






一、存储系统基本概念
在计算机组成原理的第一章我们说过,由存储器、运算器和控制器组成主机,第二章主要讲的是运算器与控制器是如何配合CPU中的各种寄存器完成二进制数的算术运算的。那么第三章存储系统主要讲的就是存储器是如何在计算机中形成一个存储体系的。
1.1存储系统的层次结构
神说要有主存,于是便有了主存,但是由于组成主存的元件特性限制,主存的数据传输效率不会很高,但是CPU运行速度是很快的。那么为了解决CPU与主存之间的速度矛盾,于是便有了Cache,Cache是一种高速存储器,他可以介于主存和CPU之间,来降低这个矛盾,但是CPU的运算过程中,还需要一些存储器来辅助CPU完成运算过程,这个存储器就是ACC、MQ等寄存器,所以寄存器是介于CPU与Cache之间的。
CPU可以直接与Cache进行数据交换,也可以直接与主存进行数据交换,而Cache与主存之间也可以直接进行数据交换,这个过程是由硬件自主完成的。但无论是Cache、主存还是寄存器,他们的电路设计过于复杂,集成度不会特别高,就导致他们无论如何都满足不了现代计算机所需要的存储容量,于是便出现了辅存,所以辅存是为了解决主存存储容量不够的问题,辅存的容量很大,比如磁盘、光盘等都是辅存,辅存的存储容量虽然大,但是他们的电路设计简单,造价低,这也导致了辅存功能性差,不能与CPU直接进行数据交换,只能与主存直接进行数据交换,而这个交换过程就是我们操作系统中所讲的作业调度变为进程,这个知识在操作系统中讲到,那么显然这个过程是由操作系统完成的。这样一来由计算机的存储系统便层次分明,各层互相配合着工作。
1.2存储器的分类
存储器可以通过材料来划分:主存和Cache由半导体材料组成,内存条和Cache中的MOS管就是半导体材料;磁盘和磁带这种外存由磁性材料组成;光盘由光性材料组成。存储器还可以通过存取方式进行分类:首先是随机存取存储器(RAM),这种存储器给出任意一个逻辑地址,CPU可以直接找到对应的物理地址,存取时间与其本身的物理位置无关;顺序存取存储器(SAM),这种存储器是根据存储的物理地址来顺序的访问存储的内容,比如磁带,只有当磁带旋转到某个位置时才能访问该位置存储的内容;直接存取存储器(DAM),这种存储器即有随机存取的特性,又有顺序存取的特性,比如机械硬盘,机械硬盘的磁头可以移动到任意位置这就有了随机的特性,而机械硬盘的盘块又可以旋转,这就有了顺序的特性。以上三种存储器都是给出一个地址,根据地址来找到对应的数据信息,但是有一种存储器叫做相联存储器,这种存储器是直接根据内容来检索存储位置进行读写操作,快表就是相联存储器。
存储器还可以通过写入信息的可更改性来划分,比如光盘,一但写入就无法更改,而磁盘、内存、Cache等就可以更改,最后是根据断电能否保存信息来划分:内存和Cache断电后信息会丢失,而磁盘和固态硬盘断电后信息不会丢失。
1.3存储系统的指标
1.存储容量:表示形式为512K×32位这种形式,512K为存储字数,32位为存储字长。该知识点通常与Cache的容量与内存的转换关系以及字位扩展来联合考察。
2.单位成本:总成本/总容量,该知识点我还没见到对应题目,考的较少。
3.存储速度:存储字长/存储周期,该知识点重点是存储周期的概念,存储周期分为存取时间和恢复时间,恢复的过程也是刷新的过程,在后面我们会讲到。
二、存储器的基本组成
2.1DRAM芯片基本组成
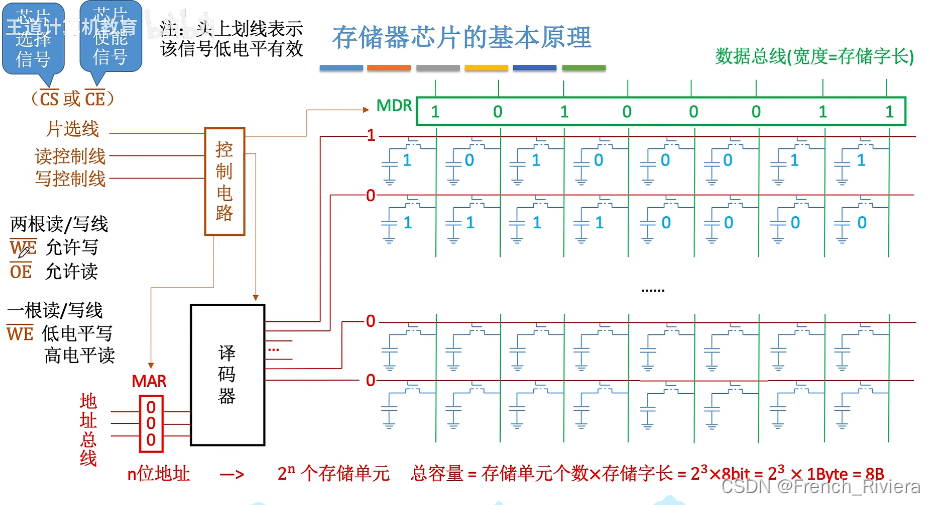
