kafka提供的原生的消费者是安全的,但是事情会这么完美吗?
自动提交
最简单的提交方式是让消费者自动提交偏移量。 如果enable.auto.commit被设为 true,消费者会自动把从poll()方法接收到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认值是5s。
自动提交是在轮询里进行的,消费者每次在进行轮询时会检査是否该提交偏移量了,如果是,那么就会提交从上一次轮询返回的偏移量。
不过,在使用这种简便的方式之前,需要知道它将会带来怎样的结果。
假设仍然使用默认的5s提交时间间隔, 在最近一次提交之后的3s发生了再均衡,再均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后了3s,所以在这3s内到达的消息会被重复处理。可以通过修改提交时间间隔来更频繁地提交偏移量, 减小可能出现重复消息的时间窗, 不过这种情况是无法完全避免的。
在使用自动提交时,每次调用轮询方法都会把上一次调用返回的最大偏移量提交上去,它并不知道具体哪些消息已经被处理了,所以在再次调用之前最好确保所有当前调用返回的消息都已经处理完毕(enable.auto.comnit被设为 true时,在调用 close()方法之前也会进行自动提交)。一般情况下不会有什么问题,不过在处理异常或提前退出轮询时要格外小心。
消费者的配置参数
auto.offset.reset
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
只要group.Id不变,不管auto.offset.reset 设置成什么值,都从上一次的消费结束的地方开始消费。
Kafka的消费全流程
消费者组群
kafka的群组消费—负载均衡建立在分区级别
一个分区不能同时给一个消费者群组中的多个消费者消费
RocketMQ顺序消费,消息取模
Kafka的消费全流程
多线程安全问题
当前系统线程核心数
Runtime.getRuntime().availableProcessors()
Kafka的Producer(生产者)是原始线程安全的
利用final修饰确保线程安全
/**
* 类说明:多线程下使用生产者
*/
public class KafkaConProducer {
//发送消息的个数
private static final int MSG_SIZE = 1000;
//负责发送消息的线程池
private static ExecutorService executorService = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors());
private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE);
private static User makeUser(int id){
User user = new User(id);
String userName = "msb_"+id;
user.setName(userName);
return user;
}
/*发送消息的任务*/
private static class ProduceWorker implements Runnable{
private ProducerRecord<String,String> record;
