







时间:2021年3月30
公司:创维数字–底层驱动开发工程师
面试流程
- 前台填写应聘基本信息表 – 10分钟
- HR了解基本情况 – 10分钟
- 答写软件基本面试题 – 40分钟
- 技术官问答面试 – 30分钟
面试题总结
- 笔试主要考察基础的C语言知识
- 数据结构方面考察较多的是链表知识
- 指针操作是面试重点
- 判断错误纠正错误题目需加强训练
- 编程题目考察链表与基本函数
面试题知识点总结
//1、如何给字符数组char[10]赋值
1)定义的时候直接用字符串赋值
char a[10] = "hello";
2)对数组中字符逐个赋值
char a[10] = {'h','e','l','l','o'};
3)利用strcpy
char a[10]; strcpy(a,"hello");
** 易错情况 **
/*
*1、char a[10]; a[10] = "hello";
* //一个字符怎么能容纳一个字符串?况且a[10]是不存在的。
*2、char a[10]; a = "hello";
* //这种情况容易出现,a虽然是指针,但是它已经指向在堆栈中分配的10个字符空间,现在这个情况a又指向数据区中的hello常量,这里的指针a出现混乱,操作不允许!
* 3、补充说明:char *a; a = "hello"是正确做法
* 4、C语言的运算符无法操作字符串,所以不能使用“==”来比较字符串,只能用strcmp()函数来处理。
* 5、在C语言中把字符串当作数组来处理,因此,对字符串的限制方式和对数组一样,特别是,他们都不可以使用C语言的运算符进行赋值和比较操作。
* 例如:str1 = "abc", str2 = str1,会被C语言编译器解释为一个指针对另一个指针之间的(非法)复制运算。
* 但是,使用=初始化字符数组是合法的:例:char str1[10] = "hello";这是因为在声明中,=不是赋值符号。
* 6、试图使用关系运算符或判断运算符来比较字符串是合法的,但是不会产生预期的结果:
* 例:if(str1 == str2),这条语句将str1和str2作为指针来进行比较,而不是比较两个数组的内容,因为str1和str2有不同的地址,座椅表达式的值一定为0。
*/
//2、关于“指向常量字符串的字符指针不可更改字符串内容”的理解及引申
int main()
{
// 字符数组,先在常量区存储"hello1",声明的字符数组arr[],系统会在栈区申请内存空间进行存放,
// 将"hello1"复制过去,arr指向栈区的"hello1"
char arr[] = "hello1";
char *p = "hello2"; // 注意p指向常量字符串,在常量区存储"hello2",p直接指向常量区的"hello2"
//在定义字符指针时默认的在前面有一个const就是无法修改它的值。
arr[0] = 'X'; // 可成功修改,
//可以使用arr[i] = 'a' 或者*(arr+i) = ‘a’的形式来修改数组内容。
p[0] = 'X'; // 编译器不能发现该错误,但运行时错误,p指向常量区内容,该区域内容不能被修改
arr = "hello2 world"; // 错误,arr是数组名,相当于指针常量,指向不能改变
p = "hello3 world"; // 可成功修改,p指向另一个字符串常量
return 0;
}
**要点说明**
/*
*1、在双引号“”内的字符序列或者转义字符串序列称为字符串常量这些字符串常量存储在内容的常量存储区。其内容不可被更改。
*(常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。与静态存储区有区别)。
*2、字符常量可以赋值给字符变量,如“char b = 'a'”;但不能把字符串常量赋给一个字符常量,同时也不能对字符串常量赋值。
*/
**面试真题**
下面叙述错误的是(D)
char acX[]='abc';
char acY[]={'a','b','c'};
char *szX="abc";
char *szY="abc";
A、acX与axY的内容可以修改
B、szX与szY指向相同的地址
C、acX占用的内存空间比acY占用的大
D、szX的内容修改后,szY的内容也会被更改
/*
* A acX和acY都是数组,当然可以修改
* B 因为"abc"是常量字符串,当它被多次使用时,编译器并不愿意再多分配出额外的内存空间存放多个"abc",而是重复使用这一个"abc",所以,scX和scY指针会指向同一个地址。
* C 因为acX是字符串数组,字符串的尾部有一个结束符'\0',所以acX有四个元素,内存空间比acY大。
* D 字符指针指向的是常量字符串,常量字符串不能修改,若修改,则变成指针重定向。
*/
void sqlist_str(char* in_str){
//该函数为错误函数,注释部分为改正方式。
//char *in_tmp = (char *)malloc(sizeof(in_str) * sizeof(char));
//in_tmp = in_str;
int i;
for (i=0; i<strlen(in_str); i++){
if ((*(in_str+i) == 0xa)||(*(in_str+i) == 0xb)){
*(in_str+i) = 0;
}
}
}
/* 注意:1、使用指针时需要先分配内存空间再赋值 */
/* 2、作为参数传入函数的字符串常量是不可更改的 */
//3、getmem()函数的实现,有面试需要改错,有面试需要直接写出