该图为内存条的电路基本组成,也是DRAM芯片的基本组成,图中右侧中的一个基本元件是由一个电容接地,然后一个MOS管一端连着电容一端连着数据线来形成一个基本元件,在数电中MOS管其实就是一个高电平打通,低电平不通的一个半导体元件,而电容中就可以存放高电平或者低电平的电荷。图中红色的线是地址线(这里为了方便我直接说地址线,但是这个地址线和地址总线不同),地址线可以通过译码器传送的电流来打通MOS管;绿色的线是数据线,当某一行的MOS管被打通后,电容中的电荷会通过MOS管进入数据线,通过数据总线来传送数据。图中译码器的功能就是通过地址总线传来的地址来判断此时应该接通哪根地址线来打通MOS管。
以上是内存条中单个芯片的工作原理,但是众所周知,一个内存条包含多个DRAM芯片,那么我们如何去选择此时到底是要使用哪个芯片呢?这就涉及到了片选线的功能(如果头上有一横就代表低电平有效),那么每个芯片都有一根片选线连接着控制电路,图中是低电平有效,所以控制电路一开始会将所有片选线都连接高电平信号,当我们要读取某个芯片的数据时,控制电路会对相应芯片的片选线连接一个低电平信号来打通该芯片,这样我们就可以读写该芯片中的内容,不用我说,读写自然也是需要占用一根线的。
这样一来,内存条的整体工作原理便理清了,芯片是通过引脚来与内存条相连接的,而我们刚才所说的所有的线都需要占用一个引脚,题中经常考察的点就包括让你计算一个芯片的引脚数目,引脚数目=地址总线数+数据总线数+片选线+读写控制线(不过片选线这里可能会存在一些问题,在DRAM的地址线复用技术中,片选线似乎被行选通线和列选通线所代替,在真题中我也没见过要计算芯片的总引脚数所以也没法证实,真题中通常是求地址线数和数据线数)。
2.2寻址
这里直接举例说明,假如一个内存共有16个地址,那么也就是说共有2^4个地址,那么就需要4根地址总线也就是4位比特的数据来表达这16个地址,DRAM地址线复用技术中,地址总线数量还可以减半。
2.3DRAM芯片的地址线复用技术
在前面的图示中我们发现,所有的地址线都连在一个译码器上,图中的地址为3位,可以表示8个地址,而现代计算机的地址通常都是32位和64位,那么可以表示的地址就是很大的一个量级,那么此时将这么多的地址线都连接在一个译码器上,显然是不太现实的,那么我们就需要将一个32位的地址拆分成前16位和后16位,那么如果此时我们有两个译码器,分别传输这16位地址的话,就可以大大降低一个译码器所连接的地址线数量,如图。 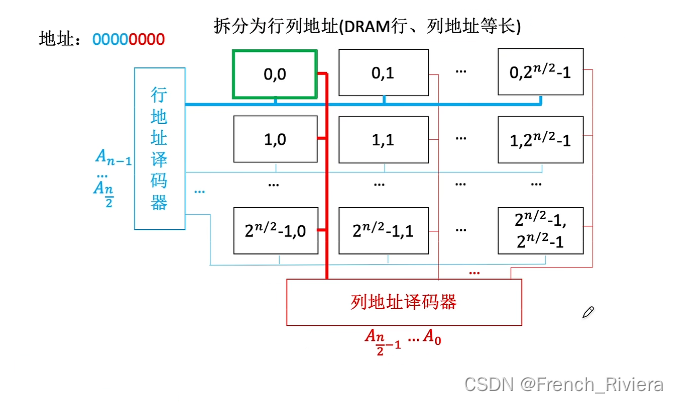
该图就是将译码器分为了行地址译码器和列地址译码器,分别传输前16位地址和后16位地址。那么现在我们解决了一个译码器的地址线负担问题,我们现在来讲讲DRAM的地址线复用技术
比如一个内存中一共有16个地址,那么如果按照行列来划分的话,就是有4行4列,那么也就是说一共需要2个行地址总线和2个列地址总线就可以表达4个行和4个列。那么DRAM的地址线复用技术就是指,行地址总线和列地址总线合并使用也就是一共使用2个地址总线来传输地址,先给行地址译码器传送2比特位地址,再给列地址译码器传送2比特位地址,这样一来地址总线的数量可以减半,而且电路设计起来更加简单。
2.4DRAM和SRAM的区别
DRAM和SRAM最基本的区别就在于元件不同,这也导致了二者的性质差异。DRAM是由栅极电容来存放数据,而SRAM是用六个MOS管形成的电路中某两处电平高低的两种状态,也叫双稳态触发器来存储信息的。
