







数据预处理-数值型
1. 为何预处理
- 原始数据又脏又嘈杂
- 机器学习算法对输入数据有一定的约束
- 数据转换可以提高模型性能
- 无论是什么数据,在我们获得以后,都面临许多问题:数据缺失,数据格式不正确等等。这种我们直接获得,难以进行使用的数据有一种形象的称呼:脏数据
2. 预处理的作用
- 经过预处理的数据才可以真正被我们使用
- 预处理后的数据也往往能够提升模型的效果
- 在预处理时,我们甚至可以发现一些数据之间的联系
3. 数据的分类
在机器学习与深度学习的问题中,有几种类型的数据是十分常用的:
- 数值型数据(是一种结构化的数据,**例如:**吴恩达机器学习课程中的房价数据)
- 文本数据(是一种非结构化的数据,需进行标注。**例如:**我国的人民日报语料库,国外训练 word2vec 模型的 GoogleNews 语料库)
- 图片数据(非结构化数据,需要进行标注。**例如:**ImageNet)
鉴于每种类型的数据都有独特的数据预处理方式(图片:图像增强、灰度处理等;文本:词向量,词根化,标点大小写等),我将分三篇文章来介绍不同的数据预处理方法。
本篇先介绍最常用的:数值型数据
4. 不同类型的数据异常及处理方式
4.1 数据重复(Duplicate)
4.1.1 为什么处理数据重复?
出现数据泄露。
为了保证模型的泛化能力,十分重要的是:在整个训练过程中,算法中看不到测试集中的数据。
如果在模型的训练集和测试集中都存在相同的数据,这可能会导致模型的评估结果不可靠。
4.1.2 去除重复数据
import pandas as pd
df = pd.read_csv("file.csv")
data = df.copy()
print(len(data)) # Check number of rows before removing duplicates
data = data.drop_duplicates() # Remove duplicates
print(len(data))# Check new number of rows
4.2 数据缺失(Missing)
4.2.1 为什么会有数据缺失?
数据缺失的常见原因
- Programming error
- Failure of measurement
- Random events
数据缺失值的常见表示
- NaN (not a number)
- Large negative(较大的负数)
- 无穷大
发现数据中的缺失值
data.isnull().sum().sort_values(ascending=False) # NaN count for each column
data.info() # 也可以
4.2.2 处理缺失值
- 删除
import numpy as np data.drop(columns=["BA","CA"], inplace=True) #删除某一列 data = data[data.BA.notna()] #删除某一列中所有有缺失值的行 - 填充
缺失值有时是有含义的!
但是填充数据也会带来 问题: 人为的主观因素、列与列之间的关系丢失…
使用固定值替换:
使用 sklearn 中的 simplerImputer 进行数据填充,填充时可以选择想要的填充方式 [“mean”,“median”,“most_frequent”]data.BA.replace(np.nan, "NoBA", inplace=True) #Replace NaN by "NoBA"from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy="mean") # Instanciate a SimpleImputer object with strategy of choice imputer.fit(data[['BA']]) # Call the "fit" method on the object data['BA'] = imputer.transform(data[['BA']]) # Call the "transform" method on the object print(imputer.statistics_) # The mean is stored in the transformer's memory
4.3 异常值(Abnormal)
某项数据和大多数其他数据之间存在较大差异。
4.3.1 异常值的影响
- 数据集分布和模式
- 集中趋势指标,例如平均值和标准偏差
- 机器学习模型的性能
4.3.2 异常值的发现和处理
- 发现异常值:使用Boxplot(箱线图)
data[["HAVEOUTLIER"]].boxplot() - 处理异常值
# 要找到不合理的异常值的index false_observation = data['HAVEOUTLIER'].argmin() # Get index corresponding to minimum value data = data.drop(false_observation).reset_index(drop=True) # Drop row data[['HAVEOUTLIER']].boxplot() # Visualize boxplot
4.4 缩放(Scaling)
将连续数据转变到一个更小的范围内。(ps:非连续型的变量不应采用该方法)
4.4.1 为何要进行 Scaling
- 大幅度的特征可能会错误地超过小幅度的特征(Features with large magnitudes can incorrectly outweigh features of small magnitudes)
- 缩放到较小的幅度可提高计算效率(Scaling to smaller magnitudes improves computational efficiency)