#define CODE_FIXED
/*
* 原因:传入pTemp分配内存,但getmem结束后,分配的空间被释放掉了。
* 主函数定义了一个指针pTemp,但是没给它分配内存,所以pTemp指向是一个无效的地址,然后子函数参数分配了一个指针char *pStr,这个指针的所有权是子函数的,当你调用子函数的时候,pTemp的值被复制到了pStr中,此时pStr同样是一个无效指针。
* 当调用malloc后,pStr会分配到一段有效内存空间,但是pTemp仍然指向的是无效空间(pTemp和pStr地址不一样,此处分配是给pStr分配)。
* 所以当子函数结束后,pStr作为参数变量,被销毁,那么这段内存虽然分配了,但是却使用不了(内存泄漏了)。
* 因此正确的方法是使用二级指针,让pStr成为指向指针的指针。*PStr将指向pTemp的内存地址,那么对*pStr分配就是对pTemp进行了内存分配
*/
#if defined(CODE_FIXED)
int getmen(char **pStr)//把被调函数getmem的参数该为char **pStr
{
*pStr = (char *)malloc(20);//把pStr改为*pStr,此处还需注意malloc返回值类型为void *,还需要进行强制类型转换成char *
//注意判空处理
if (*p == NULL)
free(*p);
return 0;
}
int main(int argc, char **argv)
{
char *pTemp = NULL;
getmem(&pTemp); //把pTemp改成&pTemp传入其地址
strcpy(pTemp,"123");
printf("pTemp = %s", pTemp);
return 0;
}
#else
int getmen(char *pStr)
{
pStr = (char *)malloc(20);
return 0;
}
int main(int argc, char **argv)
{
char *pTemp;
getmem(pTemp);
strcpy(pTemp,"123");
printf("pTemp = %s", pTemp);
return 0;
}
#endif
//4、手写memcpy函数,要求针对32位平台进行效率优化
/*
* 设计思路:常规方法是使用指针按照字节顺序进行赋值,但是性能太低。
* 原因有二,其一,一次复制一个字节效率太低,地址总线一般是32位,能搬运4字节,一次一个肯定很慢;其二,当内存区域重叠时会出现混乱情况。
* 在速度上进行优化时,可以按照CPOU位宽板运输局,效率更高
*/
void *mymemcpy(void *dst,const void *src,size_t num)
{
if((dst!=NULL)&&(src!=NULL))
{
int wordnum = num/4;
int slice = num%4;
int * pintsrc = (int *)src;
int * pintdst = (int *)dst;
while(wordnum--)
*pintdst++ = *pintsrc++;
while (slice--)
*((char *)pintdst++) =*((char *)pintsrc++);
return dst;
}
return 0;
}
拓展思考:编写实现memset功能的函数,以字节设置内存的值。
void *my_memset(void *str, char c, size_t size)
{
if (str == NULL) return 0;
char *pstr = (char *)str;
while(size--)
{
*pstr++ = c;
}
return str;
}
//5、设计一个函数,找出单向链表的倒数第N个元素(要求效率高,节省空间)
/*
* 解题思路:常规思路是先获取链表的长度N,然后返回N-K+1位置处的节点即可,但是此方法需要遍历两次链表。
* 双指针遍历:设定两个指针p1、p2,将这两个指针都指向第一个节点,然P1先走K步,然后两个指针一起向后移动,当P1达到最后一个节点时,P2指针刚好指向链表的倒数第K个节点。
*/
static int get_end_K(Node* link, int k)
{
Node *p1,*p2;
int i;
if (link->next == NULL || k <= 0)
return -1;
p1 = link->next;
while(k--)
{
if (p1->next == NULL) return -1;
p1 = p1->next;
}
p2 = link->next;
while(p1->next != NULL)
{
p1 = p1->next;
p2 = p2->next;
}
return p2->data;
}
//6、计算一个字符串中子串出现的次数。
/*解题思路*/
/*
* 串的匹配模式在数据结构中有KMP算法,但这个算法实现起来比较繁琐,难度很大,所以对于一般来说,使用暴力法求解
* 设有字符串str和子串sub,第一轮循环从str的第一个字符开始,设置一个位置标号j,再与子串sub逐个比较,若比较相同的话,则位置标记向后移,比较下一个字符,出现第一个不同字符则该轮比较结束
* 比较结束后若j的值和sub字符串长度相同,说明找到一个子串,计数count递增,第二轮循环则从str的第二个字符开始比较。以此类推
*/
int subString(char *str, char *sub)
