







文章目录
0. 前言
完整项目的代码我已上传到 github:https://github.com/friedrichor/Language-Model-Next-Word-Prediction
本文主要讲解实现代码(可以搭配着 github 中的完整项目一起看),如何使用多种语言模型来实现 下一单词预测(next-word prediction)。
语言模型
语言模型主要就是将 单词 → \to →数字。语言模型可以分为离散型表示 和 分布式表示。
- 离散表示有 one-hot 编码、BOW(Bag of Words,词袋模型)、N-gram;
- 分布式表示就是将单词转换为向量的形式,这样每个单词间就会有一定的关联,比如说 沈阳 和 盛京,这两个词都表示的是同一地点,如果用离散型表示会将它们两个词判定为两个完全不同的词,而转换为向量就会将他们判定为意思相近的词,在向量空间中他们也会距离的比较近。主要有 神经网络语言模型(如NNLM、RNNLM)、Word2Vec、GloVe、Elmo、BERT等等。
next-word prediction
最好的例子就是 智能手机键盘的下一个单词预测功能,这是一个数十亿人每天使用数百次的功能。下一个单词的预测是一项可以通过语言模型来完成的任务。语言模型可以获取一个单词列表(假设是两个单词),并尝试预测紧随其后的单词。比如说我输入了 I like,那么手机键盘就会有提示 cat, dog 等等来预测我接下将要打的单词。
1. 数据集
本文使用的是 PTB 数据集,PTB数据集是一个英语语料库,并被许多研究者用于语言建模实验。
github 中提供了两种数据集,下图左边的是完整的 PTB 数据集(penn文件夹),右边的是小型的 PTB 数据集(data文件夹)。训练完整的数据集需要足够大的GPU显存,自己电脑GPU显存充足或者服务器GPU够大就能跑;为了防止显存不足,这里也提供了一个小型的数据集,这个一般自己电脑就能够跑了,不过这个小型的数据集由于数据量较小,比较容易过拟合。
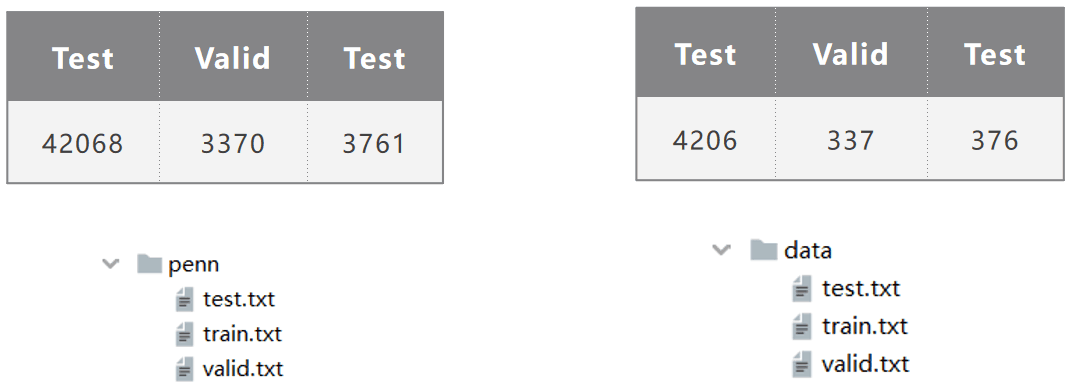
penn/train.txt 部分数据如下所示:

2. 生成单词表
由于数据集为文本,我们知道只有数字的形式才能使用深度学习来进行训练模型,所以首先就要把文本转化为数字。
根据训练集来生成单词表,即 单词 → \to →索引 和 索引 → \to →单词 的字典。
除了单词外,NLP中还有四种常用的标识符,即 <PAD>,<UNK>,<SOS>,<EOS>:
<PAD>: 补全字符<UNK>: 低频词或未在词表中的词<SOS>: 句子起始标识符<EOS>: 句子结束标识符
# 在 utils.py
def generate_vocab(data_path):
word_list = []
f = open(data_path, 'r')
lines = f.readlines()
for sentence in lines:
word_list += sentence.split()
word_list = list(set(word_list))
# 生成字典
word2index_dict = {w: i + 2 for i, w in enumerate(word_list)}
word2index_dict['<PAD>'] = 0
word2index_dict['<UNK>'] = 1
word2index_dict = dict(sorted(word2index_dict.items(), key=lambda x: x[1])) # 排序
index2word_dict = {index: word for word, index in word2index_dict.items()}
# 将单词表写入json
json_str = json.dumps(word2index_dict, indent=4)
with open(vocab_path, 'w') as json_file:
json_file.write(json_str)