- 增加特征系数的可解释性(Increases interpretability of feature coefficients)
4.4.2 Scaling 的方法
详情见 数据标准化
-
Standardizing(标准化)
z = ( x − m e a n ) s t d z = {(x-mean)\over std} z=std(x−mean)from sklearn.preprocessing import StandardScaler scaler= StandardScaler() std_data = scaler.fit_transform(data) -
Normalizing(归一化)
X ′ = ( X − X m i n ) X m a x − X m i n X' = {(X-{X}_{min})\over {X}_{max}-{X}_{min}} X′=Xmax−Xmin(X−Xmin)from sklearn.preprocessing import MinMaxScaler minmax_scaler = MinMaxScaler() data_scaled = minmax_scaler.fit_transform(data) data_scaled_df = pd.DataFrame(data_scale_1) data_scaled_df.head() -
RobustScaler
若数据中存在很大的异常值,可能会影响特征的平均值和方差,影响标准化结果。在此种情况下,使用中位数和四分位数间距进行缩放会更有效。
R o b u s t S c a l e d = x − m e d i a n I Q R RobustScaled = {x-median}\over IQR IQRRobustScaled=x−medianfrom sklearn.preprocessing import RobustScaler r_scaler = RobustScaler() # Instanciate Robust Scaler r_scaler.fit(data) # Fit scaler to feature data = r_scaler.transform(data) #Scale data.head()
4.5 分布不平衡 (Balacing)
详情见 解决样本分布不均衡
在分类的数据中,常常会有不同类别的数据量相差极大的情况。此时需要通过 Balacing 将不同类别的数据量之间进行平衡
4.5.1 为什么要进行 Balacing
样本分布不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律。即使得到分类模型,也容易产生过度依赖于有限的数据样本而导致过拟合的问题。当模型应用到新的数据上时,得到的准确性和健壮性将很差。
样本分布不均衡主要在于不同类别间的样本比例差异。如果不同分类间的样本量差异超过10倍就需要引起警觉,并应考虑处理该问题,超过20倍就一定要处理该问题。
4.5.2 Balacing 的方法
抽样是解决样本分布不均衡相对简单且常用的方法,包括过抽样和欠采样两种。
- 过抽样(Oversampling)和欠采样(Undersampling)解决样本不均衡
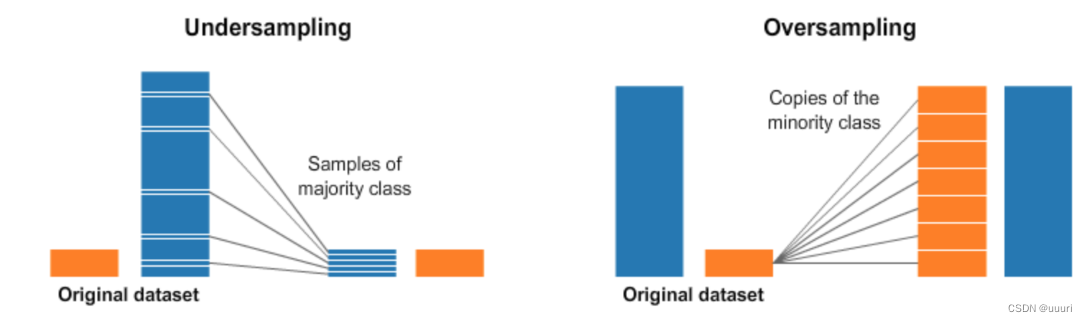
- 过抽样: 又称上采样,其通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本以形成多条记录。这种方法的缺点: 如果样本特征少可能导致过拟合的问题。经过改进的过抽样方法会在少数类中加入随机噪声、干扰数据、或通过一定规则产生新的合成样本,例如SMOTE算法
SMOTE算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
# 使用imlbearn库中上采样方法中的SMOTE接口
from imblearn.over_sampling import SMOTE
# 定义SMOTE模型,random_state相当于随机数种子的作用
smo = SMOTE(random_state=42)
X_smo, y_smo = smo.fit_sample(X, y)
- 欠抽样: 又称下采样,其通过减少分类中多数类样本的数量来实现样本均衡,最直接的方法是随机去掉一些多数类样本来减小多数类的规模。缺点是会丢失多数类样本中的一些重要信息。
总体上,过抽样和欠抽样更适合大数据分布不均衡的问题,尤其是过抽样方法,应用极为广泛
4.6 真值转换
详情见 真值转换
4.6.1 标志方法处理分类和顺序变量
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
le.fit([1, 2, 2, 6])
4.6.2 特征 OneHot 编码
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
model_enc = OneHotEncoder() # 实例化
df_new2 = model_enc.fit_transform(raw_convert_data) # 独热编码转换
4.6.3 数据对数化
详情见 数据对数化
4.7 离散化(Discretizing)
详情见 数据离散化
所谓离散化,就是把无限空间中有限的个体映射到有限的空间中。数据离散化操作大多是针对连续数据进行的,处理之后的数据值域分布将从连续属性变为离散属性,这种属性一般包含 2 个或 2 个以上的值域。
4.7.1 数据离散化的意义
- 节约计算资源,提高计算效率。
- 算法模型的计算需要。 虽然很多模型,例如决策树可以支持输入连续型数据,但是决策树本身会先将连续型数据转化为离散型数据,因此离散化转换是一个必要步骤。
