







剪枝分类树 Pruned classification tree
一棵有着更少的分支的小树,方差一般比较小,也很方便人们解释,但是以偏差为代价的。另一个方法是设定RSS的阈值,当树的分枝超过这个阈值之后,就停止继续往下生长(分支)。这个方法存在问题,某些看似不值得继续分割的点,实际上继续往下分,RSS会更小。所以,我们可以考虑先初始化一棵大树T0,然后一点一点地剪枝,剪到我们需要的那一棵小树(subtree)。对于分类树来说,RSS就是分错的比例(classification error rate)。实际使用中,会用吉尼Gini系数或entropy来评判。
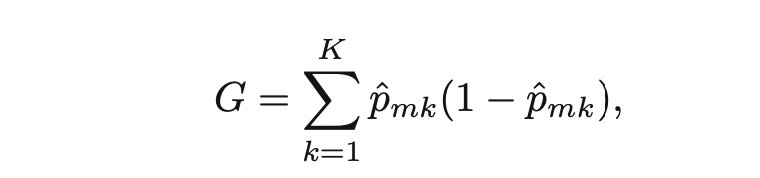
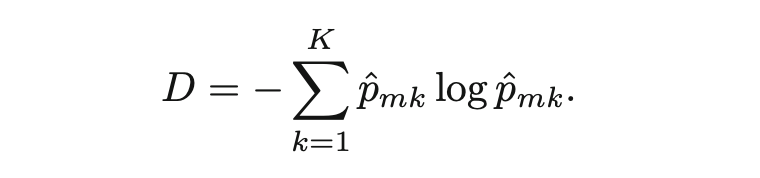
但如果我们的目标是算正确率accuracy的话,还是直接用classification error rate比较好。
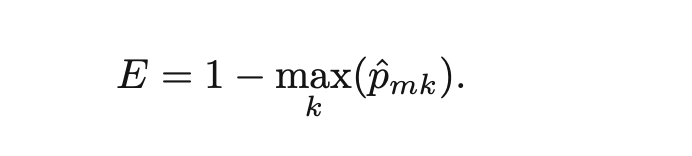
这里的![]() 代表来自于k类的m训练样本区域的观测值的个数的比例。
代表来自于k类的m训练样本区域的观测值的个数的比例。
bagging
树模型通常都有很大方差(high variance),所以需要想办法减少方差。根据统计知识,我们知道,假设有Z1,Z2,...,Zn个独立的变量,每个的方差都是,均值的方差就是
/n。换句话说,我们就可以集成一系列的观测值来减少方差。这样做的不好之处就是失去树形模型的可解释性。
random forests
boosting
另一提升统计学习模型方法是boosting。bagging是利用bootstrap sampling技术复制并创建很多训练集的数据。然后用这些数据去训练模型,训练出来的树模型都是独立的,为了获得最后的单一的模型,所以这些模型都要进行合并(取均值average)。boosting的方法也是类似的,只不过这些树之间不是独立的。它们是按次序生长的(trees are grown sequentially):后面的输的生成都利用到了前面的树的信息。
参考资料:
An Introduction to Statistical Learning with Applications in R——Chap8















 2067
2067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









