







一、例子说明
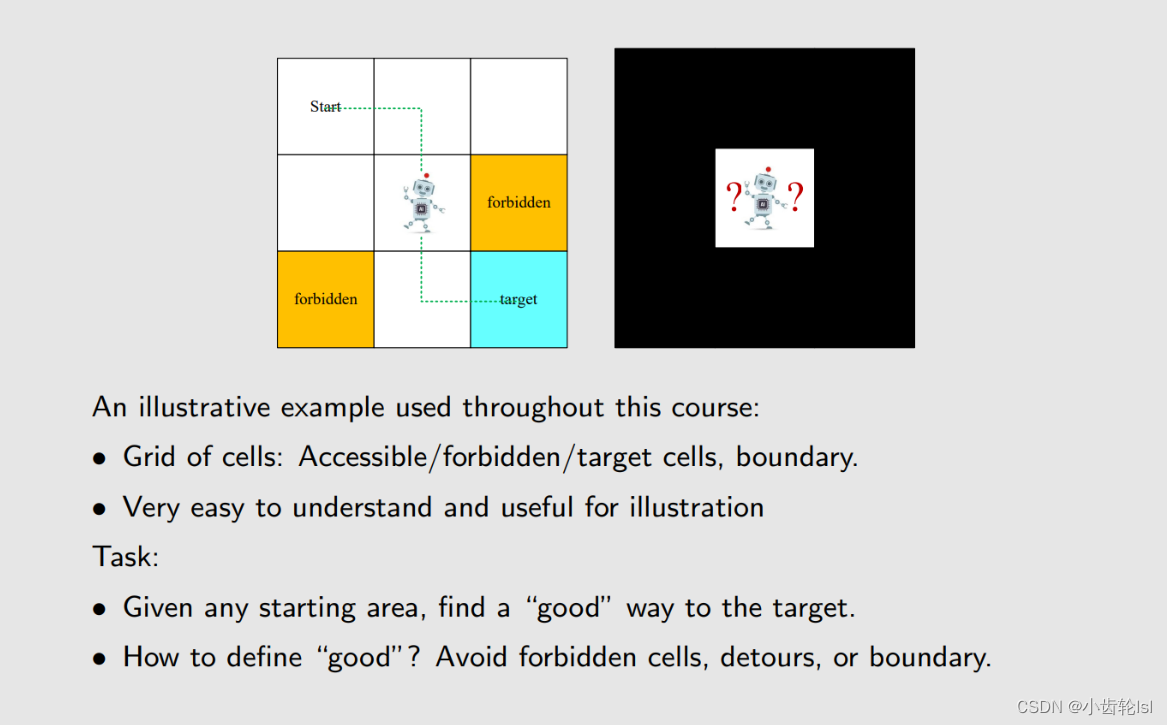
- 网格(Grid of cells):包括了开始网格( start)、目标网格(target)、可以进入的网格(Accessible、白)、禁止进入网格(forbidden、黄)和边界( boundary)组成。
- 目的:给出开始网格,找到一条好的线路到达目标网格,在到达目标网格的路线中,尽量避免走被禁止的网格、拐弯或者走出边界。
1.网格状态 State

在网格区域中,从s1...s9对应着不同的状态,状态s可能是受着一个或者多个因素所影响,比