{
int count = 0, i, j;
for (i = 0; i < strlen(str); i++)
{
for (j = 0; j < strlen(sub); j++)
{
if(str[i+j] != sub[j])
break;//出现不同字符就退出循环
}
if (j == strlen(sub))
count++;//退出循环后若j的值等于子串的长度,则找到子串。
}
return count;
}
//7、sizeof面试题分析
void *p = malloc(100); sizeof(p) = 4;
//指针的字节数与其数据类型无关,与其指向的内容容量无关,等于系统的字节长度。
void Func(char str[100]); sizeof(str) = 4;
//数组作为函数的参数进行传递时,该数组自动退化为同类型的指针。
char str[100]; sizeof(str)=100;
//不是函数的参数时
char str[] = "hello"; sizeof(str)=6;
//字符长度
char *p = str; sizeof(str)=4;
//指针变量
int n=10; sizeof(str)=4;
//根据数据类型判断
//使用sizeof求数组元素个数
char a1[] = "abc"; 元素个数:sizeof(a1)/sizeof(char) //总长度、单个元素长度
int a2[3]; 元素个数:sizeof(a1)/sizeof(a1[0]); //总长度、第一个元素的长度
sizeof判断占用内存空间延伸:
1).内存对齐规则:
结构(struct)、或联合(union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机器为4字节,要从4的整数倍地址开始存储)。
2).结构体作为成员:
如果一个结构体有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(struct a里面有struct b, b里面有char , int , doubel , 等元素,那么b应该从8的整数倍开始存储)。
3).收尾工作
结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
常用数据类型所占字节数
char 1;int 4;float 4;double 8;short 2;
自主复习知识 – 二分查找
#include <stdio.h>
#include <string.h>
/* 二分查找的两种实现方式 */
/* 二分查找也叫折半查找算法,针对一个有序的数据集合,每次都通过跟区间中间的元素对比*/
/* 将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为0 */
/* 迭代法 */
static int binary_search(int array[], int num, int value)
{
int low = 0;
int high = num - 1;
while(low <= high)
{
int mid = low + ((high - low) >> 1);
if(array[mid] > value)
high = mid - 1;
else if (array[mid] < value)
low = mid + 1;
else
return array[mid];
}
return -1;
}
/*递归法*/
static int binary_search_recurse(int array[], int low, int high, int value)
{
int mid = low + ((high - low) >> 1);
if (low > high) return -1;
if(array[mid] > value)
return binary_search_recurse(array, low, mid - 1, value);
else if (array[mid] < value)
return binary_search_recurse(array, mid + 1, high, value);
else
return array[mid];
}
int main(void)
{
int str[10] = {1,2,3,4,5,6,8,12,15,16};
int m;
m = binary_search(str, sizeof(str)/sizeof(str[0]), 5);
printf("binary_search: %d\n", m);
m = binary_search_recurse(str, 0, sizeof(str)/sizeof(str[0]), 5);
printf("binary_search_recurse: %d\n", m);
return 0;
}
面试官沟通问答
问题总结:
- 当前工作内容自我的概括能力不足,需加强
- 基本知识点的回答无法顺利回答
- 面试前期的准备不够充分
- 对自我简历的认知深度不够
- 面试官提问问题主要有,什么是大下端序?一个驱动文件包含哪几部分?如何编写一个驱动中的ko文件?关于I2C通讯协议?自我工作内容的概述,与软硬件如何配合?你在工作中遇到的最大挑战是什么?为何离开上家公司?
面试官提问基础知识复盘:
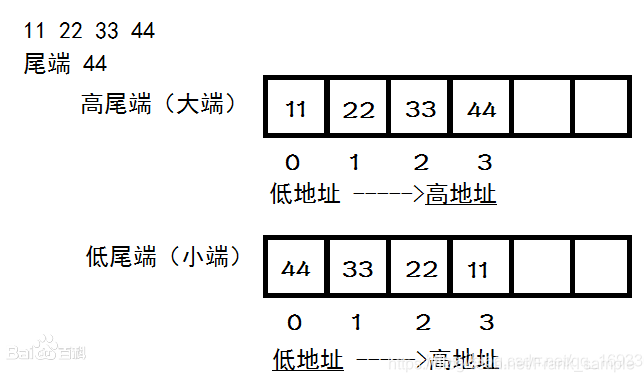
1、关于大小端序?