当我们读取DRAM芯片中的信息时,由于DRAM芯片是通过电容来存储信息的,读取信息就代表着拿走电容中的电荷,那么这种读取信息的方式就是破坏性的读出,当我们读出信息之后还需要对电容中的电荷进行恢复的操作,这也是为什么一个存取周期=存取时间+恢复时间的原因,而由于SRAM是通过电路中的电平高低来存放信息的,故读取信息的方式为非破坏性的读出,而这也是SRAM比DRAM更快的原因之一。
在DRAM芯片中,由于存放信息的元件是电容,而如果长时间不给电容充电,那么电容中的电荷就会自己消失,也就是说,我们每隔一段时间就要对DRAM芯片中的某行栅极电容进行充电操作,而这个操作又称刷新,通常一个电容能将电荷存放2ms。而刷新的方式分为三种:1.集中刷新:集中刷新就是等2ms过后集中一段时间将整个芯片中所有电容进行充电操作,而这个过程中,CPU无法访问该DRAM芯片中的内容,这个过程叫做访存死区;2.分散刷新:每读一行信息就立即对该行电容进行刷新,通常访存时间0.5μs,刷新时间0.5μs,该刷新方式不存在死时间、死区一说;3.异步刷新:2ms内一共会产生128个刷新请求,将128个刷新请求分散到这2ms内进行刷新,也就是每隔15.6μm刷新一次,而该刷新时间称为死时间。SRAM不需要刷新,而这也是SRAM比DRAM更快的原因之一。值得注意的是区分好恢复和刷新的区别。
接下来就是一些比较容易理解的区别:1.集成度,由于SRAM电路复杂,单位元件较大,故SRAM的集成度较低;2.发热量,SRAM电路复杂,发热量自然较高;3.运行速度:SRAM较快;4.存储成本,SRAM造假高存储成本自然就较高。5.最后是是否采用地址线复用技术:SRAM由于存储空间较小,故SRAM不采用,DRAM存储空间大,地址线较多,故采用。SRAM常用作制备Cache而DRAM常用作制备内存。
2.5几种常见的ROM
第一种ROM:掩膜式只读存储器MROM,这种存储器是由厂家直接生产写入信息后,不可修改;第二种ROM:可编程式存储器PROM,这种存储器可以写入一次内容,写完后便不能再修改;第三种ROM:可擦除可编程存储器EPROM,这种存储器分为两种,光擦除UVEPROM,一种是电擦除EEPROM这种存储器可以重复写入和擦除,光擦除是全部擦除,电擦除可以擦除一部分内容;第四种ROM:闪存式存储器flash,这种存储器特点是写入速度较快,不过每次写入都要先将存储器中的内容全部擦除;第五种ROM:固态硬盘SSD,这种存储器保留了flash中的存储芯片,但与flash最大的区别在于控制单元不同。
总的来说,在目前的说法中,RAM通常指的是内存,ROM通常指的是外存,在计算机开机的时候,由于内存的断电信息丢失的特性,导致内存中没有任何数据,也就是说CPU无法通过调入内存中的指令来启动操作系统,那么CPU就需要使用主板上的另一块元件:BIOS芯片,BIOS芯片属于ROM,故CPU会直接调用ROM中的指令来启动操作系统,但是我们前面说过,外存无法直接与CPU进行数据互换,所以不能绝对的将ROM看作是辅存,所以主存包括RAM以及一部分ROM。RAM和ROM的界限没有那么清晰明朗。
三、多模块存储器
在学计算机之前,我们可能大多数人都听说过双通道可以使计算机运行速度更快,而现在的商家在售卖内存条的时候,通常也将一个16GB的内存拆分成两个8GB的内存来售卖,那么双通道和内存拆分来售卖有什么联系呢?双通道又是如何来实现的?
