








 超级会员免费看
超级会员免费看

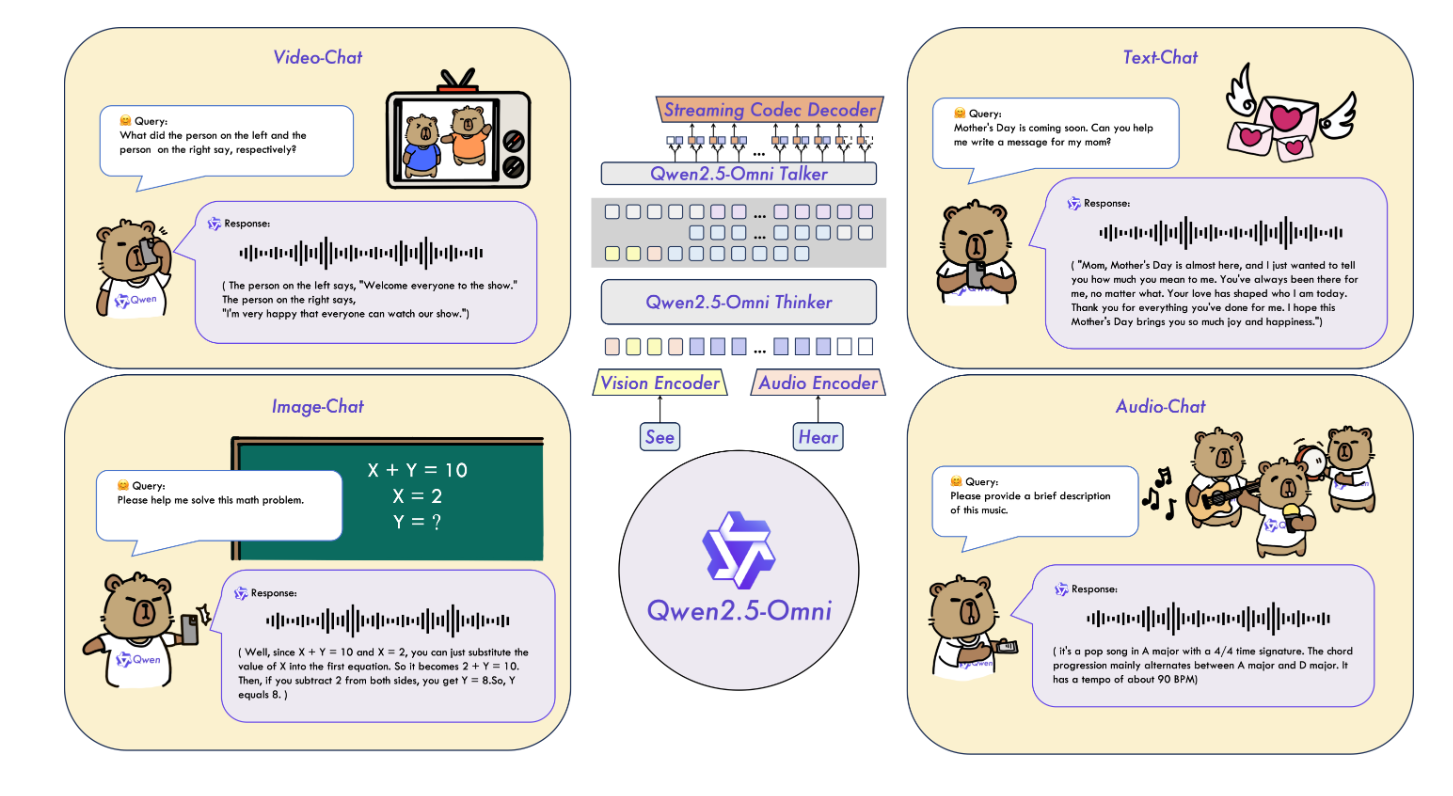
引言:全模态交互的时代已来
2025年3月27日,阿里通义千问团队开源了其最新旗舰级多模态大模型Qwen2.5-Omni-7B。这一模型不仅支持文本、图像、音频和视频的全模态输入与输出,更通过创新的架构设计实现了“看、听、说、写”的无缝融合,标志着多模态大模型技术迈入实时交互的新纪元110。用户可通过官方Demo体验如同“视频通话”般的自然交互,感受人工智能的边界被进一步打破。
核心突破:Thinker-Talker架构与全模态能力
1. 端到端的多模态统一架构
Qwen2.5-Omni采用Thinker-Talker双核架构,实现了感知与生成的深度融合:
-
Thinker模块:作为“大脑”,基于Transformer解码器整合文本、音频、图像和视频编码器,提取跨模态语义表征并生成中间文本。
-
Talker模块:作为“发声器官”,以双轨自回归解码器实时接

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