如在设备运行的过程中,会有多种因素导致工作环境的温度变化,而在这个例子中每个特定的温度都对应着一个S状态网格,而这个温度状态网格可能是由多个参数所影响的。
2.行动 Action
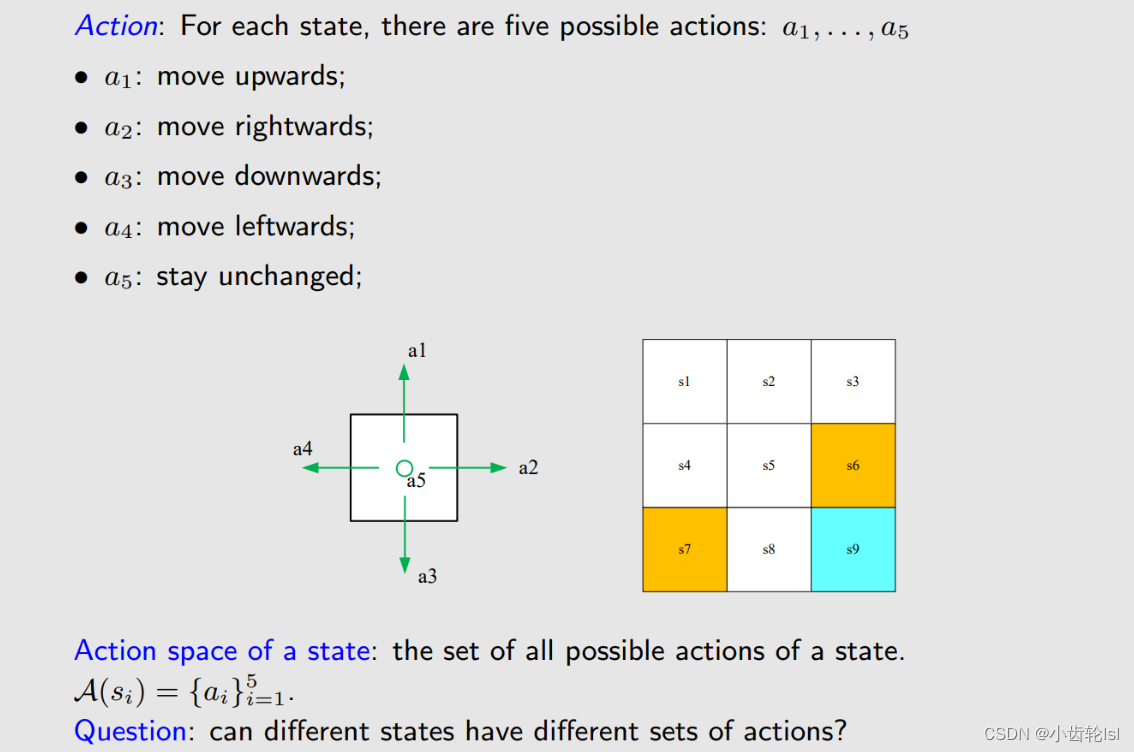
对每一个状态网格,都有5种可能会在下次进行的行动,可以用a1...a5集合来表示。比如温度的变化,可能在下一个时刻,会有升温、降温、温度不变三个状态。
3.状态转换 State transition

当下个时刻采取了行动时,网格的转换情况,根据采取的行动不同,下个时刻的状态可能不同,即所处的网格也有可能不同。有可能从一个网格到另一个网格,也有可能原地不动。