3.1交叉编址的多体存储器
其实双通道的原理来源于内存条DRAM的恢复操作,我们前面说过,当我们读出一个DRAM芯片的时候是破坏性的读出,读出一个数据后需要一端恢复时间,所以说存取周期=存取时间+恢复时间,而我们知道物理地址在内存中是连续存放的,根据局部性原理,我们读出地址1,接下来很可能读取地址2和地址3,那么如果我们将这些地址全都储存在一个DRAM芯片上,那么每当我们读取一个地址的时候,都需要等待一整个存取周期,因为读完一个数据后DRAM芯片需要恢复数据,此时CPU是无法继续访问该DRAM芯片的。那么有没有什么办法能使CPU在访问连续地址的情况下,不连续访问某个内存条呢?如图: 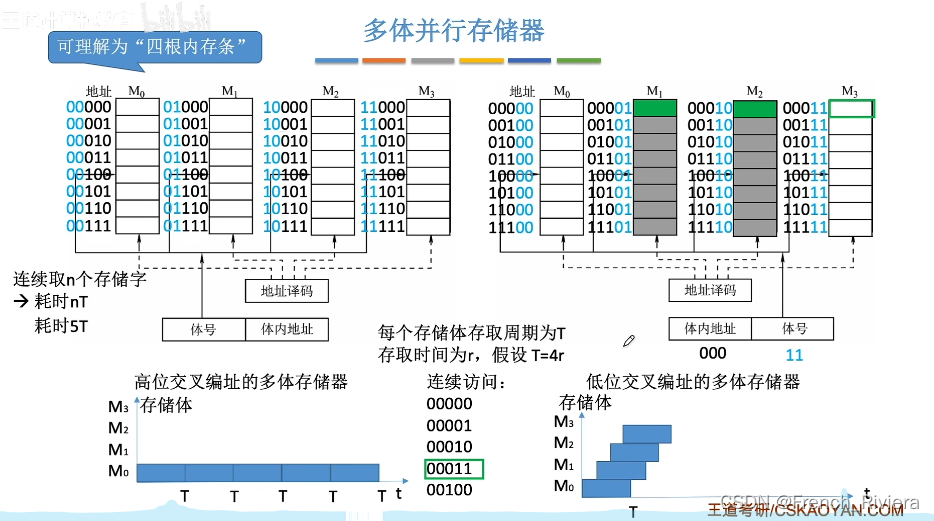
图左为高位交叉编址的四体存储器,图右为低位交叉编址的四体存储器,我们假设存取时间为r,恢复时间为3r,存取周期为T=4r,根据高位交叉编址我们发现地址的高两位代表着几号内存条,而连续的地址存放在同一根内存条中,这样一来就发生了我们前面说的,CPU不能连续访问同一个内存条芯片的问题,而低位交叉编址由于连续的4个地址存放在四个不同的内存条中,根据存取时间和恢复时间的长度,来指定到底使用几个内存条,这样一来就避免了CPU无法连续的访问同一个内存条的问题。
3.2单体多字存储器
这种存储器就是将上面的多体合并成一体,每次读取的时候一次性的读走一整行的信息,在上图左的图示来说就是一次性读走00000、00001、00010、00011这四个字,所以是单体多字存储器,显然这种存储器相较于多提存储器而言,读取信息更快,但是很多时候可能会都到很多无用的信息,综合来看还是多体存储器性能更好。
四、CPU与存储器的连接
当我们购买内存条的时候会发现上面有不止一个芯片,这是由于单个芯片的存储空间有限,需要将这些芯片合并到一起再与CPU进行连接,存储容量的表示方法通常为512K×32位这样的形式,那么一个芯片可能无论在存储字数上,以及位数上都要小于存储容量,那么我们本节主要讲的就是如何在字数上和位数上来使芯片合并到一起达到扩容的目的。
要想知道如何合并芯片,那么我们首先要知道芯片与CPU都有哪些线相连,首先是片选线负责选择芯片,其次是读写控制线,在然后就是地址总线和数据总线。
4.1位扩展
位扩展显然是某个芯片的位数小于存储字长,我们需要使芯片的位数扩展到与存储字长相同,那么位数与CPU上的数据总线有关,我们只需要选中多个芯片将芯片与所有数据总线相连接,而地址总线只需要选中那些一个芯片能够接受的地址范围所代表的线即可,如图: 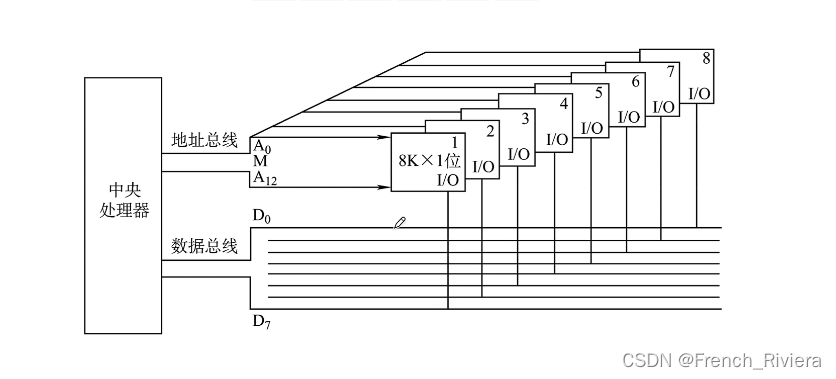
从图中我们可以看到,CPU的所有数据总线全部被芯片所连接,而地址总线一共只连接了13根,这是因为一个芯片的地址范围为8K正好对应13根地址总线。
学完了位扩展,我们还需要思考几个问题,一个芯片位扩展就连接了8个芯片,而片选线是用来选择此时使用哪个芯片的,那么位扩展中片选线应该如何连接?显然,位扩展中所有芯片的片选线接口只需要一个片选信号即可,这是因为,这8个芯片存放的信息是需要同时使用的,因为地址总线传给芯片的二进制数被分别存放在了这8个芯片中。
4.2字扩展
位扩展中是芯片位数小于存储字长,那么如果芯片字数小于存储字数,就需要进行字扩展,但是一个CPU的地址总线数量有限,不能像位扩展一样,每个芯片都连接一个地址总线,那么此时我们就需要片选线的帮助,试想一下,如果地址总线给每个芯片都传送同样的地址数据,但是我们可以通过重定位寄存器重新定位每个芯片所对应的地址,这样不就可以达到扩展字数的目的吗?