private KafkaProducer<String,String> producer;
public ProduceWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) {
this.record = record;
this.producer = producer;
}
public void run() {
final String id = Thread.currentThread().getId() +"-"+System.identityHashCode(producer);
try {
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(null!=exception){
exception.printStackTrace();
}
if(null!=metadata){
System.out.println(id+"|" +String.format("偏移量:%s,分区:%s", metadata.offset(),
metadata.partition()));
}
}
});
System.out.println(id+":数据["+record+"]已发送。");
countDownLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的序列化
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
try {
for(int i=0;i<MSG_SIZE;i++){
User user = makeUser(i);
ProducerRecord<String,String> record = new ProducerRecord<String,String>("concurrent-test",null,
System.currentTimeMillis(), user.getId()+"", user.toString());
executorService.submit(new ProduceWorker(record,producer));
}
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
executorService.shutdown();
}
}
}
KafkaConsumer的实现 不是 线程安全的
实现消费者多线程最常见的方式: 线程封闭 ——即为每个线程实例化一个 KafkaConsumer对象
/**
* 类说明:多线程下正确的使用消费者,需要记住,一个线程一个消费者
*/
public class KafkaConConsumer {
public static final int CONCURRENT_PARTITIONS_COUNT = 2;
private static ExecutorService executorService = Executors.newFixedThreadPool(CONCURRENT_PARTITIONS_COUNT);
private static class ConsumerWorker implements Runnable{
private KafkaConsumer<String,String> consumer;