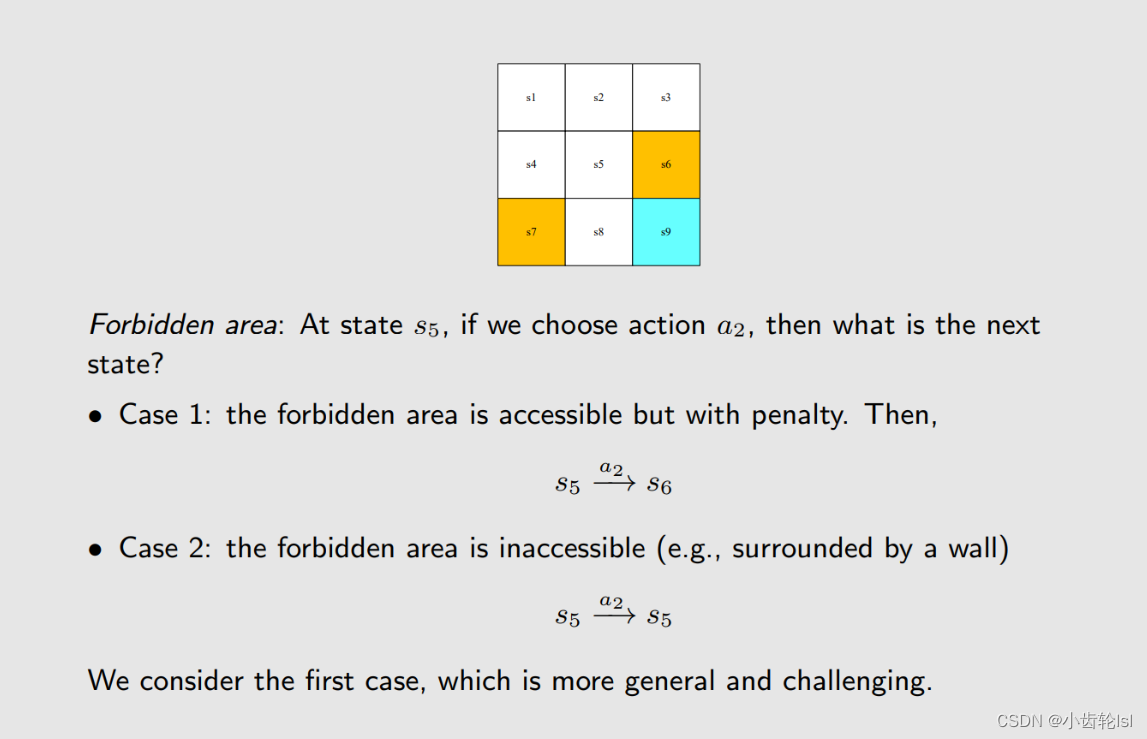
对于禁止进入的网格forbidden area 在采取行动时分成了两种情况,一种是可以进入,另一种是不可以进入。一般采取禁止网格也是可以采取行动进入的情况。
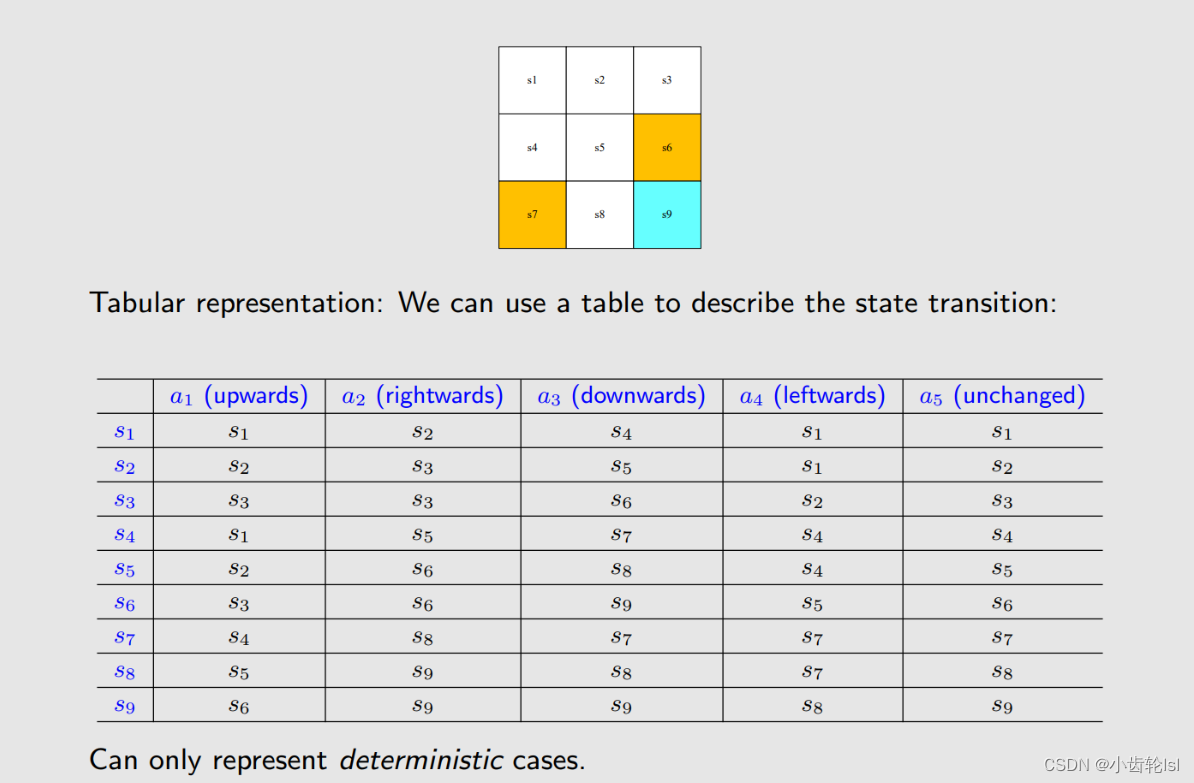
采取禁止网格可以进入,行动结果的表格。
状态转换的概率 State transition probability
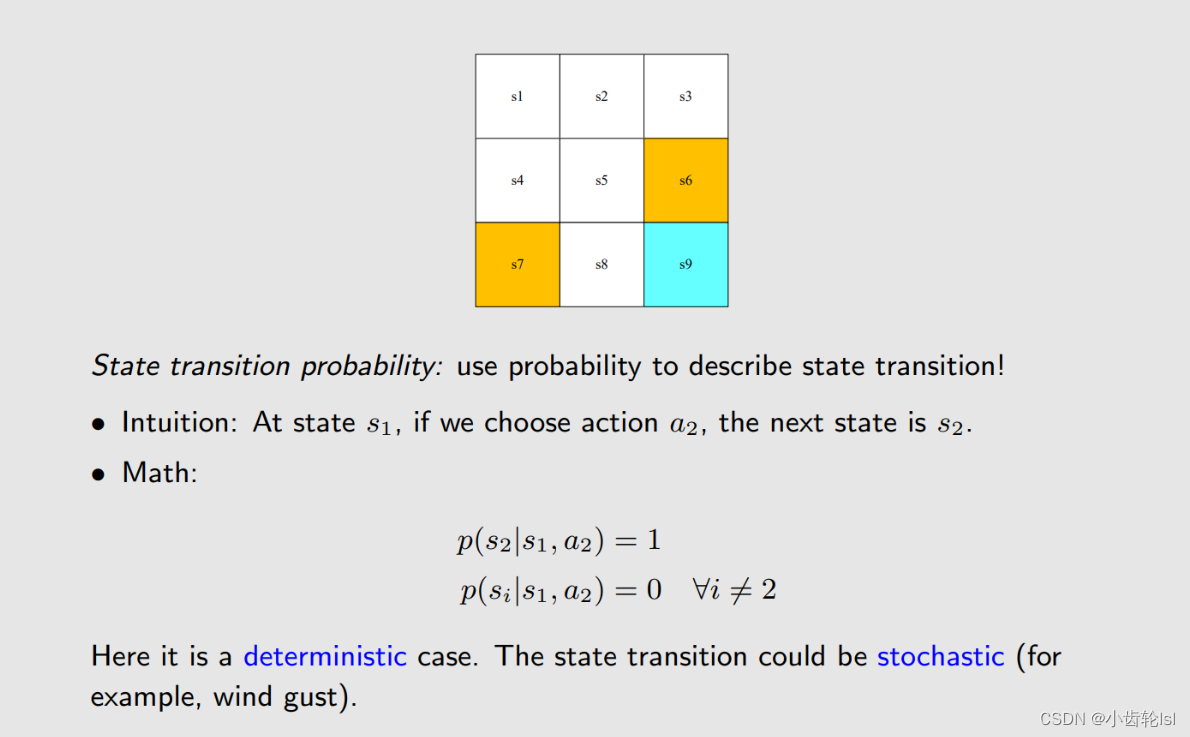