我们用4个芯片举例,我们可以看到,一个芯片位数为8位,CPU的数据总线也是8根,正好一一对应,但是地址总线只连接了12根在芯片的地址接口上,这就是我前面说的,地址总线给每个芯片都传送同样的地址数据,而14和15这两根地址总线连接着译码器,而两个地址数据正好能表示4个芯片,译码器的作用就是通过14和15这两根地址总线传来的数据来判断此时使用哪个芯片,再通过重定位寄存器来将CPU给出的逻辑地址转换为芯片中的物理地址即可达到扩展字数的目的。
与字扩展的译码器对应的就是直接将地址总线连接到存储芯片的片选接口上,但是这样一来不仅扩展能力会下降,而且地址也不会连续,该方法叫做线选法,而译码器叫做译码片选法。
4.3字位扩展
字位扩展就是将字扩展与位扩展结合,如图: 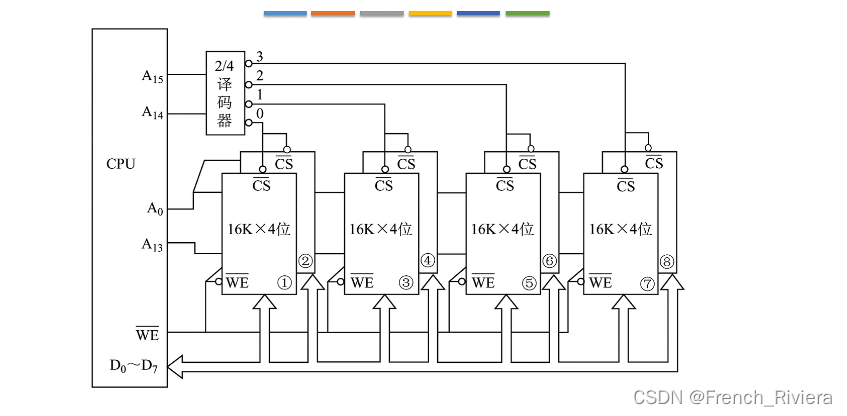
该图示就是字位扩展法,我们可以看到一共有8块芯片,1号芯片和2号芯片进行的是位扩展,1号芯片和3号芯片进行的是字扩展,而1号芯片和2号芯片的片选线接口连接着同一个片选线,而1号芯片和3号芯片的片选接口连接着不同的片选线。
五、外存储器
5.1磁盘存储器
磁盘存储器又称机械硬盘存储器,机械二字的含义就是该存储器是由磁头、磁盘、马达等机械元件组成,磁头负责读写数据,磁盘通过表面涂抹的磁性材料来存储不同方向的磁场来存储二进制的0和1,而马达负责旋转磁盘,来使磁头移动到磁盘的特定位置来读取磁盘上的数据。
我们重点要讲磁盘,磁盘上涂抹的磁性材料是一圈一圈的涂上去的,而每一圈磁性材料被称作一条磁道,一个机械硬盘可能包含多个磁盘,这些磁盘纵向排列,这样每个磁盘上的磁道就形成了一个柱面,而一条磁道上的某个弧称作扇区,机械硬盘结构如图:

了解了机械硬盘的基本结构之后,我们接下来要重点学习机械硬盘的性能指标。
1.机械硬盘容量:我们看到图中的磁盘,最上面和最下面并没有磁头,这说明并不是每个盘面都有数据存储,而且也并不是连接了磁头的盘面就存储数据,这与厂家出厂磁盘的时候是否格式化有关,为了避免某个磁盘的盘面损坏导致的数据丢失,厂家通常会将磁盘格式化,通过保留一些磁盘盘面不给用户写入数据,来使损坏的盘面数据复制到保留好的盘面上,所以格式化后的机械硬盘会比未格式化的机械硬盘空间更小。
2.记录密度:一个磁盘,在我们的认知中,处于不同半径下的磁道长度自然不同,也就是越外圈的磁道长度越长,但是这并不能代表越外圈的磁道存放的数据越多,机械硬盘中,盘面的内圈和外圈的磁道存放的数据一样多,这也代表着越是内圈,记录密度越大。
3.平均存储时间:该性能指标是常考点,平均存储时间=寻道时间+旋转延迟时间+传输时间,寻道时间是指磁头寻找对应磁道的时间,旋转延迟时间是指找到对应磁道后,磁盘旋转到对应扇区的时间(通常取磁盘转半圈的时间),传输时间是指找到对应扇区后磁头划过扇区所需要的时间。
4.数据传输率:数据传输率=磁盘转速×一条磁道存放的字数。
最后是磁盘阵列,又称廉价冗余磁盘阵列RAID,RAID0是指磁盘不经格式化,磁盘的全部盘面都可以被用户所使用,但是这种方式如果盘面损坏会丢失数据;RAID1是指磁盘只有一半的空间可以被用户所使用,另一半的空间用来拷贝用户所存放的数据,这样一来当盘面损坏时,也不会造成数据丢失,但是这种方式冗余信息过多;RAID2是指用一部分磁盘空间以及海明校验码来恢复用户丢失的数据,这种方式不仅容错率高而且冗余信息较少,总之RAID越大,容错率越高,冗余信息越少。
5.2固态硬盘
固态硬盘所用的存储芯片是flash闪存芯片,芯片为EEPROM电可擦除可编程只读存储器,固态硬盘由闪存翻译层和若干闪存芯片组成,闪存翻译层负责通过重定位寄存器来将逻辑地址翻译为物理地址,而一个闪存芯片包含多个块,而每个块包含多个页框(这里的块和操作系统中学的物理块不是一个概念,操作系统中一个物理块大小为页框大小,要注意二者的区别)。
