






搜狗实验室下载数据格式如下。要提取的内容为第二行中的类型,第四行中的标题,第五行中的内容。下面的方法是将所需要的数据抽取到1.txt文本中。
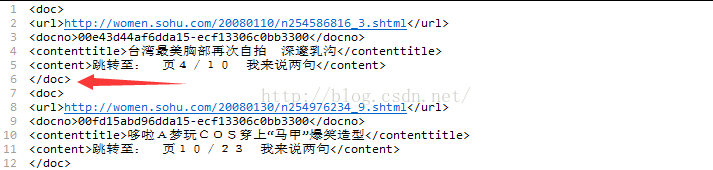
#include<fstream>
#include<iostream>#include<string>
using namespace std;
int main()
{
ifstream infile("D://news.sohunews.010801.txt");//读文件流
ofstream outfile("D://1.txt"); //写文件流
string str; //定义字符串str
string result_str; //定义字符串result_str
int line_size = 0; //控制行数
while (getline(infile, str)) //按行读取文件存储在str字符串中
{
line_size++;
if (line_size % 6 == 2) //如果行数等于2则提取新闻所属于的类别
{
string::size_type pos1, pos2; //设置pos1 pos2来定位要截取的字符串的位置。
pos1 = str.find('/'); //前面字符为'/'
pos2 = str.find(".sohu"); //后面字符串为.sohu
result_str = str.substr(pos1+2,pos2-pos1-2); //substr(参数1,参数2) 参数1为开始截取的位置,参数2为截取的长度。
outfile << result_str << "###"; //输出内容到文件,以###作为分隔符。
}
if (line_size % 6 == 4) //行数为4时提取新闻的标题内容
{
string::size_type pos1, pos2;
pos1 = str.find('>');
pos2 = str.find("</");
result_str = str.substr(pos1 + 1, pos2-pos1-1);
outfile << result_str << "###";
}
if (line_size % 6 == 5) //行数为5提取新闻的正文内容
{
string::size_type pos1, pos2;
pos1 = str.find('>');
pos2 = str.find("</");
result_str = str.substr(pos1 + 1, pos2 - pos1 - 1);
outfile << result_str;
}
if (line_size % 6 == 0) //行数为6时输出一个换行符
{
outfile<< endl;
}
}
system("pause");
}
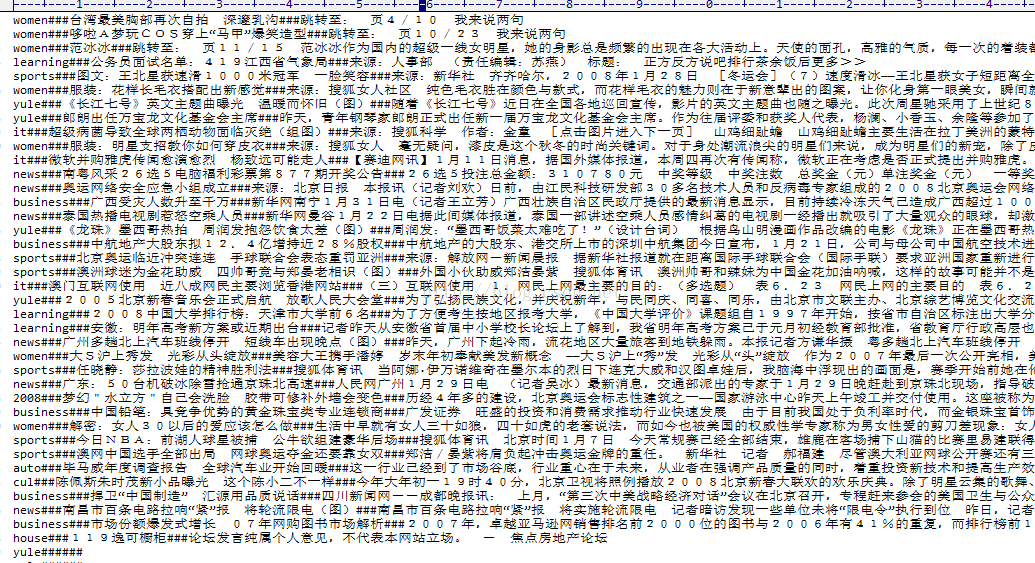
运行结果如下:















 8290
8290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