对于图中所举的确定的例子,在网格S1进行a2行动,到达不同的网格有不同的概率,这可以用式子表示出来,但是实际中的状态转换是随机的而不是确定的。
4.策略 Policy
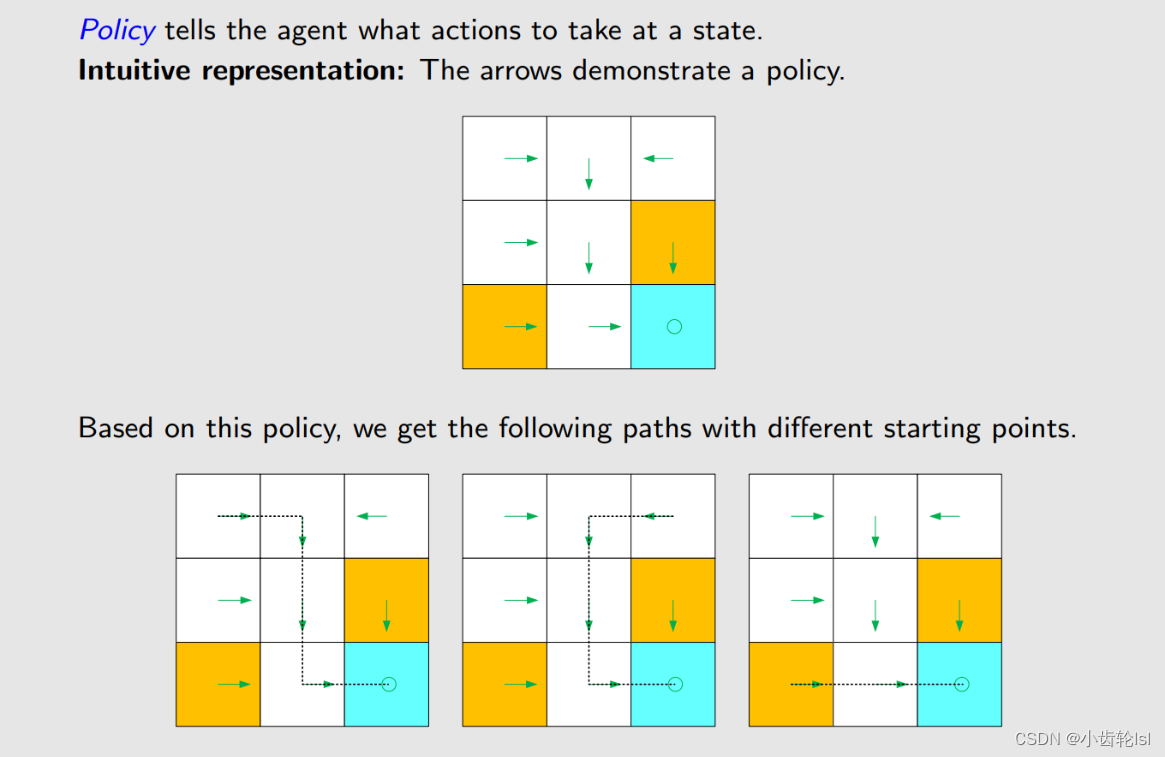
策略就是接下来言采取的行动,不同的起点,我们根据策略产生了不同的到达路线,图中的箭头即是策略,是一种确定的行动Action。
策略概率

在确定的策略下,每一个不同的网格空间,不同的行动有着不同的概率。
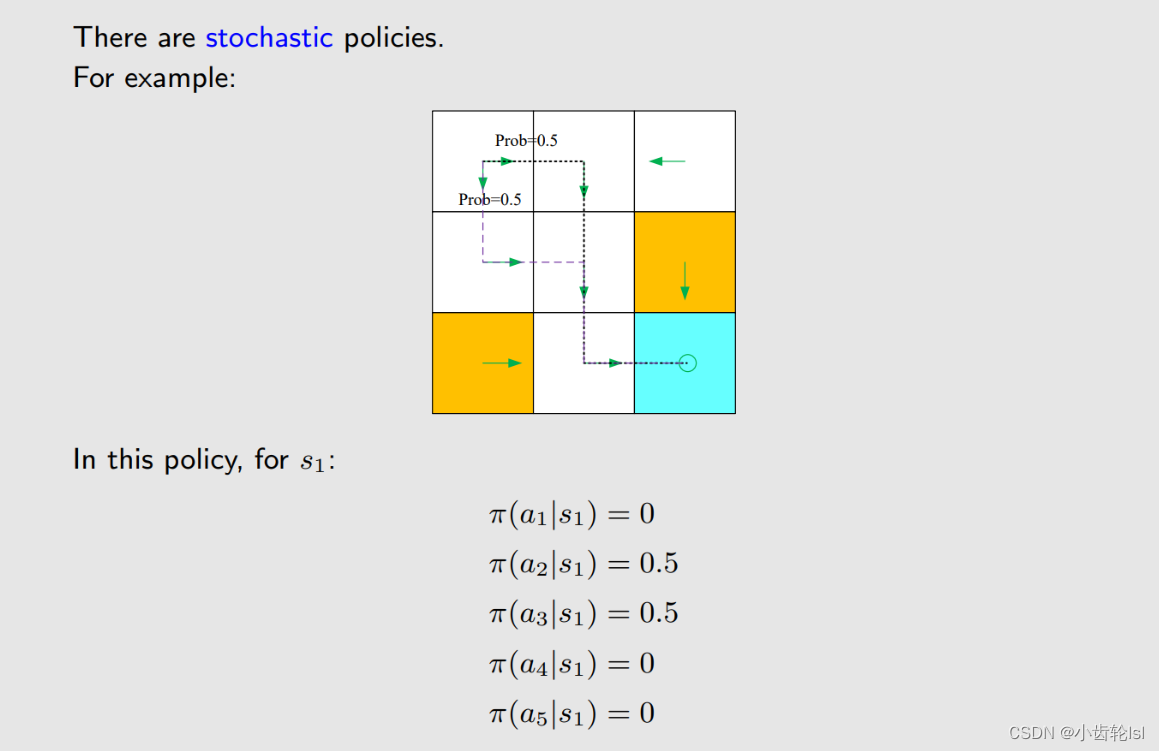
这是一个在网格a1有着随机策略的情况。