return word2index_dict, index2word_dict
说明:
- 这里并没有加标识符
<SOS>,<EOS>,需要的话自己加上就可,同时word2index_dict = {w: i + 2 for i, w in enumerate(word_list)}要改成word2index_dict = {w: i + 4 for i, w in enumerate(word_list)} - 两个返回值
word2index_dict用于编码(单词 → \to →索引),index2word_dict用于解码(索引 → \to →单词) - 这里将单词表写入 json 文件,保证每次训练和测试时的单词表都是相同的,保证每个单词对应的索引要一致(如果更换数据集记得把先前生成的 vocab.json 删了,单词表和数据集要对应)。
在 train.py 中如下调用:
# 生成单词表
if not os.path.exists(vocab_path):
word2index_dict, index2word_dict = generate_vocab(train_path)
else:
with open(vocab_path, "r") as f:
word2index_dict = json.load(f)
index2word_dict = {index: word for word, index in word2index_dict.items()}
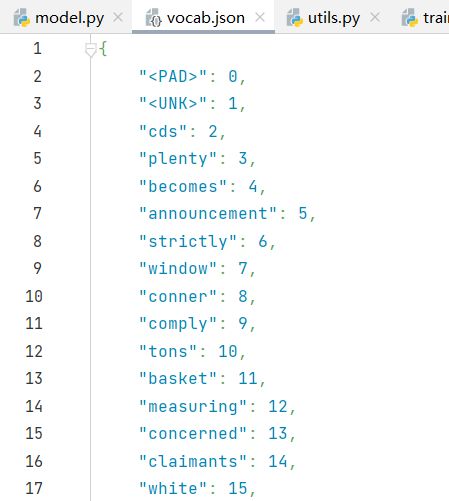
vocab.json:
3. 实例化 Dataset 和 DataLoader
定义Dataset类:
# 在 my_dataset.py
from torch.utils.data import Dataset
class MyDataSet(Dataset):
def __init__(self, inputs, targets):
self.inputs = inputs
self.targets = targets
def __getitem__(self, item):
input = self.inputs[item]
target = self.targets[item]
return input, target
def __len__(self):
return len(self.inputs)
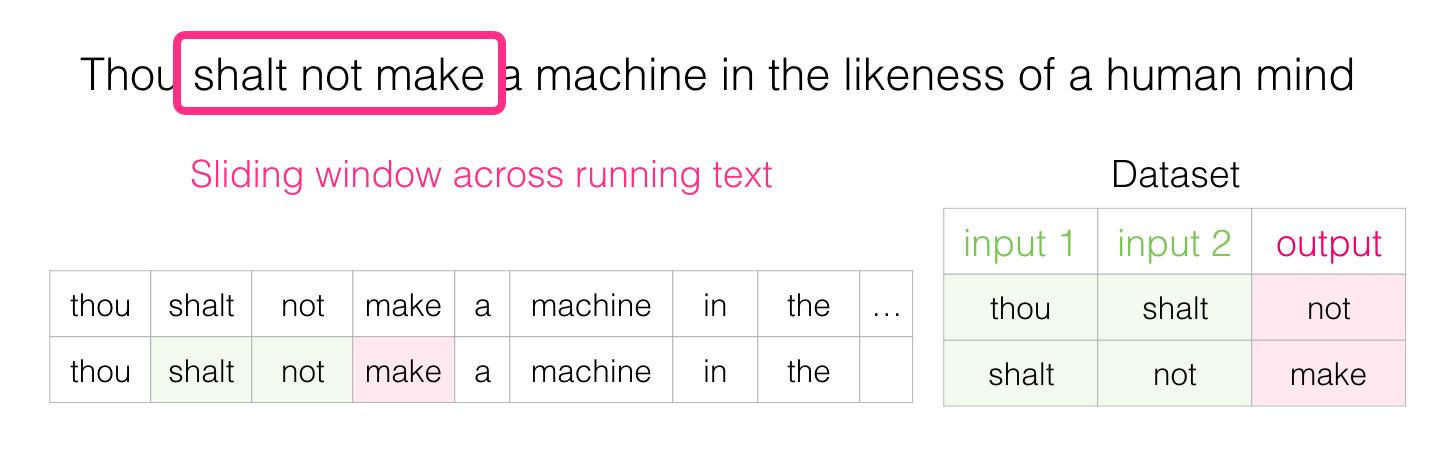
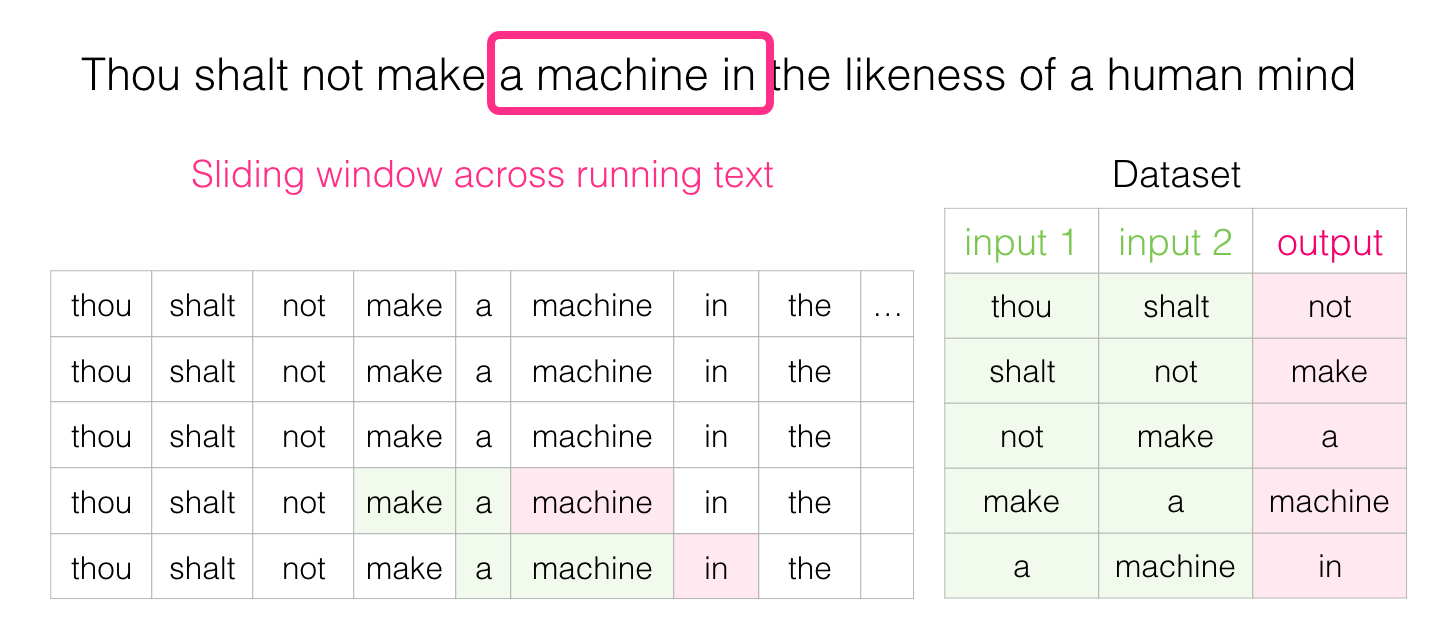
遍历数据集,首先 padding(如果句子长度不够的话),然后将句子中的每个单词进行编码(单词 → \to →索引),根据滑动窗口构造input、target列表,然后传入 MyDataset 类中实例化就完成了对数据集的实例化。
对于滑动窗口构造input、target列表,可以通过以下例子理解:

关于标识符<PAD>,<UNK>,<SOS>,<EOS>,举个例子,有句子 I like cats,我想要根据 I like 来预测下个单词可能是什么,假如我训练的语言模型是需要 根据前四个词才能预测下一个词 且 单词like未在训练集中出现或出现频率低(即不在单词表中),那么这个句子已知的单词明显不足,首先需要补全字符,即 <PAD> <PAD> I <UNK>,然后把这个句子放入模型进行预测即可。(这里代码中并没加<SOS>和<EOS>,这个可以自行加上,在句首和句尾补充标识符即可,即 <SOS> I like cats <EOS> )
# 在 utils.py
def generate_dataset(data_path, word2index_dict, n_step=5):
"""
:param data_path: 数据集路径
:param word2index_dict: word2index字典
:param n_step: 窗口大小
:return: 实例化后的数据集
"""
