代码部分
# -*- encoding:utf-8 -*-
"""
create by 邪老黄大 on 20220814
"""
import numpy as np
import matplotlib.pyplot as plt
# 1、创建数据集
def createdata():
samples = np.array([[3, -3], [4, -3], [1, 1], [1, 2]])
labels = [-1, -1, 1, 1]
return samples, labels
# 训练感知机模型
class Perceptron:
def __init__(self, x, y, a=1):
self.x = x
self.y = y
self.w = np.zeros((x.shape[1], 1)) # 初始化权重,w1,w2均为0
self.b = 0
self.a = 1 # 学习率
self.numsamples = self.x.shape[0]
self.numfeatures = self.x.shape[1]
def sign(self, w, b, x):
y = np.dot(x, w) + b
return int(y)
def update(self, label_i, data_i):
tmp = label_i * self.a * data_i
tmp = tmp.reshape(self.w.shape)
# 更新w和b
self.w = tmp + self.w
self.b = self.b + label_i * self.a
def train(self):
isFind = False
while not isFind:
count = 0
for i in range(self.numsamples):
print("i = ", i)
tmpY = self.sign(self.w, self.b, self.x[i, :])
if tmpY * self.y[i] <= 0: # 如果是一个误分类实例点 ==> y(训练)*y(真) = 不同类则进行更新权值
print("tmpY = ", tmpY)
print("self.y[i] =",self.y[i])
print('误分类点为:', self.x[i, :], '此时的w和b为:', self.w, self.b)
print("---------------------------------------------------------------")
count += 1
t1 = self.y[i]
t2 = self.x[i, :]
self.update(t1, t2)
if count == 0:
print('最终训练得到的w和b为:', self.w, self.b)
isFind = True
return self.w, self.b
# 画图描绘
class Picture:
def __init__(self, data, w, b):
self.b = b
self.w = w
plt.figure(1)
plt.title('Perceptron Learning Algorithm', size=14)
plt.xlabel('x0-axis', size=14)
plt.ylabel('x1-axis', size=14)
xData = np.linspace(0, 5, 100)
yData = self.expression(xData)
plt.plot(xData, yData, color='r', label='sample data')
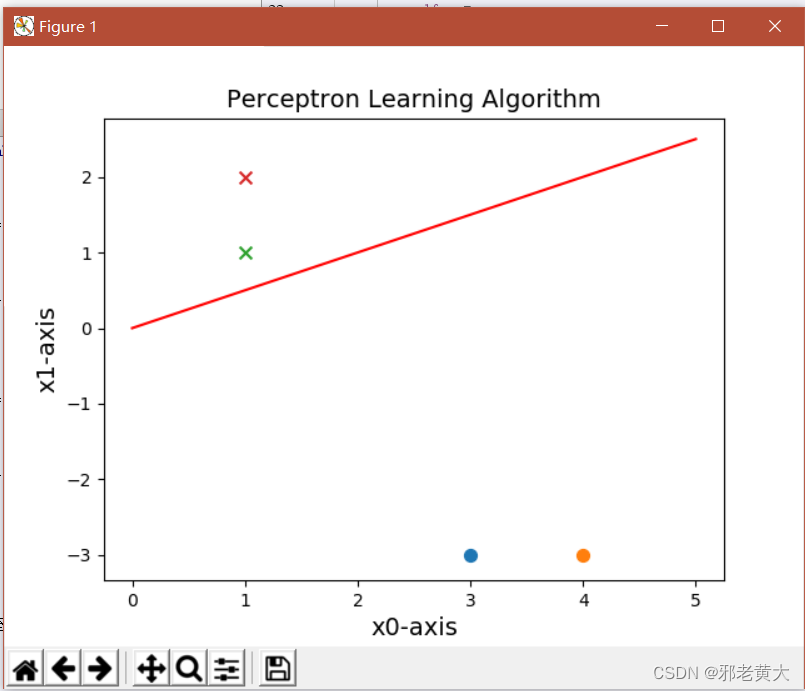
plt.scatter(data[0][0], data[0][1], s=50)
plt.scatter(data[1][0], data[1][1], s=50)
plt.scatter(data[2][0], data[2][1], s=50, marker='x')
plt.scatter(data[3][0], data[3][1], s=50, marker='x')
plt.savefig('2d.png', dpi=75)
def expression(self, x):
y = (-self.b - self.w[0] * x) / self.w[1] # 注意在此,把x0,x1当做两个坐标轴,把x1当做自变量,x2为因变量
return y
def Show(self):
plt.show()
if __name__ == '__main__':
samples, labels = createdata()
myperceptron = Perceptron(x=samples, y=labels)
weights, bias = myperceptron.train()
Picture = Picture(samples, weights, bias)
Picture.Show()
效果
i = 0
tmpY = 0
self.y[i] = -1
误分类点为: [ 3 -3] 此时的w和b为: [[0.]
[0.]] 0
---------------------------------------------------------------
i = 1
i = 2
tmpY = -1
self.y[i] = 1
误分类点为: [1 1] 此时的w和b为: [[-3.]
[ 3.]] -1
---------------------------------------------------------------
i = 3
i = 0
i = 1
i = 2
i = 3
最终训练得到的w和b为: [[-2.]
[ 4.]] 0























 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