public ConsumerWorker(Map<String, Object> config, String topic) {
Properties properties = new Properties();
properties.putAll(config);
this.consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList(topic));
}
public void run() {
final String ThreadName = Thread.currentThread().getName();
try {
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for(ConsumerRecord<String, String> record:records){
System.out.println(ThreadName+"|"+String.format(
"主题:%s,分区:%d,偏移量:%d," +
"key:%s,value:%s",
record.topic(),record.partition(),
record.offset(),record.key(),record.value()));
//do our work
}
}
} finally {
consumer.close();
}
}
}
public static void main(String[] args) {
/*消费配置的实例*/
Map<String,Object> properties = new HashMap<String, Object>();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"c_test");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
for(int i = 0; i<CONCURRENT_PARTITIONS_COUNT; i++){
//一个线程一个消费者
executorService.submit(new ConsumerWorker(properties, "concurrent-test"));
}
}
}
群组协调
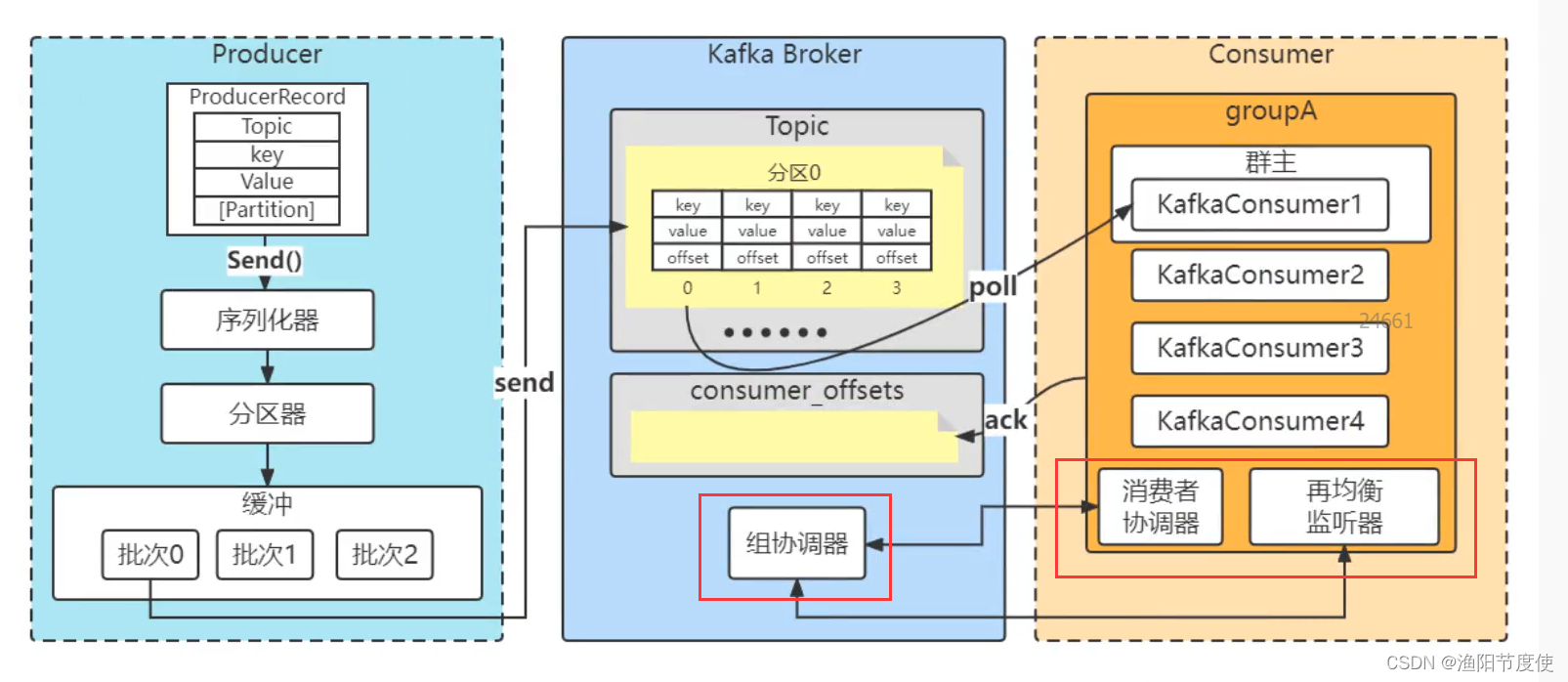
消费者要加入群组时,会向群组协调器发送一个JoinGroup请求,第一个加入群主的消费者成为群主,群主会获得群组的成员列表,并负责给每一个消费者分配分区。分配完毕后,群主把分配情况发送给群组协调器,协调器再把这些信息发送给所有的消费者,每个消费者只能看到自己的分配信息,只有群主知道群组里所有消费者的分配信息。群组协调的工作会在消费者发生变化(新加入或者掉线),主题中分区发生了变化(增加)时发生。
组协调器
组协调器是Kafka服务端(Broker)自身维护的。
组协调器( GroupCoordinator )可以理解为各个消费者协调器的一个中央处理器, 每个消费者的所有交互都是和组协调器( GroupCoordinator )进行的。
- 选举Leader消费者客户端
- 处理申请加入组的客户端
- 再平衡后同步新的分配方案
- 维护与客户端的心跳检测
- 管理消费者已消费偏移量,并存储至