def word2index(word):
try:
return word2index_dict[word]
except:
return 1 # <UNK>
input_list = []
target_list = []
f = open(data_path, 'r')
lines = f.readlines()
for sentence in lines:
word_list = sentence.split()
if len(word_list) < n_step + 1: # 句子中单词不足,padding
word_list = ['<PAD>'] * (n_step + 1 - len(word_list)) + word_list
index_list = [word2index(word) for word in word_list]
for i in range(len(word_list) - n_step):
input = index_list[i: i + n_step]
target = index_list[i + n_step]
input_list.append(torch.tensor(input))
target_list.append(torch.tensor(target))
# 实例化数据集
dataset = MyDataSet(input_list, target_list)
return dataset
在 train.py 中如下调用:
# 实例化数据集
train_dataset = generate_dataset(train_path, word2index_dict, n_step)
vaild_dataset = generate_dataset(valid_path, word2index_dict, n_step)
实例化 DataLoader:
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw)
valid_loader = DataLoader(vaild_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw)
其中 nw 为线程数,我在 params.py 中有定义:
# 在 params.py
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
4. 模型
在 model.py 中提供了 NNLM、RNNLM 及 引入注意力机制的RNNLM
4.1 NNLM
论文:A Neural Probabilistic Language Model
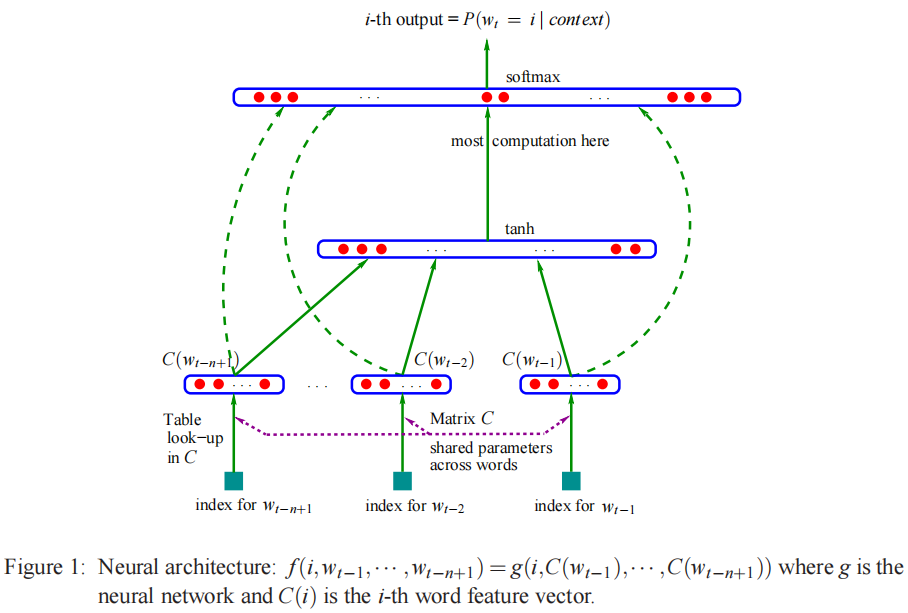
class NNLM(nn.Module):
def __init__(self, n_class):
super(NNLM, self).__init__()
self.n_step = n_step
self.emb_size = emb_size
self.C = nn.Embedding(n_class, emb_size)
self.w1 = nn.Linear(n_step * emb_size, n_hidden, bias=False)
self.b1 = nn.Parameter(torch.ones(n_hidden))
self.w2 = nn.Linear(n_hidden, n_class, bias=False)
self.w3 = nn.Linear(n_step * emb_size, n_class, bias=False)
def forward(self, X):
X = self.C(X)
X = X.view(-1, self.n_step * self.emb_size)
Y1 = torch.tanh(self.b1 + self.w1(X))
b2 = self.w3(X)
Y2 = b2 + self.w2(Y1) # 为什么不用加softmax?因为pytorch实现的交叉熵里面用了softmax