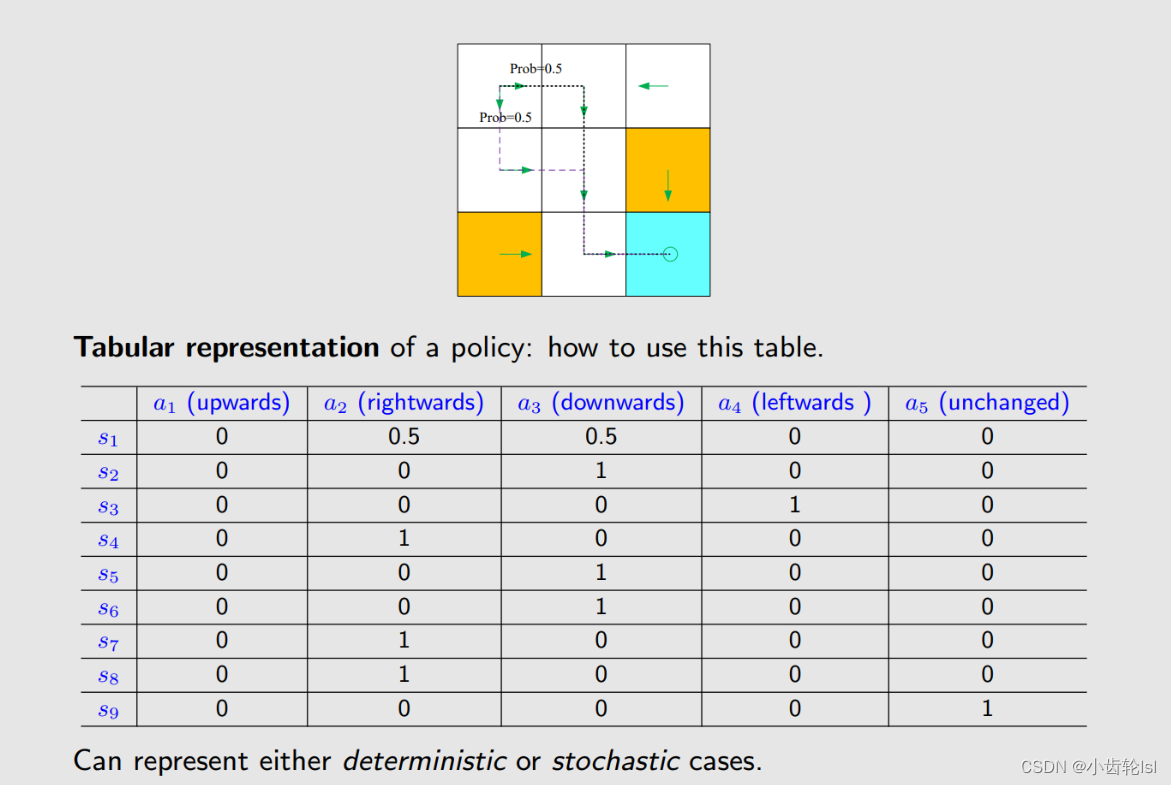
s1开始网格、s9目标网格,在如图所示不确定策略下的路线概率表格。
5.奖励 Reward

奖励是我们在采取一个行动后得到的一个实数。

在采取行动后,如果进去禁止网格和脱离边界,则奖励为-1;
如果到达目标边界,则奖励为1;
如果是其他情况,为0。
通过这个奖励的行为,我们来训练模型去找到一条到达目标网格好的路线。
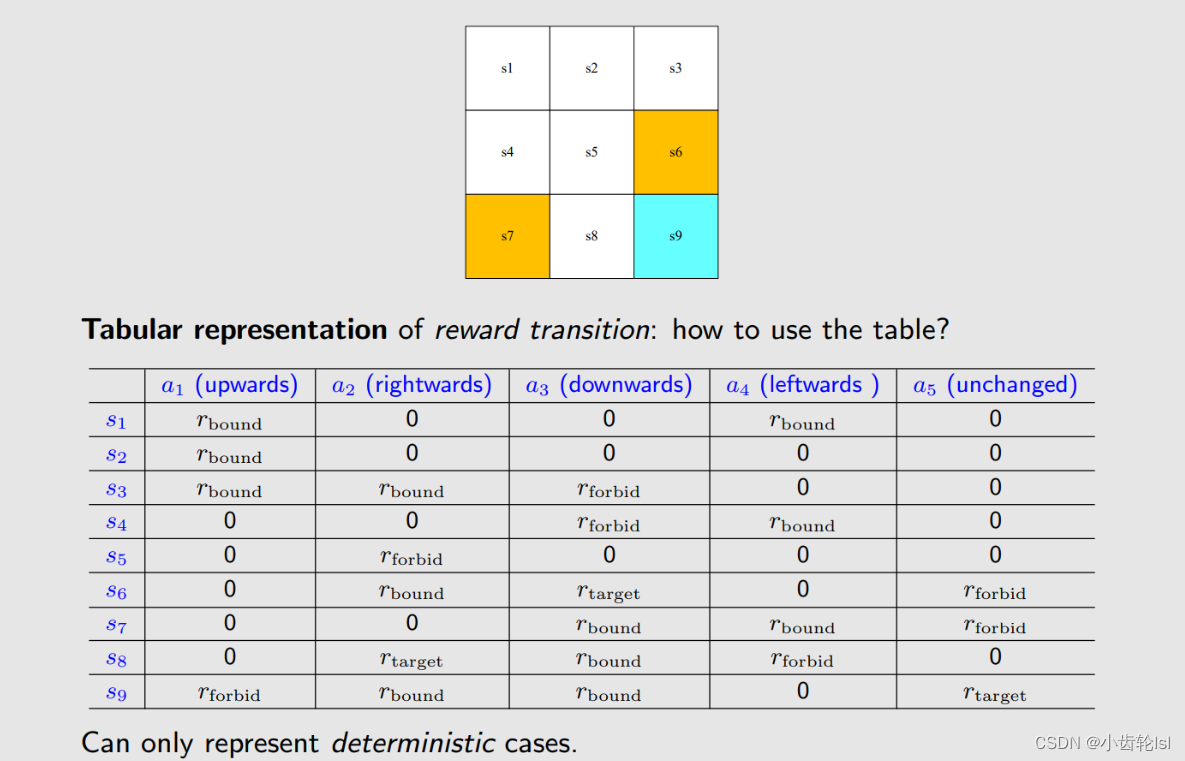
这是一个在不同网格,采取不同行动后得到不同奖励的表格。
奖励概率