固态硬盘的芯片既然是EEPROM,那么说明其是可擦除,可重复写入数据的。但是,固态硬盘的读/写操作是以页框为单位,也就是操作系统中的物理块,而擦除是以块为单位,也就是说,当我们需要擦除某一页的时候需要将包含该页的整个块的所有页都擦除,但这显然是不行的,所以擦除前需要将该块中的数据转移到另一个块中,然后再向其页写入数据,然后擦除原来的块即可。由于固态硬盘是电擦除,所以每个块都有一定的擦除寿命,当一个块擦除的次数过多时,该块就会损坏,为了避免这种情况的发生,固态硬盘通常会采用擦除均衡技术,一种是动态均衡,也就是每次擦除和写入都会选择那些比较新的块进行写操作。另一种是静态均衡,硬件通常会选择一些比较老的块来负责只读工作,而用比较新的块进行写操作。
那现在来说说机械硬盘和固态硬盘的异同:二者都是外存。但机械硬盘的读写速度较为缓慢,因为机械硬盘需要完成寻道、旋转延迟时间等机械操作才能读写某个扇区,但固态硬盘是通过电路的方式来读写某个页框,机械硬盘不会因为写入和擦除的次数过多而损坏,但是固态硬盘会。
六、Cache
6.1Cache的基本概念和工作原理
学习Cache的基本概念和工作原理之前,我们先回忆一下操作系统第三章中虚拟存储技术的请求分页存储管理,因为请求分页存储管理和Cache实在是太相像了,只不过请求分页存储管理面向对象为内存和外存之间,而Cache工作原理面向的对象是Cache和内存之间。
请求分页存储管理中,我们学到了为什么我们在运行一个程序的时候,只需要将部分页面调入内存即可,以及在程序运行的过程中,我们需要换入和换出哪些页面,以及置换页面的算法,由于局部性原理,所以我们可以将某些局部的页面全部调入内存,当该程序运行需要其他页面的时候在通过页面置换来调入其他页面,这样在用户看来似乎达到了一种内存很大的状态,而页面置换算法分为最佳置换算法、先进先出置换算法、最近最久未使用置换算法(LRU)、时钟置换算法以及其优化(CLOCK)。
其实Cache的工作原理和请求分页存储管理类似,由于CPU和内存的运行速度不匹配,根据局部性原理,我们可以将一些常用的主存块号,也就是页面调入Cache中,这样就可以缓和CPU和内存运行速度不匹配的问题,而我们在将内存中的页面调入Cache中后,CPU可能会对Cache中的内容进行更改,那么我们就需要找到Cache中该页面原本在内存中的什么位置,好将改好的内容写回,那这就涉及到了Cache和主存的映射关系以及Cache的写策略,而当CPU在Cache中没有找到想要的页面时,此时CPU就会去内存中寻找,那么CPU去内存中寻找页面后,硬件需要将该页面立即写入Cache,但Cache容量其实很小,很容易装满,那么我们应该替换掉Cache中的哪些页面呢?这就涉及到了Cache替换算法。接下来我将讲述这三个问题。
6.2Cache和主存映射关系
Cache和主存之间的信息交换是以行为单位的,内存中的一行等于Cache中的一行,而行的大小是不唯一的,假如一个机器按照字节编址,而一行有64B,那么内存中的一行就可以存放64个地址。当一个内存共有64KB的大小时,而且一行有64B的大小,那么我们就可以将一个内存拆分成1K个行,而行内又可以根据编址大小具体拆分,这样一来就可以用行号+行内地址这种地址结构来表示内存中任意一个地址。
1.全相联映射
全相联映射是指,内存的所有的行可以存放在Cache的任意行里面。但是为了方便寻找到底是内存中的哪一行占用了Cache中的某一行,就需要在Cache的每一行前加一个标记位,标记位记录了内存中的行号,而没有被占用的Cache行标记位为全0,但是内存中的第一行行号也为全0,那么为了区分他们还需要再设置一个有效位,当有效位为1时说明此标记有效,有效位为0时则无效。
全相联映射时,全相联地址结构将被分成标记和块内地址
2.直接映射