return Y2
4.2 RNNLM
论文:Recurrent neural network based language model
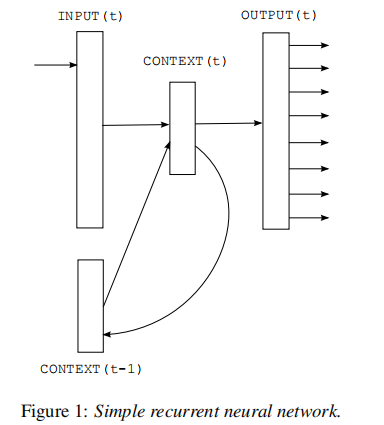
class TextRNN(nn.Module):
def __init__(self, n_class):
super(TextRNN, self).__init__()
self.C = nn.Embedding(n_class, embedding_dim=emb_size)
self.rnn = nn.RNN(input_size=emb_size, hidden_size=n_hidden)
self.W = nn.Linear(n_hidden, n_class, bias=False)
self.b = nn.Parameter(torch.ones([n_class]))
def forward(self, X):
X = self.C(X)
X = X.transpose(0, 1) # X : [n_step, batch_size, embeding size]
outputs, hidden = self.rnn(X)
# outputs : [n_step, batch_size, num_directions(=1) * n_hidden]
# hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
outputs = outputs[-1] # [batch_size, num_directions(=1) * n_hidden]
model = self.W(outputs) + self.b # model : [batch_size, n_class]
return model
引入注意力机制(仅供参考)(这部分与github有所差别,在于返回值,可以直接将下面这部分代码替换github中的代码,然后utils.py中的训练和验证代码均不需要动,注释可以删了,那部分注释是之前为了打印Attention矩阵才用的):
class TextRNN_attention(nn.Module):
def __init__(self, n_class):
super(TextRNN_attention, self).__init__()
self.C = nn.Embedding(n_class, embedding_dim=emb_size)
self.rnn = nn.RNN(input_size=emb_size, hidden_size=n_hidden)
self.W = nn.Linear(2 * n_hidden, n_class, bias=False)
self.b = nn.Parameter(torch.ones([n_class]))
def forward(self, X):
X = self.C(X)
X = X.transpose(0, 1) # X : [n_step, batch_size, embeding size]
outputs, hidden = self.rnn(X)
# outputs : [n_step, batch_size, num_directions(=1) * n_hidden]
# hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
output = outputs[-1]
attention = []
for it in outputs[:-1]:
attention.append(torch.mul(it, output).sum(dim=1).tolist())
attention = torch.tensor(attention)
attention = attention.transpose(0, 1)