奖励取决于当前网格和要采取的行动,与下个时刻网格不相关。
6.轨迹 Trajectory and retur
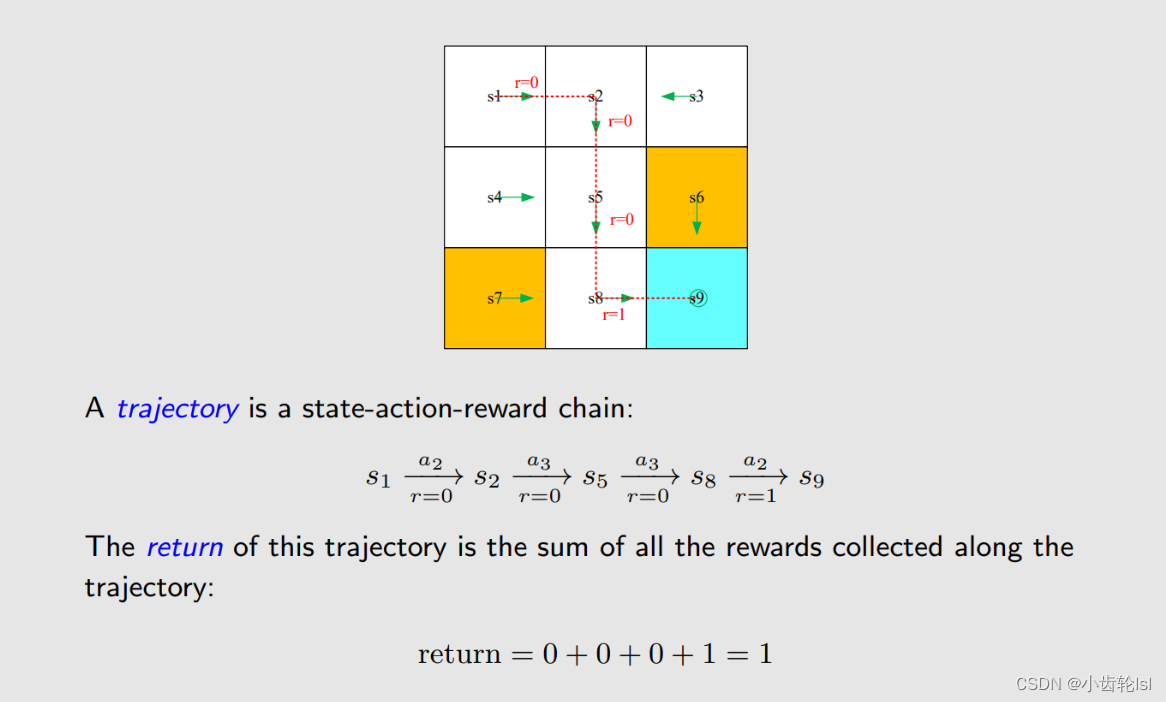
轨迹由网格、行动和奖励组成,return就是由此轨迹得到的奖励总和。
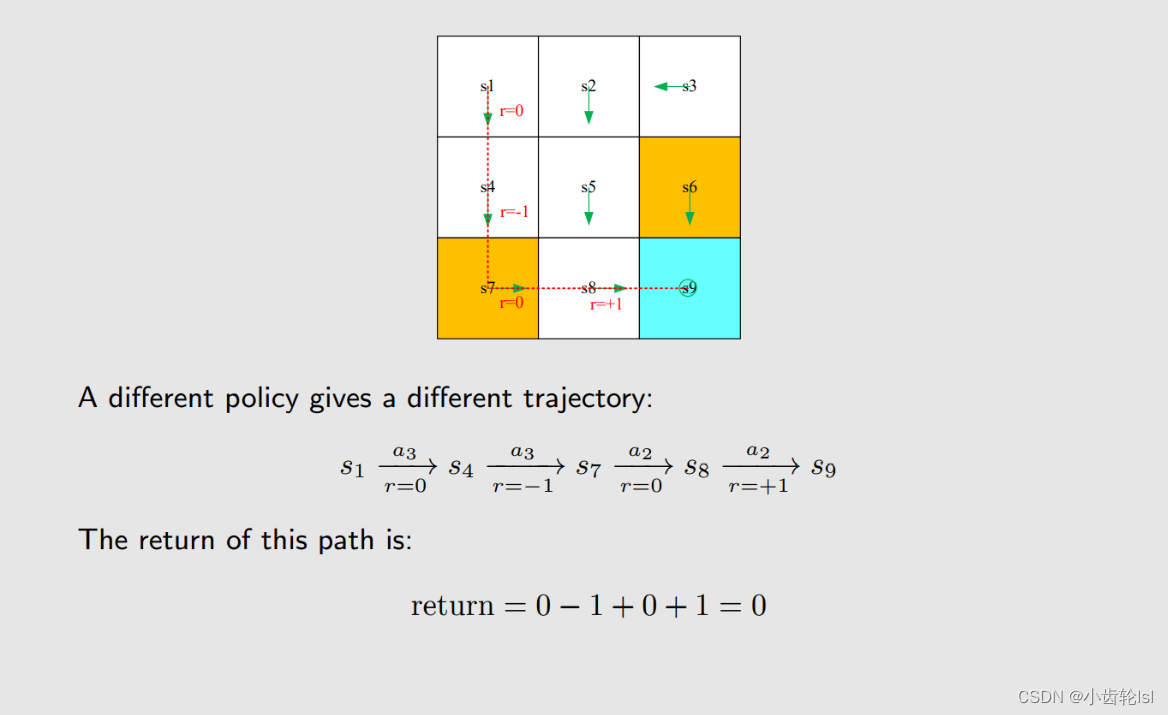
不同的策略轨迹不同,所得到的return也不同。
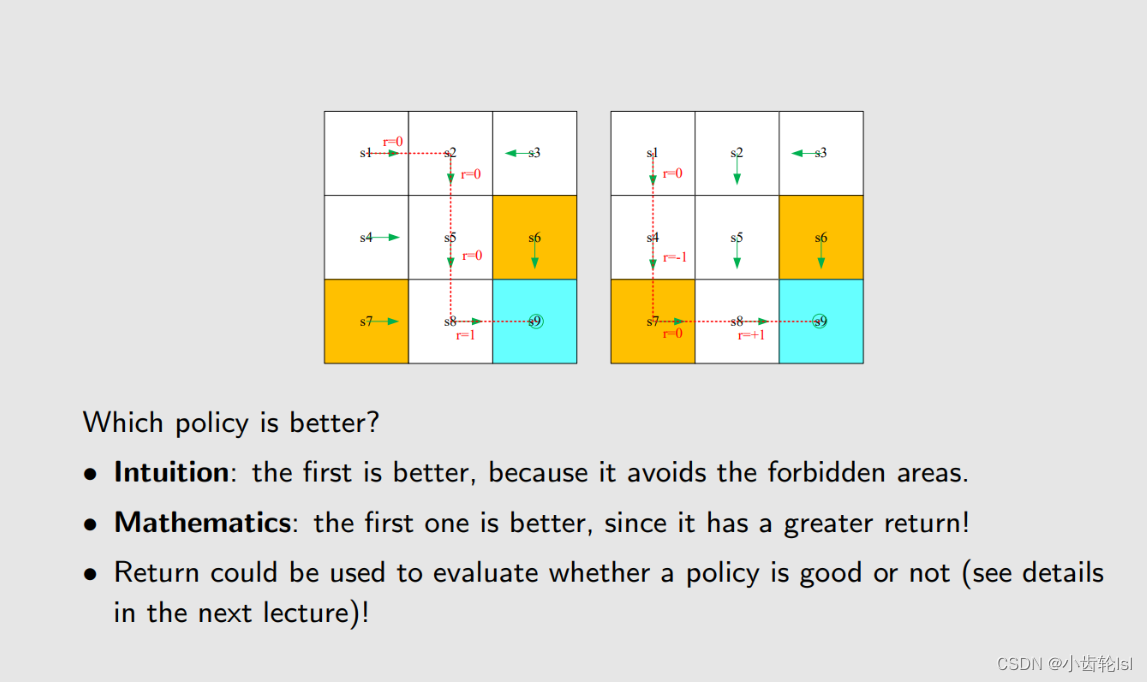
return就是来评估一个策略好坏的参数。
7.奖励有效值 Discounted return
