










 文章介绍了从传统的使用Postman进行接口测试,到利用Python脚本自动化测试,包括读取Excel存储的测试用例,执行GET和POST请求,以及JSON解析。进一步讨论了接口测试自动化如何与持续集成工具如Jenkins结合,虽然PDF报告在Jenkins展示不便,但可以通过脚本分享或邮件发送。作者分享了个人经验,旨在帮助读者提升测试效率。
文章介绍了从传统的使用Postman进行接口测试,到利用Python脚本自动化测试,包括读取Excel存储的测试用例,执行GET和POST请求,以及JSON解析。进一步讨论了接口测试自动化如何与持续集成工具如Jenkins结合,虽然PDF报告在Jenkins展示不便,但可以通过脚本分享或邮件发送。作者分享了个人经验,旨在帮助读者提升测试效率。
目录
前言:
在现代软件开发中,自动化测试和持续集成是两个不可或缺的环节。自动化测试可以提高测试效率、减少人工错误,并确保软件的质量。持续集成则可以帮助开发团队更快地集成和交付代码,提高开发效率和团队协作。
- 传统接口测试
- 接口自动化测试
- 接口自动化的持续集成
- 探讨
传统接口测试
不知道别人家的接口测试是怎么做的。这边是用 postman 这个 google 插件。测试人员按照接口开发人员的 wiki,设计测试用例,然后 post/get 一下。查看返回 json 的状态或者字段。