__consumer_offset中
kafka上的组协调器( GroupCoordinator )协调器有很多,有多少个 __consumer_offset分区, 那么就有多少个组协调器( GroupCoordinator )
默认情况下, __consumer_offset有50个分区, 每个消费组都会对应其中的一个分区,对应的逻辑为 hash(group.id)%分区数。
消费者协调器
每个客户端(消费者的客户端)都会有一个消费者协调器, 他的主要作用就是向组协调器发起请求做交互, 以及处理回调逻辑
- 向组协调器发起入组请求
- 向组协调器发起同步组请求(如果是Leader客户端,则还会计算分配策略数据放到入参传入)
- 发起离组请求
- 保持跟组协调器的心跳线程
- 向组协调器发送提交已消费偏移量的请求
消费者加入分组的流程
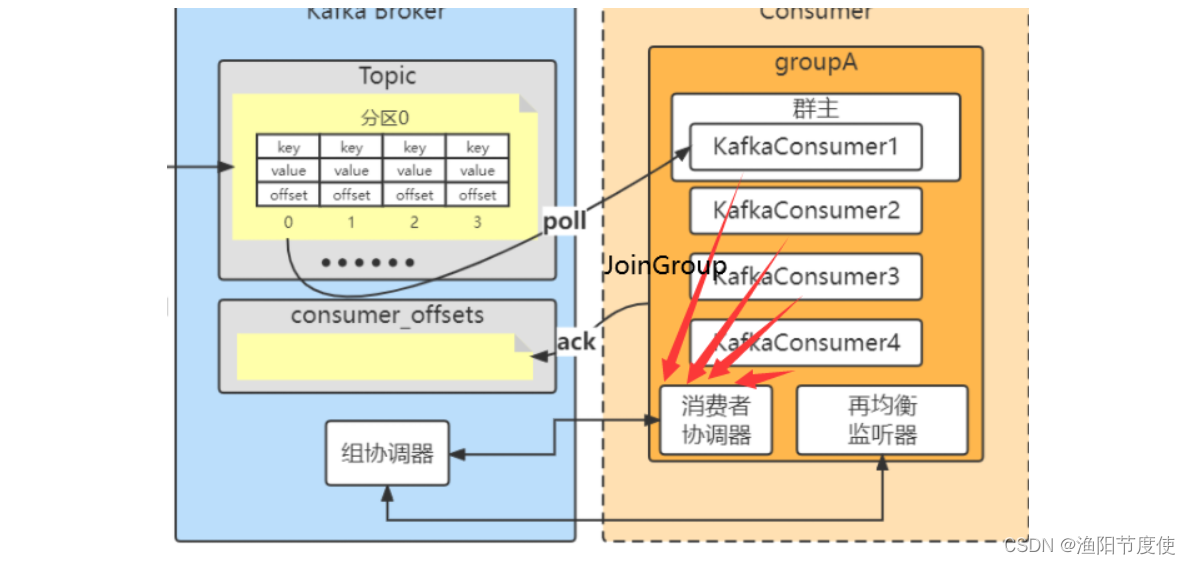
1、客户端启动的时候, 或者重连的时候会发起JoinGroup的请求来申请加入的组中。
2、当前客户端都已经完成JoinGroup之后, 客户端会收到JoinGroup的回调, 然后客户端会再次向组协调器发起SyncGroup的请求来获取新的分配方案
3、当消费者客户端关机/异常 时, 会触发离组LeaveGroup请求。
当然有主动的消费者协调器发起离组请求,也有组协调器一直会有针对每个客户端的心跳检测, 如果监测失败,则就会将这个客户端踢出Group。
4、客户端加入组内后, 会一直保持一个心跳线程,来保持跟组协调器的一个感知。
并且组协调器会针对每个加入组的客户端做一个心跳监测,如果监测到过期, 则会将其踢出组内并再平衡。
消费者消费的offset的存储
consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
consumer_offsets 是 kafka 自行创建的,和普通的 topic 相同。它存在的目的之一就是保存 consumer 提交的位移。
kafka-consumer-groups.bat --bootstrap-server :9092 --group c_test --describe
使用 kafka 提供的脚本查询某消费者组的元数据信息
Math.abs(groupID.hashCode()) % numPartitions,
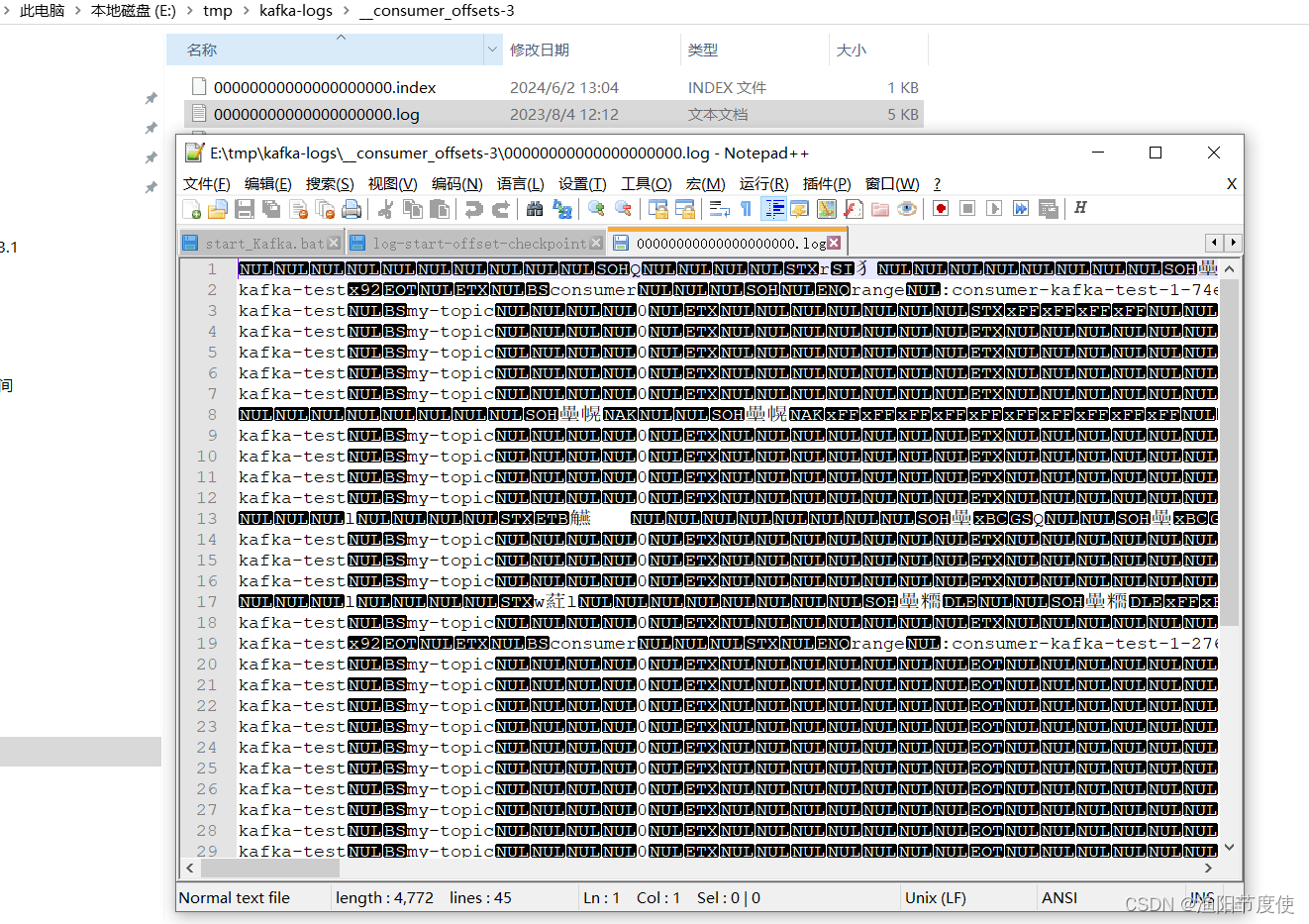
_consumer_offsets 的每条消息格式大致如图所示
可以想象成一个 KV 格式的消息,key 就是一个三元组:group.id+topic+分区号,而 value 就是 offset 的值
分区再均衡
当消费者群组里的消费者发生变化,或者主题里的分区发生了变化,都会导致再均衡现象的发生。Kafka中,存在着消费者对分区所有权的关系。
这样无论是消费者变化,比如增加了消费者,新消费者会读取原本由其他消费者读取的分区,消费者减少,原本由它负责的分区要由其他消费者来读取,增加了分区,哪个消费者来读取这个新增的分区,这些行为,都会导致分区所有权的变化,这种变化就被称为 再均衡 。
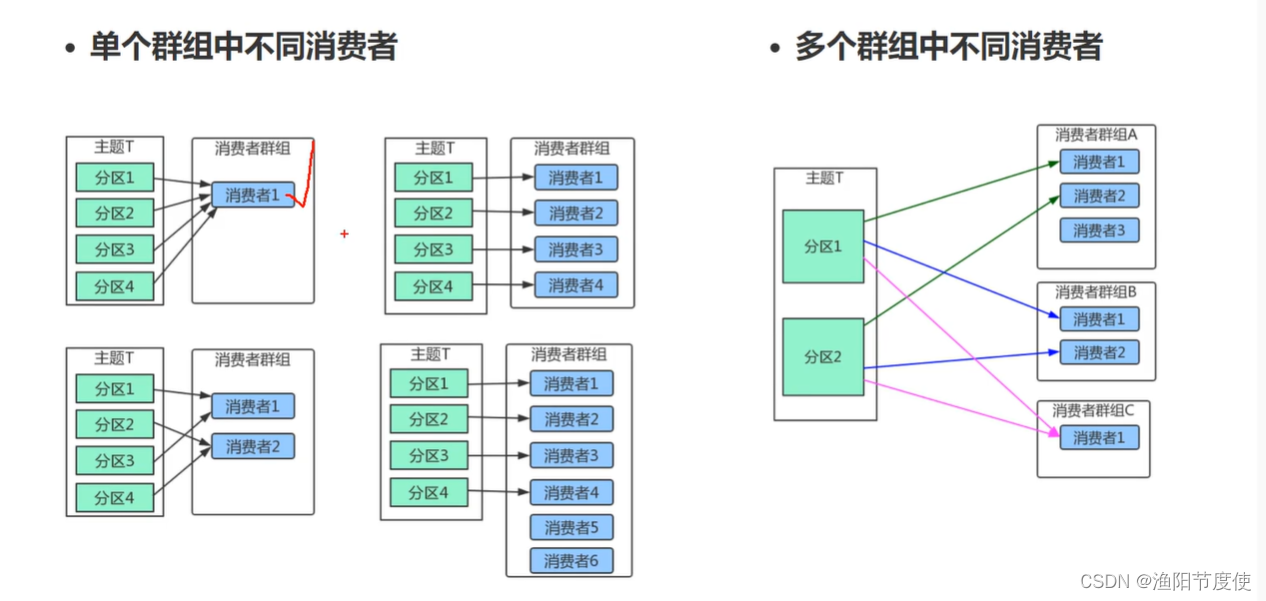
再均衡对Kafka很重要,这是消费者群组带来高可用性和伸缩性的关键所在。不过一般情况下,尽量减少再均衡,因为再均衡期间,消费者是无法读取消息的,会造成整个群组一小段时间的不可用。