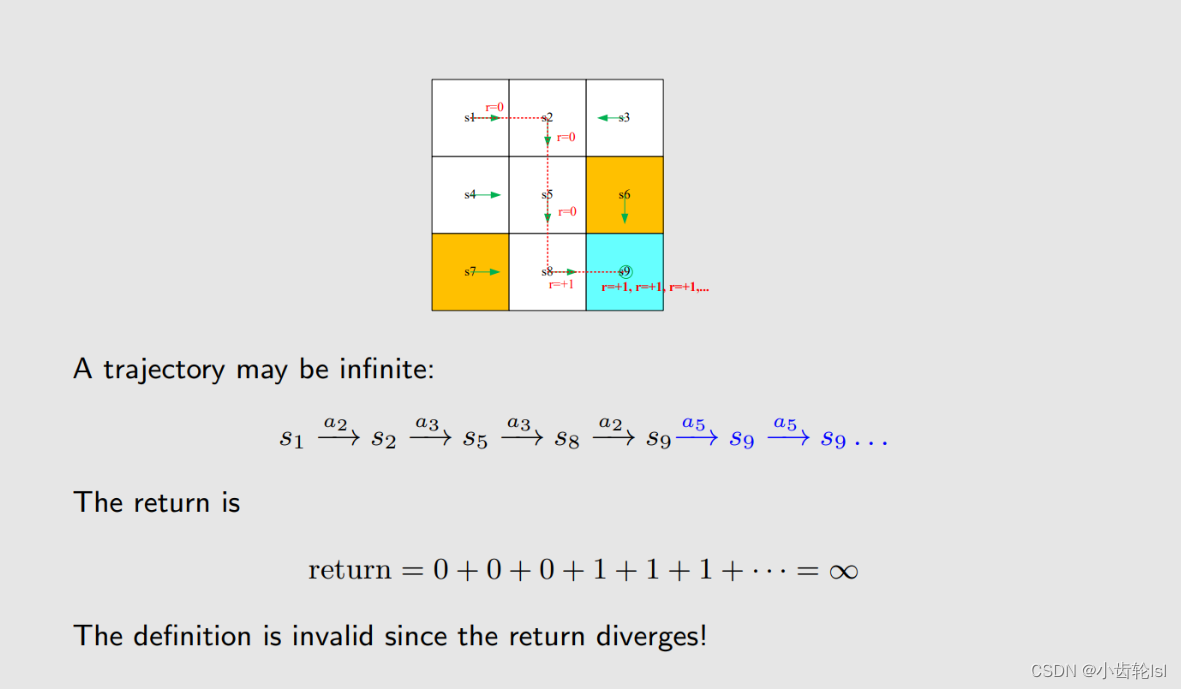
设备是不停的在运行的,因此在达到目标网格后,是不会停止的,会一直保持稳定在目标网格,但是一直加下去是毫无意义的。

引入一个discount rate γ,使我们计算的奖励趋于有限值。
如果我们将 γ趋于0,则有效奖励取决于近期的奖励,算出结果后半部分;
如果 γ趋于1,则取决于远期的奖励,算出结果前半部分。
8. Episode
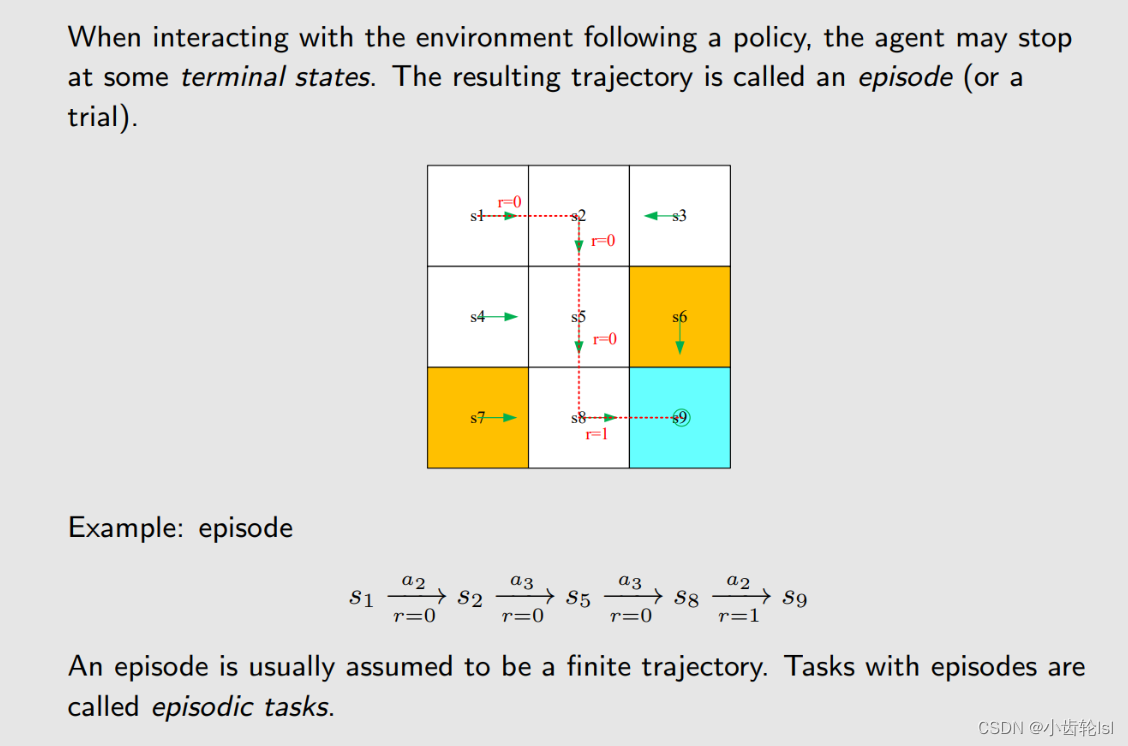

