







IO方面:
一个典型的算法题,一般会有一个输入输出模板,例如以下这道题:
- 输入:
输入第一行包含一个正整数 T,表示需要检验的用户名数量。
接下来有 T 行,每行一个字符串 s,表示输入的用户名。- 输出:
对于每一个输入的用户名 s,请输出一行,表示符不符合用户名的规定格式。
我之前用的代码:
import java.util.Scanner;
public class Solution {
public static boolean fit(String name) {
//验证用户名格式
}
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
int nameCount = scanner.nextInt();
int booleans = new boolean[nameCount];
for (int i = 0; i < nameCount; i++) {
String name = scanner.next();
booleans[i] = fit(name);
}
for (int i = 0; i < nameCount; i++) {
System.out.println(booleans[i] ? "Accept" : "Wrong");
}
}
}
| 数值 | 打败用户 | |
|---|---|---|
| 用时 | 132 ms | 18.23% |
| 内存 | 29.8 MB | 35.94% |
后来当我改为以下代码:
import java.io.*;
public class Solution {
public static boolean fit(String name) {
//验证用户名格式
}
public static void main(String[] args) throws IOException {
boolean[] booleans = null;
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));
int nameCount = Integer.parseInt(reader.readLine());
booleans = new boolean[nameCount];
for (int i = 0; i < nameCount; i++) {
booleans[i] = fit(reader.readLine());
}
reader.close();
for (int i = 0; i < nameCount; i++) {
writer.write(booleans[i] ? "Accept" : "Wrong");
}
writer.flush();
writer.close();
}
}
| 数值 | 打败用户 | |
|---|---|---|
| 用时 | 76 ms | 93.23% |
| 内存 | 26.5 MB | 95.83% |
自底而上(合并的思想)
很多时候,我们遇到过一些问题,是将整体进行拆分,最后拼起来。常见的问题有:斐波那契数列等。
这些题的求解往往不能从拆分 的角度入手,而是要以合并的思想。
例如这道题:(来自美团笔试题)
小美是美团仓库的管理员,她会根据单据的要求按顺序取出仓库中的货物,每取出一件货物后会把剩余货物重新堆放,使得自己方便查找。已知货物入库的时候是按顺序堆放在一起的。如果小美取出其中一件货物,则会把货物所在的一堆物品以取出的货物为界分成两堆,这样可以保证货物局部的顺序不变。
已知货物最初是按 1~n 的顺序堆放的,每件货物的重量为 w[i] ,小美会根据单据依次不放回的取出货物。请问根据上述操作,小美每取出一件货物之后,重量和最大的一堆货物重量是多少?
如果这道题从拆分的角度看,要知道每一次取出一个元素后,会被分成哪些堆?它们各自的和是什么?它们中和最大是哪个堆?并不容易(因为找不到一种数据结构可以去实现这种数组的拆分,链表或许可以,但是每一次都需要去遍历链表找元素。单纯用数组来存放某下标位置其左侧所有元素之和似乎可以,但终究还是不够优雅,代码复杂且在计算和这件事上也要耗费很多时间)。
但是从合并的角度看,我们将“从满拿出元素到空”的思路转换成“从空放回元素到满”,这时就只需要每一次放回后合并就行了,用的数据结构是并查集
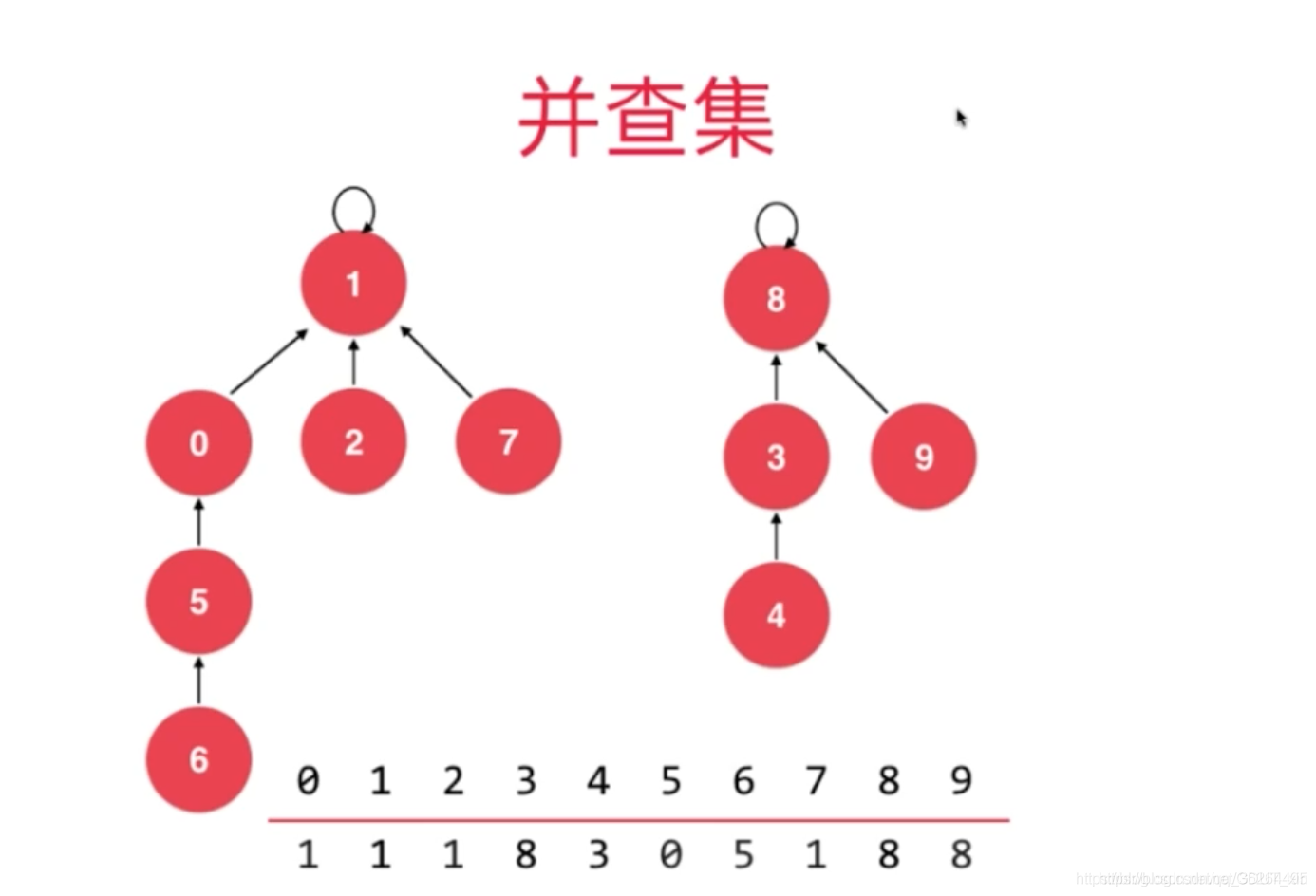
并查集的思想:一个数组存放数据,另一个数组存放0~n下标的元素的父亲的下标。这样从第二个数组向上找总会找到一个“代表”。并查集的操作一般有:判断是不在一个集合中、合并集合、查找代表元素(一般是路径压缩)。
既然找到了相应的数据结构,那么这道题也就很容易解决了,只要每次插入数据时将连在一起的部分合并成一个集合,然后重新计算该集合的和(存放到额外的数组的“代表元素”所在的地方,这样每一次的集合合并,例如将A集合并入B集合,只需要计算sum[Bi]=sum[Bi]+sum[Ai]就行了)。
使用排序库函数