直接映射是指对内存的行号进行取模操作,取模大小为Cache的行数。而二进制数取模有一个比十进制更加特殊的地方在于,二进制取模后,剩下的余数一定是二进制的低位,且这个低位不大于模大小。比如说,如果Cache行数为8,那么内存中的0号行和7号行都可以存放在Cache的第0行(这涉及到了Cache替换策略),因为0号的低三位和8号的低三位都为000,所以Cache的标记位在直接映射中可以去掉低三位来减少标记位所占用的Cache存储空间。
直接映射时,主存地址将被分成标记、Cache行号和块内地址,与全相联映射的地址结构相对应,直接相连映射中标记+Cache行号正是全相联映射中的标记。
3.组相连映射
组相联映射类似于直接映射,只不过需要将Cache分组,每组包含若干个行,我们可以将每个分组看成是一个Cache行,然后组相联映射就变成了直接映射,不过与直接映射不同的地方在于,直接映射的0号行和7号行不能同时存放在Cache的第0行中,但是组相联映射可以将0号行和7号行都存放在第0组,前提是一组中至少有两个Cache行,而0号和7号在第一组中的位置是任意的。
组相联映射时,主存地址将被分成标记、组号和块内地址,与全相联映射的地址结构相对应,组相联映射中标记+组号正式全相联映射中的标记。
学完这三种映射,我亲身经历我们很容易搞混全相联映射和直接映射,这里我给大家一个记忆的方法,其实全相联映射就是一种特殊的组相联映射,只不过Cache全部的行为一组而已,这也是“全”字的由来,而直接映射也是一种特殊的组相联映射,只不过每个组只有一个Cache行,我们用这种理解性的记忆,相信大家绝不会再搞混全相联映射和直接映射。
6.3Cache替换算法
前面既然说过了全相联映射、直接映射、组相联映射这三者其实都可以归纳为同一种映射,那么此处的Cache替换算法只以最普通的全相联映射为例,另外两种映射方式的替换算法参考本小节的替换算法即可。
1.随机替换算法(RAND)
随机替换算法就是,当Cache中需要进行替换的时候,随机选取一个被占用的Cache行进行替换操作,显然这种算法随机性很大,并没有遵循局部性原理,故此算法性能较差。
2.先进先出替换算法(FIFO)
与操作系统中请求分页存储管理中的先进先出替换算法类似,此算法会优先替换掉那些先进来的行,但是最先进来的行未必在未来就不会被使用,故此算法也没有遵循局部性原理,而且与操作系统类似,如果Cache的行数可以增加,可能还会引发Belady异常。
3.最近最久未使用替换算法(LRU)
与操作系统中的LRU类似,该算法的原理就是当需要进行Cache替换的时候,硬件会向过去的Cache行检索,当检索到最久没有被使用的Cache行的时候,就对该Cache行进行替换操作。显然该算法很好的遵循了局部性原理,算法性能也是这4个算法中最好的,唯一的缺点就是需要硬件的支持,造价贵。
4.最近不经常使用替换算法(LFU)
该算法的原理是为每一个Cache行增加一个计数器,当某一个Cache行被访问时,将该行所对应的计数器加一,当需要进行Cache替换的时候,选择计数器中数值最小的行进行替换,该算法似乎满足了局部性原理的要求,但是,如果某一个Cache行只是在某一段时间里经常被访问,但是在后面的时间中不会被经常访问,比如视频聊天,那么该Cache行的计数器数值是很大的,当需要进行Cache替换的时候,很难再将视频聊天部分的Cache行替换掉,所以该算法的实际性能并不如最近最久未使用替换算法
6.4Cache写策略
1.写回法:本方法是在写命中的前提下发生的,当CPU访问某个内容命中了Cache,当CPU想要改变内容的时候,直接写在Cache中即可,无需立刻将内容也写回主存,当该内容即将被置换出Cache的时候,在将改变的内容写回内存中的相应位置,为了判断哪些Cache行是被修改过的,Cache行中还应该保留1位脏位,为了判断该Cache行是否被使用,还应该有一位有效位。
2.全写法: 本方法也是在写命中的前提下发生的,与写回法不同的是,当CPU要改变数据的时候,会将数据一同写入Cache和内存里面,但是由于内存的数据传输缓慢,所以需要一个写缓冲区,写缓冲区也是由SRAM芯片构成,将改变的内容先放在写缓冲区中,当CPU进行其他操作的时候,再将缓冲区中的内容写入主存。