attention = nn.functional.softmax(attention, dim=1).transpose(0, 1)
# get soft attention
attention_output = torch.zeros(outputs.size()[1], n_hidden)
for i in range(outputs.size()[0] - 1):
attention_output += torch.mul(attention[i], outputs[i].transpose(0, 1)).transpose(0, 1)
output = torch.cat((attention_output, output), 1)
# joint ouput output:[batch_size, 2*n_hidden]
model = torch.mm(output, self.W.weight) + self.b # model : [batch_size, n_class]
return model
4.3 其他模型(见github)
可以参考 https://github.com/graykode/nlp-tutorial,里面包含多个语言模型。
直接在model.py 中添加即可,然后在 train.py 中更改 model = TextRNN(n_class).to(device)为自己的模型即可。
5. 损失函数、优化器、调度器
这部分可以自行更改,以下只是给了几个例子。
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), epochs,
# warmup=True, warmup_epochs=5)
lr_scheduler = None
# lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 50, gamma=0.1, last_epoch=-1)
# lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20)
说明:
- 这里我定义
lr_scheduler = None为不使用调度器(因为训练函数中需要传参进去,这里就需要实例化),即学习率一直不变 create_lr_scheduler函数为Poly学习率调整策略,具体原理可以参考:网络训练时使用不同学习率策略(Poly)以及学习率是如何计算,实现如下:
# 在 utils.py
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3,
end_factor=1e-6):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
current_step = (x - warmup_epochs * num_step)
cosine_steps = (epochs - warmup_epochs) * num_step
# warmup后lr倍率因子从1 -> end_factor
return ((1 + math.cos(current_step * math.pi / cosine_steps)) / 2) * (1 - end_factor) + end_factor
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
按我代码中定义,得到的学习率变化图如下(训练 200 epoch,预热 5 epoch,优化器中定义的初始学习率为 1e-3):
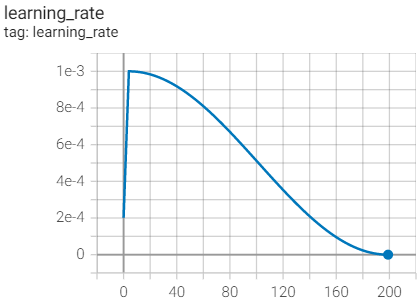
6. 训练
以下为训练一轮的代码:
# 在 utils.py
def train_one_epoch(model, loss_function, optimizer, data_loader, device, epoch, lr_scheduler):
model.train()
accu_loss = torch.zeros(1).to(device) # 累计损失