答:大端模式:低位字节存放在高地址上,高位字节存在低地址上
小端模式:低位字节存放在低地址上,高位字节存放在高地址上
采用小端模式的CPU对操作数的存放方式是从低字节到高字节,而大端模式对操作数的存放方式是从高字节到低字节。
/* 大小端判断 - 存放取位法 */
/* 原理
* 以int类型存入一个数字1,它换算成16进制存入内存的数据是0x00000001
* 取该数据的低位字节
* 如果是大端存储:01这个低字节存放在高地址,高字节00存放在低地址
* 如果是小端存储:01这个低字节存放在低地址,高字节00存放在高地址
* 如何获取得到01这个字节,使用char*指针即可取到1个字节
*/
int check_CPU()
{
int a = 0;//0x00000001
return *((char *)&a)
//返回1,表示小端;
//返回0,表示大端;
}
/* 大小端判断 - 共用体法 */
/* 原理
* 联合也是一种特殊的自定义类型这种类型定义的变量也包含一系列的成员,
* 特征是这些成员公用同一块空间(所以联合也叫共用体)
* 存一个int类型数组,int i =1, 以char类型的取一字节。
*/
union
{
char c;
int i;
}u;
int check_CPU()
{
u.i = 1;
//返回1,表示小端
//返回0,表示大端
return u.c;
}
2、一个内核模块包含哪些部分?
**必备头文件**
module.h //包含有装载模块需要的大量符号和函数的定义
init.h //用来指定初始化和清除函数
- 模块加载函数
//当通过insmod或modprobe命令加载内核模块时,模块的加载函数会自动被内核执行,完成本模块的相关初始化工作。
- 模块卸载函数
//当通过rmmod命令卸载某模块时,模块的卸载函数会自动被内核执行,完成与模块加载函数相反的功能。
- 模块许可证声明
//许可证(LICENSE)声明描述内核模块的许可权限,如果不声明LICENSE,模块被加载时,将收到内核被污染(Kernel Tainted)的警告
//在Linux内核模块领域,可接受的LICENSE包括“GPL” 、 “GPL v2” 、 “GPL and additional rights” 、 “Dual BSD/GPL” 、 “Dual MPL/GPL”等,一般常用GPL许可证
- 模块参数
//模块参数是模块被加载的时候可以传递给它的值,它本身对应模块内部的全局变量
- 模块导出符
//内核模块可以导出的符号(symbol,对应于函数或变量),若导出,其他模块则可以使用本模块中的变量或函数
- 模块作者等信息声明
3、如何编写一个ko文件?
1).编写模块.c文件
#include <linux/module.h> //所有内核模块都必须包含这个头文件
#include <linux/init.h> //一些初始化的函数如module_init()
static int hello_init(void)
{
printk("hello_init");
}
static void hello_exit(void)
{
printk("hello_exit \n");
}
MODULE_LICENSE("GPL"); //模块许可声明
module_init(hello_init); 加载时候调用该函数insmod
module_exit(hello_exit);卸载时候 rmmod
2).编写编译文件Makefile
ifneq ($(KERNELRELEASE),)
obj-m:=hello.o
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build #内核源码目录
PWD:=$(shell pwd) #当前目录
all:
make -C $(KERNELDIR) M=$(PWD) modules
clean:
rm -rf *.ko *.o *.sysvers *.cmd *.cmd.o *.~core .depend *.mod.c
endif
3).模块操作工具
insmod #加载模块,indmod hello.ko会自动调用hello_init()函数
rmmod #模块释放,rmmod hello.ko就可以卸载hello.ko模块
modprobe #比较高级的加载和卸载模块命令,可以解决模块之间的依赖问题
lsmod #列出已加载的模块信息
modinfo #查询模块的相关信息,比如作者、版权等。
4、关于I2C总线简述