我们一般习惯在传统的数组中用循环迭代来排序,找出最大值。这样的做法,确实会省下很多内存,也可以解决绝大多数问题。但是一旦这种排序、寻找最大值的次数多了呢?代码就不优雅了!例如以下这题:(美团笔试题简化)
一个数组中,找出最大的n个数的下标,它们按照序号从小到大排列(同一个数可能因为比较后出现就打印不出来)
这道题的特点就是,它需要很多次的排序(我已经想象出等下代码有多混乱了)
但是这时候,如果我们利用好库函数,排序也就是一行代码的事了。
public static void maxN(int[] nums,int n) throws IOException {
// 用优先队列定义最大堆,当值相等时下标小的“大”,实现第一次大小排序
Queue<int[]> heap = new PriorityQueue<>((o1, o2) -> {
if (o1[0] == o2[0]) return Integer.compare(o2[1], o1[1]);
return Integer.compare(o1[0], o2[0]);
});
// 用数组链表来实现第二次排序:纯下标排序
List<int[]> res = new ArrayList<>();
for (int i = 0; i < nums.length; i++) {
heap.offer(new int[]{nums[i], i});
if (heap.size() > n) heap.poll();
}
while (!heap.isEmpty()) res.add(heap.poll());
res.sort(Comparator.comparingInt(o -> o[1]));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));
for (var x : res) writer.write(x[1] + " ");
writer.flush();
writer.close();
}
| 输入 | 输出 |
|---|---|
| {44,33,22,34,55,11,44,34}.3 | 0 4 6 |
| {44,33,22,34,55,11,34},3 | 0 3 4 |
数组引用作为参数
数组引用作为参数,其实是传入数组的引用,这个引用(实参)传到方法中虽然变为了局部的变量(形参),但是它的值却也能够找到该数组,也就是说此情况下,用该形参操作数组,其实就是操作“原先的数组”。
审题+调试
有时候你的代码在你的理解范围内其实是对的,但是题目里的一些信息往往忽略后,就会使代码一直报错,这时候多改几个地方,然后看看错误信息的变化。
例如这道题:(来自美团笔试题)
粘贴操作:1 k x y,表示把 A 序列中从下标 x 位置开始的连续 k 个元素粘贴到 B 序列中从下标 y 开始的连续 k 个位置上。原始序列中的元素被覆盖。(数据保证不会出现粘贴后 k 个元素超出 B 序列原有长度的情况)
你觉得最后一句是什么意思?(我觉得这道题让我怀疑了我的语文水平)
String不转char[]
经过测试后证明,用String的charAt(int index)的效率比转为char[]后用数组下标取要快
在获得最终想要的结果的时候,一般会用到以下的方法:(附jdk15源码)
public String substring(int beginIndex, int endIndex) {
int length = length();
checkBoundsBeginEnd(beginIndex, endIndex, length);
if (beginIndex == 0 && endIndex == length) {
return this;
}
int subLen = endIndex - beginIndex;
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
子字符串的长度subLen为endIndex-beginIndex,然后在newString方法中从beginIndex出发截取subLen长度,那么可知,endIndex位置是取不到的。
HashMap取代重复查找
为了得到某种值,每一轮都去循环查找,但是优化算法的时候就会发现,这些查找花费了太多时间,而且结果跟在哪一次中查找没有关系。这时何不先存起来,要得到这个值的时候去取出来即可。
例题:
根据一棵树的前序遍历与中序遍历构造二叉树。(leetcode 105)
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
得到:[3,9,20,null,null,15,7](层次遍历)
这道题不难,用子问题的解决方法就可以了。
但是很多人都会在每一轮的寻找中序遍历中的中间结点的时候去遍历inorder数组,想要在其中去找到preorder的第一个元素(父节点),以确定左右子树在中序遍历中的分界点(例如第一轮的时候是在inorder中查找3的下标是1)。代码就会像以下这样:
for (int i = iStart; i <= iEnd; i++) {
if (inorder[i] == preorder[pStart]) {
