







 本文详细介绍了决策树的基础知识,包括熵、信息增益、基尼不纯度等概念。阐述了ID3、C4.5和CART算法的工作原理,以及它们在分类和回归问题中的应用。此外,还讨论了决策树的过拟合问题,提出了剪枝策略,包括先剪枝和后剪枝,以及如何通过验证集来选择最佳剪枝方案。最后,提到了Python中绘制决策树的方法。
本文详细介绍了决策树的基础知识,包括熵、信息增益、基尼不纯度等概念。阐述了ID3、C4.5和CART算法的工作原理,以及它们在分类和回归问题中的应用。此外,还讨论了决策树的过拟合问题,提出了剪枝策略,包括先剪枝和后剪枝,以及如何通过验证集来选择最佳剪枝方案。最后,提到了Python中绘制决策树的方法。
熵(entropy):是一种不确定性的度量,在一般情况下香农熵的公式表示为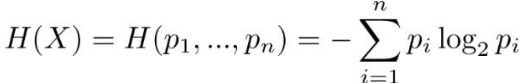
熵的性质:(1)均匀分布具有最大的不确定性
(2)对于独立事件,不确定性是可以相加的
(3)加入发生为0的事件并不会影响结果
(4)不确定性的度量应该是联系的
(5)具有更多可能结果的均匀分布可能有更大的不确定性
(6)事件用于非负的不确定性
(7)有确定结果的事件具有0不确定性
(8)掉转参数顺序没有影响
联合熵:是一集变量之间不确定性的衡量手段

条件熵:H(Y|X)表示在随机表量X的情况下随机变量Y的不确定性

信息增益:在决策树算法中用来衡量特征选择的好坏,在概率中表示为待分类的集合的熵与选定某个条件下熵之间的差
![]()

基尼不纯度:是指将来自集合中的某种结果随机应用在集合中,某一数据项的预期误差率
公式:IG(f)=∑i=1mfi(1−fi)=∑i=1mfi−∑i=1mf2i=1−∑i=1mf2i
性质:(1)基尼不纯度越小,纯度越高,集合的有序程度越高,分类的效果越好
(2)基尼不纯度为 0 时,表示集合类别一致
(3)基尼不纯度最高(纯度最低)时,f1=f2=…=fm=1m,IG(f)=1−(1m)2×m=1−1m
决策树:分为回归树和分类树,一种是对连续变量作分类一种是对离散变量作分类
不同的分类算法:
1、ID3算法介绍
ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。ID3算法, 即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法.在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策空间。
2、C4.5算法介绍
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。 C4.5由J.Ross Quinlan在ID3的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。
3、CART分类树
CART算法有两步:
决策树生成和剪枝。
决策树生成:递归地构建二叉决策树的过程,基于训练数据集生成决策树,生成的决策树要尽量大;
自上而下从根开始建立节点,在每个节点处要选择一个最好的属性来分裂,使得子节点中的训练集尽量的纯。
不同的算法使用不同的指标来定义"最好":
分类问题,可以选择GINI,双化或有序双化;
回归问题,可以使用最小二乘偏差(LSD)或最小绝对偏差(LAD)。
决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。
这里用代价复杂度剪枝 Cost-Complexity Pruning(CCP)
回归树的生成
回归树模型表示为:

其中,数据空间被划分成了 R1~Rm 单元,每个单元上有一个固定的输出值 cm。
这样就可以计算模型输出值与实际值的误差:

我们希望每个单元上的 cm,可以使得这个平方误差最小化,易知当 cm 为相应单元上的所有实际值的均值时,可以达到最优:

那么如何生成这些单元划分?
假设,我们选择变量 xj 为切分变量,它的取值 s 为切分点,那么就会得到两个区域:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3271
3271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