optimizer.zero_grad()
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
input, target = data
pred = model(input.to(device))
loss = loss_function(pred, target.to(device))
loss.backward()
accu_loss += loss.detach()
data_loader.desc = "[train epoch {}] loss: {:.3f}, ppl: {:.3f}, lr: {:.5f}".format(
epoch,
accu_loss.item() / (step + 1),
math.exp(accu_loss.item() / (step + 1)),
optimizer.param_groups[0]["lr"]
)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
# gradient clip
# clip_grad_norm_(parameters=model.parameters(), max_norm=0.1, norm_type=2)
optimizer.step()
optimizer.zero_grad()
# update lr
if lr_scheduler != None:
lr_scheduler.step()
return accu_loss.item() / (step + 1), math.exp(accu_loss.item() / (step + 1))
说明:
- 参数:
model:模型;
loss_function:损失函数;
optimizer:优化器;
data_loader:上一步实例化后的 DataLoader;
device:训练使用的设备,gpu / cpu;
epoch:当前训练是第几轮,这个主要是用来实时显示当前训练到第几轮的;
lr_scheduler:学习率调度器; - data_loader.desc 用于实时打印训练过程,其中 ppl 直接用 e C r o s s E n t r o p y L o s s e^{CrossEntropyLoss} eCrossEntropyLoss 表示了,计算方法可能有所差别。
clip_grad_norm_(parameters=model.parameters(), max_norm=0.1, norm_type=2)被注释掉了,这里表示是否使用梯度裁剪,如果需要的话可以自行启用,不过这里的参数我并没有进行调参,用或不用差别不大,可以自行探索。- 如果传入的参数
lr_scheduler为None,那么就不使用调度器,即学习率一直保持不变。 - 这里调度器是一个 step 更新一次学习率,用的是 Poly策略,如果改成StepLR、CosineAnnealingLR(余弦退火)等等的话一般是一个epoch更新一次学习率,这里就需要注意一下更改
lr_scheduler.step()的位置。 - 在 github 中的代码这部分还有更多的注释,那些注释其实是在 使用注意力机制的RNNLM 中我为了打印其中的 注意力Attention矩阵 才用的,正常使用NNLM、RNNLM等模型其实上面这部分代码就够了。
7. 验证
上面是对训练集进行模型训练的,这部分是验证当前模型效果的,大部分与训练时代码相似,这里不做过多说明。
def evaluate(model, loss_function, data_loader, device, epoch):
model.eval()
accu_loss = torch.zeros(1).to(device) # 累计损失
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
input, target = data
pred = model(input.to(device))