- 增强模型的稳定性和准确度。 数据离散化之后,处于异常状态的数据不会明显的突出异常特征,而是会被划分为一个子集中的一部分。如10000为异常值,可以划分为>100。因此异常数据对模型的影响会大大降低,尤其是基于距离计算的模型效果更明显。
- 特定数据处理和分析的必要步骤,尤其是在图像处理方面应用广泛。 大多数图像做特征检测时,都需要先将 图像做二值化处理,二值化也是离散化的一种。
- 模型结果应用和部署的需要。 如果原始数据的值域分布过多,或者值域划分不符合业务逻辑,俺么模型结果将很难被业务理解并应用。以银行信用卡评分距离,在用户填写表单时,不可能填写年收入为某个具体数字如100万,而是填写薪资位于哪个范围,这样从业务上来说才是可行的。
4.7.3 数据离散化方法
- 时间数据离散化
- 多值离散数据离散化
- 连续数据离散化
- 分位数法:使用四分位、五分位、十分位等分位数进行离散化处理,这种方法简单易行。
- 距离区间法:使用等距区间或自定义区间的方式进行离散化。这种方法比较容易,并且可以较好的保持数据原有结构分布。
- 频率区间法:将数据按照不同数据的频率分布进行排序,然后按照等频率或指定频率离散化,这种方法会把数据变换成均匀分布,但是会改变原有数据结果分布
- 聚类法:
- 卡方过滤:通过基于卡方的离散化方法,找出数据的最佳临近区间并合并,形成较大的区间
- 连续数据二值化
4.8 特征创建 (Feature creation)
如果对于要训练的数据有一定的专业知识,就可以进行特征的创建,进而使用创建的特征进行模型训练
4.9 特征选择(Feature selection)
详情见 特征选择
有的时候,我们获得的数据里面有许多特征字段,不是所有字段都需要使用.
特征选择是消除非信息性特征的过程。 统计特征选择有2种主要类型:
- 单变量特征选择
- 多变量
4.9.1 特征选择的意义
- 进去是垃圾,模型出来也是垃圾
- 过高维度的数据在传统机器学习种难以处理,减少复杂性
- 只有对于要解决的问题有用的数据才应该放到模型中
4.9.2 特征选择的方法
-
特征的相关性
判断两个特征之间的相关性,如果两个特征高度相关,那么就移除其中一个。
Pearson Correlationimport seaborn as sns # Heatmap corr = data.corr() sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns, cmap= "YlGnBu") corr_df = corr.unstack().reset_index() # Unstack correlation matrix corr_df.columns = ['feature_1','feature_2', 'correlation'] # rename columns corr_df.sort_values(by="correlation",ascending=False, inplace=True) # sort by correlation corr_df = corr_df[corr_df['feature_1'] != corr_df['feature_2']] # Remove self correlation corr_df.head() -
特征置换
评估每个特征在预测目标中的重要性
步骤:- 训练并记录包含所有特征的Baseline的测试分数
- 随机选择(置换)测试集中的特征
- 在改组的测试集上记录新分数
- 将新分数与原始分数进行比较
- 对每个feature重复该操纵
from sklearn.inspection import permutation_importance log_model = LogisticRegression().fit(X, y) # Fit model permutation_score = permutation_importance(log_model, X, y, n_repeats=100) # Perform Permutation importance_df = pd.DataFrame(np.vstack((X.columns, permutation_score.importances_mean)).T) # Unstack results importance_df.columns=['feature','score decrease'] importance_df.sort_values(by="score decrease", ascending = False) # Order by importance
4.10 数据降维
维度指的就是样本的数量或者特征的数量。一般无特别说明,指的都是特征数量。降维算法中的降维,指的就是降低特征矩阵中特征的数量
4.10.1 数据降维的意义
降维的目的是为了让算法运算更快,效果更好。降维可以使数据集变得更易使用,对于数据量较大的数据集,我们可以通过降维降低模型算法的计算开销,与此同时,去除掉数据集中无用的噪声数据,而且少量的特征也可能使得模型解释起来简单易懂。
4.10.2 降维算法
- 主成分分析PCA
在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此我们可以忽略余下的坐标轴,即对数据进行了降维处理。
4.10.3 特征选择和数据降维的区别
- 特征选择是从已存在的特征中选取携带信息量最多的,选完之后的特征依然具有可解释性,我们依然知道这个特征在原数据的哪个位置,代表原数据上的什么含义。
- 降维,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。















 2337
2337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