弱点是不便于管理 case 和不方便统计结果,执行要一个一个手工去点,效率低下。
接口测试自动化
我用 python 写了个脚本,将 case 写在 excel 里,然后读取 excel 来实现这个过程,并自动判断和统计结果,生成报告。
case 这么设计的。
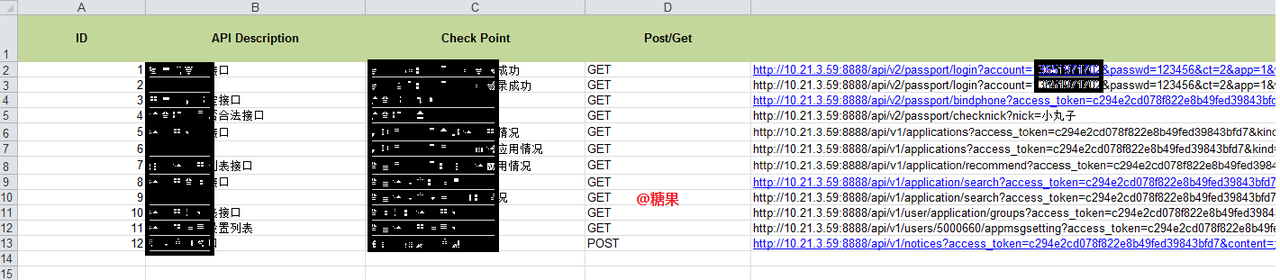
脚本这么写的:
#encoding:utf-8
import ConfigParser
import os
import xlrd
import re
import httplib
import urllib
from urlparse import urlparse
import json
import time
import unittest
import pdf
currentdir=os.path.split(os.path.realpath(__file__))[0]
class test_class():
def getexcel(self):
casefile=currentdir + '/case.xls'
if ((os.path.exists(casefile))==False):
print "当前路径下没有case.xls,请检查!"
data=xlrd.open_workbook(casefile)
table = data.sheet_by_name('login')
nrows = table.nrows #行数
ncols = table.ncols #列数
#colnames = table.row_values(1) #某一行数据
for rownum in range(1,nrows):
for col in range (3, ncols):
value=table.cell(rownum,col).value
if (col==3):
method=value
if (col==4):
url=value
return table,nrows,ncols
def getexceldetail(self,table,row,ncols):
#rownum = table.row_values(row) #某一行数据
for col in range (0, ncols):
value=table.cell(row,col).value
if (col==0):
caseid=value
print caseid
if (col==3):
method=value
print method
if (col==4):
url=value
return method,url,caseid
def httpget(self,url):
httpClient = None
conn = urlparse(url)
url=url.encode('utf-8')
try:
httpClient = httplib.HTTPConnection(conn.netloc, timeout=10)
httpClient.request('GET', url)
# response是HTTPResponse对象
response = httpClient.getresponse()
print response
d0=response.read()
d0=d0.decode('unicode_escape')
except Exception, e:
print e
finally:
if httpClient:
httpClient.close()
return response.status,d0
def httppost(self,url):
httpClient = None
conn = urlparse(url)
url=url.encode('utf-8')
try:
header = {"Content-type": "application/x-www-form-urlencoded",
"Accept": "text/plain"}
httpClient = httplib.HTTPConnection(conn.netloc, timeout=30)
httpClient.request("POST", url)
response1 = httpClient.getresponse()
d1=response1.read()
d1=d1.decode('unicode_escape')
except Exception, e:
print e
finally:
if httpClient:
httpClient.close()
return response1.status,d1
代码太多了点,没写下。其实就是一个读 excel,一个 post,一个 get 的过程。
后面还有一个对 json 的解析过程。开始以为是一个字典就搞定了,后面发现有些{}里面嵌套了好几层。
最后用了个递归搞定。
#! /usr/bin/env python
#coding=utf-8
import urllib2
import json
class readjson():
def read(self,obj,key):
collect = list()
for k in obj:
v = obj[k]
if isinstance(v,str) or isinstance(v,unicode):
if key== ' ':
collect.append({k:v})
else:
collect.append({str(key)+"."+k:v})
elif isinstance(v,int):
if key== ' ':
collect.append({k:v})
else:
collect.append({str(key)+"."+k:v})
elif isinstance(v,bool):
if key== ' ':
collect.append({k:v})
else:
collect.append({str(key)+"."+k:v})
elif isinstance(v,dict):
collect.extend(read(v,k))
elif isinstance(v,list):
collect.extend(readList(v,key))
return collect
def readList(self,obj,key):
collect = list()
for index,item in enumerate(obj):
for k in item:
v = item[k]
if isinstance(v,str) or isinstance(v,unicode):
collect.append({key+"["+str(index)+"]"+"."+k:v})
elif isinstance(v,int):
collect.append({key+"["+str(index)+"]"+"."+k:v})
elif isinstance(v,bool):
collect.append({key+"["+str(index)+"]"+"."+k:v})
elif isinstance(v,dict):
collect.extend(read(v,key+"["+str(index)+"]"))
elif isinstance(v,list):
collect.extend(readList(v,key+"["+str(index)+"]"))
return collect
#ojt=test_data1
#print read(ojt,' ')
最后是结果:
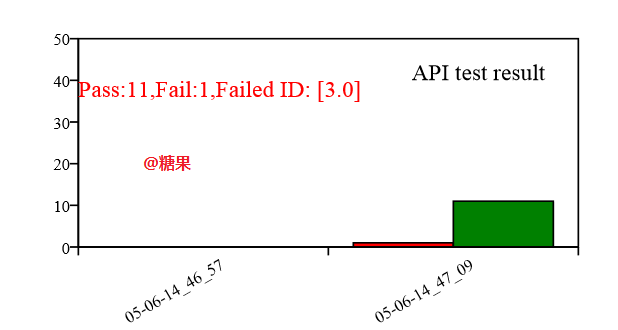
是用 python 写图表,生成 pdf.
from reportlab.graphics.shapes import Drawing
from reportlab.graphics.charts.barcharts import VerticalBarChart
from urllib import urlopen
from reportlab.graphics.shapes import *
from reportlab.graphics.charts.lineplots import LinePlot
from reportlab.graphics.charts.textlabels import Label
from reportlab.graphics import renderPDF
class pdfreport():
def createpdf(self,datas):
drawing = Drawing(400, 200)
#data = [(13, 5, 20),(14, 6, 21)]
data=datas
bc = VerticalBarChart()
bc.x = 50
bc.y = 50
bc.height = 125
bc.width = 300
bc.data = data
bc.strokeColor = colors.black
bc.valueAxis.valueMin = 0
bc.valueAxis.valueMax = 50
bc.valueAxis.valueStep = 10
bc.categoryAxis.labels.boxAnchor ='ne'
bc.categoryAxis.labels.dx = 8
bc.categoryAxis.labels.dy = -2
bc.categoryAxis.labels.angle = 30
bc.categoryAxis.categoryNames = ['Jan-99','Feb-99','Mar-99']
#bc.categoryAxis.categoryNames =ytype
drawing.add(bc)
drawing.add(String(250,150,"ss", fontSize=14,fillColor=colors.red))
#drawing.add(String(250,150,des, fontSize=14,fillColor=colors.red))
renderPDF.drawToFile(drawing,'report1.pdf','API')
#renderPDF.drawToFile(drawing,'APIReport.pdf','API')
datas=[(0,20),(0,25)]
f=pdfreport()
f.createpdf(datas)
接口自动化的持续集成
配置到 jenkins 上也很简单,这里就不过多描述。现在问题是,生成的报告是 pdf。Jenkins 里面不太好展现出来。弄成 zip 附件查看不方便。最后我写个脚本将其传到共享里面,或者写脚本用邮件发出来。后面写打包的时候会讲到的。
![]()
作为一位过来人也是希望大家少走一些弯路
在这里我给大家分享一些自动化测试前进之路的必须品,希望能对你带来帮助。
(WEB自动化测试、app自动化测试、接口自动化测试、持续集成、自动化测试开发、大厂面试真题、简历模板等等)
相信能使你更好的进步!
点击下方小卡片
















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









