






目录
摘要:主成分分析(PCA)是一种常用的数据降维技术,通过保留数据集中的主要特征分量来简化模型。本文介绍了PCA的基本原理、应用场景以及在Python中的实现方法。
一、引言
在数据分析和机器学习领域,我们经常遇到高维数据集,其中包含大量的变量。这些变量可能之间存在相关性,导致数据冗余和复杂性增加。主成分分析(Principal Component Analysis,PCA)是一种有效的数据降维方法,它可以将多维数据映射到较低维度,同时保留数据集中的主要特征分量。PCA在很多领域都有广泛的应用,例如图像处理、语音识别、机器学习等。
二、PCA原理
PCA的基本思想是通过线性变换将原始数据映射到新的坐标系统中,从而简化数据集。这个变换过程涉及到以下几个步骤:
1. 数据中心化:将原始数据集减去其均值得到X,使得数据的均值为0。
2. 计算协方差矩阵:计算数据集的协方差矩阵,表示数据变量之间的相关性。S=X⋅XT
3. 特征值和特征向量:求解协方差矩阵的特征值和特征向量。特征值表示数据分布的方差,特征向量表示数据分布的方向。
4. 选择主成分:根据特征值的大小,降序排列特征值,并选择前k个最大的特征值对应的特征向量作为主成分。这些主成分能够解释数据集的大部分方差。
5. 重建数据:使用选定的主成分重建数据,得到降维后的数据集。
三、PCA应用
PCA在许多领域都有广泛的应用,以下是一些常见的应用场景:
1. 图像处理:通过PCA可以提取图像的主要特征,从而进行图像压缩、降噪等处理。
2. 语音识别:PCA可以用于语音信号处理,提取语音信号的主要成分,从而提高语音识别的准确率。
3. 机器学习:PCA可以作为预处理步骤,降低数据维度,提高机器学习模型的性能。
四代码实现
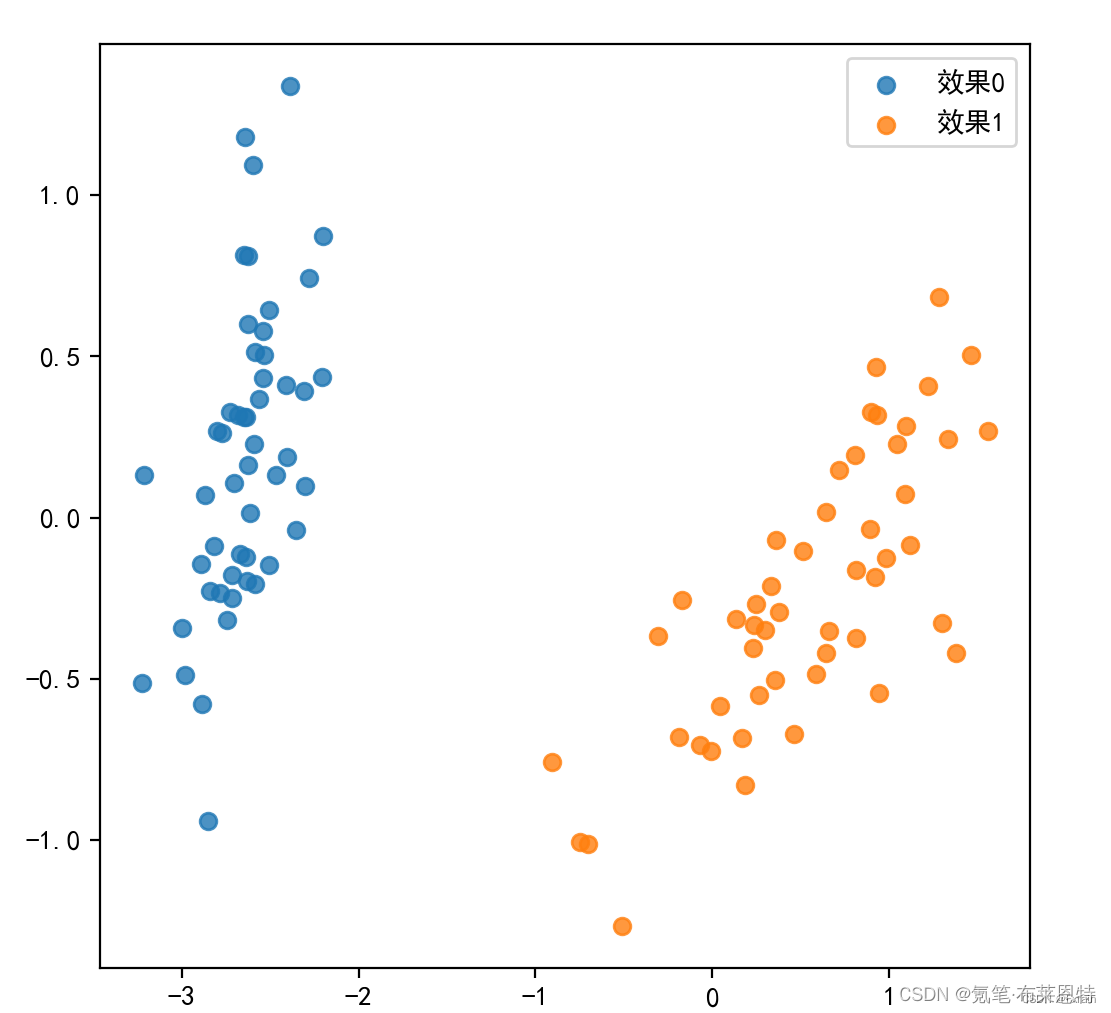
结果展示
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 鸢尾花的数据集
iris = datasets.load_iris()
print(iris)
X=iris['data']
y=iris['target']
print('Before pca: \n', X[:3,:])# 前三行,所有列
pca_1 = PCA(n_components=2) # 指定主成分数量初始化 将数据降为2维
X_red_1 = pca_1.fit_transform(X) # fit并直接得到降维结果
# 这里只展示前三行的结果以示对比
print('After pca: \n', X_red_1[:3, :],'\n')
# 查看各个特征值所占的百分比,也就是每个主成分保留的方差百分比
print('方差百分比: ', pca_1.explained_variance_ratio_)
# 当前保留总方差百分比;
print('总方差百分比: ',pca_1.explained_variance_ratio_.sum(),'\n')
# 线性变换规则
print('components_: \n', pca_1.components_)
#结果可视化
plt.figure(figsize=(6,6))
for i in range(2):
plt.scatter(x=X_red_1[np.where(y==i),:][0][:,0], y=X_red_1[np.where(y==i),:][0][:,1], alpha=0.8, label='效果%s' % i)
plt.legend()
plt.show()五、总结分析
本次实验通过PCA实现特征提取(降维)。PCA算法可以简化模型或是对数据进行压缩,同时最大程度的保持了原有数据的信息,最后的结果只与数据有关。各主成分之间正交,可以消除原始数据成分间对的影响。但是PCA是基于线性变换,假设数据是线性相关的。对于非线性关系较强的数据,PCA可能不够有效,需要使用非线性降维方法。















 65万+
65万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