消费者通过向称为群组协调器的broker(不同的群组有不同的协调器)发送心跳来维持它和群组的从属关系以及对分区的所有权关系。如果消费者长时间不发送心跳,群组协调器认为它已经死亡,就会触发一次再均衡。
心跳由单独的线程负责,相关的控制参数为max.poll.interval.ms。
消费者提交偏移量导致的问题
当调用poll方法的时候,broker返回的是生产者写入Kafka但是还没有被消费者读取过的记录,消费者可以使用Kafka来追踪消息在分区里的位置,称之为 偏移量 。消费者更新自己读取到哪个消息的操作,称之为 提交 。
消费者是如何提交偏移量的呢?消费者会往一个叫做_consumer_offset的特殊主题发送一个消息,里面会包括每个分区的偏移量。发生了再均衡之后,消费者可能会被分配新的分区,为了能够继续工作,消费者者需要读取每个分区最后一次提交的偏移量,然后从指定的地方,继续做处理。
分区再均衡的例子:
某软件公司,有一个项目,有两块的工作,有两个码农,一个小王、一个小李,一个负责一块(分区消费),干得好好的。突然一天,小王桌子一拍不干了,老子中了5百万了,不跟你们玩了,立马收拾完电脑就走了。这个时候小李就必须承担两块工作,这个时候就是发生了分区再均衡。
过了几天,你入职,一个萝卜一个坑,你就入坑了,你承担了原来小王的工作。这个时候又会发生了分区再均衡。
1)如果提交的偏移量小于消费者实际处理的最后一个消息的偏移量,处于两个偏移量之间的消息会被重复处理,
2)如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失
创建一个分区数是3的主题rebalance
kafka-topics.bat --bootstrap-server localhost:9092 --create --topic rebalance --replication-factor 1 --partitions 3
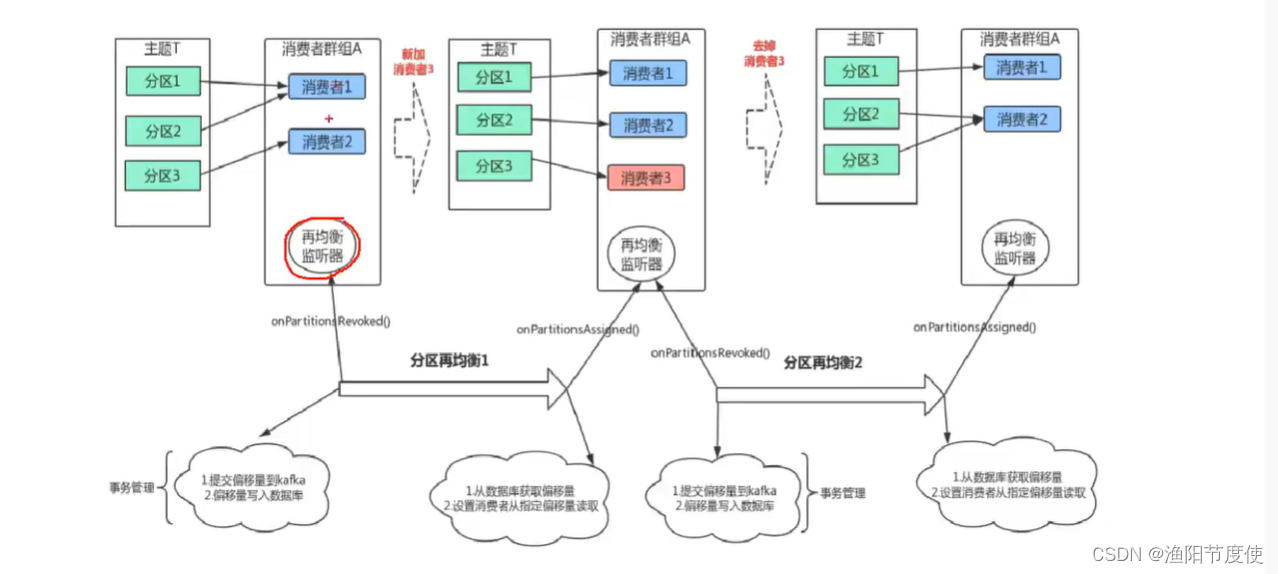
在为消费者分配新分区或移除旧分区时,可以通过消费者API执行一些应用程序代码,在调用 subscribe()方法时传进去一个 ConsumerRebalancelistener实例就可以了。
ConsumerRebalancelistener有两个需要实现的方法。
- public void
onPartitionsRevoked( Collection< TopicPartition> partitions)方法会在
再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管分区的消费者就知道该从哪里开始读取了
- public void
onPartitionsAssigned( Collection< TopicPartition> partitions)方法会在重新分配分区之后和消费者开始读取消息之前被调用。
具体使用 ,先创建一个3分区的主题,然后实验,
在再均衡开始之前会触发onPartitionsRevoked方法
在再均衡开始之后会触发onPartitionsAssigned方法
Kafka集群与可靠性
目标
1、高并发
2、高可用(防数据丢失)
3、动态伸缩
集群规模如何预估
吞吐量:
集群可以提高处理请求的能力。单个Broker的性能不足,可以通过扩展broker来解决。
磁盘空间:
比如,如果一个集群有10TB的数据需要保留,而每个broker可以存储2TB,那么至少需要5个broker。如果启用了数据复制,则还需要一倍的空间,那么这个集群需要10个broker。