I2C是一种由PHILIPS公司开发的两线式串行总线,用于连接微控制器及其外围设备。由数据线SDA和时钟线SCL组成的串行总线,可发送和接收数据。
I2C采用半双工的通信方式,任何一个设备都能像主控器一样工作,并控制总线,但是同一时刻只能有一个主控设备。
总线上的每一个设备都有一个独一无一的地址,根据设备的能力,作为主设备或从设备工作。
SDA传输数据采用大端传输的方式(高位先传,低位后传),以字节为单位。
I2C的基本通信流程:
1)、主设备发出开始信号(Start),SCL为高电平,SDA线由高电平转变为低电平。
2)、主设备发出 8bit 的从设备地址信息,其中最低位为读写控制码(0为写,1为读),高7位为从机器地址码。
3)、从设备发出应答信号,表示I2C通信成功
4)、主设备开始对设备进行读写操作;
如果是读操作,则每读取8bit数据,主设备会发送一个应答信号(ACK)给从设备;如果是写操作,则每写入8bit数据,从设备会发送一个应答信号(ACK)给主设备
5)、重复数据读或写流程
6)主设备发出结束信号(Stop),SCL为高电平,SDA由低变高。
拓展:简述SPI总线
SPI是Motorola公司推出的一种同步串行通讯总线,一般有四条信号线,串行时钟(SCLK)、串行数据输出(SDO)、串行数据输入(SDI)、片选信号(SS)。
SPI总线采用全双工的通信方式,收发独立,操作简单,数据传输速率高,但是只支持单个主机,没有指定的流控制,没有应答机制确认是否接收到数据。
SPI总线特点:
1)、采用主-从模式的控制方式
SPI规定两个SPI设备之间通信必须由主设备来控制此设备。一个Master设备可以提供clock以及对Slave设备进行片选来控制多个Slave设备。
SPI协议规定Slave设备的clock由Master设备通过SCK管脚进行分配,Slave设备本身不能产生或控制Clock,没有clock的Slave设备不能正常工作。
2)、采用同步方式传输数据
Master设备会根据要交换的数据来产生相应的时钟脉冲,时钟脉冲组成了时钟信号,时钟信号通过时钟极性(CPOL)和时钟相位(CPHA)控制着两个SPI设备间何时数据交换以及何时对接收到的数据进行采样,来保证数据在两个设备之间的同步传输。
3)、数据交换
SPI设备间的数据传输之所以被称为数据交换,是因为SPI协议规定一个SPI设备不能在数据通信过程中仅仅只充当一个“发送者”或者“接收者”。也就是说是全双工的,在每个Clock周期内,SPI设备都会发送并接收一个bit大小的数据,相当于该设备有一个bit大小的数据被交换了。
一个Slave设备要想能够接收到Master发过来的控制信号,必须在此之前能够被Master设备进行访问。所以,Master信号必须首先通过SS/CS对Slave设备进行片选,把想要访问的Slave设备选上。
在数据传输的过程中,每次接收到的数据必须在下一次数据传输之前被采样。如果之前接收的数据没有被读取,那么这些已经接收完成的数据将有可能会被丢弃,导致SPi物理模块最终失效。
因此,在程序中一般都会在SPI传输完数据后,去读取SPI设备里的数据,即是这些数据(Dummy Data)在我们的程序里是无用的。
总结:SPI总线与IIC总线的异同
1、IIC总线是半双工,2根线(SCL、SDA),SPI总线实现全双工,4根线(SCK、CS、MOSI、MISO)
2、IIC是多主机总线,通过SDA上的地址信息来锁定从设备。SPI总线只有一个主设备,主设备通过CS片选来确定设备。
3、IIC总线的传输速度在100kb~4Mb。SPI总线传输速度更快,可以达到30MHz以上。
4、IIC总线空闲状态下SDA、SCL都是高电平,SPI总线空闲状态MOSI MISO也都是高电平,SCK是由CPOL决定的。
5、IIC总线SCL高电平时,SDA下降沿标志传输开始,上升沿表示传输结束。SPI总线cs拉低标志传输开始,cs拉标志传输结束
6、IIC总线是SCL高电平采样。SPI总线因为是全双工,因此是沿采样,具体要根据CPHA决定。一般情况下,Master device是SCK的上升沿发送,下降沿采集。
7、IIC总线和SPI总线数据传输都是MSB在前,LSB在后(串口是LSB在前)
8、IIC总线和SPI总线时钟都是由主设备产生,并且只在数据传输时发出时钟。
9、IIC总线读写时序比较固定统一,设备驱动编写方便。SPI总线不同从设备读写时序差别比较大,因此必须根据具体的设备datasheet来实现读写,相对复杂。

















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