return new TreeNode(preorder[pStart],
buildSubTree(preorder, pStart + 1, pStart + i - iStart, inorder, iStart, i - 1),
buildSubTree(preorder, pStart + i - iStart + 1, pEnd, inorder, i + 1, iEnd));
}
}
但是每一轮查找的结果都是一样的,因为inorder数组本身并没有改变。
用HashMap存每一个元素对应的下标。
for (int start = 0; start < inorder.length; start++) {
map.put(inorder[start], start);
}
后续的上述代码会优化为:
i = map.get(preorder[pStart]);
return new TreeNode(preorder[pStart],
buildSubTree(preorder, pStart + 1, pStart + i - iStart, inorder, iStart, i - 1),
buildSubTree(preorder, pStart + i - iStart + 1, pEnd, inorder, i + 1, iEnd));
转移问题矛盾+map代替循环
例题:两数之和(LeetCode 1)
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
- 看到这道题,很容易就想出暴力解法。
- 如果将数组改为排序数组是不是就会简单很多呢?其实并不是很好,因为最终还是要找到原来数组的下标,我们重排序之后总是会将下标打乱。用map来存值和下标的关系,也会遇到重复元素的问题。
最终的解法,是结合1和2,在暴力解法中,第一层循环不变,第二层循环改为在map中尝试取出 target-nums[i](有点转移问题矛盾的意思)。
这里map虽然不能存重复的元素,但是如果a+a!=target,我们只要其中一个就行,而如果a+a==target,那在存入之前将与之前的a配对。
public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (map.containsKey(target - nums[i])) {
return new int[]{i, map.get(target - nums[i])};
}
map.put(nums[i], i);
}
return null;
}
不新创建NodeList引用
新创建的引用和函数形参中的引用,其实指向的是同一个链表,所以新创建一个引用也只能是浪费内存而已。(除非之后还要用到原来引用的位置)
Set->判断存在,Map->判断存在+储存信息
如果要判断一个值或对象是否已经出现过,那么用set.add、set.contains、set.remove基本可以满足需求。
如果要判断一个值或对象是否已经存在过,还要知道这个已存在的值或对象的具体附加信息,例如出现在数组中的下标位置。
例题:无重复字符的最长子串(LeetCode 3)
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
- 我们可以很快的想出具有两层循环的暴力解法:求出i位置开始的最大不重复串。
但是真的必要吗?因为每一次大循环,小循环都会重复之前已经确定的结果,因为没有一个数据结构去辅助。 - 这时候我们选择HashSet进行辅助,可以立即得到是否出现过。每次大循环左指针+1,左指针之前的字符会被remove。在小循环中可以从上次的位置继续(因为前面都已经判断过不重复了)。这种解法就是滑动窗口解法。这种解法的好处是右指针不用频繁的活动,缺点是右指针很多时候都会走一步就发现重复(因为与之重复的大概率不是左指针位置的数据,左指针右移之后依然没有去掉将会重复的那个值)。
- 还有一种方法,就是每一次遇到重复值之后都要清空set,然后将左指针移动到之前重复值在的地方,如果没有位置信息的存储,那么就要从左指针位置开始循环查找到那个位置,特别麻烦。我们有一个数据结构,既能判断重复,又能储存相应附加信息(数组位置),那就是HashMap。这种方法的好处是左指针跳的快,缺点是右指针总是从左指针开始循环,还要频繁清空HashMap。
冗杂的break
看一下这段代码
int a = 0;
while(a < 100){
if(map.get(a)!='abc'){
System.out.println(a);
a++;
}else{
break;
}
}
是不是感觉这个break很奇怪
其实简化如下:
for(int a = 0;a < 100 && map.get(a)!='abc';a++){
System.out.println(a);
}

















 1799
1799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