Kafka集群原理
成员关系与控制器
控制器其实就是一个broker, 只不过它除了具有一般 broker的功能之外, 还负责分区首领的选举。
当控制器发现一个broker加入集群时, 它会使用 broker ID来检査新加入的 broker是否包含现有分区的副本。 如果有, 控制器就把变更通知发送给新加入的 broker和其他 broker, 新 broker上的副本开始从首领那里复制消息。
简而言之, Kafka使用 Zookeeper的临时节点来选举控制器,并在节点加入集群或退出集群时通知控制器。 控制器负责在节点加入或离开集群时进行分区首领选举。
集群工作机制
复制功能是 Kafka 架构的核心。在 Kafka 的文档里, Kafka 把自己描述成“一个分布式的、可分区的、可复制的提交日志服务”。
复制之所以这么关键, 是因为它可以在个别节点失效时仍能保证 Kafka 的可用性和持久性。
Kafka 使用主题来组织数据, 每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存在 broker 上, 每个 broker 可以保存成百上千个属于 不同主题和分区的副本。
replication-factor参数
比如我们创建一个lijin的主题,复制因子是2,分区数是2
./kafka-topics.sh --bootstrap-server 192.168.10.7:9092 --create --topic lijin --replication-factor 2 --partitions 2
replication-factor用来设置主题的副本数。每个主题可以有多个副本,副本位于集群中不同的 broker 上,也就是说副本的数量不能超过 broker 的数量。

从这里可以看出,lijin分区有两个分区,partition0和partition1 ,其中
在partition0 中,broker1(broker.id =0)是Leader,broker2(broker.id =1)是跟随副本。
在partition1 中,broker2(broker.id =1)是Leader,broker1(broker.id =0)是跟随副本。

首领副本
每个分区都有一个首领副本。为了保证一致性,所有生产者请求和消费者请求都会经过这个副本 。
跟随者副本
首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一一的任务就是从首领那里复制消息, 保持与首领一致的状态 。 如果首领发生崩溃, 其中的一个跟随者会被提升为新首领 。
auto.leader.rebalance.enable参数
是否允许定期进行 Leader 选举。
设置它的值为true表示允许Kafka定期地对一些Topic 分区进行Leader重选举,当然这个重选举不是无脑进行的,它要满足一定的条件才会发生。
比如Leader A一直表现得很好,但若auto.leader.rebalance.enable=true,那么有可能一段时间后Leader A就要被强行卸任换成Leader B。
你要知道换一次Leader 代价很高的,原本向A发送请求的所有客户端都要切换成向B发送请求,而且这种换Leader本质上没有任何性能收益,因此建议在生产环境中把这个参数设置成false。
集群消息生产
复制系数、不完全的首领选举、最少同步副本