很多任务都是持续性的任务,不会停止,所以在达到目标状态后,有两种情况,第一种是它在目标网格永远不会离开,我们给其奖励为0;另一种情况是可能会离开,只要下次是进入目标网格的行动,就给奖励1。一般采用第二种情况,这样就不用区分目标状态和其他状态。
9.决策过程 Markov decision process (MDP)

关键参数。
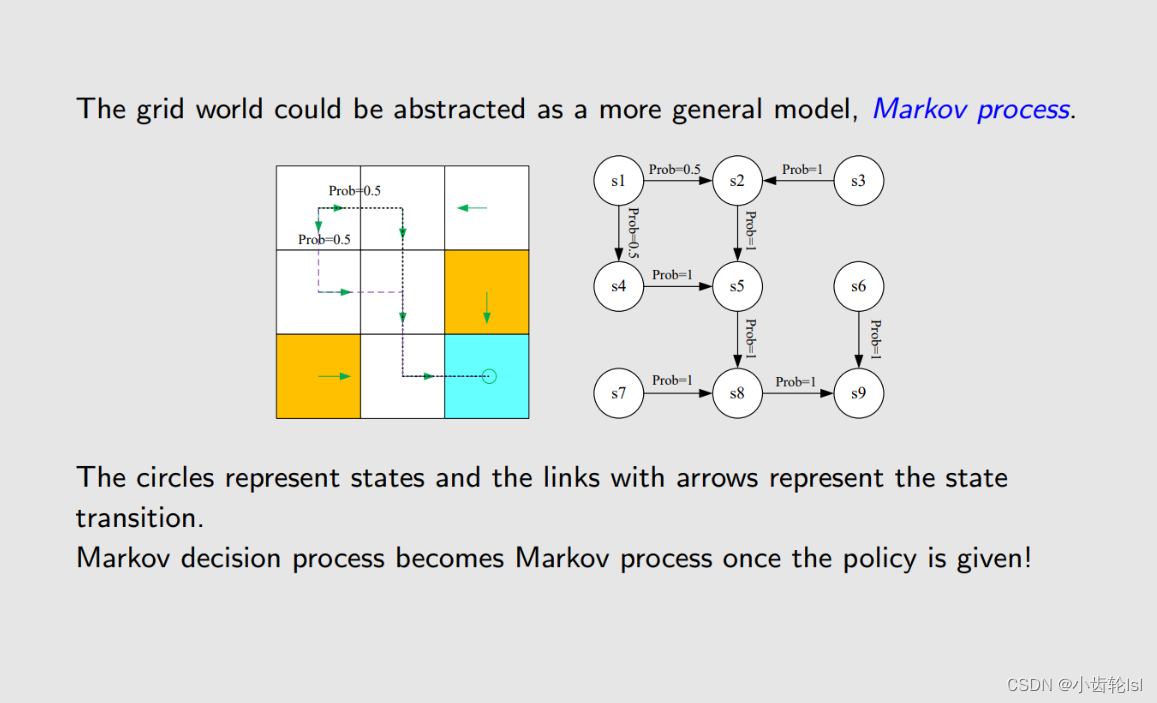
在策略确定的情况下,就是一个 Markov process过程。















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