3.写分配法:本方法是在写不命中的前提下发生的,当CPU要改变某些数据的时候,数据所在的行不在Cache中,那么此时CPU会将该行调入Cache,然后在Cache中改变数据但是不写回主存,后续操作与写回法相同,所以该方法通常与写回法配合使用。
4.非写分配法:本方法是在写不命中的前提下发生的,与写分配法不同的是,非写分配法不需要将要修改的数据所在行调入Cache,而是直接在内存中修改,该方法通常与全写法配合使用。
Cache的写策略全部讲完了,但是还存在着一些问题,比如非写分配法明明CPU已经访问了内存并修改数据,但是为什么不将内存中的数据写入Cache中?
这些问题只要明白了一点,就都容易理解了,那就是写回法和写分配法通常运用在内存和Cache之间,全写法和非写分配法通常运用在各级Cache之间。写回法和写分配法,不先将要修改的数据写入内存是因为内存数据传输缓慢;而非写分配法中,如果我们将内存看成二级Cache,而Cache看成一级Cache,那么我们也就无需将二级Cache中的内容再写入一级Cache,因为被修改的数据不一定是重要的,而该数据已经在Cache中,也就没有什么访问了内存而不写入Cache一说
七、页式存储器、虚拟存储器
本节的内容在操作系统的第三章中已经学过了一遍,并且讲的十分详细,这里简要复习一下即可。
7.1页式存储器
首先是页式存储器,页式存储器的实现方式为将内存分成很多个页框,而一个页框通常为4KB,那么当有某个很大的程序需要调入内存的时候,就不需要再给该程序分配连续的内存空间,而是通过逻辑地址结构来讲该程序分成很多个页面,分别存放在内存中的各个位置。将程序分配完之后存在一个问题,那就是我们需要一种能够显示该程序的每个页面分别存放在了内存的哪些页框中的数据结构,而该数据结构就是页表,而一个页表是由多个页表项组成,一个页表项可以表示一个页面所在的页框号,页表项是由页号和页框号组成的,而逻辑地址结构是由页号和页内偏移量组成,页表中的页号是隐含的,就像数组中的下标一样。那么通过页号对应的页框号以及页内偏移量,我们就能找到任意一个位置。
注意,页表也是需要存放在内存中的,而如果一个程序很大的话,相应的页表也会很大,那么就会出现和程序一样的问题,无法分配连续的内存空间来存放页表,此时就出现了二级页表,多级页表,二级页表的原理就是将页表也看成是一个程序,将页表分成多个页框大小的页面分散存放在内存中的各个位置,此时一级页表就起到了页表的功能。
7.2虚拟存储器
其次是虚拟存储器,一个程序可能比内存大得多,而CPU运行程序需要在内存中运行,举个例子,荒野大镖客2共有100GB,而我们的内存可能只有16GB,此时程序大小远远大于内存大小。但是并不是在同一时刻,程序的所有页面都是需要被CPU调用的,我们只需要将部分需要用到以及可能会用到的页面调入内存就可以运行该程序,而该技术就是虚拟技术。
虚拟存储器涉及到了请求分页存储管理,而请求分页存储管理就是页式存储管理的底层原理,页式存储管理主要研究的是如何找到这些分配到内存中的页面,而请求分页存储管理主要研究的是如何去管理这些分配到内存中的页面,比如说什么时候将页面换出等操作。
请求分页存储管理与Cache替换算法类似,存在不同的地方就是请求分页存储管理多了最佳置换算法(OPT)以及时钟置换算法(CLOCK),最佳置换算法是需要操作系统对未来即将哪些页面会被使用进行预判,显然是不可能做到的,而时钟置换算法则是通过两个标记位,将可以被分配的物理块首尾相连形成一个环形,通过标记位的变化来判断此时应该置换哪个页面,时钟置换算法与时钟管理没有半毛钱关系。















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