可靠系统里的生产者
发送确认机制
3 种不同的确认模式。
acks=0 意味着如果生产者能够通过网络把消息发送出去,那么就认为消息已成功写入Kafka 。
acks=1 意味若首领在收到消息并把它写入到分区数据文件(不一定同步到磁盘上)时会返回确认或错误响应。
acks=all 意味着首领在返回确认或错误响应之前,会等待(min.insync.replicas)同步副本都收到悄息。
ISR
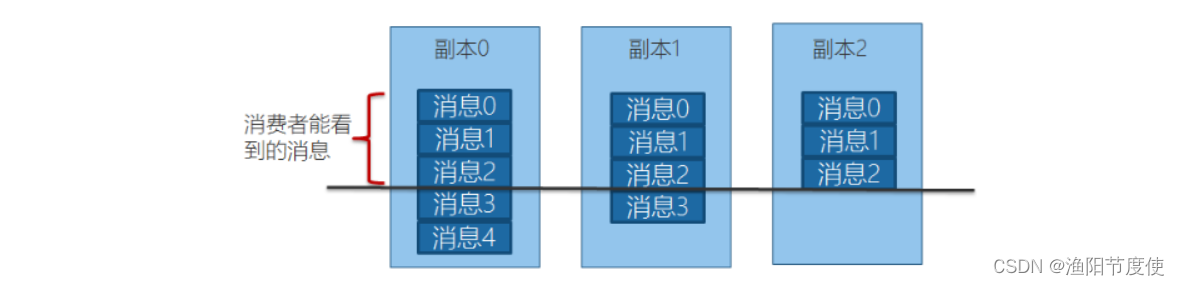
Kafka的数据复制是以Partition为单位的。而多个备份间的数据复制,通过Follower向Leader拉取数据完成。从一这点来讲,有点像Master-Slave方案。不同的是,Kafka既不是完全的同步复制,也不是完全的异步复制,而是基于ISR的动态复制方案。
ISR,也即In-Sync Replica。每个Partition的Leader都会维护这样一个列表,该列表中,包含了所有与之同步的Replica(包含Leader自己)。每次数据写入时,只有ISR中的所有Replica都复制完,Leader才会将其置为Commit,它才能被Consumer所消费。
这种方案,与同步复制非常接近。但不同的是,这个ISR是由Leader动态维护的。如果Follower不能紧“跟上”Leader,它将被Leader从ISR中移除,待它又重新“跟上”Leader后,会被Leader再次加加ISR中。每次改变ISR后,Leader都会将最新的ISR持久化到Zookeeper中。
至于如何判断某个Follower是否“跟上”Leader,不同版本的Kafka的策略稍微有些区别。
从0.9.0.0版本开始,replica.lag.max.messages被移除,故Leader不再考虑Follower落后的消息条数。另外,Leader不仅会判断Follower是否在replica.lag.time.max.ms时间内向其发送Fetch请求,同时还会考虑Follower是否在该时间内与之保持同步。
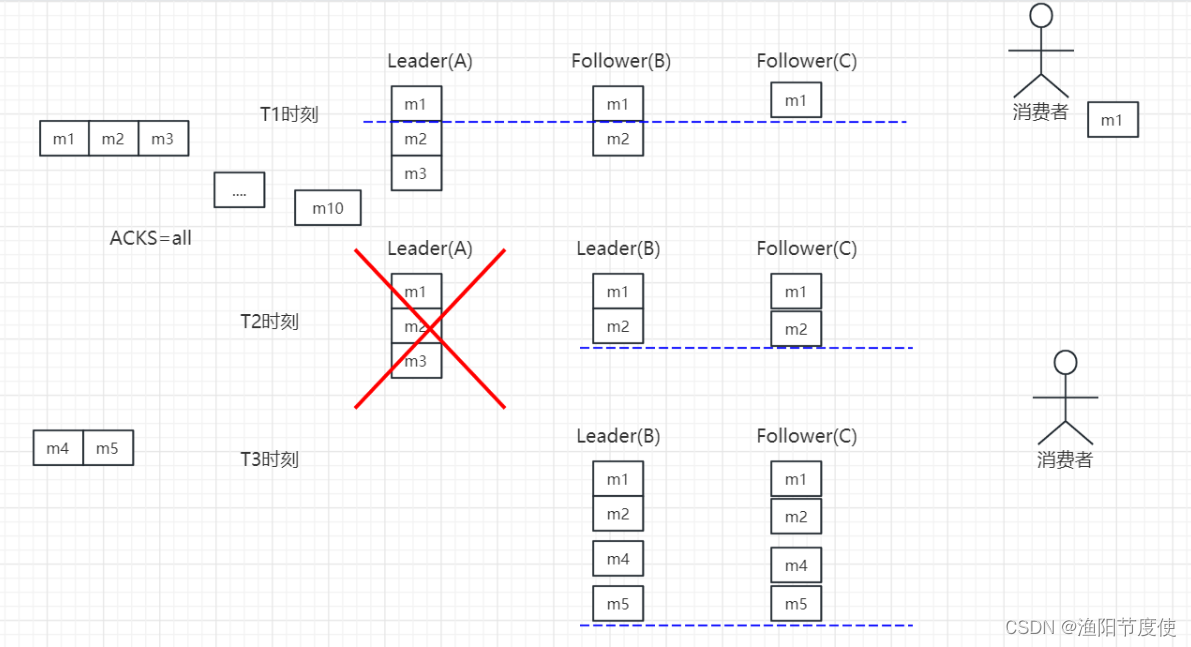
在第一步中,Leader A总共收到3条消息,但由于ISR中的Follower只同步了第1条消息(m1),故只有m1被Commit,也即只有m1可被Consumer消费。此时Follower B与Leader A的差距是1,而Follower C与Leader A的差距是2,虽然有消息的差距,但是满足同步副本的要求保留在ISR中。
在第二步中,由于旧的Leader A宕机,新的Leader B在replica.lag.time.max.ms时间内未收到来自A的Fetch请求,故将A从ISR中移除,此时ISR={B,C}。同时,由于此时新的Leader B中只有2条消息,并未包含m3(m3从未被任何Leader所Commit),所以m3无法被Consumer消费。
使用ISR方案的原因
由于Leader可移除不能及时与之同步的Follower,故与同步复制相比可避免最慢的Follower拖慢整体速度,也即ISR提高了系统可用性。
ISR中的所有Follower都包含了所有Commit过的消息,而只有Commit过的消息才会被Consumer消费,故从Consumer的角度而言,ISR中的所有Replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。