loss = loss_function(pred, target.to(device))
accu_loss += loss
data_loader.desc = "[valid epoch {}] loss: {:.3f}, ppl: {:.3f}".format(
epoch,
accu_loss.item() / (step + 1),
math.exp(accu_loss.item() / (step + 1)),
)
return accu_loss.item() / (step + 1), math.exp(accu_loss.item() / (step + 1))
8. 完整训练+验证过程
tb_writer = SummaryWriter()
for epoch in range(epochs):
# train
train_loss, train_ppl = train_one_epoch(model=model,
loss_function=loss_function,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch,
lr_scheduler=lr_scheduler)
# validate
valid_loss, valid_ppl = evaluate(model=model,
loss_function=loss_function,
data_loader=valid_loader,
device=device,
epoch=epoch)
tags = ["train_loss", "train_ppl", "valid_loss", "valid_ppl", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_ppl, epoch)
tb_writer.add_scalar(tags[2], valid_loss, epoch)
tb_writer.add_scalar(tags[3], valid_ppl, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
if (epoch + 1) % save_epoch == 0:
torch.save(model, os.path.join(models_path, f'weights-{epoch + 1}.ckpt'))
说明:
- 这里使用了
tensorboard中的SummaryWriter记录训练日志,存储每一轮训练时训练集、验证集的损失、ppl及学习率, 如下图就是我做对比实验时使用SummaryWriter保存的日志生成的图像,还是很好用的,不过不需要的话可以忽略。
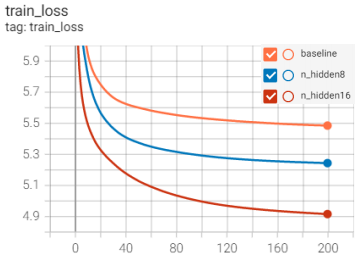
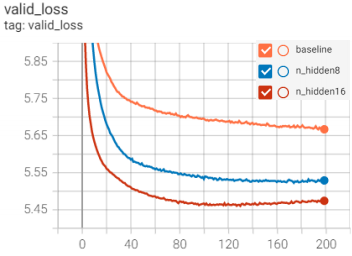
- 代码最后一部分设定了每训练多少轮就保存一次模型,这一部分也可以自行更改。
9. 测试
在 test.py,整个过程与验证相似,代码中仅仅输出了 loss。这部分可以根据 index2word_dict 解码回单词,实现真正的 next-word prediction 的功能。
10. 其他说明
项目中一些通用的全局参数在 params.py,包括 模型相关参数 n_step(滑动窗口大小)、n_hidden、emb_size,训练相关参数 epochs、batch_size、lr、device、nw,以及 训练集、验证集、测试集路径 等等。
如果想要进一步了解 Word2vec ,也可以查看我的一篇博文:一文带你通俗易懂地了解word2vec原理,是根据The Illustrated Word2vec翻译的(看原文更好一些,当时写的理解并不是很好),里面的讲解通俗易懂,整篇文章看完基本就明白了,还是很有帮助的。



















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











