







文章目录
解决样本类别分布不均衡的问题
1. 什么是样本分布不均衡
所谓的不均衡指的是不同类别的样本量差异非常大。样本类别分布不均衡主要出现在与分类相关的建模问题上。样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数据分布不均衡两种。
- 大数据分布不均衡:这种情况下整体数据规模大,只是其中的小样本类的占比比较小。但是从每个特征的分布来看,小样本也覆盖了大部分或全部的特征。例如,在拥有1000万条记录的数据集中,其中占比50万条的少数分类样本便属于这种情况。
- 小数据分布不均衡:这种情况下整体数据规模小,并且占据少量样本比例的分类数量也少,这会导致特征分布的严重不均衡。例如,拥有1000条数据样本的数据集中,占有10条样本的分类,其特征无论如何拟合也无法实现完整特征值的覆盖,此时属于严重的数据样本分布不均衡。
样本分布不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律。即使得到分类模型,也容易产生过度依赖于有限的数据样本而导致过拟合的问题。当模型应用到新的数据上时,得到的准确性和健壮性将很差。
样本分布不均衡主要在于不同类别间的样本比例差异。如果不同分类间的样本量差异超过10倍就需要引起警觉,并应考虑处理该问题,超过20倍就一定要处理该问题。
2. 为什么会出现样本分布不均衡
- 异常检测场景:大多数企业中的异常个案都是少量的,比如恶意刷单、黄牛订单、信用卡欺诈、电力窃电、设备故障灯、这些数据样本所占的比例通常是整体样本中很少的一部分。以信用卡欺诈为例,刷实体信用卡欺诈的比例一般在0.1%以内。
- 客户流失场景:大型企业的流失客户相对于整体客户通常是少量的,尤其对于具有垄断地位的行业巨擘,例如电信、石油、网络运营商等更是如此。
- 罕见事件的分析:罕见事件与异常检测类似,都属于发生个案较少的情况;但不同点在于异常检测通常都是能预先知道的,并且大多数异常事件都会对企业运营造成负面影响,因此针对一长时间的检测和预防非常重要;但罕见事件则无法预判,并且没有明显的积极或消极的影响。例如,某大V无意转发了企业的一条趣味广告,导致用户流量明显提升便属于此类。
- 发生低频率的事件:这种事件是预期或计划性事件,但是发生频率非常低。例如,每年一次的双11购物节都会产生较高的销售额,但放到全年来看,这一天的销售额占比量可能只有不到1%。尤其对于很少参与活动的公司而言。
3. 如何解决样本分布不均衡?
3.1 通过过抽样和欠采样解决样本不均衡
抽样是解决样本分布不均衡相对简单且常用的方法,包括过抽样和欠采样两种。
- 过抽样:又称上采样,其通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本以形成多条记录。这种方法的缺点是,如果样本特征少可能导致过拟合的问题。经过改进的过抽样方法会在少数类中加入随机噪声、干扰数据、或通过一定规则产生新的合成样本,例如SMOTE算法
SMOTE算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
- 欠抽样:又称下采样,其通过减少分类中多数类样本的数量来实现样本均衡,最直接的方法是随机去掉一些多数类样本来减小多数类的规模。缺点是会丢失多数类样本中的一些重要信息。
总体上,过抽样和欠抽样更适合大数据分布不均衡的问题,尤其是过抽样方法,应用极为广泛。
代码实现:
引包:
[1]:import pandas as pd
from imblearn.over_sampling import SMOTE # 过抽样处理库SMOTE
from imblearn.under_sampling import RandomUnderSampler # 欠抽样处理库RandomUnderSampler
数据加载:
[2]:df = pd.read_csv('data2.csv',index_col = 0)
df.head()
分离特征和标签:
[3]:x,y = df.iloc[:,:-1],df.iloc[:,-1]
查看类别分布情况:
[4]:groupby_data_orgianl = df.groupby('label').count()
agroupby_data_orgianl
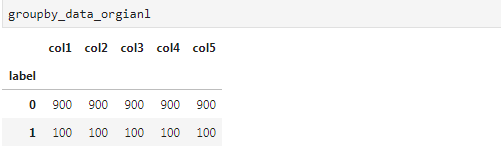
从上图可以看出,样本分类及其不均衡,label=0的行记录数量是label=1的9倍。所以我们可以试着从过采样和欠采样两方面来处理该问题。
过抽样:
[5]:model_smote = SMOTE() # 过采样模型实例化
x_smote_resampled,y_smote_resampled = model_smote.fit_sample(x,y) # 输入数据并作过抽样处理
y_smote_resampled = pd.DataFrame(y_smote_resampled,columns=['label']) # 此时y_smote_resampled 为Series,将其转换为DataFrame
smote_resampled = pd.concat([x_smote_resampled,y_smote_resampled],axis=1) # 将过抽样后的特征和标签合并