ISR相关配置说明
Broker的min.insync.replicas参数指定了Broker所要求的ISR最小长度,默认值为1。也即极限情况下ISR可以只包含Leader。但此时如果Leader宕机,则该Partition不可用,可用性得不到保证。
只有被ISR中所有Replica同步的消息才被Commit,但Producer发布数据时,Leader并不需要ISR中的所有Replica同步该数据才确认收到数据。Producer可以通过acks参数指定最少需要多少个Replica确认收到该消息才视为该消息发送成功。acks的默认值是1,即Leader收到该消息后立即告诉Producer收到该消息,此时如果在ISR中的消息复制完该消息前Leader宕机,那该条消息会丢失。而如果将该值设置为0,则Producer发送完数据后,立即认为该数据发送成功,不作任何等待,而实际上该数据可能发送失败,并且Producer的Retry机制将不生效。
更推荐的做法是,将acks设置为all或者-1,此时只有ISR中的所有Replica都收到该数据(也即该消息被Commit),Leader才会告诉Producer该消息发送成功,从而保证不会有未知的数据丢失。
总之
设置acks=all,且副本数为3
极端情况1:
默认min.insync.replicas=1,极端情况下如果ISR中只有leader一个副本时满足min.insync.replicas=1这个条件,此时producer发送的数据只要leader同步成功就会返回响应,如果此时leader所在的broker crash了,就必定会丢失数据!这种情况不就和acks=1一样了!所以我们需要适当的加大min.insync.replicas的值。
极端情况2:
min.insync.replicas=3(等于副本数),这种情况下要一直保证ISR中有所有的副本,且producer发送数据要保证所有副本写入成功才能接收到响应!一旦有任何一个broker crash了,ISR里面最大就是2了,不满足min.insync.replicas=3,就不可能发送数据成功了!
根据这两个极端的情况可以看出min.insync.replicas的取值,是kafka系统可用性和数据可靠性的平衡!
减小 min.insync.replicas 的值,一定程度上增大了系统的可用性,允许kafka出现更多的副本broker crash并且服务正常运行;但是降低了数据可靠性,可能会丢数据(极端情况1)。
增大 min.insync.replicas 的值,一定程度上增大了数据的可靠性,允许一些broker crash掉,且不会丢失数据(只要再次选举的leader是从ISR中选举的就行);但是降低了系统的可用性,会允许更少的broker crash(极端情况2)。
深入理解Kafka
深入理解Kafka-消费者源码分析
深入理解Kafka-网络通讯模型
Kafka与Spring整合及流计算
Kafka时间轮算法与常见问题
rocketmq高可用
NameServer集群
broker:
主从集群,故障转移
同步刷盘机制
kafka高可用
controller(master节点)
zookeeper
isr机制
副本机制
分区机制
故障转移
reblance重分配机制















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