查看过抽样结果:
[6]:groupby_data_smote = smote_resampled.groupby("label").count()
groupby_data_smote
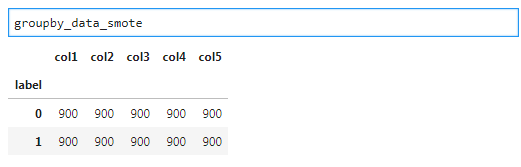
这里将少数类的记录数增加到和多数类相同。这样达到分类均匀。注意:smote算法并不是单纯复制少数类,而是根据算法,生成新的少数类记录。如果希望从少数类的样本中进行随机采样来增加新的样本,则使用RandomOverSampler方法,使用方法和下面的欠抽样相同。
from imblearn.over_sampling import RandomOverSampler
欠抽样:
[7]:model_RandomUnderSampler = RandomUnderSampler() # 欠抽样模型实例化
x_RandomUnderSampler_resampled,y_RandomUnderSampler_resampled = model_RandomUnderSampler.fit_sample(x,y) # 输入数据并作欠抽样处理
y_RandomUnderSampler_resampled = pd.DataFrame(y_RandomUnderSampler_resampled,columns=['label']) # 此时y_RandomUnderSampler_resampled 为Series,将其转换为DataFrame
RamdomUnderSampler_resampled = pd.concat([x_RandomUnderSampler_resampled,y_RandomUnderSampler_resampled],axis=1) # 将欠抽样后的特征和标签合并
查看欠采样结果:
RamdomUnderSampler_resampled.groupby("label").count()
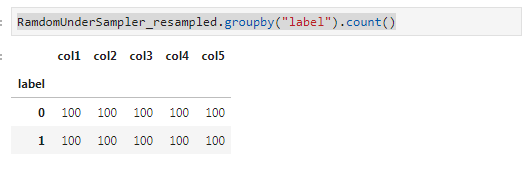
可以看到,该算法直接删除了多数类中800条数据(原来900条),达到和少数类记录数相同。但是该方法丢失了多数类样本中的一些重要信息,对于当前数据集,原来1000条数据缩减为200条数据,所以一般很少使用欠抽样。
3.2 通过正负样本的惩罚权重解决样本不均衡
通过正负样本的城府权重解决样本不均衡的问题的思想是:在算法实现过程中,对于分类中不同样本数量的类别分别赋予不同的权重(分类中的小样本量类别权重高,大样本量类别权重低),然后进行计算和建模。
使用过这种方法时,不需要对样本本身做额外处理,只需要在算法模型中进行相应设置即可。很多模型和算法中都由基于类别参数的调整设置。如果算法本身支持,这种思路是更加简单且高效的方法。
在随机森林算法中,参数class_weight就是控制与标签相关联的权重。默认是None,即默认所有的标签持有相同的权重。如果class_weight=balanced,将会使用标签的值与输入数据中的类频率成反比的权重。
3.3 通过组合/集合方法解决样本不均衡
组合/集成方法指的是在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生和分类预测结果。
例如,数据集中的正、负例的样本分别为100条和10000条,比例为1:100.此时可以将类别中的大量样本(负例样本)随机分为100份,每份100条数据;然后每次形成训练集时使用所有的正样本(100条)和随机抽取的负样本(100条)形成新的数据集。如此反复可以得到100个训练集和对应的训练模型。
这种解决问题的思路类似于随机森林。在随机森林中,虽然每个小决策树的分类能力很弱,但是通过大量的小树组合形成的森林具有良好的模型预测能力。
如果计算资源充足,并且对于模型的时效性要求不高,这种方法比较合适。
3.4 通过特征选择解决样本不均衡
上述居中方法都是基于数据行的操作,通过多种途径可使不同类别的样本数据行记录均衡。除此之外,还可以考虑使用或辅助于基于列的特征选择方法。
一般情况下,样本不均衡也会导致特征分布不均衡,但如果小类别样本量具有一定的规模,那么就意味着其特征值的分布较为均匀,可通过选择具有显著性的特征配合参与解决样本不均衡问题,也能在一定程度上提高模型效果。
上述几种方法的思路都是基于分类问题解决的。实际上,这种从大规模数据中寻找罕见数据的情况,也可以使用非监督式的学习方法。例如使用One-class SVM进行异常检测。分类是监督式方法,前期是基于带有标签Label的数据进行分类预测;而采用非监督式方法,则是使用除了标签以外的其他特征进行模型拟合,这样也能得到异常数据记录。所以,要解决异常检测类的问题,显示考虑整体思路,然后再考虑方法模型。
参考资料:《Python数据分析与数据化运营》
关联文章:
数据预处理Part1——数据清洗
数据预处理Part2——数据标准化
数据预处理Part3——真值转换
数据预处理Part4——数据离散化
数据预处理Part6——数据抽样
数据预处理Part7——特征选择
数据预处理Part8——数据共线性
数据预处理Part9——数据降维

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









